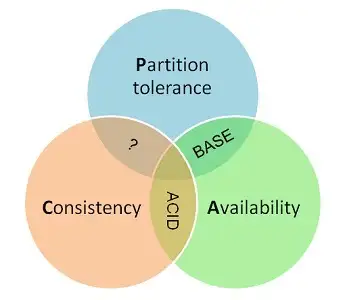
CAP理论
C - Consistency 一致性
- 一致性是指写操作后的读操作可以读取到最新的数据状态,当数据分布在多个节点上,从任意结点读取到的数据都是最新的状态。
A - Availability 可用性
- 可用性是指任何事务操作都可以得到响应结果,且不会出现响应超时或响应错误。
- 所有请求都有响应,且不会出现响应超时或响应错误
P - Partition tolerance 分区容忍性
- 通常分布式系统的各各结点部署在不同的子网,这就是网络分区,不可避免的会出现由于网络问题而导致结点之间通信失败,此时仍可对外提供服务,这叫分区容忍性。
- 分区容忍性分是布式系统具备的基本能力(分布式要解决的问题之一就是单点故障,因此这个不可或缺)
结论
- 在所有分布式事务场景中不会同时具备 CAP 三个特性,因为在具备了P的前提下C和A是不能共存的

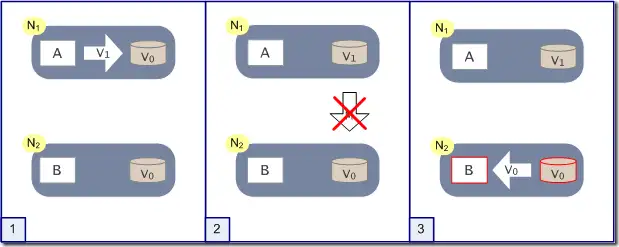
证明
- A发消息使得N1的val变为V1,但是由于网络问题(属于P的需求),V1无法通知N2的val
- 此时B对N2的val进行访问,现在B有两种选择
- 返回旧结果给B,等网络恢复再进行更新(放弃一致性,返回旧结果,AP)
- 等待网络恢复,拒绝马上返回结果(放弃可用性,CP)
- 因此系统无法做到同时具备CAP三个特性
设计
CA
- 放弃分区容忍性,即不进行分区,不考虑由于网络不通或结点挂掉的问题,则可以实现一致性和可用性。那么系统将不是一个标准的分布式系统,最常用的关系型数据就满足了CA,日常一般使用的都是CA(即非分布式系统)
AP
- 放弃一致性,追求分区容忍性和可用性.要求系统返回的结果不一定是最新的.一般用于实时性要求不这么高的场景,比如退款之类,保证最终一致性,类似消息队列的无限重试就是这个(保证一定执行,但不保证马上执行),分布式事务常用这个
CP
- 放弃可用性,追求一致性和分区容错性,zookeeper和etcd(raft)其实就是追求的强一致,用于一致性要求很高的场所(银行之间的转账),就是很多时候宣传的高可用性(因为无法到达100%)或者强一致性都是这个体系
示例
A给B转账,事务1:扣A钱,事务2:加B钱 CA解决方案: 放在同一个系统,用mysql事务保证CA 就是单体结构 AP解决方案: 1成功后,如果2不成功,那么把2扔到消息队列无限重试(也可以是其他的办法),这期间,A和B都可以该操作账户(只是数据未必真实) CP解决方案: 1成功后,2不成功的话,A和B账户因为事务并没有成功出现不可用的情况,只有等到结束才能拿到数据(此时数据真实,但是中间时间不可用)
分布式事务问题
- 因为cap存在使得系统无法也不可能达到100%可用性,无法满足事务的ACID的基本要求
分布式事务解决方案
2PC两阶段提交
[!NOTE] 在mysql中这部分的是通过XA协议进行交互的
步骤
- 准备阶段(Prepare phase):事务管理器给每个参与者发送 Prepare 消息,每个数据库参与者在本地执行事务,并写本地的undo/redo日志,此时事务没有提交。此时mysql事务对所需资源自动进行上锁
- 提交阶段(commit phase):如果事务管理器收到了参与者的执行失败或者超时消息时,直接给每个参与者发送回滚(Rollback)消息;否则,发送提交(Commit)消息;参与者根据事务管理器的指令执行提交或者回滚操作,并释放事务处理过程中使用的锁资源.必须在最后阶段释放锁资源。
缺点
- 一旦事务多起来,到处都是mysql预留的资源锁(prepare这部分实际上通过mysql的事务实现),损耗性能
- 代码侵入度大,不利于代码维护
Seata
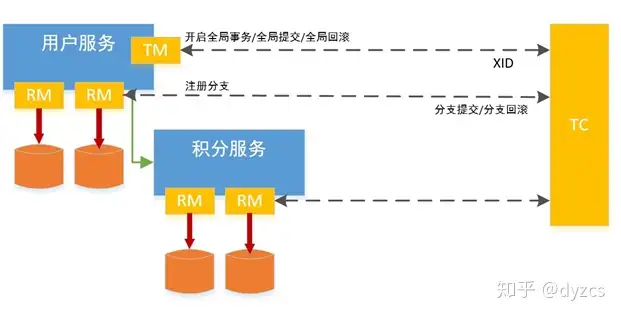
区别
- 将数据库层面的业务剥离到额外的业务层面,业务代码入侵度小
- 一阶段直接提交事物,通过锁和补偿性提交避免脏读问题,性能更加好
TCC
TCC 是 Try、Confirm、Cancel 三个词语的缩写
步骤
- Try,首先预留资源,比如在数据库资源的status修改使其不能被其他事务使用,如果出错直接跳到Cancel取消资源的预留(修改status成为可使用)O
- Confirm,提交事务,通常情况下,采用TCC则认为 Confirm 阶段是不会出错的。即只要Try成功,Confirm一定成功,如果不成功需要重试或者人工.
- Cancel,取消事务,如果try失败,直接cancel.默认认为TCC的cancel阶段不会出问题,出问题需要重试或者人工
优点
- 通过状态取代事物,相当于乐观锁取代悲观锁,进一步提升性能,两阶段变为三阶段,在应用层面解决
缺点
- 代码入侵性强,实现难度大
- 状态复杂,需要实现不同的回滚策略
可靠消息一致性
- 如何保证事务的消息传递出去,以异步的方式完成交易
- 解决因为重复导致的幂等性问题
本地消息表
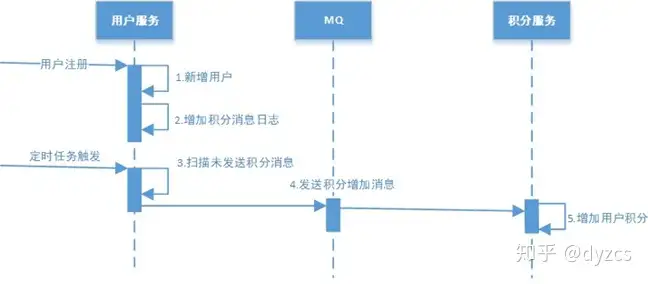
- 先在自己的表存储消息,然后把消息扔到MQ中,等待MQ重试发送消息,回ACK就不再发,基于MQ保证至少被消费一次,如果MQ反馈成功就删掉记录,否则一直定时发
最大努力通知
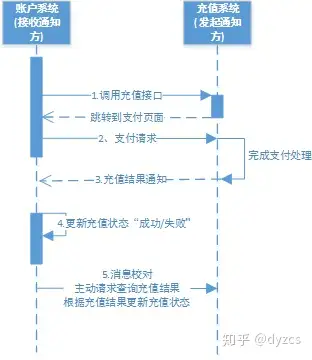
- 发起通知方通过一定的机制最大努力将业务处理结果通知到接收方。
- 一定的消息通知重试机制(基于MQ)
- 消息校验机制,消费者自己向生产者索取
总结
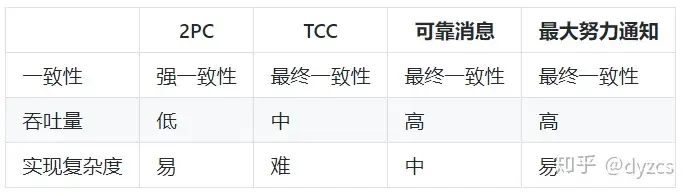
- 2PC 阻塞协议,很难用于并发较高以及子事务生命周期较长(long-running transactions) 的分布式服务中。
- TCC 在应用层面实现,可以用于支付,转账的高性能和一致性场所
- 可靠消息 适合执行周期长且实时性要求不高的场景,避免了同步阻塞的操作
- 最大努力通知 是分布式事务中要求最低的一种,适用于一些最终一致性时间敏感度低的业务(比如支付成功通知等)
微信支付
- 使用两阶段提交+MQ事务的方法保证最终一致性,分为主事务和从事务,主事务成功后,不停尝试执行从事务
- 如果是面对面转账这种强一致性的多主事务,需要使用mysql的事务机制,加上TCC的机制
- 如果为代扣的这种事务就是先创单(主事务),然后延迟打钱(从事务)
事件中心
- 底层是消息队列

- 解耦,就是对事务分主次:
- 主事务一般是核心逻辑,逻辑重,同步调用;
- 从事务一般是次要逻辑,逻辑轻,异步调用。
- 第一阶段是prepare,将消息暂存到事件中心,但是不发布,等待二次确认;prepare后,业务执行主事务(一般是rpc远程调用),成功就发commit给事件中心,投递消息到从事务;失败就发rollback给事件中心,不做投递。
- 这里需要两阶段提交的原因是:我们常规理解的入队操作,也就是一阶段提交,无论是放在主事务执行前,还执行后,都无法保证最终一致。考虑如下场景
如果是先做主事务,再入队,那可能入队前就宕机了; 如果是先入队再做主事务,那可能主事务没做成功,但从事务做成功了。
- 所以无论哪种做法都有问题,二阶段提交是必须的。
反查
- 如果prepare后没有进行commit或者rollback(消息丢失或者系统重启),事件中心就会主动下发消息询问主事务执行的结果
普通消息
- 普通消息直接通过事务中心执行所有事务
- 两个必须要用事务消息的场景:
第一是事务逻辑复杂,也就是发生逻辑失败的概率大,比如扣款前要检查余额是否足够,如果余额不足,那在异步流程中重试多少次都是失败。
第二是事务不可重入,例如业务系统入队时并未确定一个唯一事务ID,那各事务就无法保证幂等,假设如果其中一个事务是创建订单,不能保证幂等的话,重试多次就会产生多个订单;所以这里需要用事务消息,明确一个分布式事务的开始,生成一个唯一事务ID,让各个事务能以这个事务ID来保证幂等。
事件中心设计
- 事件中心的本质是队列驱动事务,所以要满足常见的队列功能,比如多订阅、出队有序、限速、重试等等
- 订阅者用于执行从事务

- Producer是发布者,Consumer是消费者,Consumer用推模式将消息推给Subscriber订阅者,这都是比较好理解的。然后来看Store,队列存储Store的实现选择了Paxos,是因为Paxos能保证副本一致,可避免乱序/去重问题,非常适合队列模型。Paxos协议的正确运行需要同步刷盘,副本同步数3份,这能提高数据可靠性。朴素Paxos的性能不是很好,所以通过批量提交的方式保证写入性能。
- 接着来看Scheduler,Scheduler是Consumer的协调者,通过与Consumer维持心跳,定义Consumer的生死,实现容灾;同时收集Consumer负载信息,实现负载均衡。Sched还依赖分布式锁Lock来选举master,只有master提供服务,自然实现容灾和服务一致性。
- 最后来看Lock,Lock是一个分布式锁,不仅用来给Scheduler选master,他还服务于Consumer,防止负载均衡流程中多个消费者同时处理一条队列。
- 这里Consumer的负载均衡流程也是一个二阶段提交,第一阶段是Consumer先跟Scheduler确定自己该处理哪些队列,第二阶段是访问Lock对队列抢锁,只有抢到锁后才能开始处理。
- kv查无记录时反查业务。只有确认commit,Consumer才会投递消息给订阅者。

多个主事务
-
类似TCC的机制,预锁资源的方法
这里也可以通过补偿的方式,但是中间态会短暂暴露
-
事务预写的具体做法是,将主事务1中会导致逻辑失败的部分,提前到prepare前执行,从而减少prepare...commit/rollback之间的事务个数。主事务1的执行结果在提交前并不对外可见,所以即使该结果不回滚,也不破坏一致性。与TCC中的Try操作类似。

优缺点
优点
- 减低耦合度和业务入侵性,相当与把本地的事务表存储在MQ中
- 吞吐量大,不会涉及2pc的阻塞问题
缺点
- 从事务默认可以通过重试成功(因为没有提供主事务补偿的机制),导致不能覆盖所有应用场景
- 需要提供反查的接口,增加复杂度
参考
- https://zhuanlan.zhihu.com/p/263555694
- https://www.cnblogs.com/cbvlog/p/15458737.html