私聊
tira-im
群聊
helper-im
综合
openim
直播聊天室
- 消息扩散比大,同时要保证实时性;
- 成员流动性大,在线状态难维护;
- 不关注历史消息,消息下发后即可删除;
- 消息量大,容忍少量消息丢失;
- 用户爆发量大,需要支持快速水平扩展;
goim(哔站弹幕系统)

结构图

整体流程
- logic是负责处理http请求部分,job相当于异步下发的中间件(逻辑层),comet主要负责长连接以及消息的下发(接入层的感觉)
- comet只关心连接的部分,任何人都有可能连接到任何一个comet
-
通过logic的http接口发送消息,logic直接将消息扔到kafka中
消息的类型,消息的body,发送人,以及房间号
-
job模块拿出来之后放到room的chan中,这部分每一个job、都有可能拿到消息,只会被消费一次,
-
遍历所有的comet,通过rpc异步发送这个消息(这里如果不是广播而是私信就只发布到指定用户在的comet)
-
comet拿到之后遍历所有的bucket(相当于每个用户的连接被放到不同bucket中,这部分可以仔细看看)
-
bucket遍历对应房间chan中的所有连接,下发消息)
特点
- 使用写扩散的机制,发一条将消息体直接下发到每个人
- 消费kafka的时候也是拿出来后直接mark成功,这里涉及丢包的现象毕竟比较少,影响也比较小
- 使用中间件job避免大量消息堆积在kafka中,同时方便扩展job,通过kafka实现消息的削峰,通过job实现消息的分流
- comet中存在大量的chan缓冲作用(基本上每个模块的连接都是通过chan)
- 使用bucket再次进行缓冲和连接的分片,每个连接代表一盒channel
缺点
- 只是改善,依旧存在写风暴的问题,但是通过层层缓冲一定程度减轻了影响
- 中间可能出现丢消息的情况(因为chan满了直接丢弃)
- 轻量化,容易实现,但是有序性和必达性不保证(其实弹幕系统这两个需求也不高)
微信聊天室

- 使用群聊收件箱的机制,以群聊维度发号,消息只存一份
- 客户端携带自己的seq下拉,如果是新用户seq为0,拉取最近的40条消息,否则拉取最新的消息
和goim比较
- 因为只需要下发ID,写扩散压力大大减小
- 读压力放大,因为客户端需要不断申请拉取新的消息
- 引入了存储的部分,消息需要存储,goim不需要存储
- goim使用长连接主动下发push的办法,微信使用HTTP LongPolling(客户端发起收消息请求后,把请求先hold在服务端,等待一段时间,设置为5s,若期间有新消息,则立马返回,若没有则等待结束后返回空消息)
解决读压力太大的问题
- 使用集群缓存的办法解决,通过hash将不同的聊天室hash到不同的缓存集群中,每个集群都缓存了集群负责群的最近1000条消息
- 使用两份写表切换的形式解决读写锁冲突的问题

解决没有长连接统计在线问题
- 设置一个统一的聊天室在线列表缓存svr,当用户有http时候就向svr发送心跳包,实际上这部分还是有可能出现断连消息滞后的问题(只能等待自动过期)
消息通知流程
- 用户根据房间号hash之后得到缓存的集群地点,直接向集群发送请求,集群自己负载均衡之后打到某台机器上
- 请求进入缓存层后,若有新消息,则立刻返回,无须等待;
- 请求进入缓存层后,若没有新消息,将请求加入队列中hold住,每200ms轮询max_seq

微信IM
整体架构图
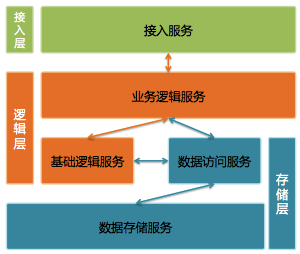
- 微信的消息不进行持久化存储,特别是私聊消息收到ack之后过几天就删除了,无法提供消息漫游的功能,但是QQ可以
- 微信的消息成功的通知是在消息的成功落库之后才进行的,因此可以保证必达性
推送模型

- 下发ID和下发data两种模式相结合的形式
- 下发模式分为notify和data两种模式,data为数据体模式,notify为下行ID的形势
- data模式明显比notify模式快,但是可能出现消息丢失的现象(除非使用双链,但是双链重试使得效率降低),因此微信采取的data模式时候是在服务端转换的(接入层更改),这部分意味着由服务器保存一份用户接受到了的最新id,然后通过这个id查询你需要的消息体,打包下发
- Data的状态需由客户端触发形成,触发的时机为客户端主动上服务器来做过一次消息收取的请求。由于在Data状态下需由服务器的ConnectSvr主动去ReceiveSvr获取增量消息,服务器必须知道客户端此时的sequence才能做到通过sequence的比较增量下发消息。所以在进入NotifyData状态前,需等待客户端主动做一次消息收取的请求将此时客户端的sequence保存在ConnectSvr中。
- 在Data状态下,客户端必须对服务器下发的每一个Data进行Ack,并且服务器在下发了Data未收到Ack的这段时间内需关闭Data状态(即在图2的2.7和2.8步骤之间不能再做NotifyData下发)
- 直接推送更加快,但是可能出现乱序和丢失的问题,因此需要严格控制下发body的触发条件
消息模型
- ack的在进入界面,退出界面,在界面停留几秒都会发送ack
私聊
- 私聊以个人维度发号,和tira中的私聊设计类似
- 这样可以很方便做管理(只需要拉一条时间线上的消息)
- 微信这部分的私聊消息很可能压根没有做MQ,估计为了保证不会丢消息,一定是写消息成功落库之后才会返回前端成功.收件箱为了持久化存储,使用的不是redis这种内存数据库,估计是类似leveldb这种
群聊
实际上微信基本上都是用户一个inbox,使得不支持大群,而且不好做已读未读
- 群聊使用群聊收件箱的机制,和help的机制一样,维护群聊收件箱
- 群聊维度使用群维度发号,以群id维度发号,类似读扩散
朋友圈
- 朋友圈使用写扩散,读扩散大概率出现失败导致刷不出来(因为需要从不同的人拉取,跨idc),但是写可以重试写,容错比较高,选择写扩散
- 朋友圈的评论也是后台拉出来然后进行过滤后返回
惊艳设计
如何解决一大堆群聊消息下发浪费带宽
- 采取按需拉取的方法
- 下发的时候只下发id和摘要,,不会直接下发消息体,这个和私聊不一样,私聊可能直接下发消息体,点开之后才会进行拉取
- 消息序列中允许空洞的出现
- 可以向后台请求空洞中的所有消息消除空洞

- 可以向后台请求空洞中的所有消息消除空洞
如何解决群聊的未读消息计算的问题
- 计算在服务器中进行,遇到未读消息修改收件箱的时候顺手给用户未读数加1,进群之后直接清零
如何解决收件箱崩溃问题
- 一旦出现消息过载导致收件箱绷不住了(比如除夕),使用旁路下发的手段
- 旁路下发不需要写收件箱,直接对消息进行二次加密后直接下发到客户端,能极大增加下发速度
- 使用前提:如果副设备最近 72 小时没有登陆过,那么重新登陆时不会同步最近消息。我们只对满足这个要求的用户推送,则用户不会感知消息未被写入收件箱,同时做到削减收件箱读写量的目标。
- 本质上是因为,微信不提供消息的漫游服务,使得无需长期保存消息,app保存的消息列表就是最终的消息列表
飞书IM
收件箱方案

- 采取每个会话有一个收件箱作为存储
- 每个人也有一个收件箱,每个人的收件箱是专门用来接受命令消息的(更新会话,更新成员等 不直接展示在端上的通知)
- 大部分命令消息是不重要的(更新会话,更新成员等,可以通过拉取接口获取最新数据,命令消息只是保证了及时性),都放到单链中会影响正常消息的拉取效率;sdk拉展示10条消息,原先只需要请求一次,现在可能需要多次;
- 命令消息不展示在端上,也不能更新最近会话排序,如果放到单链中无法和普通消息一样通过最近会话version保证消息不丢
- 还有一个最近会话链,记录当前的会话信息的排序

相关方

已读未读
- 每个会话维护每个人的读取进度,其中包括 [startIndex,endIndex] (start是为了处理中间拉人的情况)
- 下拉的时候对比每个人的endindex就可以获取每个人的读取进度
- 这个已读未读的拉取是定时的,而不会已读进行消息的下发,避免写扩散的现象,目前飞书的设计是每隔1s将会话列表中的已读未读拉取一次更行,这个对时效性要求不高
消息属性
- 表情回复这种都属于消息的属性
- 客户端上报表情修改命令消息,服务端读出对应消息,如果是添加,则append用户到对应表情的点赞用户列表中。如果是删除,则从列表中删除该用户
- 服务端更新消息版本号,写回消息内容。
- 服务端写变更操作到会话链,服务端通知会话成员,消息属性变更(推送消息全量属性,避免端上处理复杂和两端不一致)。
- 在线设备收到推送后,如果本地有消息,则处理属性变更命令,覆盖本地的消息属性。如果本地无消息,则直接丢弃该命令(因为后续拉取到该消息时属性一定是全的)
命令消息
- 类似删除会话这种都是命令消息,命令消息单独写入user链中然后进行统一进行下发
- 类似修改message属性的行为都属于命令消息,比如修改内容,表情回复
- 先写入消息体,对消息体直接进行更改,在写入命令消息触发推送逻辑,推送直接全量推送整个消息,为了避免复杂的情况
- 命令消息只使用一次或者少量次数,没必要和单链一起储存,有关命令消息的更改一定是全量拉取之后完全可以忽略的
流程
- 抖音IM和飞书IM核心区别在于响应的返回不一样,抖音IM写入kafka后作为成功直接返回,飞书IM需要落库等一系列操作才返回,只有下发是异步的. 飞书IM主要使用mysql存储,抖音IM主要使用abase存储,tt主要是走的单链写扩散模式
- 因为飞书IM对于发送QPS没有这么大需求(毕竟是企业用户),但是对于数据持久性要求高
- 使用redis的zset存储收件箱
- redis的hash维护每个chat会话的每个人的读取进度(这个也可以用abase)
- 还要存储这个chat最新的messageid
- 存储个人的阅读进度时候存储 nowpos和beginpos(后面这个为了标识后来加群这种操作)
- 再redis使用list+hash维护一条最近对话的链(这个感觉可以用lru类似)
发送
- 发送时候需要生成message_id以及position,position\需要保证绝对递增,目前应该是使用了mysql的事务机制保证绝对递增性质
- 发送时候先开启事务,在mysql记录对话表中将 last_position+1,这里直接采用乐观锁,失败进行重试(失败次数并不多)
- 插入message表格中(携带position,messageid),position因为绝对递增性,用于不适合用于直接作为messageid
- 端上拉取的时候可以直接根据下发的position判断是否连续以及是否存在空洞
拉取
- 拉取的时候先拉去最近对话的链条(拿到所有的chatid)
- 根据所有的chatid拉取所有所有的chat的读取进度,并且找到自己的读取进度,和判断自己是否存在未读消息
- 将大于本地的id都拉下来,根据自己的进度作为未读计算
- 以及拉取命令消息的收件箱,如果存在就执行,不存在就直接放弃(因为下次拉肯定是最新的)
- 如果是新启动的app(完全没有原始数据),这个时候不需要拉命令消息,因为所有数据都是最新的,直接那最新的命令消息id作为localid
- 如果是有数据的app打开需要根据localid拉取消息(因为不会进行全量拉取,需要进行回放)
- 每隔几s拉取所有chat的读取进度,并且计算已读未读的现实
- 读取之后可以出发更新操作,更新自己的已读的nowpos(这个可以离开chat触发,也可以定时触发)
- 在线推送的时候直接推送消息体,如果qps流量太大触发降级就改为推ID,再上行拉.如果出现空洞(每个消息会携带上一个消息的ID,通过mysql事务性获取chat上一条消息的ID获得,这里依赖消息id的连续递增性或者直接从mysql获取自增id下发,即对mysql中chat的信息进行CAS交换,拿到上一条信息并且把下一条改成自己的)就进行补偿拉取(拉取空洞的内容)
- 这里考虑messageid和index完全可以不需要一直,只要保证messageid完全的递增性就行,这里也可以和插入mysql body作为一个事物去执行
- 直接根据index进行拉取,但是redis还需需要保存index到messageid的映射关系,好处是客户端完全可以根据index是否连续直接判断是否有空缺,可以直接下发消息body
存储
- message实体储存到message_entity 表中.表格使用chatid进行分表(这个就是会话的id)
- 使用abase kv数据库存储 messageid到chatid的关系
- 使用一张mysql表记录chat(会话)的信息(比如最后一个messageid等)
- redis作为zset缓存inbox和message body缓存
数据同步
- 抖音的IM通过 kafka进行数据同步,直接将其重放到不同地区,保证数据一致性
- 飞书的IM根据用户确定选择机房,无论在哪里最后的请求都回到原地的机房(比较慢)
- 即时通讯网 - 即时通讯开发者社区!这个IM网站非常不错,推荐