分布式总览
分布式核心
- 核心就是所有的中心化,单体的所有架构都会出现明显的中心故障的问题,导致可用性下降的问题,去中心化是分布式的核心思想
保证高可用性的方法
1. 解耦
- 使得就算一个程序panic,不会影响其他的程序,微服务框架 > svrkit
2. 隔离
- 解耦的目的就是为了隔离,避免出现一个panic所有都panic的问题
3. 异步
- 削峰,避免大流量导致雪崩,消息队列
4. 备份
- 容灾策略,避免出现机房着火数据丢失,类似分布式架构 > GFS
- 微信使用的是分布式数据库(leveldb+类raft)
5. 重试
- 需要有可用性就必须有重试,因为分布式架构下,网络波动是不可避免的,这又牵扯到幂等性的处理
6. 熔断
- 保护机制,避免因为一个微服务不可用导致整条链路故障,熔断通常伴随着降级,因为不能访问了
7. 补偿
- 分布式事务情况下,类似兜底办法,容许错误
8. 限流
- 保护机制,避免服务过载导致雪崩,限流算法 > 微信过载保护
9. 降级
- 保护机制,服务降级,将有限的资源用在更加紧急的地方
10. 多活
- 容灾策略,一般通过两地三机房,同时配上负载均衡,避免崩了一个业务不可用
mit6.824
MapReduce
- 主要解决分布式计算的问题
- 通过一个中心化的MapReduce程序分配map任务和Reduce
流程

- MapReduce 框架首先将输入文件划分为 M 片,每片通常为 16MB 到 64MB 大小。随后会启动集群中的机器(进程)。
- 集群中的一个进程是一个特殊的 master 进程。剩余的 worker 进程都由 master 分配任务。一共有 M 个 map 任务和 R 个 reduce 任务需要分配。master 会挑选空闲的 worker,一次分配一个 map 任务或者一个 reduce 任务。
- 被分配到 map 任务的 worker 读入对应分片的输入,从输入中解析出键值对,并分别将其传给用户定义的 map 函数。map 函数返回的中间键值对会被暂时缓存在内存里。
- worker 内存中缓存的键值对,会被分片函数分成 R 个分片,并周期性地写进本地磁盘。这些键值对在磁盘上的位置会被发生给 master,master 负责将位置发送给被分配到 reduce 任务的 worker。
- 当一个 reduce worker 接收到 master 发送的这些位置,它会向保存这些内容的 map worker 发送 RPC 请求来读取这些内容。当一个 reducer worker 读取完所有的中间数据,就会将其根据 key 进行排序,这样所有相同 key 的数据就会聚合在一起。这种排序是必要的,因为通常许多不同的 key 会由同一个 reduce 任务处理。如果数据过大,可能会使用外部排序。
- reduce worker 遍历有序的中间数据,对遇到的所有 key,都会将 key 和对应的值集合传给用户定义的 reduce 函数。reduce 函数的输出会被追加到一个最终的输出文件(每个 reduce 分片一个)。
- 当所有的 map 任务和 reduce 任务都完成后,MapReduce 的任务也就完成了。
GFS
- 一个 GFS 集群还包括一个 Master 节点和若干个 Chunk Server
- 主要负载为大容量连续读、小容量随机读以及追加式的连续写
- Chunk Server储存数据的分片(64MB为一片),每个文件对应的chunk和对应的偏移量由master储存
- 读取文件中的内容或者追加写入都是通过Chunk,Chunk通过又备份,多个备份之间有一个主的备份(Primary),这个Chunk Server负责写入,和master维护租约(60s)
- master负责管理和存储chunk数据,在对数据进行操作之前都会写日志
- 文件与 Chunk 的 Namespace
- 文件与 Chunk 之间的映射关系
- 每个 Chunk Replica 所在的位置
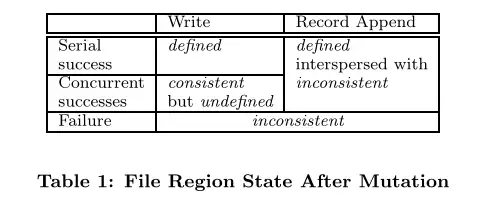
数据一致性
- 如果一次写入操作成功且没有与其他并发的写入操作发生重叠,那这部分的文件是确定的(同时也是一致的)
- 如果有若干个写入操作并发地执行成功,那么这部分文件会是一致的但会是不确定的:在这种情况下,客户端所能看到的数据通常不能直接体现出其中的任何一次修改
- 失败的写入操作会让文件进入不一致的状态
数据更改
覆写
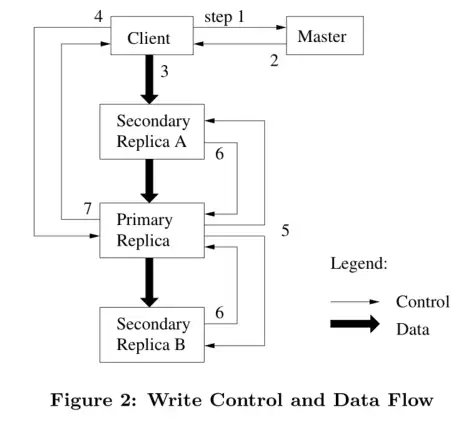
- 客户端向 Master 询问目前哪个 Chunk Server 持有该 Chunk 的 Lease
- Master 向客户端返回 Primary 和其他 Replica 的位置(master只负责帮客户端发现Chunk server)
- 客户端将数据推送到所有的 Replica 上。Chunk Server 会把这些数据保存在缓冲区中,等待使用
- 待所有 Replica 都接收到数据后,客户端发送写请求给 Primary。Primary 为来自各个客户端的修改操作安排连续的执行序列号,并按顺序地应用于其本地存储的数据
- Primary 将写请求转发给其他 Secondary Replica,Replica 们按照相同的顺序应用这些修改
- Secondary Replica 响应 Primary,示意自己已经完成操作
- Primary 响应客户端,并返回该过程中发生的错误(若有)
追加
- 客户端将数据推送到每个 Replica,然后将请求发往 Primary
- Primary 首先判断将数据追加到该块后是否会令块的大小超过上限:如果是,那么 Primary 会为该块写入填充至其大小达到上限,并通知其他 Replica 执行相同的操作,再响应客户端,通知其应在下一个块上重试该操作
- 如果数据能够被放入到当前块中,那么 Primary 会把数据追加到自己的 Replica 中,拿到追加成功返回的偏移值,然后通知其他 Replica 将数据写入到该偏移位置中
- 最后 Primary 再响应客户端
- 当追加操作在部分 Replica 上执行失败时,Primary 会响应客户端,通知它此次操作已失败,客户端便会重试该操作。和写入操作的情形相同,此时已有部分 Replica 顺利写入这些数据,重新进行数据追加便会导致这一部分的 Replica 上出现重复数据,不过 GFS 的一致性模型也确实并未保证每个 Replica 都会是完全一致的。
- GFS 只确保数据会以一个原子的整体被追加到文件中至少一次。由此我们可以得出,当追加操作成功时,数据必然已被写入到所有 Replica 的相同偏移位置上,且每个 Replica 的长度都至少超出此次追加的记录的尾部,下一次的追加操作必然会被分配一个比该值更大的偏移值,或是被分配到另一个新的块上。
快照
- 快照操作的实现采用了写时复制(Copy on Write)的思想:
- 在 Master 接收到快照请求后,它首先会撤回这些 Chunk 的 Lease,以让接下来其他客户端对这些 Chunk 进行写入时都会需要请求 Master 获知 Primary 的位置,Master 便可利用这个机会创建新的 Chunk
- 当 Chunk Lease 撤回或失效后,Master 会先写入日志,然后对自己管理的命名空间进行复制操作,复制产生的新记录指向原本的 Chunk
- 当有客户端尝试对这些 Chunk 进行写入时,Master 会注意到这个 Chunk 的引用计数大于 1。此时,Master 会为即将产生的新 Chunk 生成一个 Handle,然后通知所有持有这些 Chunk 的 Chunk Server 在本地复制出一个新的 Chunk,应用上新的 Handle,然后再返回给客户端
删除
- 当用户删除某个文件时,GFS 不会从 Namespace 中直接移除该文件的记录,而是将该文件重命名为另一个隐藏的名称,并带上删除时的时间戳。在 Master 周期扫描 Namespace 时,它会发现那些已被“删除”较长时间,如三天,的文件,这时候 Master 才会真正地将其从 Namespace 中移除。在文件被彻底从 Namespace 删除前,客户端仍然可以利用这个重命名后的隐藏名称读取该文件,甚至再次将其重命名以撤销删除操作。
- Master 在元数据中有维持文件与 Chunk 之间的映射关系:当 Namespace 中的文件被移除后,对应 Chunk 的引用计数便自动减 1。同样是在 Master 周期扫描元数据的过程中,Master 会发现引用计数已为 0 的 Chunk,此时 Master 便会从自己的内存中移除与这些 Chunk 有关的元数据。在 Chunk Server 和 Master 进行的周期心跳通信中,Chunk Server 会汇报自己所持有的 Chunk Replica,此时 Master 便会告知 Chunk Server 哪些 Chunk 已不存在于元数据中,Chunk Server 则可自行移除对应的 Replica。
优点
- 更加可靠,因为可能存在部分chunk server上的数据master未知,如果master下发命令删除,可能删不干净,由chunk自己进行汇报删除更加可靠
- 周期扫描和删除数据结合,减少资源损耗
- 避免误操作
高可用保证
- Master 会为每个 Chunk 维持一个版本号,以区分正常的和过期的 Replica。每当 Master 将 Chunk Lease 分配给一个 Chunk Server 时,Master 便会提高 Chunk 的版本号,并通知其他最新的 Replica 更新自己的版本号。如果此时有 Chunk Server 失效了,那么它上面的 Replica 的版本号就不会变化。
- Chunk Server 重启时,Chunk Server 会向 Master 汇报自己所持有的 Chunk Replica 及对应的版本号。如果 Master 发现某个 Replica 版本号过低,便会认为这个 Replica 不存在,如此一来这个过期的 Replica 便会在下一次的 Replica 回收过程中被移除。除外,Master 向客户端返回 Replica 位置信息时也会返回 Chunk 当前的版本号
Raft
前提
- 至少一半的机器运行正常
- 广播时间需要<<选举超时时间<<平均故障时间
- 非拜占庭情况下
状态机复制
- 底层是状态机的复制,同一个系统,相同的输入之后得到的状态是相同的
状态转换
- 所有的机器只会是leader(领导者),candidate(候选人),follower(跟随者)
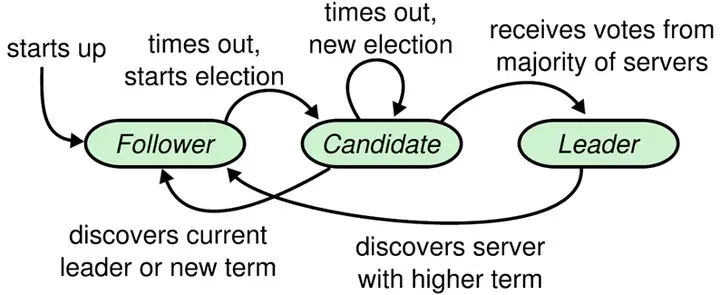
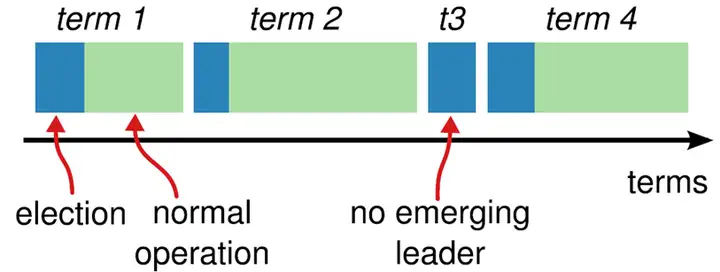
- Raft算法将时间分为一个个的任期(term),每一个term的开始都是Leader选举。在成功选举Leader之后,Leader会在整个term内管理整个集群。如果Leader选举失败,该term就会因为没有Leader而结束。
- 只存在两种RPC
- RequestVote RPC : candidate发起,请求投票
- AppendEntries RPC : leader复制日志和心跳保活
- 通讯会交换任期号,如果是follwer发现自己的任期比较小,那么会切换到大的任期号,如果是其他两种发现,会切换为follower
- 节点忽略过期任期号的请求(比如刚复活的进行选举,会选举失败)
领导者选举
- 心跳机制,leader向follower发送心跳包(携带任期号),超过最大时间follower发现没收到心跳之后
- 增大自己的任期号
- 切换为candidate状态,投票给自己,发送RequestVote给其他机器
- 结果三种可能
- 超过半数选票成为leader
- 其他赢了,标志为收到其他leader的心跳包,新leader任期不小于自己的任期号
- 没人获胜,重新选举
- 为了公平和防止进入死循环,选举超时时间会进行随机化(从发现leader没发心跳包,到成为candidate发送rpc的时间随机化)
RequestVote RPC内容
被候选者用来收集选票:
Arguments:
term 候选者的任期
candidateId 候选者编号
lastLogIndex 候选者最后一条日志记录的索引
lastLogItem 候选者最后一条日志记录的索引的任期
Results:
term 当前任期,候选者用来更新自己
voteGranted 如果自己将票投给候选人则为 true。
接受者的实现:
1. 如果 leader 的任期小于自己的任期返回 false。(5.1)
2. 如果本地 voteFor 为空,候选者
日志复制
- 只有leader具有写的权限(即向日志中附加条目),follower的写请求都会重定向到leader
AppendEntries RPC 内容
被 leader 用来复制日志,同时也被用作心跳
Arguments:
term leader 任期
leaderId 用来 follower 重定向到 leader
prevLogIndex 前继日志记录的索引
prevLogItem 前继日志的任期
entries[] 存储日志记录
leaderCommit leader 的 commitIndex
Results:
term 当前任期,leader 用来更新自己
success 如果 follower 包含索引为 prevLogIndex 和任期为
prevLogItem 的日志
接受者的实现:
1. 如果 leader 的任期小于自己的任期返回 false。(5.1)
2. 如果自己不存在索引、任期和 prevLogIndex、prevLogItem
匹配的日志返回 false。(5.3)
3. 如果存在一条日志索引和 prevLogIndex 相等,
但是任期和 prevLogItem 不相同的日志,
需要删除这条日志及所有后继日志。(5.3)
4. 如果 leader 复制的日志本地没有,则直接追加存储。
5. 如果 leaderCommit>commitIndex,
设置本地 commitIndex 为 leaderCommit 和最新日志索引中
较小的一个。
- 只有日志号和任期号才能唯一确定一个日志
日志有两种状态,生成和提交,提交之后不可撤回,只有半数以上节点ack,日志才会变为提交,只有leader同意,follower才能提交,没有生成的日志有可能被替代
- 具体流程
- leader接受到写请求,将日志通过rpc复制到所有的follower中
- 等待超过半数的follower复制成功并且返回ack(就是下一个心跳包)之后,leader会提交日志到版本库,并且返回应用层成功的消息
- leader告诉所有的follower让他们提交
- follower提交
follower宕机
- 如果follower没有响应,leader会不断进行重发到该follower尝试
- follower回复之后会进行一致性检查恢复缺失的日志
当发送一个 AppendEntries RPC 时,Leader会把新日志条目紧接着之前的条目的log index和term都包含在里面。如果Follower没有在它的日志中找到log index和term都相同的日志,它就会拒绝新的日志条目。
leader宕机
- 如果宕机的leader还有日志未提交,那么可能出现其他leader强制性覆盖旧leader未提交的数据
安全性
投票
- 如果投票者手上的日志信息比candidate还新,就会拒绝该请求
相同任期比日志号,不同任期比任期号,日志号不是提交了的日志号,而是存在的日志号码(没有提交的也算)
日志
- leader只会对自己的任期内的日志计算副本数目的提交,上一个任期内的日志不会被马上提交,只有自己产生了新日志才会进行统一提交
成员变更
联合一致
- 采用两阶段的方法避免脑裂问题
- leader发起rpc请求,使整个集群进入联合一致的状态,此时rpc在新旧两个配置都要达到大多数才算成功
- leader发起rpc,整个集群进入新配置状态,能达到大多数就算成功,在新增节点时,需要等待新增的节点完成日志同步才开始成员变更
- 复杂,使用较少
单节点变更
- 完成增加节点的日志同步
- leader发送rpc请求,等待大多数之后就可以提交标识成功
数据读写
- 写请求统一发送到leader
- 读请求到了 follower 后,follower会去向 leader 请求 readindex(也就是当时 leader 的 commitindex), leader 在确认自己还是 leader 之后,就会吧 readindex 发给 follower,follower 会对比自己的 commitindex 和 readindex,只有commitindex 大于等于 readindex 之后,才能读取数据返回.
ETCD
- etcd 就是底层使用raft实现的一个kv类型的数据库,可以保证强一致性,属于CP类型的数据库
参考
- https://raft.github.io/
- https://zhuanlan.zhihu.com/p/32052223
参考
- https://zhuanlan.zhihu.com/p/33944479
- https://pdos.csail.mit.edu/6.824/schedule.html