底层结构
数组
- 使用数组,每次作为函数参数会复制整个数组
- 不同大小数组类型不一样,长度不可变
切片
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
- 切片append之后,由于Data内容可能发生变化,所以要切片重新赋值
- 切片作为参数时候,会拷贝结构体内容,因此修改本体
注意,作为参数传递时候,如果是append可能导致data指向发生变化导致外围无法感知变化,因此如果要修改最好还是传指针
func Temp(slice []string) {
slice = append(slice, "1")
fmt.Println(slice)
}
func TryAppend() {
var slice []string
Temp(slice)
fmt.Println(slice)
}
// 这部分代码结果为 [1] []
func Temp(slice *[]string) {
*slice = append(*slice, "1")
fmt.Println(*slice)
}
func TryAppend() {
var slice []string
Temp(&slice)
fmt.Println(slice)
}
// 这部分代码结果为 [1] [1]
和数组区别
- 数组长度不能改变,初始化后长度就是固定的;切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大
- 函数调用时的传递方式不同,数组按值拷贝,slice按只拷贝指针
- unsafe.sizeof的取值不同,unsafe.sizeof(slice)返回的大小是切片的描述符,不管slice里的元素有多少,返回的数据都是24字节。unsafe.sizeof(arr)的值是在随着arr的元素的个数的增加而增加,是数组所存储的数据内存的大小。
- 初始化方式不同
Map
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
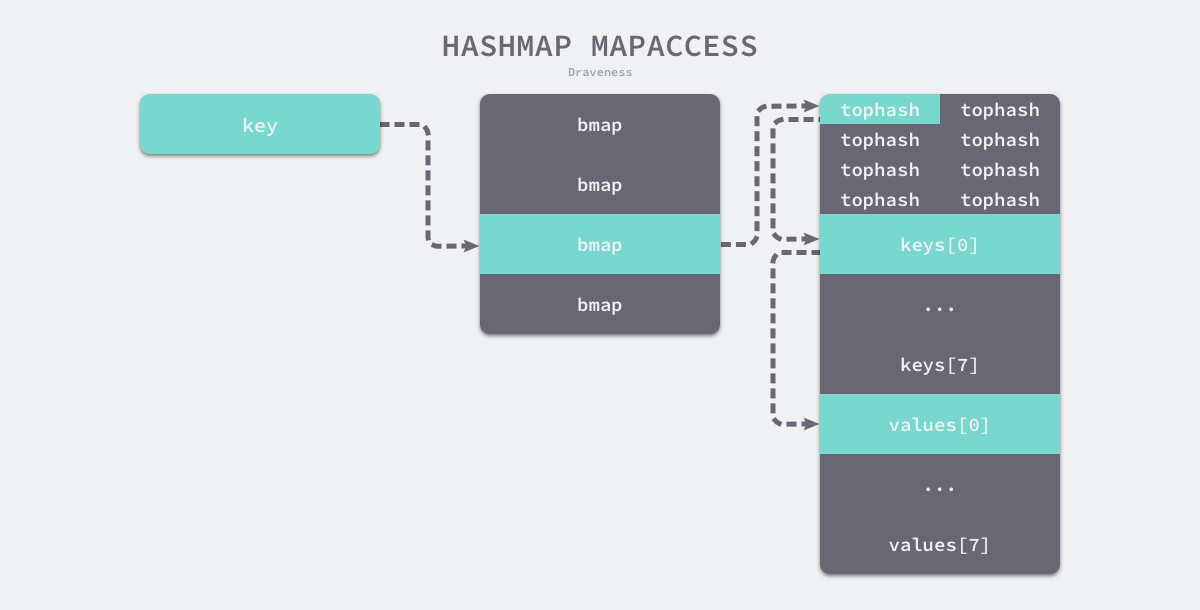
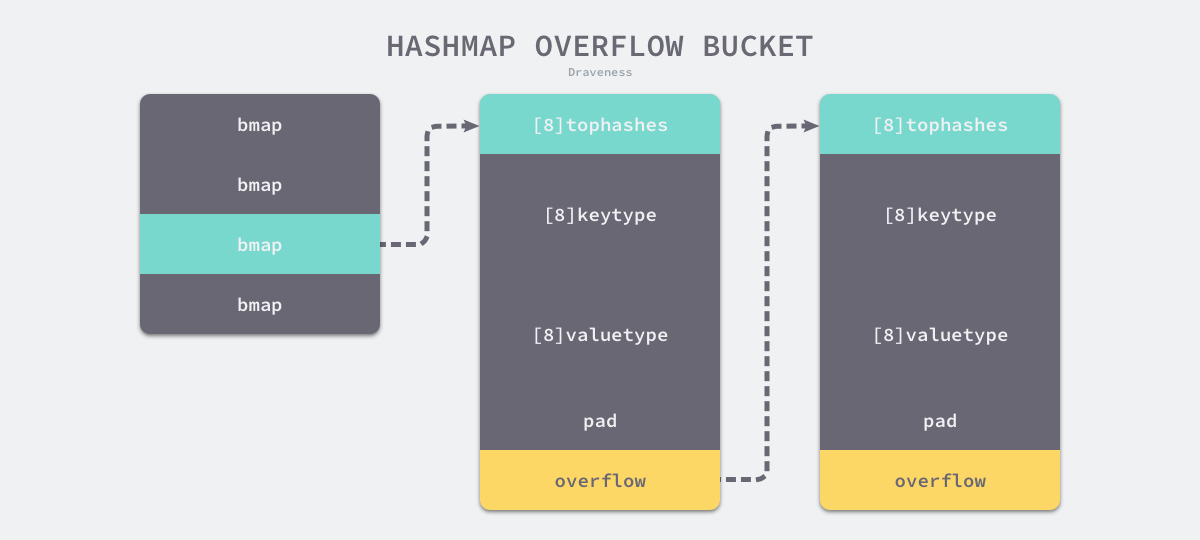
-
使用公共溢出区解决hash冲突
- 空间利用效率高(不需要存储指针)2.内存连续性3.灵活的动态扩展
-
实际上存的也是指针,参数会改变
-
只有 hash 后的值相等以及字面值相等,才被认为是相同的 key。很多字面值相等的,hash出来的值不一定相等,比如引用。
-
线程不安全:在查找、赋值、遍历、删除的过程中都会检测写标志,一旦发现写标志置位(等于1),则直接 panic。赋值和删除函数在检测完写标志是复位之后,先将写标志位置位,才会进行之后的操作
-
也是通过渐进式扩容,和redis类似,#### rehash
服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于
1; 服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于5- 渐近式,不会出现突发性能问题(还是用空间换时间)
- 按照倍数扩大
过程
- 为
ht[1]分配空间, 让字典同时持有ht[0]和ht[1]两个哈希表。 - 在字典中维持一个索引计数器变量
rehashidx, 并将它的值设置为0, 表示 rehash 工作正式开始。 - 在 rehash 进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将
ht[0]哈希表在rehashidx索引上的所有键值对 rehash 到ht[1], 当 rehash 工作完成之后, 程序将rehashidx属性的值增一。 - 随着字典操作的不断执行, 最终在某个时间点上,
ht[0]的所有键值对都会被 rehash 至ht[1], 这时程序将rehashidx属性的值设为-1, 表示 rehash 操作已完成。
- 标识开始hash,在每次操作时候进行,按照顺序
- 均为单线程操作
操作
- 查找先在原来的查,找不到再查新的,删除,改变归同时操作两个
- 增加只在新的增加
字符串
type StringHeader struct {
Data uintptr
Len int
}
// byte
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
- 字符串不能更改,只能重新赋值(修改指针,类似+这种都是生成新的字符串)
- []byte(string)实际上发生了拷贝,而不是指针转移,因此开销很大
- 也是线程不安全
接口
- 接口不是任意类型,它自己带有数据,!=nil
// 不带有方法(函数)的接口
type eface struct { // 16 字节
_type *_type
data unsafe.Pointer
}
type _type struct {
size uintptr //用于计算占用大小
ptrdata uintptr
hash uint32 //重要,用于用hash计算两个对象是否相等
tflag tflag
align uint8
fieldAlign uint8
kind uint8
equal func(unsafe.Pointer, unsafe.Pointer) bool
gcdata *byte
str nameOff
ptrToThis typeOff
}
// 带的接口
type iface struct { // 16 字节
tab *itab
data unsafe.Pointer
}
type itab struct { // 32 字节
inter *interfacetype
_type *_type
hash uint32 //和上面的hash一样
_ [4]byte
fun [1]uintptr //重要,虚函数指针
}
-
类型断言实际上就是比较hash值是否相同
-
方法调用时候的操作和C++类似,虚函数加偏移## 多态的实现
虚函数表
- 虚函数表可以理解为就是一个函数指针数组
functype ptr[] - 虚函数表内部存放的是函数指针,而不是函数地址
- 无论是基类还是子类,(前提有虚函数)都有一个自己的虚函数表,继承时候会直接复制基类的虚函数表
- 重写时候会改写虚函数表里面指针指向的函数地址,达到多态作用
- 子类添加新的虚函数(不是重写,而是新的)会追加在虚函数表最后
- 父类指针拿到子类对象时候,对着表格拿到函数指针,但是实际上拿到的是子类的虚函数表,因此函数指针也是指向子类的,因此实现多态

- 多重继承时候会有多个虚函数表
面向过程区别
- 面向对象是以功能来划分问题,而不是以步骤解决
三大特性
封装
- 类仅仅通过有限的方法暴露必要的操作,也能提高类的易用性
- 增强代码可读性和可维护性
继承
- 代码复用,将这些相同的部分,抽取到父类中,让两个子类继承父类
[!tips] 注意点 继承的时候所有虚函数不要加const, 因为不确定子类重写的时候会不会需要更改, 加上是不合适的
多态
- 提高了代码的可扩展性。
- 只需要根据父类指针调用函数,不用关心子类的具体实现
底层模型
虚拟继承
- 解决菱形继承的问题
- A作为base类会被放在最下面,作为共享部分,然后与base不同部分放在上面
D VTable +---------------------+ | vbase_offset(32) | +---------------------+ struct D | offset_to_top(0) | object +---------------------+ 0 - struct B (primary base) | RTTI for D | 0 - vptr_B ----------------------> +---------------------+ 8 - int bx | D::f0() | 16 - struct C +---------------------+ 16 - vptr_C ------------------+ | vbase_offset(16) | 24 - int cx | +---------------------+ 28 - int dx | | offset_to_top(-16) | 32 - struct A (virtual base) | +---------------------+ 32 - vptr_A --------------+ | | RTTI for D | 40 - int ax | +---> +---------------------+ sizeof(D): 48 align: 8 | | D::f0() | | +---------------------+ | | vcall_offset(0) |x--------+ | +---------------------+ | | | vcall_offset(-32) |o----+ | | +---------------------+ | | | | offset_to_top(-32) | | | | +---------------------+ | | | | RTTI for D | | | +--------> +---------------------+ | | | Thunk D::f0() |o----+ | +---------------------+ | | A::bar() |x--------+ +---------------------+多线程
- 当一个thread对象既没有detach也没有join时候,thread释放(可以是因为栈对象自动释放)后会直接中断程序
- thread提供参数之后不能通过引用传递,但是可以通过指针传递,因为thread构造参数时候直接使用拷贝
- condition_variable的wait调用后,会先释放锁,之后进入等待状态;当其它进程调用通知激活后,会再次加锁
std::unique_lock和std::lock_guard类似,第一个更加灵活,但是性能更加差- 条件变量的用法通常为生产者消费者模型,多个线程用同一个锁+条件变量阻塞
- bind函数可以将函数和参数进行绑定生成一个新的函数对象,这样适配接口就会更加方便
void fun1(int n1, int n2, int n3) { cout << n1 << " " << n2 << " " << n3 << endl; } struct Foo { void print_sum(int n1, int n2) { std::cout << n1+n2 << '\n'; } int data = 10; }; int main() { //_1表示这个位置是新的可调用对象的第一个参数的位置 //_2表示这个位置是新的可调用对象的第二个参数的位置 auto f1 = bind(fun1, _2, 22, _1); f1(44,55); Foo foo; auto f = std::bind(&Foo::print_sum, &foo, 95, std::placeholders::_1);// 第二个参数必须是对象作为this指针 f(5); // 100 }- thread是可以移动的move,但是不能复制copy
条件变量和信号量的区别
- 条件变量支持广播方式唤醒等待者;而信号机制不支持,只能一个一个通知
- 条件变量只能结合互斥量做同步用;信号机制除了做同步,还能用于共享资源并发访问加锁
- 条件变量是无状态的,如果唤醒早于等待,则唤醒会丢失;信号机制是有状态的,可以记录唤醒的次数
多线程demo
class ThreadPool{ private: std::queue<std::function<void(void)>> task_que_; std::condition_variable cond_;// 条件变量,通常和锁一起使用 std::mutex que_mut_;// 队列锁 std::vector<std::thread> arr_thread_; std::atomic<bool> is_close; std::atomic<int> busy_num_;// 多线程操作,原子变量 public: ThreadPool(int thread_num){ is_close=false; for (int i = 0; i < thread_num; i++) { arr_thread_.emplace_back(std::thread(Consumer,this));// 本身就是右值,可以不适用std::move,如果是左值而且使用emplace_back的话需要std::move避免thread的复制行为 } } ThreadPool():ThreadPool(5){} ~ThreadPool(){ is_close=true; cond_.notify_all(); for(auto& thread_now:arr_thread_){ thread_now.join(); } } void Add(const std::function<void(void)>& call_back){ std::lock_guard<std::mutex> guard(que_mut_); task_que_.emplace(call_back); cond_.notify_one(); } private: static void Consumer(ThreadPool* pool){ if (pool==nullptr) { return; } auto& cond=pool->cond_; auto& mut=pool->que_mut_; std::function<void(void)> task{nullptr}; while (1) { {// 这个作用域结束que_mut_自动释放,为了避免锁的占用 std::unique_lock<std::mutex> unique(pool->que_mut_); cond.wait(unique,[&]()->bool{return !pool->task_que_.empty()||pool->is_close;});// wait函数首先通过第一个参数拿到锁的控制权,然后不会加锁或者解锁,会等待条件变量的到来,条件变量到来后尝试加锁(多个线程最后只有一个能拿到锁),拿到之后判断第二个参数是否为true,如果为true就继续执行,否则就解开锁继续等待 if (pool->is_close) { return; } task=pool->task_que_.front(); pool->task_que_.pop(); } pool->busy_num_++; if (task!=nullptr) { task(); } pool->busy_num_--; } } }; void PrintFunc(int print_num){ std::cout<<"run:"<<print_num<<std::endl; } int main() { ThreadPool pool; for (int i = 0; i < 20; i++) { pool.Add(std::bind(PrintFunc,i));// std::bind的作用是生成一个新的函数对象,这个对象可以直接提供参数,达到参数简化的目的 } sleep(2); return 0; }
参考
- 深度探索C++对象模型
- 虚函数表可以理解为就是一个函数指针数组
函数调用
- 和C一样的地方:重后向前计算参数
- 不一样:GO不用寄存器,而C用
关键字
for range
for i,v := range arr{}
//会转化为下面形式,长度在一开始就确定了,不会变
//`range` 运算符会创建了数组的副本。同时,循环不会更新副本
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
for ; hv1 < hn; hv1++ {}
- hash遍历顺序是不确定的
select
- 随机生成一个遍历的轮询顺序
pollOrder并根据 Channel 地址生成锁定顺序lockOrder; - 根据
pollOrder遍历所有的case查看是否有可以立刻处理的 Channel;- 如果存在,直接获取
case对应的索引并返回; - 如果不存在,创建
runtime.sudog结构体,将当前 Goroutine 加入到所有相关 Channel 的收发队列,并调用runtime.gopark挂起当前 Goroutine 等待调度器的唤醒;
- 如果存在,直接获取
- 当调度器唤醒当前 Goroutine 时,会再次按照
lockOrder遍历所有的case,从中查找需要被处理的runtime.sudog对应的索引;
defer
- 底层为链表结构,添加的反而时候会在头部添加最新的defer,执行时候从头执行,类似栈
- 如果是传递参数的话,添加时候(声明defer)函数的参数就已经确定了
- defer和goroutine关联,panic只会调用自己协程的defer
- defer在函数退出时才能执行,在for执行defer会导致资源延迟释放,不要在循环中使用defer,除非构造局部函数
- defer如果是直接接受对象的函数,会立刻拷贝这个对象,如果是对象实体,那么后续改变不影响defer内容,如果是对象指针,后面会影响defer内容
[!important] Defer坑点
... if(xxx){ mut.lock() defer mut.unlock() defer fmt.Println(1) } fmt.Println(2)这段代码的结果是
21,而且因为这个特性很容易产生死锁,defer的调用是在其所在函数返回的时候才会发生的,其他时候不会出现,即使再加个大括号也不行
panic/recover
- 之后defer可以捕获panic并执行recover >在 panic之后不执行,因此不能放后面 >放前面panic没发生,捕获不到
- recover不能跨栈(必须统一层次)执行
func main() {
defer func() {
recover()// 只有放到这里才能执行
}()
panic(1)
}
break
- break+标签的方式作用不是goto 标签,而是跳出标签下的第一个select/switch/for 循环,goto+标签 才是直接跳到该标签
- break只能跳出一个 select/switch/for 循环
- 单独在select中使用break和不使用break没有啥区别。
- 单独在表达式switch语句,并且没有fallthough,使用break和不使用break没有啥区别。
- 单独在表达式switch语句,并且有fallthough,使用break能够终止fallthough后面的case语句的执行。
- 带标签的break,可以跳出多层select/ switch作用域。让break更加灵活,写法更加简单灵活,不需要使用控制变量一层一层跳出循环,没有带break的只能跳出当前语句块。
系统组件
Mutex
正常模式
- 非公平锁
- 正常模式下,所有等待锁的 goroutine 按照 FIFO(先进先出)顺序等待。唤醒 的 goroutine 不会直接拥有锁,而是会和新请求 goroutine 竞争锁。新请求的 goroutine 更容易抢占:因为它正在 CPU 上执行,所以刚刚唤醒的 goroutine有很大可能在锁竞争中失败。在这种情况下,这个被唤醒的 goroutine 会加入 到等待队列的前面。
- 性能好,因为切换成本低.
饥饿模式
- 公平锁
- 饥饿模式下,直接由 unlock 把锁交给等待队列中排在第一位的 goroutine (队 头),同时,饥饿模式下,新进来的 goroutine 不会参与抢锁也不会进入自旋状 态,会直接进入等待队列的尾部。这样很好的解决了老的 goroutine 一直抢不 到锁的场景。
- 触发条件:当一个 goroutine 等待锁时间超过 1 毫秒时,或者当前 队列只剩下一个 goroutine 的时候,Mutex 切换到饥饿模式。
计时器
-
使用四叉堆
时间堆
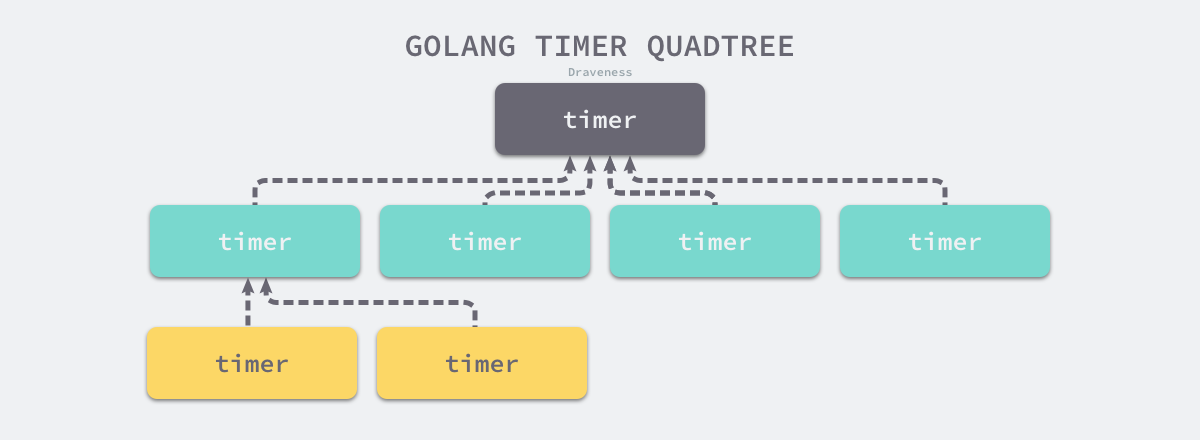
- 高精度
- 逻辑复杂
- 一般用四叉堆
- 插入和删除的复杂度是logn(因为涉及到排序二分搜索)
思路
- 类似二叉堆,最小先执行的时间放在上面
- 到了实现执行之后重新计算堆
cron
- 使用类似二叉堆的办法
for { // Determine the next entry to run. sort.Sort(byTime(c.entries))// 直接数组排序 var timer *time.Timer if len(c.entries) == 0 || c.entries[0].Next.IsZero() { timer = time.NewTimer(100000 * time.Hour) } else { timer = time.NewTimer(c.entries[0].Next.Sub(now))//计算最小到期时间并且计时 } for { select { case now = <-timer.C://触发标识出现计时器到期 now = now.In(c.location) // Run every entry whose next time was less than now for _, e := range c.entries { if e.Next.After(now) || e.Next.IsZero() { break } c.startJob(e.WrappedJob) e.Prev = e.Next e.Next = e.Schedule.Next(now)//计算下一次触发时间 c.logger.Info("run", "now", now, "entry", e.ID, "next", e.Next) } case newEntry := <-c.add://添加之后会重新计算最小到期时间 timer.Stop() now = c.now() newEntry.Next = newEntry.Schedule.Next(now) c.entries = append(c.entries, newEntry) c.logger.Info("added", "now", now, "entry", newEntry.ID, "next", newEntry.Next) //...略 case id := <-c.remove: timer.Stop() now = c.now() c.removeEntry(id)//删除节点 c.logger.Info("removed", "entry", id) } break//无论结果到这里都会出来重新计算 } }
chan
type hchan struct {
qcount uint
dataqsiz uint
buf unsafe.Pointer
elemsize uint16
closed uint32
elemtype *_type
sendx uint
recvx uint
recvq waitq
sendq waitq
lock mutex
}
qcount— Channel 中的元素个数;dataqsiz— Channel 中的循环队列的长度;buf— Channel 的缓冲区数据指针;sendx— Channel 的发送操作处理到的位置;recvx— Channel 的接收操作处理到的位置;
除此之外,
elemsize和elemtype分别表示当前 Channel 能够收发的元素类型和大小;sendq和recvq存储了当前 Channel 由于缓冲区空间不足而阻塞的 Goroutine 列表,这些等待队列使用双向链表runtime.waitq表示,链表中所有的元素都是runtime.sudog结构
- 阻塞发生时候会加入队列后沉睡,然后等待调度器唤醒
- 使用环形缓冲区实现缓冲

发送流程
- 检查 recvq 是否为空,如果不为空,则从 recvq 头部取一个 goroutine,将数据发送过去,并唤醒对应的 goroutine 即可。
- 如果 recvq 为空,则将数据放入到 buffer 中。
- 如果 buffer 已满,则将要发送的数据和当前 goroutine 打包成
sudog对象放入到sendq中。并将当前 goroutine 置为 waiting 状态。
接收流程
- 检查是否有数据,如果有数据,直接返回数据
- 如果没有数据,加入recvq,并且让出协程
关闭的chan
- 向关闭的chan写入会出现panic,重复关闭chan会panic,未初始化关闭会panic(核心就是已经关闭的cha只能读不能写)
- 读取关闭的chan
- 通过val,ok读取得到的ok为false
- 通过val读取得到的为默认值
- close chan时候所有阻塞读chan的协程都会收到消息
- close chan后chan编程只读状态,任何写操作都会panic(比如close和写入消息)
避免产生panic方法
- 应该只在发送端关闭 channel。(防止关闭后继续发送)
- 存在多个发送者时不要关闭发送者 channel,而是使用专门的 stop channel。(因为多个发送者都在发送,且不可能同时关闭多个发送者,否则会造成重复关闭。发送者和接收者多对一时,接收者关闭 stop channel;多对多时,由任意一方关闭 stop channel,双方监听 stop channel 终止后及时停止发送和接收)
for-select模型
- 非阻塞写
for{
select {
case ch <- 1:
fmt.Println("Sent 1")
default:
fmt.Println("Channel is full")
}
}
- 非阻塞读
for{
select {
case i := <-ch:
fmt.Println("Received", i)
default:
fmt.Println("No value received")
}
}
- 退出监控
- 退出时候给所有等待中的chan发送默认值
for {
select {
case <-G2CServer.ExitChan:
return
}
}
调度器
- goroutine之所以这么快就是因为其比线程更加小,操作系统完全不感知,由Go调度器自己执行和分配而可以做到系统不感知的重要操作是函数调用不需要使用寄存器,这样协程使得所有的操作都在内存进行
GMP模型
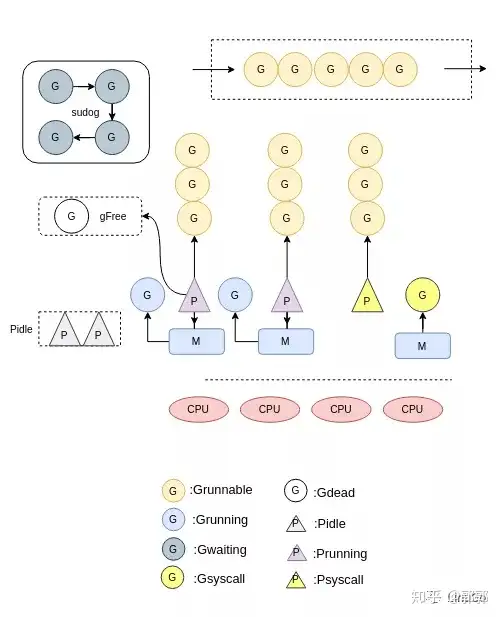
- G:表示goroutine,每个goroutine都有自己的栈空间,定时器,初始化的栈空间在2k左右,空间会随着需求增长。
- M:抽象化代表内核线程,记录内核线程栈信息,当goroutine调度到线程时,使用该goroutine自己的栈信息。
- P:代表调度器,负责调度goroutine,维护一个本地goroutine队列,M从P上获得goroutine并执行,同时还负责部分内存的管理。
- 一个M只能同时运行一个G
- M运行哪个G从P获取,P负责G顺序和部分内存的管理,G的运行队列是环形的保证公平
- 再运行GC时候会主动放弃主动权
调度时机
- Channel阻塞:当goroutine读写channel发生阻塞时候,会调用gopark函数,该G会脱离当前的M与P,调度器会执行schedule函数调度新的G到当前M。mutex阻塞也会发生这个情况
- 系统调用:当某个G由于系统调用陷入内核态时,该P就会脱离当前的M,此时P会更新自己的状态为Psyscall,M与G互相绑定,进行系统调用。结束以后若该P状态还是Psyscall,则直接关联该M和G,否则使用闲置的处理器处理该G。
- 系统监控:当某个G在P上运行的时间超过10ms时候,或者P处于Psyscall状态过长等情况就会调用retake函数,触发新的调度。
- 主动让出:由于是协作式调度,该G会主动让出当前的P,更新状态为Grunnable,该P会调度队列中的G运行。
抢占式调度
- 协作式,使用函数触发
- 基于信号,信号触发(目前只在GC使用)
协程同步的方法
- mutex锁
- cond条件变量
- chan通道
- waitgroup
优势
- 上下文切换代价小: P 是G、M之间的桥梁,调度器对于goroutine的调度,很明显也会有切换,这个切换是很轻量的: 只涉及PC SP DX三个寄存器的值的修改;而对比线程的上下文切换则需要陷入内核模式、以及16个寄存器的刷新
- 内存占用小: 线程栈空间通常是2M, Goroutine栈空间最小是2k, golang可以轻松支持10w+的goroutine运行,而线程数量到达1k, 内存占用就到2G。
并发模型
context包作用
- 用于在goroutine 之间传递取消信号、超时时间、截止时间以及一些共享的值
sync包
sync.map
- map不是线程安全的(可以通过互斥锁或者读写锁实现线程安全),但是sync.map是线程安全的
- 底层设计和缓存思想以及redis类似,都是通过缓存读的办法解决读的速度问题,但是写的时候需要维护缓存一致性因此比较慢,合适用于读多写少的情况,非常不适合写多读少的情况,删除因为只是标记,因此也很快.整个设计重点要考虑的就是一致性,和read命中两个方面的问题
结构
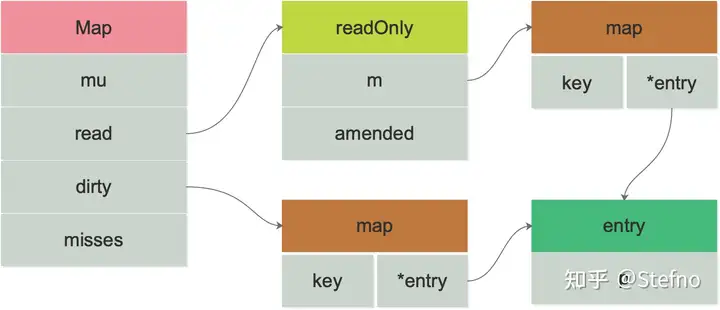
type Map struct {
mu Mutex
read atomic.Value // readOnly结构体
dirty map[interface{}]*entry
misses int
}
// Map.read 属性实际存储的是 readOnly。
type readOnly struct {
m map[interface{}]*entry
amended bool //amended 属性告诉程序 dirty 是否包含 `read.readOnly.m` 中没有的数据
}
读取过程
- 先查看 read 中是否包含所需的元素:
- 若有,则通过 atomic 原子操作读取数据并返回。
- 若无,则会判断
read.readOnly中的 amended 属性,他会告诉程序 dirty 是否包含read.readOnly.m中没有的数据;因此若存在,也就是 amended 为 true,将会进一步到 dirty 中查找数据
调用 Load 或 LoadOrStore 函数时,如果在 read 中没有找到 key,则会将 misses 值原子地增加 1,当 misses 增加到和 dirty 的长度相等时,会将 dirty 提升为 read。以期减少“读 miss”
写入过程
- 检查
m.read中是否存在这个元素。若存在,且没有被标记为删除状态,则尝试存储。 - 如果不存在进入dirty
- 加锁,dirty因为是原生的map,加锁才能使用
- 若发现 read 中存在该元素,但已经被标记为已删除(expunged),则说明 dirty 不等于 nil(dirty 中肯定不存在该元素)。其将元素状态从已删除(expunged)更改为 nil。将元素插入 dirty 中。
- 若发现 read 中不存在该元素,但 dirty 中存在该元素,则直接写入更新 entry 的指向。标记amended为true
- 若发现 read 和 dirty 都不存在该元素,则从 read 中复制未被标记删除的数据,并向 dirty 中插入该元素,赋予元素值 entry 的指向
删除过程
- 将 entry.p 置为 nil,并且标记为 expunged(删除状态),而不是真真正正的删除。
参考
- https://zhuanlan.zhihu.com/p/413467399
- https://zhuanlan.zhihu.com/p/344834329
Goroutine泄露
- 泄漏的可能主要分为
- channel 导致的泄露
- 如goroutine等待chan或者发送chan导致不能释放,这部分可以通过context的cancel取消
- 传统同步机制导致的泄露
- 比如多个协程加锁但是没有释放,导致不停等待
- channel 导致的泄露
内存管理
内存分配器
- 类似内存池分配分片式
内存回收GC
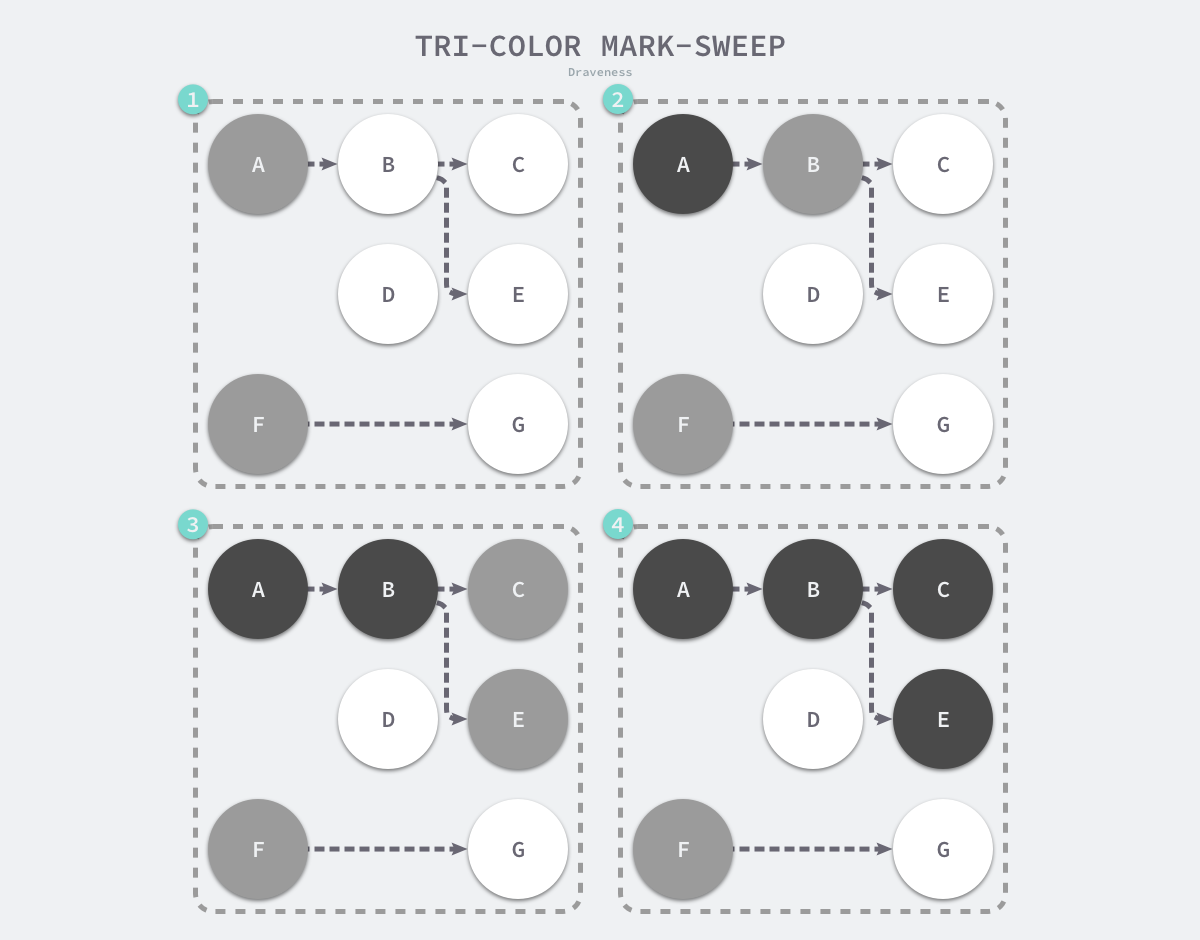
三色标记法
代码参考
- C++:https://gitee.com/chenxuan520/tricolor-notation/blob/master/gc.h
说明
- 本质也是标记清除算法,但是解决它的程序停止的缺点(核心还是读写冲突的问题,如果不暂停程序就会出现读写冲突,三色标记法使用的是类似锁的方法解决)
- 垃圾收集的根对象一般包括全局变量和栈对象,因为栈对象永远是黑色(会自动释放),只有堆对象需要回收
- Go 语言的垃圾收集可以分成清除终止、标记、标记终止和清除四个不同阶段
过程
- 先从根开始标记灰色,三个桶
- 把灰色引用到的全部变灰色,灰色变黑
- 删除白色对象
- 继续上面过程
完整流程
- GCMark 标记准备阶段,为并发标记做准备工作,启动写屏障
- STWGCMark 扫描标记阶段,与赋值器并发执行,写屏障开启并发
- GCMarkTermination 标记终止阶段,保证一个周期内标记任务完成,停止写屏障
- GCoff 内存清扫阶段,将需要回收的内存归还到堆中,写屏障关闭
- GCoff 内存归还阶段,将过多的内存归还给操作系统,写屏障关闭。
写屏障
- 强三色不变性 — 黑色对象不会指向白色对象,只会指向灰色对象或者黑色对象;
- 弱三色不变性 — 黑色对象指向的白色对象必须包含一条从灰色对象经由多个白色对象的可达路径
- 所有触发都是针对黑色和灰色对象,白色对象引用的改变不会触发
- 缺点: 需要给栈对象添加屏障,损耗指针性能
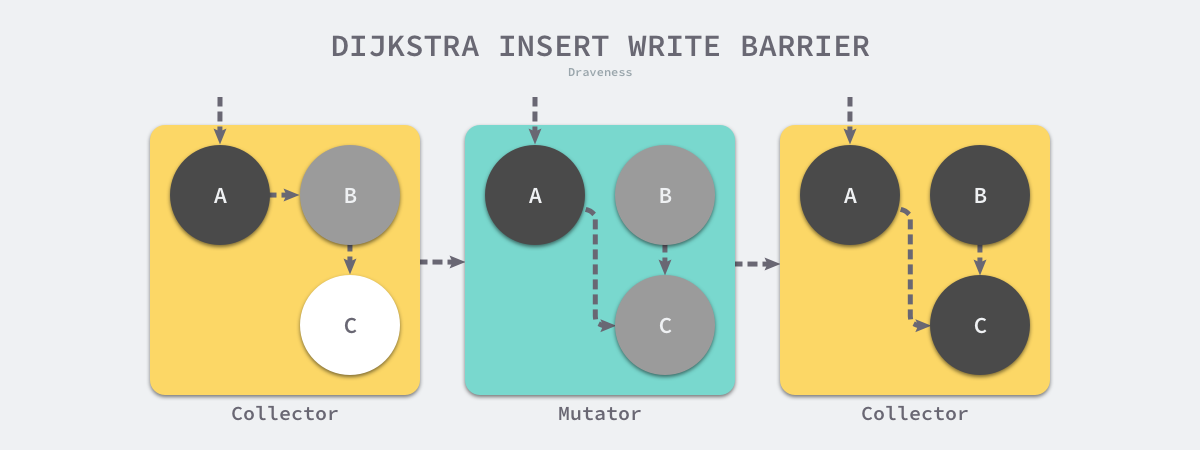
插入写屏障
writePointer(slot, ptr):
shade(ptr) //把要插入引用的对象先涂灰
*slot = ptr //改变指针到引用
- 把增加引用的对象变成灰色,添加引用时候触发,保证强三色不变性
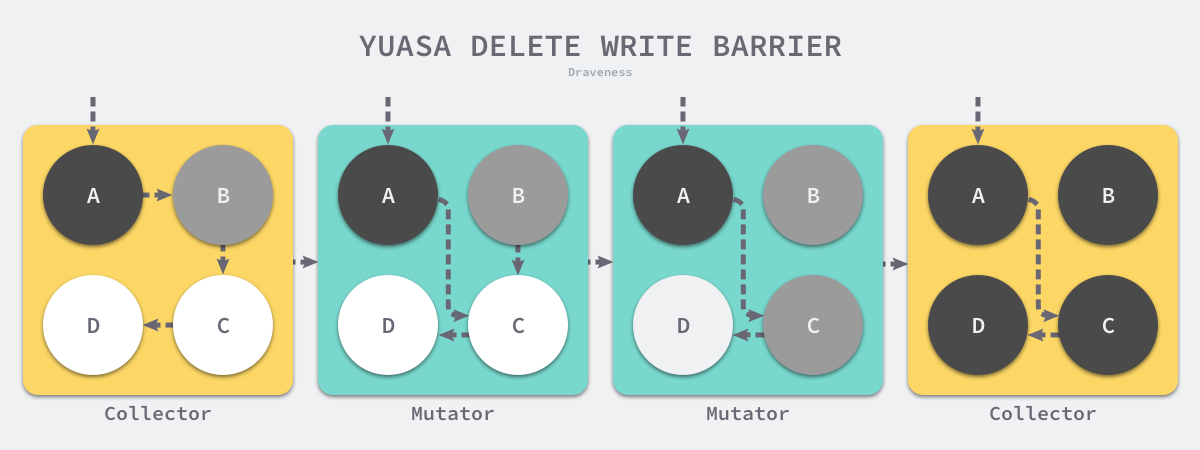
删除写屏障
writePointer(slot, ptr)
shade(*slot) //把要删除的引用对象涂灰
*slot = ptr //改变指针到引用
- 删除引用之前,先把被删除引用对象涂灰
混合写屏障
writePointer(slot, ptr):
shade(*slot)
if current stack is grey://当前栈没有扫描,是白色
shade(ptr)
*slot = ptr
- 将创建的所有新对象都标记成黑色,防止新分配的栈内存和堆内存中的对象被错误地回收
内存逃逸
- 由编译器编译时候生成AST,分析之后得出分配在哪里
原则
- 指向栈对象的指针不能存在于堆中;
- 指向栈对象的指针不能在栈对象回收后存活;
如果函数外部没有引用,则优先放到栈中; 如果函数外部存在引用,则必定放到堆中;
逃逸类型
- 外部引用(类似指针)
- 栈空间不足逃逸(分配过大空间)
- 动态类型逃逸(interface类型,由于编译期间难以确定类型,直接扔到栈上)
参考
- https://zhuanlan.zhihu.com/p/261057034
- https://draveness.me/golang/docs/part3-runtime/ch06-concurrency/golang-goroutine
- https://zhuanlan.zhihu.com/p/113643434 推荐书籍
- Go语言设计与实现