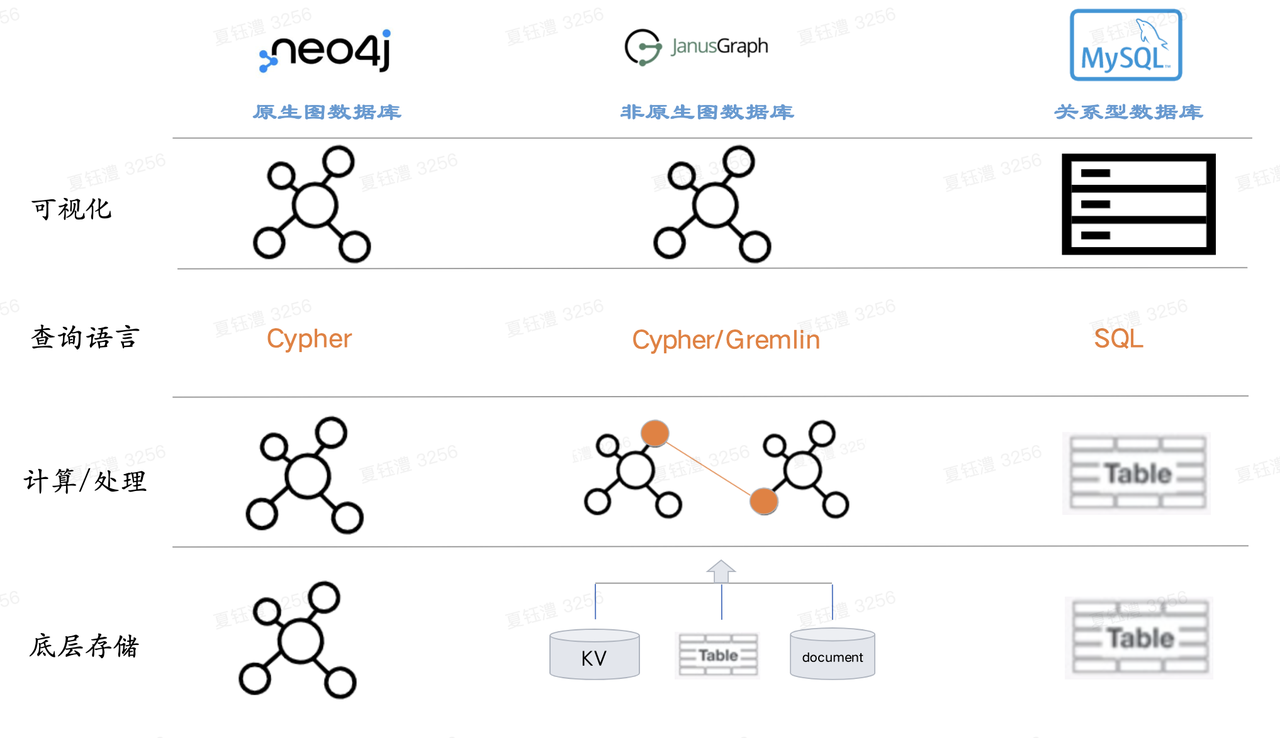
本质上就是图数据库的底层原理,和neo4j同类型的数据库
存储
方法
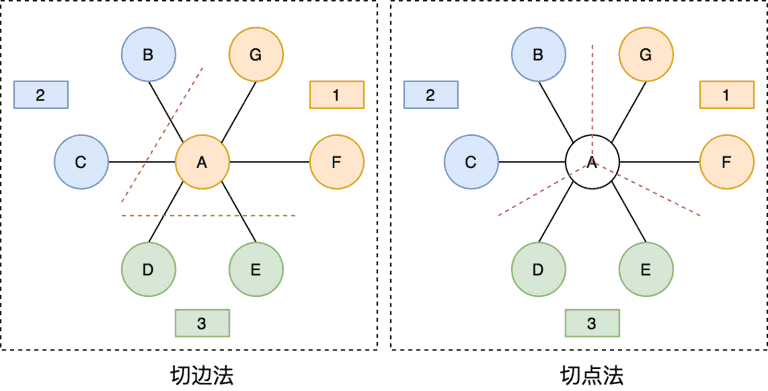
- 切边法:每个顶点都存储一次,但是有的边会被打断分到两台机器上。这样做的好处是节省存储空间;坏处是对图进行基于边的计算时,对于一条两个顶点被分到不同机器上的边来说,需要跨机器通信传输数据,内网通信流量大(因为查询的时候跨机房大量查询边。
- 切点法:每条边只存储一次,都只会出现在一台机器上。邻居多的点会被复制到多台机器上,增加了存储开销,同时会引发数据同步问题。好处是可以大幅减少内网通信量。
- neo4j和 ByteGraph 使用的都点是切点法
- 两种存储计算模式「原生图」和「非原生图」
- 底层的数据存储格式是否Graph-like,简而言之即以图的形式存储图,Native Storage通过将节点和关系写入到“相近”的位置来保证高效地存储,而使用外部存储时(如:外部的DB)认为是Non-Native。
- ByteGraph目前是典型的依赖于KV(ABase/ByteKV)的 非原生图 数据库
文件
- neostore.nodestore.db:存储 node
- neostore.propertystore.db:存储属性
- neostore.relationshipstore.db:存储关系
- 节点作为node,node之间的关系使用
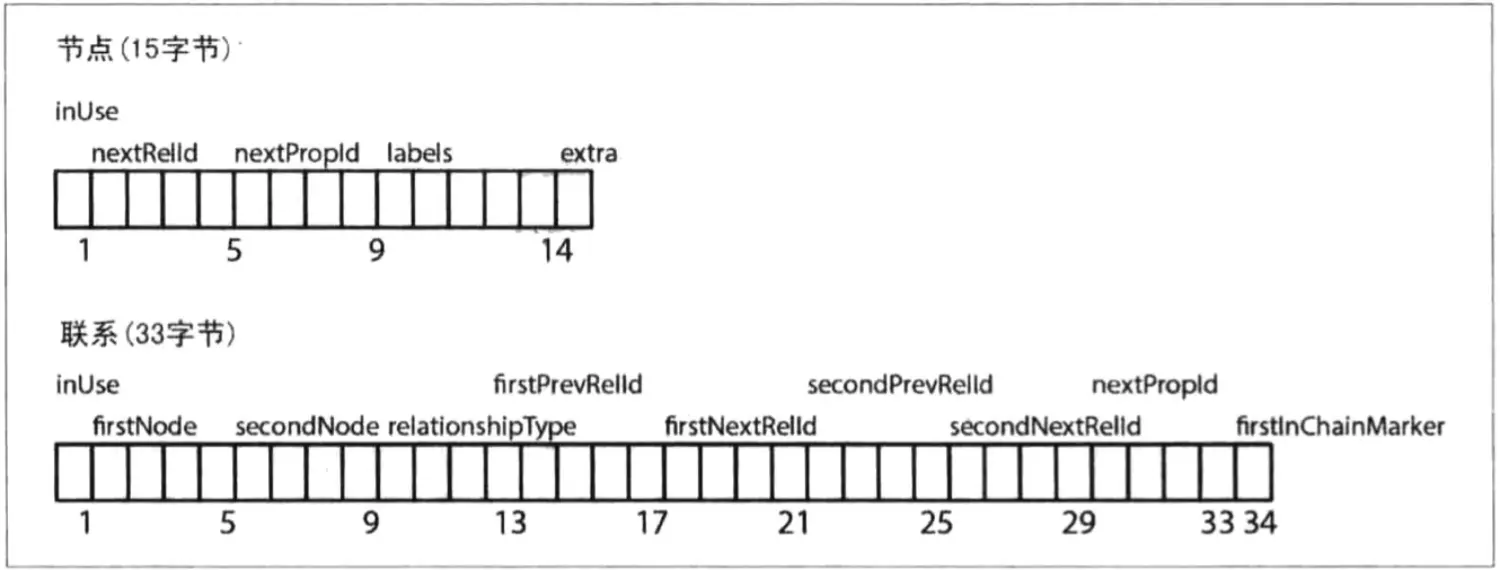
- 1byte:in-use flag,表明该 node 是否在使用
- 4byte:第一个 relation id(-1表示无)
- 4byte:第一个 property id(-1表示无)
- 5byte:label 信息(可能直接 inline 存储)
- 1byte:reversed
- 节点(指向联系和属性的单向链表,neostore.nodestore.db):第一个字节,表示是否被使用的标志位,后面4个字节,代表关联到这个节点的第一个关系的ID,再接着的4个字符,代表第一个属性ID,后面紧接着的5个字符是代表当前节点的标签,指向该节点的标签存储,最后一个字符作为保留位 .
- 关系(双向链表,neostore.relationshipstore.db):第一个字节,表示是否被使用的标志位,后面4个字节,代表起始节点的ID,再接着的4个字符,代表结束个节点的ID,然后是关系类型占用5个字节,然后依次接着是起始节点的上下联系和结束节点的上下节点,以及一个指示当前记录是否位于联系链的最前面.
- 节点中存储了关系开始的id 和属性开始的id,因为是定长存储,根据id可以直接拿到地址,相当于O(1),再根据关系的双向链表查到所有有关这个点的所有边
- 其实最大的区别在于 图数据库查关系是直接使用广度有限搜索算法的,可以根据id直接定位开始的edge,根据双向链表直接定位到所有的egde,不需要像关系型数据库慢慢查,这点的优势直接体现在可以简单直接找到关注的关系以及共同关注之类的需求
- 属性边和点都是分开存储的,因为定长存储,存储的是id,可以直接根据id算偏移,直接拿到数值点
架构
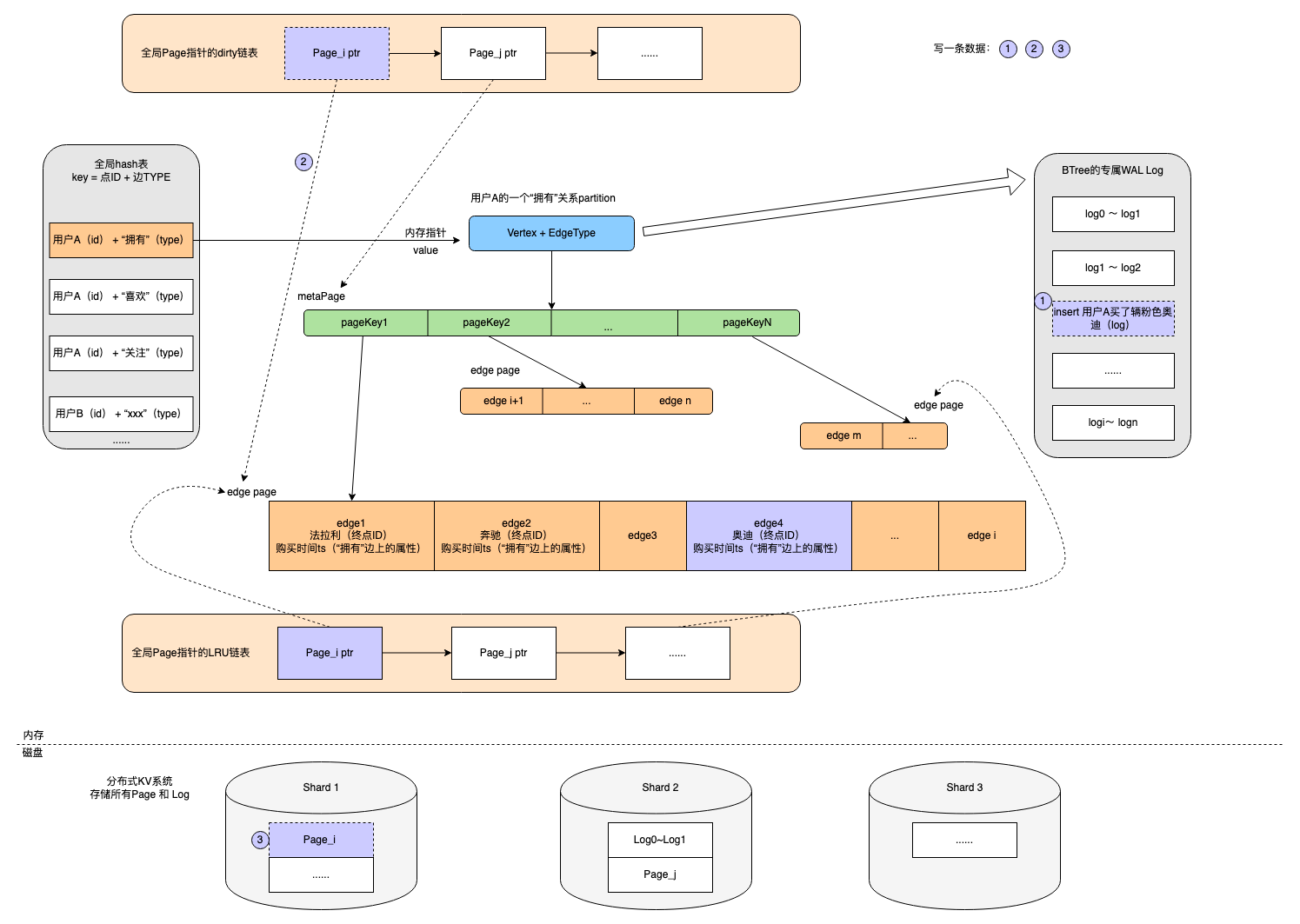
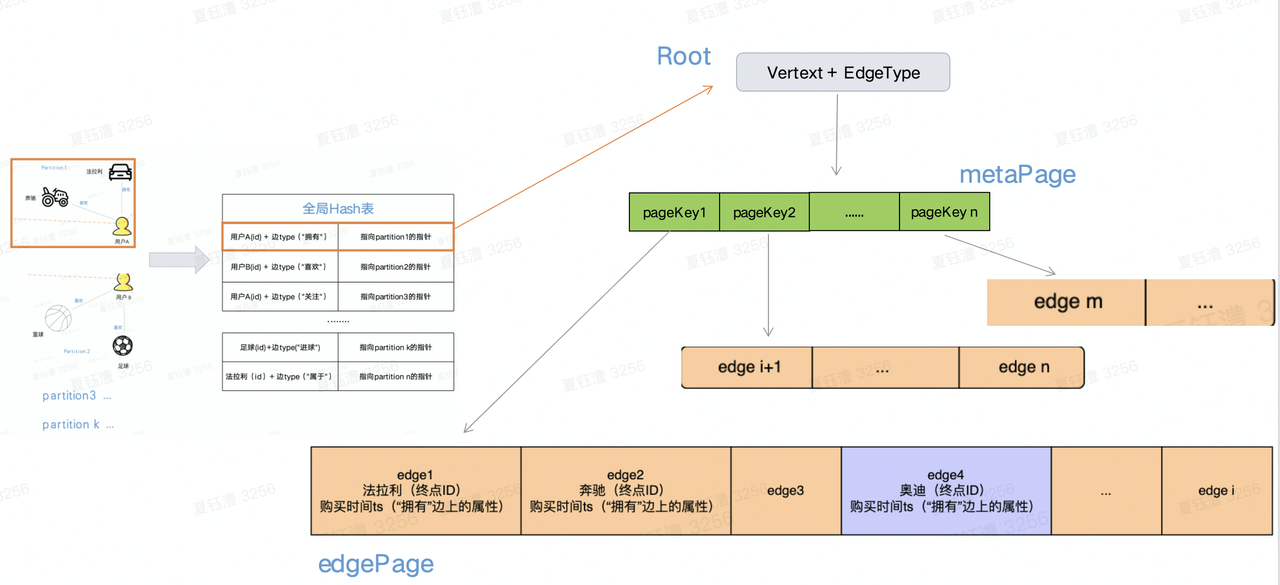
- ByteGraph采用切点法划分出不同的partition,一个partition包含一个起点+所有同类项的出边(包括边属性和终点)。目前BG将起点ID做hash,将不同partition存储在不同的GS节点中。
- 全局hash表
- key可以理解为顶点ID+边类型构成的一个唯一值,value则指向一个partition,实现了确定某个点后快速检索定位对应partition的能力。(因为日使用点切法,同一个点多个 partition,只能使用点+edge属性作为key,相同属性的边存储在同一个partition)
- 节点全局hash表(每个GS实例一份),由于采用「点切法」的原因,点的相关属性信息不可避免的被冗余到不同的「partition」中,为了减少冗余,图中所有点相关信息采用一份全局存储,各个「partition」中仅仅记录点的ID
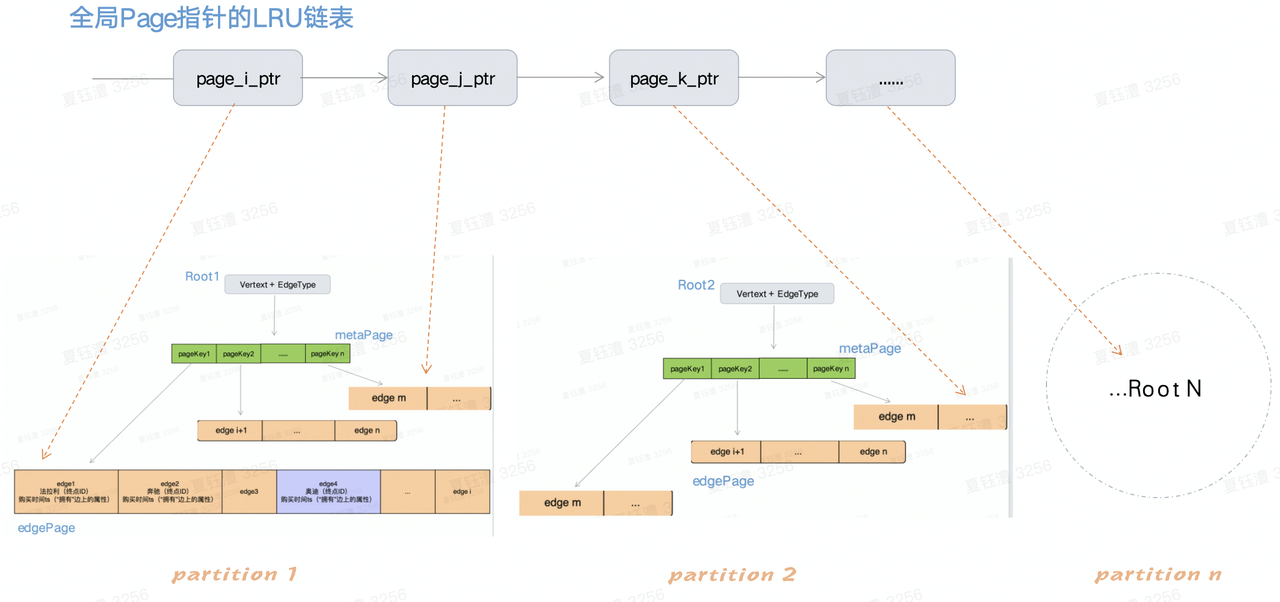
- 在内存中,partition被组织为BTree模式,其中Btree的根节点和叶子节点在内存中被组织为Page的模式(这里使用btree的原因是不可能能一次拿到包含所有edge的内存拿来一次新存放,太大了,通过组织Btree来进行索引),具体包括以下page:
- metaPage:非叶子节点,存储指向子节点的内存指针,作为BTree的索引节点
- 叶子节点,存储边数据(终点ID+边上的属性),每个page存储边的数量可供配置
- 全局LRU链表中存放指向Page的指针,Page分布于每一个partition的Btree结构中。其中Page按需加载到内存,全局LRU链表对解决数据的冷热沉降非常实用。非热点数据直接存放于磁盘,热点数据常驻内存。
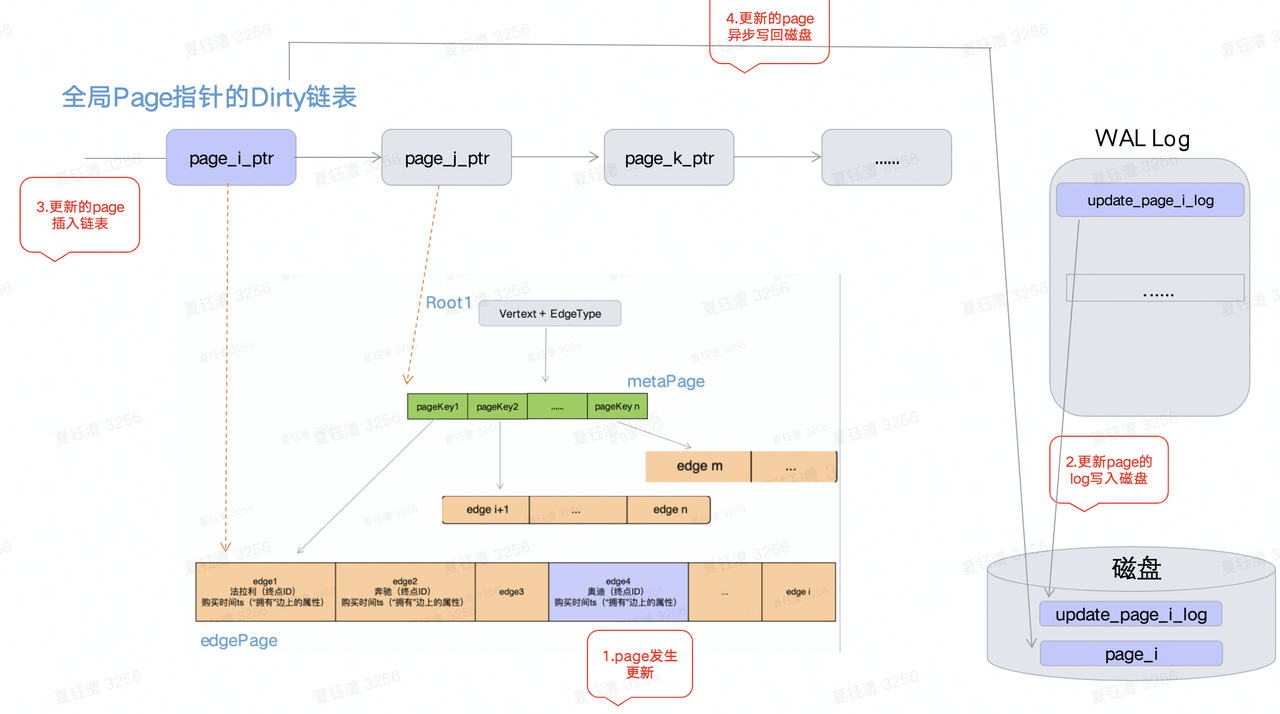
- 全局dirty链表
- dirty链表中存放的是刚刚被修改的Page指针,在数据发生修改的过程中会经历4步如图。
- 内存中的page与磁盘中的page数据采用异步方式同步,会出现数据不一致的现象,对于同一个page的多次写可以一次i/o完成。
- WAL LOG
- 每个Partition/Btree都维护自己的一个WAL log(redo log), 每次写入搭配全局Dirty链表可以实现与磁盘的异步交互。若干条 log会聚合成一个类似Page的结构便于磁盘统一存储
- 在BG中partition的各个结构,BTree、WAL Log等都被组织为Page的模式,底层的磁盘也正是按照这种Page的组织方式来存放数据。Key为顶点ID+边类型+pageKey,value为page内容
索引
边上的局部属性索引
- 针对同一个起点(局部)的多条出边,根据不同的属性进行排序查询。比如查询用户A最新关注的100个用户 vs 用户A关注中最亲密的100个用户
- 实现方式:通过对边属性作为排序key,建立索引
- 存储:会在磁盘和内存分别存储索引key和被索引的边,存储方式也是Btree+page的方式
- 构建:在增删改原有数据,同时更新索引数据
点的全局属性索引
- 针对图中全部顶点,针对单个或多个顶点属性建立索引,支持对顶点属性等值查找、范围查找、排序需求等。比如查询年龄在18岁的用户
- 实现方式:根据点属性作为排序key,建立索引
- 存储:会在磁盘和内存分别存储索引key和被索引的顶点,存储方式也是Btree+page的方式
- 构建:在增删改原有数据,同时更新索引数据
[!tip] 参考 聊一聊图数据库ByteGraph 图数据库:ByteGraph 图数据库Neo4j技术原理探秘 - 简书
Gremlin
常用图遍历语言
- V():查询顶点,一般作为图查询的第1步,后面可以续接的语句种类繁多。例:g.V(),g.V(‘v_id’),查询所有点和特定点;
- E():查询边,一般作为图查询的第1步,后面可以续接的语句种类繁多;out(edge_type)表示根据给定的边标签来沿外向游走到相邻的那些顶点。
- in(edge_type)表示根据给定的边标签来沿内向游走到相邻的那些顶点。
- both(edge_type)表示根据给定的边标签来沿双向游走到相邻的那些顶点。
- outE(edge_type)表示根据给定的边标签来沿外向游走到相邻的那些边。
- inE(edge_type)表示根据给定的边标签来沿内向游走到相邻的那些边。
- bothE(edge_type)表示根据给定的边标签来沿双向游走到相邻的那些边。
- outV()表示游走到外向顶点。
- inV()表示游走到内向顶点。
- bothV()表示游走到双向顶点。
- otherV()表示游走到其他顶点,这些顶点不包含此顶点从哪移动来的那些顶点。
g.V().has("id", {user_id} ).has("type", 80805890).outE("16").withProperties("out_time")
g.V().has("id", ).has("type", 80805890).outE("16")
g.addE("follow").from( {user_id} , 80805890).to( {item_id}, 80805893) // create a new edge
.setProperty("out_time", 10)
[!tip] 参考 ByteCloud - One-stop development platform for ByteDancer ByteCloud - One-stop development platform for ByteDancer Gremlin图遍历语言简明文档 | BobinSun.蛋总