chenxuan note
Chenxuan

How to contact me
- chenxuanweb@qq.com,this is my email
- chaiquan@androidftp.top will also work
Official website
- resume.chenxuanweb.top (this is my resume)
- www.chenxuanweb.top
- blog.chenxuanweb.top
- my github
- my gitee
Tips
- Since I am a newbie, please contact me(by email chenxuanweb@qq.com or chaiquan@androidftp.top) if there is any error
- It's not a place where everything is documented in great detail, it's just places I'm not familiar with. If you want to learn systematically, this is not a good choice.
- Obsidian Chinese Help
- thank you for coming! have a good time

burn the emacs heresy,Vim is immortal.(doge)
Update Time
- last update in 2026年 03月 02日 星期一 01:56:19 CST
Thank
- Power by mdbook
- Create by Obsidian2web
go mod镜像加速
go env -w GO111MODULE=on
go env -w GOPROXY=https://goproxy.cn,direct
清除缓存
- 清除所有的包缓存
go clean --modcache
- 清除特定版本的包缓存(暂时没发现)
目录结构
目录为go/pkg/mod
├── cache
├── dubbo.apache.org
├── github.com
├── gitlab.dian.org.cn
├── git.sublive.app
├── go.etcd.io
├── golang.org
├── google.golang.org
├── gopkg.in
├── gorm.io
├── go.uber.org
└── vimagination.zapto.org
cache记录压缩包和校验文件等内容
不同的网站拥有不同的文件夹存放
包与路径
- import的是包的路径,不是包名,会根据import的值去寻找这个路径下的包
- import之后会去路径下找包,找到文件中第一行声明的package才是真正的包名
- 路径下的包名可以和目录不一样(最好一样),但是同一个路径只能有一个包名
私有仓库包获取
- go env -w GOPRIVATE="*.gitlab.cn" 设置为私有仓库
- go env -w GONOPROXY="*.gitlab.cn" 设置不走代理
- 编辑
~/.netrc文件(这个文件是纯文本文件不能使用任何的环境变量)
machine git.gitlab.cn login chenxuan password 123456789
- 第三步也可以更改为编辑
~/.gitconfig文件
[url "ssh://git@github.com/"]
insteadOf = https://github.com/
git config --global http.sslverify false解除git ssl验证
某个pkg最新版本
- 更改go.mod中的包版本为v0.0.0
gitlab不支持ssh拉取多级私有包
问题原因
- go get分两个过程,可以使用
go get -v查看记录- 获取链接的源信息,即meta data,此时使用的是https协议
- 下载代码,此时使用的是ssh(当然这里也可以更改为http)
- 超过2的sub目录在 未认证的情况下因为可能是仓库的信息(也可能是sub目录,一级不可能是仓库),这里涉及仓库信息,因此https没带这token禁止获取
- 使得go get命令无法获取超过1 的仓库的meta data,无法clone
解决办法
netrc
- 方法参考Go包管理 > 私有仓库包获取
- 核心是走https,meta请求就携带pwd,可以获取
- 优点:简单方便
- 缺点:cicd根本用不了,会信息泄漏
replace
- 核心参考参考
require (
private.gitlab.instance/project/team/somename v1.0.0
)
replace (
private.gitlab.instance/project/team/somename => private.gitlab.instance/project/team/somename.git v1.0.0
)
- 添加.git后缀,这个办法也可以改进为直接包名带着.git
- 优点:能解决问题,而且没有信息泄漏问题,简单方便
- 缺点:丑陋,莫名其妙带上.git
相关讨论连接
- https://github.com/golang/go/issues/34094#issuecomment-556898897
- https://gitlab.com/gitlab-org/gitlab/-/issues/36354
go多级包管理
go mod init github.com/{帐号}/{仓库名字}/{子包的名字},目录demo
.
├── README.md
├── a
│ ├── a.go
│ └── go.mod
└── b
├── b.go
└── go.mod
- 需要注意的是,这时候的tag规则是
{子包的相对路径}/v1.0.0
git tag
a/v1.0.0
b/v1.0.0
b/v1.0.1
- import的时候是tag需要注意
import (
github.com/robberphex/go-test-multi-module/a v1.0.0
)
- 参考:https://learnku.com/articles/58947 和 https://tonybai.com/2023/05/10/a-guide-of-managing-multiple-go-modules-in-mono-repo/
引用特定分支
- 直接使用
go get命令 类似go get github.com/golang/go@master - 直接在go.mod文件中添加,格式: git地址 v0.0.0-时间戳- commint id 例如: github.com/golang/go v0.0.0-20221013081251-69aaa89ae530
依赖地狱
- 项目引用了 A包和B包, A和B都引用了C包, 但是A用的是v1.0,B用的是v2.0, C包的v2.0不兼容 v1.0 , 导致崩溃无法编译

- go mod的解决办法是通过package路径加上version使得两个包依赖的完全是不同的的包, 使得同一个程序可以存在两个相同名字版本不同的包(本质依赖了包本身是隔离的,不会引起冲突的问题)
- 第一个代价就是构建出来的app的二进制文件size变大了,因为二进制文件中包含了多个版本的P3的代码;第二个代价,可能也算不上代价,更多是要注意的是不同版本的module之间的类型、变量、标识符不能混用
- 需要注意的是: 这种的多版本共存的情况只存在于, 两个package version的 major 版本发生了不同, 如果是同一个major, 那么会使用最大的版本号(可能出现不兼容问题)
- 冲突时候只要 major 相同, 默认使用最新的, 但是如果包管理方有问题就很容易

[!tip] 参考 为什么有了Go module后“依赖地狱”问题依然存在 | Tony Bai
查找包依赖来源
go mod why -m gopkg.in/yaml.v2展示的链路就是引用包的来源
更新go 版本在gomod
- 使用
go get go@1.22.12如果无法满足的包会自动删除, 这样就知道是哪个包的问题了
中间件的使用
- group 里面use的中间件只能在注册的路由生效,否则会报错
- default 里面use无论任何请求都会生效
Go json
- 处理[]byte时候会自动进行base64编码,bind会自动解码
- []byte字段json解码时只能接受base64串
go test
初始化
- go test 会主动调用初始化
- 如果需要其他初始化需要使用TestMain()
覆盖率
go test -v -covermode=set -coverprofile=hint_test.out
压力测试
go test -bench .
语言知识点
- make函数如何不指定大小,默认都是0,包括chan,因此初始化map一定要指定大小
为什么Go中没有volatile
[!info] java中volatile的作用
- 保证可见性(Visibility):当一个变量被声明为
volatile时,当一个线程修改了这个变量的值,其他线程能立即看到这个变量的最新值。这是因为volatile变量的值会被立即写入主内存,并且其他线程读取该变量时会直接从主内存中读取,而不是从线程的本地缓存中读取。- 禁止指令重排序(Prevent Reordering):
volatile关键字可以防止编译器对被声明为volatile的变量进行指令重排序优化。这样可以确保程序的执行顺序符合程序员的预期。==但是这里并不保证原子性,不能直接上多写== 总的来说,volatile关键字适用于那些多线程环境下一个线程写,多个线程读的简单场景,主要用于保证可见性和禁止指令重排序。
- 这个问题一般是写java问写go的,cpp的通常不会这样问
- Go 的基本设计思想是
"Do not communicate by sharing memory; instead, share memory by communicating.",换言之,Go 并不推荐我们在内存中使用共享变量 flag 的形式来实现通信,而是利用 channel 来实现通信,核心的区别点是设计理念上的区别
json.RawMessage
- 用于有时候需要根据type在具体决定解析到哪个结构体的情况下使用,一般不用interface{},因为parse会出错,使用这个替代interface,然后使用Unmarshal直接解析不需要断言
type Obj struct {
Type ObjType `json:"type,omitempty"`
Property json.RawMessage `json:"property,omitempty"`
}
// 然后
func parseBlock(obj *Obj) (block *Block, err error) {
block = &Block{}
err = json.Unmarshal(obj.Property, block)
if err != nil {
return nil, err
}
return
}
需要make初始化结构体
- map
- chan
- 其他的类似切片的用不用都可以
格式化工具
源码阅读工具
- https://github.com/TrueFurby/go-callvis.git 或者
go install github.com/ofabry/go-callvis@latest
代码规范
- #代码规范
命名
- 包名称:
- Go 包名称应该简短并且只包含小写字母。由多个单词组成的包名称应全部小写。例如,包 tabwriter 不应该命名为 tabWriter 、 TabWriter 或 tab_writer
- 避免使用无意义的包名称,例如 util 、 utility 、 common 、 helper,很容易造成导入冲突
- 接收者命名(this指针的名称):
- 短(通常是一两个字母的⻓度) 类型本身的缩写 始终如一地应用于该类型的每个接收者
- 常量命名:
- 常量名称必须像 Go 中的所有其他名称一样使用 混合大写字母MixedCaps。导出常量以大写字母 开头,而未导出的常量以小写字母开头。常量名称不 应是其值的派生词,而应该解释值所表示的含义。
- ==不要使用非混合大写常量名称或带有 K 前缀的常量==。
- 在具有多个首字母缩写的名称中(例如 XMLAPI 因为它包含 XML 和 API ),给定首字母缩写中 的每个字母都应该具有相同的大小写,但名称中的每个首字母缩写不需要具有相同的大小写
- 在带有包含小写字母的首字母缩写的名称中(例如 DDoS 、 iOS 、 gRPC ),首字母缩写应该像在 标准中一样出现,除非你需要为了满足 导出 而更改第一个字母。在这些情况下,整个缩写词应 该是相同的情况(例如 ddos 、 IOS 、 GRPC )
- Get方法:
- 函数和方法名称不应使用 Get 或 get 前缀,除非底层概念使用单词“get”(例如 HTTP GET)。此 时,更应该直接以名词开头的名称,例如使用 Counts 而不是 GetCounts 。
- 变量名:
- 一般的经验法则是,名称的⻓度应与其范围的大小成正比,并与其在该范围内使用的次数成反比。在 文件范围内创建的变量可能需要多个单词
- ==除第一个单词外,每个单词都以大写字母开头==
- 函数接收者变量:
- 使用一个字母或两个字母的名称。
[!tip] 参考 https://github.com/xxjwxc/uber_go_guide_cn 社区认可的 https://gocn.github.io/styleguide/docs/01-overview/ google的 effect-go GO官方的
如何避免Go语言的100个错误
错误检查工具
- vet 标准Go分析工具
- kisielk/errcheck 错误检查工具
- fzipp/gocyclo 循环复杂度分析工具
- goconst 重复字符串常量分析工具
切片注意事项
s1 := make([]int, 3, 6)
s2 := s1[1:3]
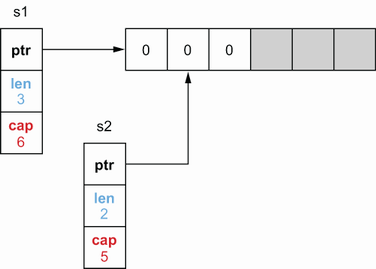
- 执行插入一个元素后,这个对于锁
- 是不可见的,因为s2的len没有改变
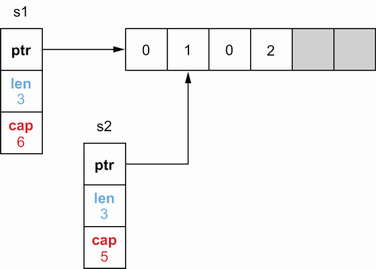
s2 = append(s2, 2)
// 此时
s1=[0 1 0], s2=[1 0 2]
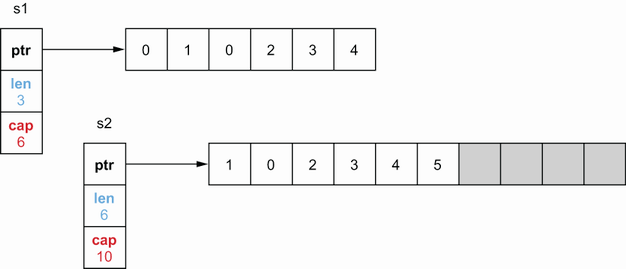
- 插入多个元素后会地址发生改变
for注意事项
- 下面这个example中 v 会进行复用,因此每次获得的 v 的地址是完全相同的
type A struct {
A string
}
func ForTest() {
testData := []A{
{"1"}, {"2"},
}
target := []*A{}
for _, v := range testData {
target = append(target, &v)
}
log.V2.Info().Obj(target).Emit()
}
// [0xc0002cb470 0xc0002cb470]
// [{"A":"2"},{"A":"2"}]
下载最新版本Go
- 卸载原来的go
apt remove golang-go - 下载安装包从 Go下载 - Go语言中文网 - Golang中文社区
rm -rf /usr/local/go && tar -C /usr/local -xzf go1.14.3.linux-amd64.tar.gz版本自己更改export PATH=$PATH:/usr/local/go/bin添加目录
gin
middleware顺序
- middleware的顺序是按照注册的顺序正序执行,而不是倒序执行
a || b && c
- 这种情况下相当于 a || (b && c) ,所有语言都是一样的, 核心是因为 and 的优先级高于 or
Cors 跨域
- 这个一定得放在 根 g 的 use 中, 不能放在子的api 的 use 中, 否则无法访问
//跨域
func Cors() gin.HandlerFunc {
return func(c *gin.Context) {
c.Writer.Header().Set("Access-Control-Allow-Origin", "*")
c.Writer.Header().Set("Access-Control-Allow-Methods", "GET, POST, PUT, DELETE")
c.Writer.Header().Set("Access-Control-Allow-Headers", "Content-Type, Authorization")
c.Writer.Header().Set("Access-Control-Allow-Credentials:", "true")
if c.Request.Method == "OPTIONS" {
c.AbortWithStatus(204)
return
}
c.Next()
}
}
gdb调试
- 编译
go build -gcflags "-N -l"
-
gdb调试
加载
调试out
- gdb a.out
调试core
- 生成core
ulimit -c unlimited(只对一个终端有用) # 如果设置了没生成用这个看下生成的目录 cat /proc/sys/kernel/core_pattern # 如果想生成当前目录或者没权限 sudo sysctl -w kernel.core_pattern=core # 临时改为生成 core 文件- gdb (程序名) (core名字)
调试程序
- gdb attach pid
运行
带着gui
- gdb -tui (a.out)
设置arg
- set args 运行时参数
常用
- r 开始运行
- c 运行到断点
- n 下一步
- s 进入函数
- until 跳出循环
- fin 结束函数
- bt backtrace 显示当前调用堆栈
- where 查看core目前位置的调用栈
打印
源代码打印
- list num(打印num行附近代码)
- list 打印代码,一直回车一直打
变量打印
- print (打印一切)
断点
设置
- b 11(普通断点)
- b 11 if some>=0(条件断点)
- tb 11(临时断点,只用一次失效)
删除断点
- delete (可以指定断点编号)
查看断点
- info break
多线程
查看线程信息
- info thread
切换线程
- thread id
查看调用帧
- info frame
- backtrace
显示汇编
修改布局
- layout asm
显示函数汇编
- disas /m functionname
查看目前汇编
- x/i $pc
- display /3i $pc
i line 13 disassemble 0x4004e9, 0x40050c退出 q
dlv调试
- 进入包目录
dlv debug
- 其他和gdb差不多
底层结构
数组
- 使用数组,每次作为函数参数会复制整个数组
- 不同大小数组类型不一样,长度不可变
切片
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
- 切片append之后,由于Data内容可能发生变化,所以要切片重新赋值
- 切片作为参数时候,会拷贝结构体内容,因此修改本体
注意,作为参数传递时候,如果是append可能导致data指向发生变化导致外围无法感知变化,因此如果要修改最好还是传指针
func Temp(slice []string) {
slice = append(slice, "1")
fmt.Println(slice)
}
func TryAppend() {
var slice []string
Temp(slice)
fmt.Println(slice)
}
// 这部分代码结果为 [1] []
func Temp(slice *[]string) {
*slice = append(*slice, "1")
fmt.Println(*slice)
}
func TryAppend() {
var slice []string
Temp(&slice)
fmt.Println(slice)
}
// 这部分代码结果为 [1] [1]
和数组区别
- 数组长度不能改变,初始化后长度就是固定的;切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大
- 函数调用时的传递方式不同,数组按值拷贝,slice按只拷贝指针
- unsafe.sizeof的取值不同,unsafe.sizeof(slice)返回的大小是切片的描述符,不管slice里的元素有多少,返回的数据都是24字节。unsafe.sizeof(arr)的值是在随着arr的元素的个数的增加而增加,是数组所存储的数据内存的大小。
- 初始化方式不同
Map
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
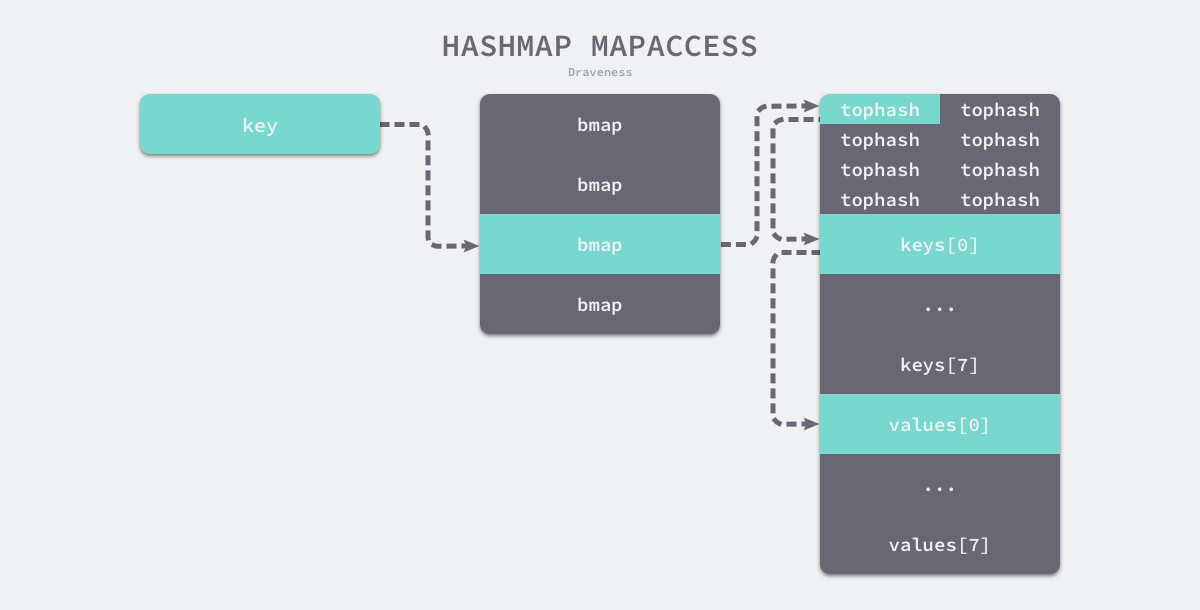
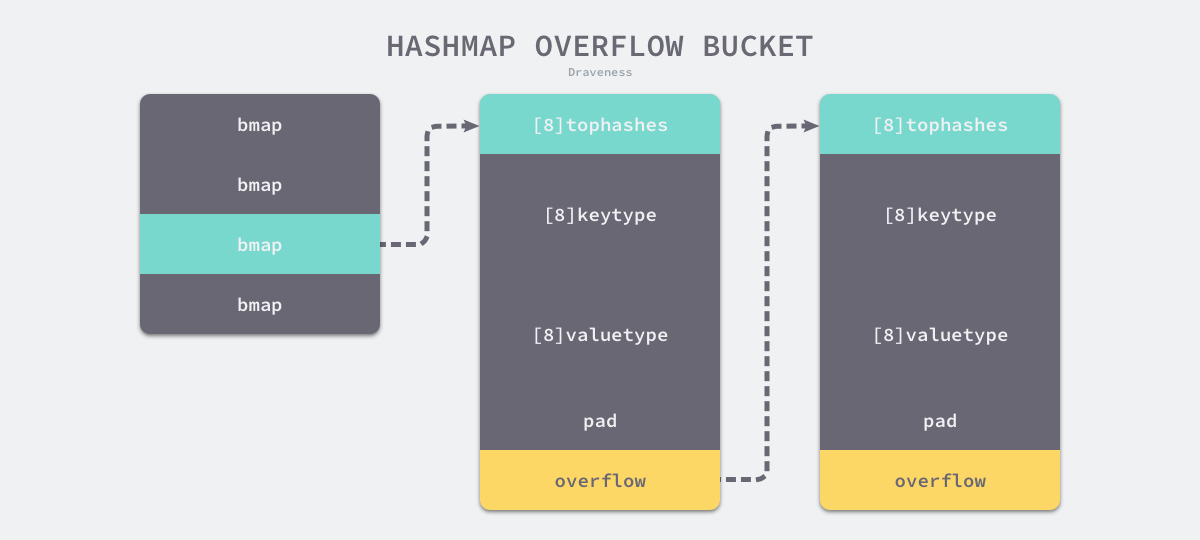
-
使用公共溢出区解决hash冲突
- 空间利用效率高(不需要存储指针)2.内存连续性3.灵活的动态扩展
-
实际上存的也是指针,参数会改变
-
只有 hash 后的值相等以及字面值相等,才被认为是相同的 key。很多字面值相等的,hash出来的值不一定相等,比如引用。
-
线程不安全:在查找、赋值、遍历、删除的过程中都会检测写标志,一旦发现写标志置位(等于1),则直接 panic。赋值和删除函数在检测完写标志是复位之后,先将写标志位置位,才会进行之后的操作
-
也是通过渐进式扩容,和redis类似,#### rehash
服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于
1; 服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于5- 渐近式,不会出现突发性能问题(还是用空间换时间)
- 按照倍数扩大
过程
- 为
ht[1]分配空间, 让字典同时持有ht[0]和ht[1]两个哈希表。 - 在字典中维持一个索引计数器变量
rehashidx, 并将它的值设置为0, 表示 rehash 工作正式开始。 - 在 rehash 进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将
ht[0]哈希表在rehashidx索引上的所有键值对 rehash 到ht[1], 当 rehash 工作完成之后, 程序将rehashidx属性的值增一。 - 随着字典操作的不断执行, 最终在某个时间点上,
ht[0]的所有键值对都会被 rehash 至ht[1], 这时程序将rehashidx属性的值设为-1, 表示 rehash 操作已完成。
- 标识开始hash,在每次操作时候进行,按照顺序
- 均为单线程操作
操作
- 查找先在原来的查,找不到再查新的,删除,改变归同时操作两个
- 增加只在新的增加
字符串
type StringHeader struct {
Data uintptr
Len int
}
// byte
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
- 字符串不能更改,只能重新赋值(修改指针,类似+这种都是生成新的字符串)
- []byte(string)实际上发生了拷贝,而不是指针转移,因此开销很大
- 也是线程不安全
接口
- 接口不是任意类型,它自己带有数据,!=nil
// 不带有方法(函数)的接口
type eface struct { // 16 字节
_type *_type
data unsafe.Pointer
}
type _type struct {
size uintptr //用于计算占用大小
ptrdata uintptr
hash uint32 //重要,用于用hash计算两个对象是否相等
tflag tflag
align uint8
fieldAlign uint8
kind uint8
equal func(unsafe.Pointer, unsafe.Pointer) bool
gcdata *byte
str nameOff
ptrToThis typeOff
}
// 带的接口
type iface struct { // 16 字节
tab *itab
data unsafe.Pointer
}
type itab struct { // 32 字节
inter *interfacetype
_type *_type
hash uint32 //和上面的hash一样
_ [4]byte
fun [1]uintptr //重要,虚函数指针
}
-
类型断言实际上就是比较hash值是否相同
-
方法调用时候的操作和C++类似,虚函数加偏移## 多态的实现
虚函数表
- 虚函数表可以理解为就是一个函数指针数组
functype ptr[] - 虚函数表内部存放的是函数指针,而不是函数地址
- 无论是基类还是子类,(前提有虚函数)都有一个自己的虚函数表,继承时候会直接复制基类的虚函数表
- 重写时候会改写虚函数表里面指针指向的函数地址,达到多态作用
- 子类添加新的虚函数(不是重写,而是新的)会追加在虚函数表最后
- 父类指针拿到子类对象时候,对着表格拿到函数指针,但是实际上拿到的是子类的虚函数表,因此函数指针也是指向子类的,因此实现多态

- 多重继承时候会有多个虚函数表
面向过程区别
- 面向对象是以功能来划分问题,而不是以步骤解决
三大特性
封装
- 类仅仅通过有限的方法暴露必要的操作,也能提高类的易用性
- 增强代码可读性和可维护性
继承
- 代码复用,将这些相同的部分,抽取到父类中,让两个子类继承父类
[!tips] 注意点 继承的时候所有虚函数不要加const, 因为不确定子类重写的时候会不会需要更改, 加上是不合适的
多态
- 提高了代码的可扩展性。
- 只需要根据父类指针调用函数,不用关心子类的具体实现
底层模型
虚拟继承
- 解决菱形继承的问题
- A作为base类会被放在最下面,作为共享部分,然后与base不同部分放在上面
D VTable +---------------------+ | vbase_offset(32) | +---------------------+ struct D | offset_to_top(0) | object +---------------------+ 0 - struct B (primary base) | RTTI for D | 0 - vptr_B ----------------------> +---------------------+ 8 - int bx | D::f0() | 16 - struct C +---------------------+ 16 - vptr_C ------------------+ | vbase_offset(16) | 24 - int cx | +---------------------+ 28 - int dx | | offset_to_top(-16) | 32 - struct A (virtual base) | +---------------------+ 32 - vptr_A --------------+ | | RTTI for D | 40 - int ax | +---> +---------------------+ sizeof(D): 48 align: 8 | | D::f0() | | +---------------------+ | | vcall_offset(0) |x--------+ | +---------------------+ | | | vcall_offset(-32) |o----+ | | +---------------------+ | | | | offset_to_top(-32) | | | | +---------------------+ | | | | RTTI for D | | | +--------> +---------------------+ | | | Thunk D::f0() |o----+ | +---------------------+ | | A::bar() |x--------+ +---------------------+多线程
- 当一个thread对象既没有detach也没有join时候,thread释放(可以是因为栈对象自动释放)后会直接中断程序
- thread提供参数之后不能通过引用传递,但是可以通过指针传递,因为thread构造参数时候直接使用拷贝
- condition_variable的wait调用后,会先释放锁,之后进入等待状态;当其它进程调用通知激活后,会再次加锁
std::unique_lock和std::lock_guard类似,第一个更加灵活,但是性能更加差- 条件变量的用法通常为生产者消费者模型,多个线程用同一个锁+条件变量阻塞
- bind函数可以将函数和参数进行绑定生成一个新的函数对象,这样适配接口就会更加方便
void fun1(int n1, int n2, int n3) { cout << n1 << " " << n2 << " " << n3 << endl; } struct Foo { void print_sum(int n1, int n2) { std::cout << n1+n2 << '\n'; } int data = 10; }; int main() { //_1表示这个位置是新的可调用对象的第一个参数的位置 //_2表示这个位置是新的可调用对象的第二个参数的位置 auto f1 = bind(fun1, _2, 22, _1); f1(44,55); Foo foo; auto f = std::bind(&Foo::print_sum, &foo, 95, std::placeholders::_1);// 第二个参数必须是对象作为this指针 f(5); // 100 }- thread是可以移动的move,但是不能复制copy
条件变量和信号量的区别
- 条件变量支持广播方式唤醒等待者;而信号机制不支持,只能一个一个通知
- 条件变量只能结合互斥量做同步用;信号机制除了做同步,还能用于共享资源并发访问加锁
- 条件变量是无状态的,如果唤醒早于等待,则唤醒会丢失;信号机制是有状态的,可以记录唤醒的次数
多线程demo
class ThreadPool{ private: std::queue<std::function<void(void)>> task_que_; std::condition_variable cond_;// 条件变量,通常和锁一起使用 std::mutex que_mut_;// 队列锁 std::vector<std::thread> arr_thread_; std::atomic<bool> is_close; std::atomic<int> busy_num_;// 多线程操作,原子变量 public: ThreadPool(int thread_num){ is_close=false; for (int i = 0; i < thread_num; i++) { arr_thread_.emplace_back(std::thread(Consumer,this));// 本身就是右值,可以不适用std::move,如果是左值而且使用emplace_back的话需要std::move避免thread的复制行为 } } ThreadPool():ThreadPool(5){} ~ThreadPool(){ is_close=true; cond_.notify_all(); for(auto& thread_now:arr_thread_){ thread_now.join(); } } void Add(const std::function<void(void)>& call_back){ std::lock_guard<std::mutex> guard(que_mut_); task_que_.emplace(call_back); cond_.notify_one(); } private: static void Consumer(ThreadPool* pool){ if (pool==nullptr) { return; } auto& cond=pool->cond_; auto& mut=pool->que_mut_; std::function<void(void)> task{nullptr}; while (1) { {// 这个作用域结束que_mut_自动释放,为了避免锁的占用 std::unique_lock<std::mutex> unique(pool->que_mut_); cond.wait(unique,[&]()->bool{return !pool->task_que_.empty()||pool->is_close;});// wait函数首先通过第一个参数拿到锁的控制权,然后不会加锁或者解锁,会等待条件变量的到来,条件变量到来后尝试加锁(多个线程最后只有一个能拿到锁),拿到之后判断第二个参数是否为true,如果为true就继续执行,否则就解开锁继续等待 if (pool->is_close) { return; } task=pool->task_que_.front(); pool->task_que_.pop(); } pool->busy_num_++; if (task!=nullptr) { task(); } pool->busy_num_--; } } }; void PrintFunc(int print_num){ std::cout<<"run:"<<print_num<<std::endl; } int main() { ThreadPool pool; for (int i = 0; i < 20; i++) { pool.Add(std::bind(PrintFunc,i));// std::bind的作用是生成一个新的函数对象,这个对象可以直接提供参数,达到参数简化的目的 } sleep(2); return 0; }
参考
- 深度探索C++对象模型
- 虚函数表可以理解为就是一个函数指针数组
函数调用
- 和C一样的地方:重后向前计算参数
- 不一样:GO不用寄存器,而C用
关键字
for range
for i,v := range arr{}
//会转化为下面形式,长度在一开始就确定了,不会变
//`range` 运算符会创建了数组的副本。同时,循环不会更新副本
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
for ; hv1 < hn; hv1++ {}
- hash遍历顺序是不确定的
select
- 随机生成一个遍历的轮询顺序
pollOrder并根据 Channel 地址生成锁定顺序lockOrder; - 根据
pollOrder遍历所有的case查看是否有可以立刻处理的 Channel;- 如果存在,直接获取
case对应的索引并返回; - 如果不存在,创建
runtime.sudog结构体,将当前 Goroutine 加入到所有相关 Channel 的收发队列,并调用runtime.gopark挂起当前 Goroutine 等待调度器的唤醒;
- 如果存在,直接获取
- 当调度器唤醒当前 Goroutine 时,会再次按照
lockOrder遍历所有的case,从中查找需要被处理的runtime.sudog对应的索引;
defer
- 底层为链表结构,添加的反而时候会在头部添加最新的defer,执行时候从头执行,类似栈
- 如果是传递参数的话,添加时候(声明defer)函数的参数就已经确定了
- defer和goroutine关联,panic只会调用自己协程的defer
- defer在函数退出时才能执行,在for执行defer会导致资源延迟释放,不要在循环中使用defer,除非构造局部函数
- defer如果是直接接受对象的函数,会立刻拷贝这个对象,如果是对象实体,那么后续改变不影响defer内容,如果是对象指针,后面会影响defer内容
[!important] Defer坑点
... if(xxx){ mut.lock() defer mut.unlock() defer fmt.Println(1) } fmt.Println(2)这段代码的结果是
21,而且因为这个特性很容易产生死锁,defer的调用是在其所在函数返回的时候才会发生的,其他时候不会出现,即使再加个大括号也不行
panic/recover
- 之后defer可以捕获panic并执行recover >在 panic之后不执行,因此不能放后面 >放前面panic没发生,捕获不到
- recover不能跨栈(必须统一层次)执行
func main() {
defer func() {
recover()// 只有放到这里才能执行
}()
panic(1)
}
break
- break+标签的方式作用不是goto 标签,而是跳出标签下的第一个select/switch/for 循环,goto+标签 才是直接跳到该标签
- break只能跳出一个 select/switch/for 循环
- 单独在select中使用break和不使用break没有啥区别。
- 单独在表达式switch语句,并且没有fallthough,使用break和不使用break没有啥区别。
- 单独在表达式switch语句,并且有fallthough,使用break能够终止fallthough后面的case语句的执行。
- 带标签的break,可以跳出多层select/ switch作用域。让break更加灵活,写法更加简单灵活,不需要使用控制变量一层一层跳出循环,没有带break的只能跳出当前语句块。
系统组件
Mutex
正常模式
- 非公平锁
- 正常模式下,所有等待锁的 goroutine 按照 FIFO(先进先出)顺序等待。唤醒 的 goroutine 不会直接拥有锁,而是会和新请求 goroutine 竞争锁。新请求的 goroutine 更容易抢占:因为它正在 CPU 上执行,所以刚刚唤醒的 goroutine有很大可能在锁竞争中失败。在这种情况下,这个被唤醒的 goroutine 会加入 到等待队列的前面。
- 性能好,因为切换成本低.
饥饿模式
- 公平锁
- 饥饿模式下,直接由 unlock 把锁交给等待队列中排在第一位的 goroutine (队 头),同时,饥饿模式下,新进来的 goroutine 不会参与抢锁也不会进入自旋状 态,会直接进入等待队列的尾部。这样很好的解决了老的 goroutine 一直抢不 到锁的场景。
- 触发条件:当一个 goroutine 等待锁时间超过 1 毫秒时,或者当前 队列只剩下一个 goroutine 的时候,Mutex 切换到饥饿模式。
计时器
-
使用四叉堆
时间堆
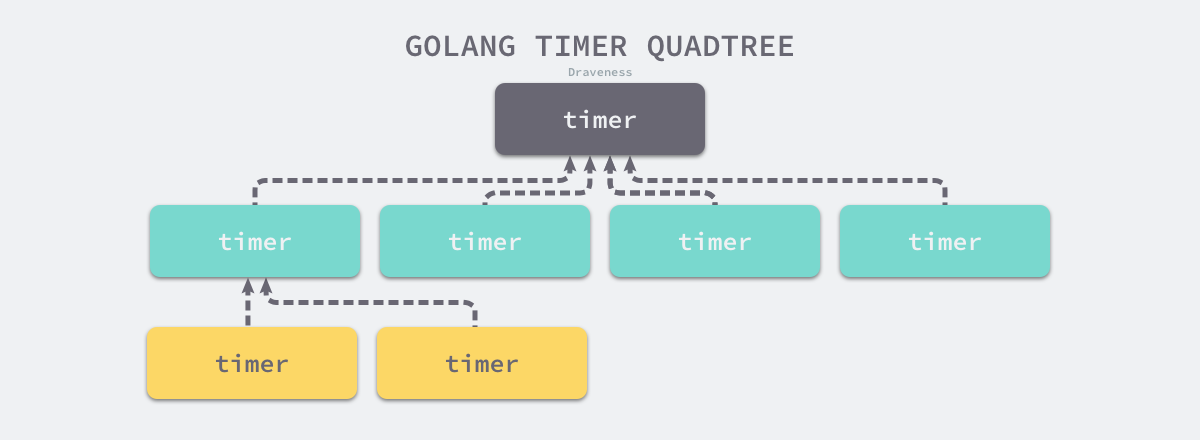
- 高精度
- 逻辑复杂
- 一般用四叉堆
- 插入和删除的复杂度是logn(因为涉及到排序二分搜索)
思路
- 类似二叉堆,最小先执行的时间放在上面
- 到了实现执行之后重新计算堆
cron
- 使用类似二叉堆的办法
for { // Determine the next entry to run. sort.Sort(byTime(c.entries))// 直接数组排序 var timer *time.Timer if len(c.entries) == 0 || c.entries[0].Next.IsZero() { timer = time.NewTimer(100000 * time.Hour) } else { timer = time.NewTimer(c.entries[0].Next.Sub(now))//计算最小到期时间并且计时 } for { select { case now = <-timer.C://触发标识出现计时器到期 now = now.In(c.location) // Run every entry whose next time was less than now for _, e := range c.entries { if e.Next.After(now) || e.Next.IsZero() { break } c.startJob(e.WrappedJob) e.Prev = e.Next e.Next = e.Schedule.Next(now)//计算下一次触发时间 c.logger.Info("run", "now", now, "entry", e.ID, "next", e.Next) } case newEntry := <-c.add://添加之后会重新计算最小到期时间 timer.Stop() now = c.now() newEntry.Next = newEntry.Schedule.Next(now) c.entries = append(c.entries, newEntry) c.logger.Info("added", "now", now, "entry", newEntry.ID, "next", newEntry.Next) //...略 case id := <-c.remove: timer.Stop() now = c.now() c.removeEntry(id)//删除节点 c.logger.Info("removed", "entry", id) } break//无论结果到这里都会出来重新计算 } }
chan
type hchan struct {
qcount uint
dataqsiz uint
buf unsafe.Pointer
elemsize uint16
closed uint32
elemtype *_type
sendx uint
recvx uint
recvq waitq
sendq waitq
lock mutex
}
qcount— Channel 中的元素个数;dataqsiz— Channel 中的循环队列的长度;buf— Channel 的缓冲区数据指针;sendx— Channel 的发送操作处理到的位置;recvx— Channel 的接收操作处理到的位置;
除此之外,
elemsize和elemtype分别表示当前 Channel 能够收发的元素类型和大小;sendq和recvq存储了当前 Channel 由于缓冲区空间不足而阻塞的 Goroutine 列表,这些等待队列使用双向链表runtime.waitq表示,链表中所有的元素都是runtime.sudog结构
- 阻塞发生时候会加入队列后沉睡,然后等待调度器唤醒
- 使用环形缓冲区实现缓冲

发送流程
- 检查 recvq 是否为空,如果不为空,则从 recvq 头部取一个 goroutine,将数据发送过去,并唤醒对应的 goroutine 即可。
- 如果 recvq 为空,则将数据放入到 buffer 中。
- 如果 buffer 已满,则将要发送的数据和当前 goroutine 打包成
sudog对象放入到sendq中。并将当前 goroutine 置为 waiting 状态。
接收流程
- 检查是否有数据,如果有数据,直接返回数据
- 如果没有数据,加入recvq,并且让出协程
关闭的chan
- 向关闭的chan写入会出现panic,重复关闭chan会panic,未初始化关闭会panic(核心就是已经关闭的cha只能读不能写)
- 读取关闭的chan
- 通过val,ok读取得到的ok为false
- 通过val读取得到的为默认值
- close chan时候所有阻塞读chan的协程都会收到消息
- close chan后chan编程只读状态,任何写操作都会panic(比如close和写入消息)
避免产生panic方法
- 应该只在发送端关闭 channel。(防止关闭后继续发送)
- 存在多个发送者时不要关闭发送者 channel,而是使用专门的 stop channel。(因为多个发送者都在发送,且不可能同时关闭多个发送者,否则会造成重复关闭。发送者和接收者多对一时,接收者关闭 stop channel;多对多时,由任意一方关闭 stop channel,双方监听 stop channel 终止后及时停止发送和接收)
for-select模型
- 非阻塞写
for{
select {
case ch <- 1:
fmt.Println("Sent 1")
default:
fmt.Println("Channel is full")
}
}
- 非阻塞读
for{
select {
case i := <-ch:
fmt.Println("Received", i)
default:
fmt.Println("No value received")
}
}
- 退出监控
- 退出时候给所有等待中的chan发送默认值
for {
select {
case <-G2CServer.ExitChan:
return
}
}
调度器
- goroutine之所以这么快就是因为其比线程更加小,操作系统完全不感知,由Go调度器自己执行和分配而可以做到系统不感知的重要操作是函数调用不需要使用寄存器,这样协程使得所有的操作都在内存进行
GMP模型
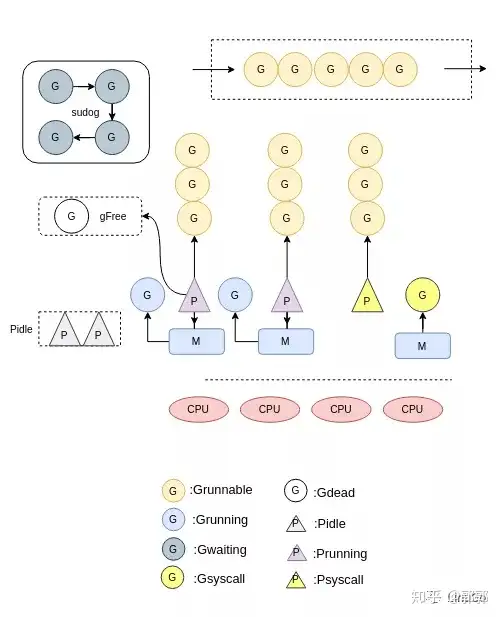
- G:表示goroutine,每个goroutine都有自己的栈空间,定时器,初始化的栈空间在2k左右,空间会随着需求增长。
- M:抽象化代表内核线程,记录内核线程栈信息,当goroutine调度到线程时,使用该goroutine自己的栈信息。
- P:代表调度器,负责调度goroutine,维护一个本地goroutine队列,M从P上获得goroutine并执行,同时还负责部分内存的管理。
- 一个M只能同时运行一个G
- M运行哪个G从P获取,P负责G顺序和部分内存的管理,G的运行队列是环形的保证公平
- 再运行GC时候会主动放弃主动权
调度时机
- Channel阻塞:当goroutine读写channel发生阻塞时候,会调用gopark函数,该G会脱离当前的M与P,调度器会执行schedule函数调度新的G到当前M。mutex阻塞也会发生这个情况
- 系统调用:当某个G由于系统调用陷入内核态时,该P就会脱离当前的M,此时P会更新自己的状态为Psyscall,M与G互相绑定,进行系统调用。结束以后若该P状态还是Psyscall,则直接关联该M和G,否则使用闲置的处理器处理该G。
- 系统监控:当某个G在P上运行的时间超过10ms时候,或者P处于Psyscall状态过长等情况就会调用retake函数,触发新的调度。
- 主动让出:由于是协作式调度,该G会主动让出当前的P,更新状态为Grunnable,该P会调度队列中的G运行。
抢占式调度
- 协作式,使用函数触发
- 基于信号,信号触发(目前只在GC使用)
协程同步的方法
- mutex锁
- cond条件变量
- chan通道
- waitgroup
优势
- 上下文切换代价小: P 是G、M之间的桥梁,调度器对于goroutine的调度,很明显也会有切换,这个切换是很轻量的: 只涉及PC SP DX三个寄存器的值的修改;而对比线程的上下文切换则需要陷入内核模式、以及16个寄存器的刷新
- 内存占用小: 线程栈空间通常是2M, Goroutine栈空间最小是2k, golang可以轻松支持10w+的goroutine运行,而线程数量到达1k, 内存占用就到2G。
并发模型
context包作用
- 用于在goroutine 之间传递取消信号、超时时间、截止时间以及一些共享的值
sync包
sync.map
- map不是线程安全的(可以通过互斥锁或者读写锁实现线程安全),但是sync.map是线程安全的
- 底层设计和缓存思想以及redis类似,都是通过缓存读的办法解决读的速度问题,但是写的时候需要维护缓存一致性因此比较慢,合适用于读多写少的情况,非常不适合写多读少的情况,删除因为只是标记,因此也很快.整个设计重点要考虑的就是一致性,和read命中两个方面的问题
结构
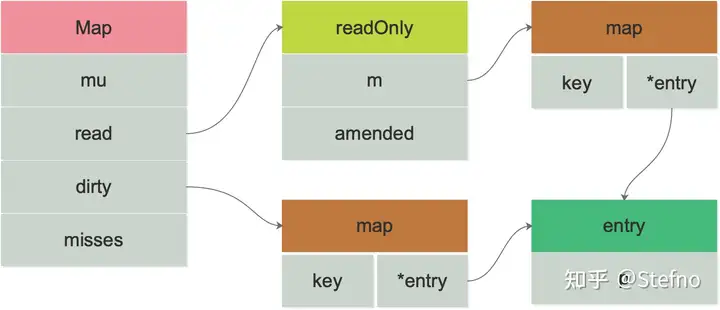
type Map struct {
mu Mutex
read atomic.Value // readOnly结构体
dirty map[interface{}]*entry
misses int
}
// Map.read 属性实际存储的是 readOnly。
type readOnly struct {
m map[interface{}]*entry
amended bool //amended 属性告诉程序 dirty 是否包含 `read.readOnly.m` 中没有的数据
}
读取过程
- 先查看 read 中是否包含所需的元素:
- 若有,则通过 atomic 原子操作读取数据并返回。
- 若无,则会判断
read.readOnly中的 amended 属性,他会告诉程序 dirty 是否包含read.readOnly.m中没有的数据;因此若存在,也就是 amended 为 true,将会进一步到 dirty 中查找数据
调用 Load 或 LoadOrStore 函数时,如果在 read 中没有找到 key,则会将 misses 值原子地增加 1,当 misses 增加到和 dirty 的长度相等时,会将 dirty 提升为 read。以期减少“读 miss”
写入过程
- 检查
m.read中是否存在这个元素。若存在,且没有被标记为删除状态,则尝试存储。 - 如果不存在进入dirty
- 加锁,dirty因为是原生的map,加锁才能使用
- 若发现 read 中存在该元素,但已经被标记为已删除(expunged),则说明 dirty 不等于 nil(dirty 中肯定不存在该元素)。其将元素状态从已删除(expunged)更改为 nil。将元素插入 dirty 中。
- 若发现 read 中不存在该元素,但 dirty 中存在该元素,则直接写入更新 entry 的指向。标记amended为true
- 若发现 read 和 dirty 都不存在该元素,则从 read 中复制未被标记删除的数据,并向 dirty 中插入该元素,赋予元素值 entry 的指向
删除过程
- 将 entry.p 置为 nil,并且标记为 expunged(删除状态),而不是真真正正的删除。
参考
- https://zhuanlan.zhihu.com/p/413467399
- https://zhuanlan.zhihu.com/p/344834329
Goroutine泄露
- 泄漏的可能主要分为
- channel 导致的泄露
- 如goroutine等待chan或者发送chan导致不能释放,这部分可以通过context的cancel取消
- 传统同步机制导致的泄露
- 比如多个协程加锁但是没有释放,导致不停等待
- channel 导致的泄露
内存管理
内存分配器
- 类似内存池分配分片式
内存回收GC
三色标记法
代码参考
- C++:https://gitee.com/chenxuan520/tricolor-notation/blob/master/gc.h
说明
- 本质也是标记清除算法,但是解决它的程序停止的缺点(核心还是读写冲突的问题,如果不暂停程序就会出现读写冲突,三色标记法使用的是类似锁的方法解决)
- 垃圾收集的根对象一般包括全局变量和栈对象,因为栈对象永远是黑色(会自动释放),只有堆对象需要回收
- Go 语言的垃圾收集可以分成清除终止、标记、标记终止和清除四个不同阶段
过程
- 先从根开始标记灰色,三个桶
- 把灰色引用到的全部变灰色,灰色变黑
- 删除白色对象
- 继续上面过程
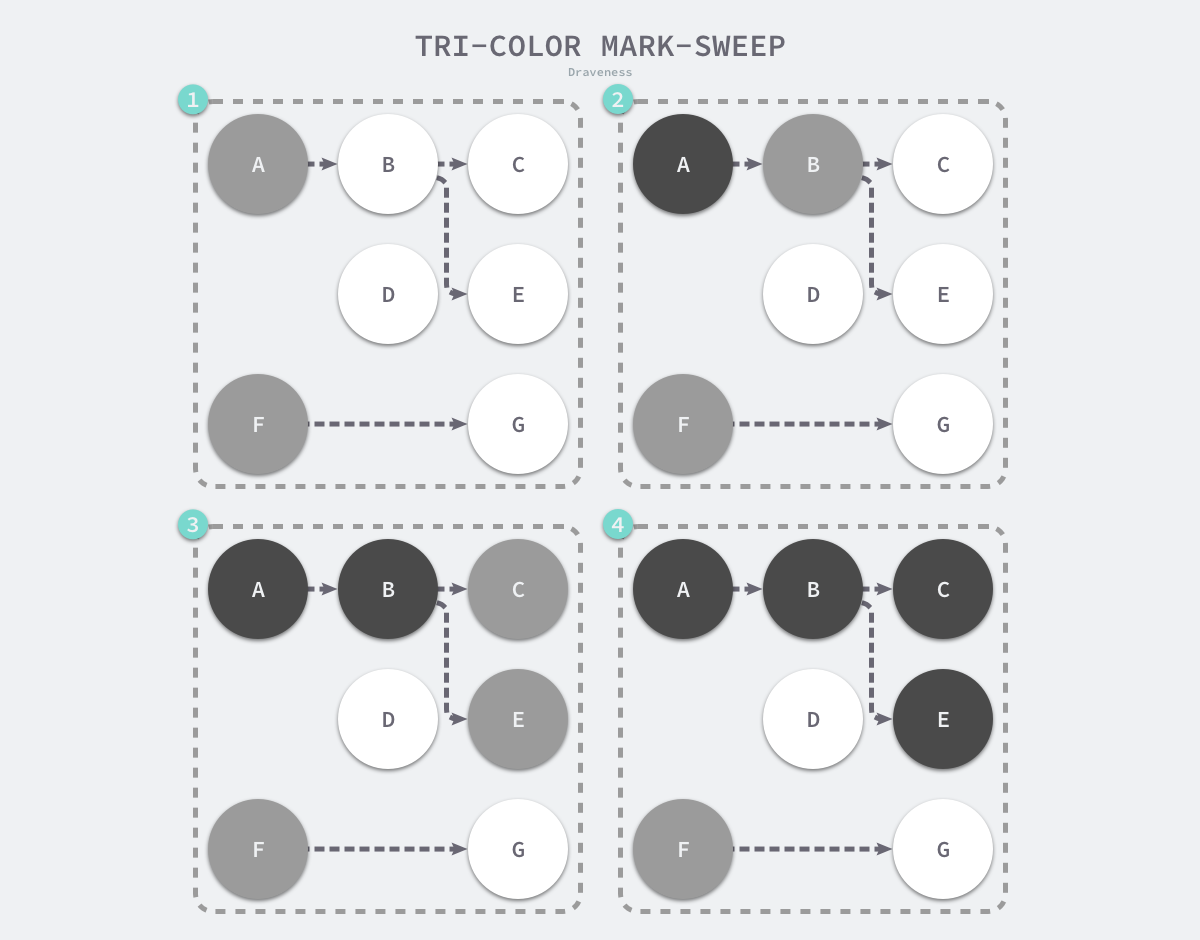
完整流程
- GCMark 标记准备阶段,为并发标记做准备工作,启动写屏障
- STWGCMark 扫描标记阶段,与赋值器并发执行,写屏障开启并发
- GCMarkTermination 标记终止阶段,保证一个周期内标记任务完成,停止写屏障
- GCoff 内存清扫阶段,将需要回收的内存归还到堆中,写屏障关闭
- GCoff 内存归还阶段,将过多的内存归还给操作系统,写屏障关闭。
写屏障
- 强三色不变性 — 黑色对象不会指向白色对象,只会指向灰色对象或者黑色对象;
- 弱三色不变性 — 黑色对象指向的白色对象必须包含一条从灰色对象经由多个白色对象的可达路径
- 所有触发都是针对黑色和灰色对象,白色对象引用的改变不会触发
- 缺点: 需要给栈对象添加屏障,损耗指针性能
插入写屏障
writePointer(slot, ptr):
shade(ptr) //把要插入引用的对象先涂灰
*slot = ptr //改变指针到引用
- 把增加引用的对象变成灰色,添加引用时候触发,保证强三色不变性
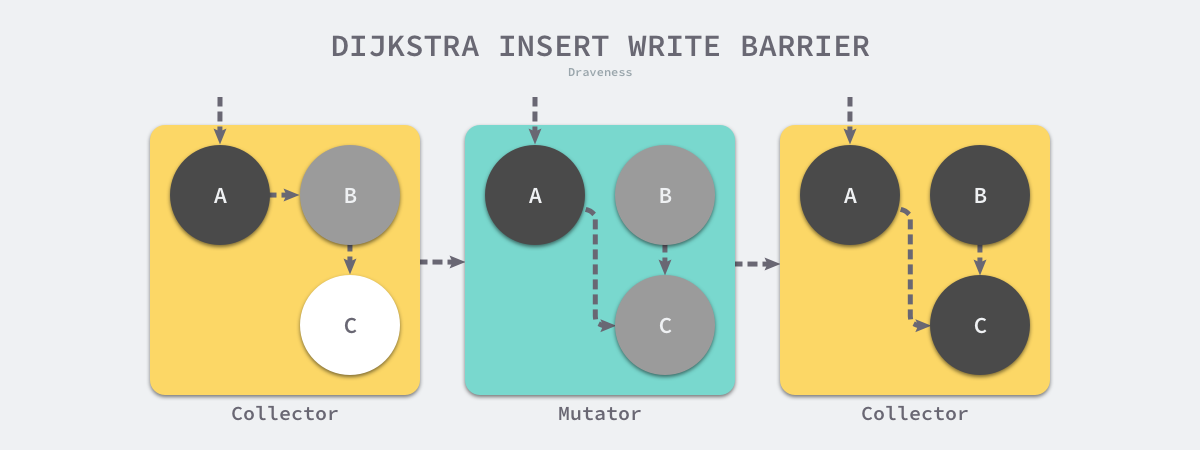
删除写屏障
writePointer(slot, ptr)
shade(*slot) //把要删除的引用对象涂灰
*slot = ptr //改变指针到引用
- 删除引用之前,先把被删除引用对象涂灰
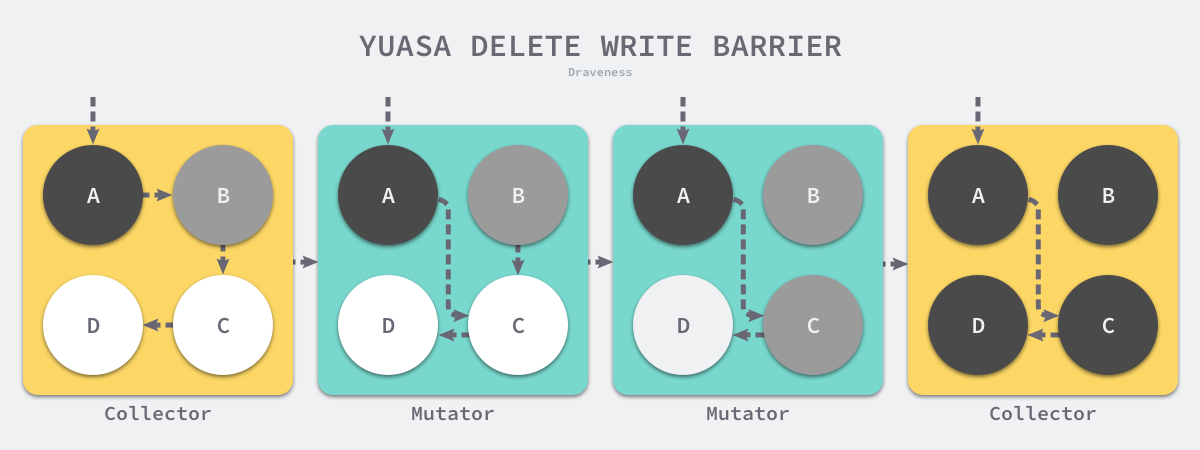
混合写屏障
writePointer(slot, ptr):
shade(*slot)
if current stack is grey://当前栈没有扫描,是白色
shade(ptr)
*slot = ptr
- 将创建的所有新对象都标记成黑色,防止新分配的栈内存和堆内存中的对象被错误地回收
内存逃逸
- 由编译器编译时候生成AST,分析之后得出分配在哪里
原则
- 指向栈对象的指针不能存在于堆中;
- 指向栈对象的指针不能在栈对象回收后存活;
如果函数外部没有引用,则优先放到栈中; 如果函数外部存在引用,则必定放到堆中;
逃逸类型
- 外部引用(类似指针)
- 栈空间不足逃逸(分配过大空间)
- 动态类型逃逸(interface类型,由于编译期间难以确定类型,直接扔到栈上)
参考
- https://zhuanlan.zhihu.com/p/261057034
- https://draveness.me/golang/docs/part3-runtime/ch06-concurrency/golang-goroutine
- https://zhuanlan.zhihu.com/p/113643434 推荐书籍
- Go语言设计与实现
封装
- 封装的私有直接使用的是大小写来判断,关键字都不需要
type Dog struct{
name string
}
func (d Dog) Say() {
fmt.Println("woof")
}
继承(嵌入)
type animal struct {
Name string
}
type Dog struct {
*animal
}
- 嵌入容易产生屏蔽问题
多态
type Animal interface {
Name() string
Speak() string
Play()
}
type Dog struct {
name string
gender string
}
func (d *Dog) Play() {
fmt.Println(d.Speak())
}
func (d *Dog) Speak() string {
return fmt.Sprintf("my name is %v and my gender is %v", d.name, d.gender)
}
func (d *Dog) Name() string {
return d.name
}
func Play(a Animal) {
a.Play()
}
- 底层为和C++类似技术/cpp/面向对象
参考
https://zhuanlan.zhihu.com/p/165621566 https://www.cnblogs.com/apocelipes/p/14090671.html https://www.cnblogs.com/u-vitamin/p/10793554.html https://www.cnblogs.com/dogtwo0214/p/13419080.html

- 小型群聊和普通聊天差不多,只是标记群聊标签,都是写扩散
- 分配seq的方法为使用redis的incr 分布式ID生成 > Redis
- 上行和下行都使用了kafka消息队列的机制
- kafka参考消息队列
- 使用websocket作为长连接通道
详细流程
- 客户端通过webSocket发送消息到msg_gateway
- msg_gateway通过gRPC调用chat的 UserSendMsg() 发送消息
- chat服务主要是本地生成唯一消息ID(去重)和发送时间
- 然后投递到Kafka,等待所有Kafka的Slave都收到消息后判断发送成,gRPC返回
- 给客户端回复ACK,携带错误码和服务端生成的MsgID等
- transfer中的消费组mysql消费到2条消息(发送者的发件箱、接收者的收件箱)
- 持久化到mysql中全量存储,主要是应对后台分析、审计等需求,客户端是从mongodb中拉取的(拉取后删除),这里和微信逻辑类似。微信号称不在服务器存储数据,所以你用微信登录PC端时,你会发现刚刚手机上的消息在PC上怎么看不到?要么是PC端没有pull的过程,要么是离线消息只针对APP端,PC端拉不到。
- 同理,transfer中消费组mongodb消费到2条消息
- 调用redis的incr,递增用户的消息序号,key格式为:"REDIS_USER_INCR_SEQ: " + UserID,所以是用户范围内递增,因为本身用户只有一个收件箱,没毛病。
- 插入mongodb中的chat collection
- 优先通过gRPC调用pusher进行推送,否则走Kafka,通过Pusher消费的方式推送
- pusher也同样通过gRPC调用msg_gateway的MsgToUser推送消息
- 通过websocket推送
- 用户b上线的时候,通过pull从mongodb中拉取离线消息(成功后会从mongodb中删除)
发送端
- 通过websocket创建长连接,安全性依赖https,没有自定义加密,使用json的[]byte数组结构体接收,gate微服务判断包的类型后发送到rpc微服务
- rpc微服务会将消息使用protobuf格式化后推送进入消息队列中(如果是通知类的消息且在线直接在线),并返回成功(并不会保证落库成功之后才进行返回)
- 从消息队列中拿出有两个消费组分别消费,一个负责mysql的直接落库(如果设置了的话)
- 另外一一个拿出来首先经过一大堆内部的chan缓冲
- 先向redis请求seq,使用redis的incr获取seq
- 插入mongo数据持久存储
- 通过websocket推送消息体(因为这部分的可以保证所有的消息seq连续递增,因此可以保证有序性)
接收端
- 上线的时候和tira-im 类似,都是通过seq和redis+mongo拉取消息
- 启动的时候根据mongo中的最大seq初始化redis中的seq
特点
- mysql,mongodb会分别消费这个topic,一条消息会被消费多次,首先通过redis的自增id,然后将消息体储存到个人的mongodb中
- 使用push模型和个人收件箱(个人和小群),消息堆直接推送到客户端
- 大群使用类似helper-im 使用群收件箱,这个小群和大群似乎是创建群聊的时候设置的而不是后续变化的(这个感觉理论上也很难变化)
唯一性
- redis的原子自增,保证seq不重不漏
- 幂等性保证,依赖kafka的特性(存疑)
必达性
- 实际上这个架构还是可能导致消息的丢失的,因为没有确保落库成功才ack到kafka
有序性
- redis生成的seq保证自增保证有序性,这里的redis扩展的时候可能需要上一致性hash的方法
优缺点
优点
- 似乎mongodb承担了收件箱排序的功能,和缓存的功能,没有进行redis缓存
- push模型,在线直接推body,省略上行拉取的过程
缺点
- 从kafka拿出来后直接标记ok,压根没有判断失败后重试的过程,只打了个日志,这样如果mysql断开连接落库失败,会导致消息的丢失
- 依赖redis的原子incr,如果出现宕机,需要从mongo中恢复最大的序号,redis可能成为一个瓶颈
架构图

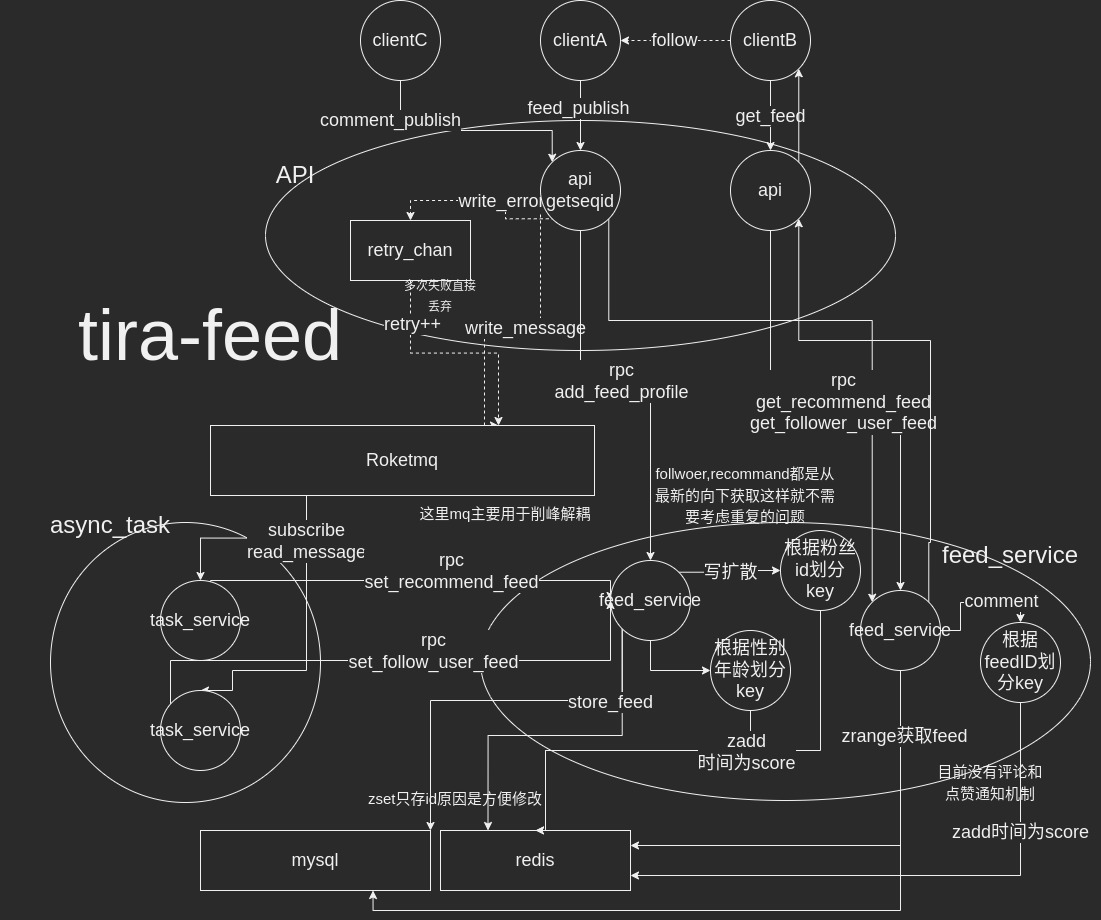
- feed流根据时间拉取最新的数据,每个用户有一个关注者收信箱,用于关注的feed流
- 每个用户根据年龄和性别划分有一个公共的收信箱,每次拉取的都是最新的和最近的
- roketmq参考消息队列
具体流程
api微服务
- 上传feed流的用户首先通过api微服务http上行请求(格式具体不是json而是protobuf),发号(通过全局发号)
- 通过rpc调用feed微服务,将上传的feed落库,图片和location和内容一共三张表,通过主表标识是否有图片和地理位置
- 通过异步协程,将消息加入消息队列中,如果加入失败,塞到chan重试
- 落库成功后直接返回成功
- 拉取时候先计算个人是属于哪一个zset的推荐流的,算不出就用全局推荐流
task微服务
- 有两个消费者组,推荐流和关注流,每条消息都需要经历两次消费
- 关注流查找所有关注了的人(通过rpc调用),然后异步将feed的id加入个人关注zset队列(每个人都有一个zset)中(写扩散),key为id
- 推荐流先加入全局的feed(通过rpc调用),通过发布者的信息(年龄和性别)分别写入不同的zset(每个属性都有一个zset),key为id,读扩散
feed微服务
- 当拉取个人关注流的时候,直接拉取zset最新的id(也可以offset和limit),(这部分可能有问题,当拉取的时候又有更新,offset和limit是不准确的,而且无法实时同时)
- 拉取推荐流也是类似,先计算个人的属性,拉取最新的feed流
tira
设计图
架构图

时序图

唯一
- 客户端生成ID(通过时间戳作为msgID)
- 服务端使用ID+TO+FROM 唯一标识信息setnx处理幂等性
必达
- 在IM部分的重试队列保证必达
- 服务端回应fin,客户端回应ack,标识受到信息
- 增量拉,避免某条消息丢失
有序
- seqID 递增机制(不连续但是一定自增),号段模式
- 防止seqID号段多次消费使用hash负载均衡使得所有的相同ID落在同一台实例上
- 通过只下发id不下发消息体保证
具体流程
客户端连接
-
请求先打到AWS四层负载均衡器上,然后进入服务器中负责网关的微服务(这部分可以使用nginx代替),微服务通过负载均衡策略将长连接请求打到nginx上
-
和edge-connect建立TCP长连接,生成唯一的tcp-id(自己edge内唯一即可),最好不用socketid,因为socketid复用容易导致出问题,可以维护自增变量(atom)
edge通过edge-id构建redis的消息队列,每个edge都有自己的队列 edge自己有个edge-id(connect-id)用于标识自己是哪个edge
-
edge生成3个协程,一个用于上游消息的阻塞接受,一个用于下行消息BRpop从redis阻塞读取读取到下行消息后放到downstreamchan中等待其他协程处理,一个用于5s心跳包发送保活(每次有消息包来都会重置)
-
将edge-id和tcp-id,以及连接的地址信息加入msg字段向route层发送
-
客户端向服务端发送auth-hello
-
route层先把body中的jwt token拿出来解析,获取uid,通过uid,val为hash,hashkey为resource,在redis检查是否连接已经建立,如果建立下发流冲突断开旧的连接,同时设置过期时间
-
服务端回应auth-reply,参考加密系统 > tira-im加密
-
验证成功后将通过uid,val为hash,hashkey为resource,插入redis,hash-val为tcp-id和edge-id,同时插入redis将tcp-id+edge-id作为key插入redis,val为个人信息和AES密钥,用于route层查找用户
edge全程不感知用户内容,仅仅作为维持长连接工具
数据包发送
-
数据包经过AWS四层负载均衡器打到edge-connect上
-
route先从session拿到对应tcp-id和edge-id对应客户端uid和uid对应的AES-key,然后AES解密得到原始报文,同时更新key的存活时间,应用层保活
这部分session中需要存储两部分的内容,一个是key为uid,val为tcp-id,edge-id等信息,用于保活,另一个是key为tcp-id+edge-id,val为aes密钥,用户获取这个tcp连接的密钥
-
route根据cmd字段分配不同的process同步处理,处理结束之后如果有应答,使用雪花算法生成id组装数据包,马上返回edge层面,edge将其加入downstream chan中下发消息,这部分的逻辑也可以改成插入nsq后立刻返回,inte拿出就返回ok(因为失败毕竟是少数情况,重新放回不会影响太多的性能,避免大量消息因为没有ack而在等待,最重要的是,需要修改字段标记处理阶段和重试次数),如果处理失败修改继续放入队列延迟重试(这部分可能造成消息的积压),向connect中推送也使用(这个一般不涉及处理连接失败和重试,而且这部分消息丢失的代价较小,因此不一定需要使用消息队列),route将数据包放到integration层立刻返回
-
integration拿到消息后进入复杂处理消息逻辑
- 检查消息合法性,是否被拉黑之类,被拉黑先客户端下行系统消息发送失败
- 通过sendid+recvid+clientid作为key,setnx插入redis,作为幂等性判断若插入失败证明信息已经发送,数据库总结 > 幂等性处理,
- 通过gennerator生成seqid(保证有序递增,不要求连续tira-others > gennerator,以个人维度发号)
- 消息落mysql数据库(这里使用to_id作为hash落库,查询自己发的消息麻烦,因此这个模式适合于android自带记录的私聊),这里使用seqid拼recvid作为private_key防止冲突
- 消息落redis,缓存时间为5分钟(这里没有进行判错校验,可能导致重复落mysql库)
- 加入redis的zset队列,seqid为key和val(没有进行判错校验,可能导致zset重复插入一直失败)
- zset队列相当于helper中的收件箱,个人和所有人的对话收件箱都在这里
- 这里注意:如果zset找不到这个key或者查的比里面最小的还小(比如出现宕机现象),需要从数据库拉取之后放入redis缓存容灾
- 获取redis zset最新的seqid,构建syncpull包,先to的所有在线resource发送syncpull,要求其下拉消息
-
syncpull包到route层,查询包中的uid对应的tcpid和stream-id,将消息塞到redis的消息队列中
-
edge从redis拿到消息封装之后塞到downstreamchan中等待发送
消息接受
- 客户端收到syncpull要求之后,检查自己的seqid和服务端发过来的seqid大小,如何自己的比较小,就把自己的seqid作为起始seqid发送syncpull请求
- edge层面直接转发到route层面
- route层面转发到integration层面
- integration层面通过zset找到比客户端seqid大的所有seqid,先在redis中找消息,找不到就去mysql找,找到之后将消息一条一条sendmessage返回到route层面,最后加上一个ack标识消息发送结束(否则客户端不知道消息什么时候发送终止)
- route将每个消息加密之后一个一个塞到redis队列中(每个TCP包大小有限,一次可能发不完,因此一个一个发)
- edge继续塞到downstreamchan等待发送
- 客户端收到消息之后,如果读取之后,上行ack携带读到的seqid
- edge传输到route,继续传输到integration,通过chan异步将redis收件箱中比客户端发的seqid小的都删除(删除收件箱)
数据包

-
edge层面packer头固定长度,先接收一个header,根据长度继续接受packer的body,header头包括版本号和长度等信息
-
除了开始的auth-hello的packer不加密,其他packer的body是加密的,密钥为serran+cliran+sessionid的md5结果
-
解决粘包问题关键,包括tcp中的数据也是这样解决粘包的问题
-
加密后的内容中存在content_type以及body,其中body是使用[]byte类型,根据不同大的type映射到不同的结构体(使用protobuf)
-
具体流程:
- edge首先接受header,根据payloadSize接受,并且将接收到的数据映射到Payload中
- edge将包上传到route的时候,封装成UpstreamMessage,使用包头中的type以及Payload的数据组装
var upstreamPacketWrapper = proto.UpstreamMessage{ ID: packet.Header().ID(), ProtocolVersion: packet.Header().ProtocolVersion(), Command: proto.NewCommandWithData(packet.Header().Command(), packet.Payload().Data()), Resource: packet.Header().Resource(), RemoteAddr: remoteAddr, LocalAddr: localAddr, StreamID: streamID, ConnectorID: connectorID,
}
3. route拿到之后根据type进行分发,并且使用protobuf反射解析到结构体 4. route分发到的不同的微服务
// edge-connector
// Header 包头
type Header struct {
//PacketID 用户空间唯一自增(版本号) 64bits
id uint64 `string:"id"`
//协议版本号 8bits
protoVersion uint8 `string:"proto_version"`
//指令枚举值 8bits
cmd uint32 `string:"cmd"`
//资源标记符:同一组资源需要处理流冲突 8bits
resource uint8 `string:"resource"`
//Payload大小, 最大支持2^31 byte长度数据 32bits
payloadSize uint32 `string:"payload_size"`
}
// Payload 包体
type Payload struct {
size uint32
data []byte
}
// coa-router-service
type UpstreamMessage struct {
//PacketID 用户空间唯一自增(版本号)
ID uint64 `json:"id" msgpack:"id" string:"id"`
//协议版本号
ProtocolVersion protocol.ProtocolVersion `json:"protocol_version" msgpack:"protocol_version" string:"protocol_version"`
//资源
Resource protocol.ClientResource `json:"resource" msgpack:"resource" string:"resource"`
//该包关联的远程以及本地地址,二元组组成唯一的TCP连接
RemoteAddr string `json:"remote_addr" msgpack:"remote_addr" string:"remote_addr"`
LocalAddr string `json:"local_addr" msgpack:"local_addr" string:"local_addr"`
//连接流ID
StreamID uint64 `json:"stream_id" msgpack:"stream_id" string:"stream_id"`
//网关ID
ConnectorID uint64 `json:"connector_id" msgpack:"connector_id" string:"connector_id"`
Command *Command `json:"command" msgpack:"command" string:"command"`
}
type Command struct {
Type protocol.CommandType `json:"type" msgpack:"type" string:"type"`
Data []byte `json:"data" msgpack:"data" string:"data"`
}
难点
- 如何让保证消息的唯一性,客户端有重试机制,大量消息出现时不会出现id重复的问题,宕机重启时候不会出现重复id
- 如何保证消息的有序性,可能出现下行消息的乱序,客户端无法主动解决这个问题,同一个群大量人发送消息时候消息处理的有序
- 如何让保证消息的必达性,弱网情况下下行的消息可能出现丢失错漏的现象,逻辑处理时候可能出现数据库宕机,程序宕机的情况,如何保证必达性
- 如何在多端登录时候下同步消息
- 如何保证消息的安全和隐私性
QA
为什么不使用websocket
- 要求信息加密性要求比较高,实时性要求比较高,因此使用简化版的SSL/TLS达到自协议加密作用加密系统
- 免去http协议升级过程,直接使用TCP连接,更加快速和便捷
- ws在nginx解密,未必到达内部服务可信层
- 公司之前有成熟的设计方案
为什么不使用主键作为seq
- 因为未来设计中群聊功能需要发号.无法使用id作为seq
- 但是这部分会出现群聊消息爆炸导致重要的个人消息拉取慢的问题(因为是一条线,必须先拉去前面的消息才能拉取后面的消息)
为什么不用websocket的保活,需要两个层面保活,如何实现
- session其他服务也需要用,业务层保活必不可少,这两个层面是不一样的,一个代表tcp在线,一个代表用户在线,并不能混用
- session保活依赖redis的自动过期,导致发现的时间长,tcp本地保活发现的时间更加快速,避免无效连接占用堆积的情况
- 缺点是每一个用户都要维护定时器,系统开销增加
//检查当前连接是否存活
//连接存活的机制:
//1) 如果有数据IO,则每一次上行以及下行均会更新activeTime,在30s过期内更新则表示存活
//2) 客户端定期的ping探测机制,能保证至少30s有一次activeTime更新(实际idleTimeout=pingIntervalTime+RT时间)
func (conn *Conn) keepAliveSchedule() {
idleTimeout := conn.srv.config.idleTimeout + conn.srv.config.roundTime
conn.checkTimer = time.NewTicker(idleTimeout)
go func() {
defer conn.checkTimer.Stop()
for {
select {
case <-conn.exitChan:
return
case tm := <-conn.checkTimer.C:
diff := tm.Sub(conn.activeTime)
if diff >= idleTimeout {
logger.Infof("conn[%d] remove staled connection after:%s", conn.ID, idleTimeout.String())
metric.EdgeConnectorCoreMetricReporter.PassiveDisConnCounter()
conn.setState(StateClosed)
conn.Exit()
return
}
}
}
}()
}
- connect层的保活直至维护长连接的状态,session的保活是为了维护用户的登录状态
- wesocket自带保活有以下缺点
- tcp 自带的 keepalive 时间非常久,一般情况业务是不能依赖的,配置在操作系统
- 中间还有个NGINX反向代理服务器,在一段时间内没收到数据也会自动断开连接
- tcp因为是虚拟的,导致没有数据传送时候掉线判断困难,ping/pong让tcp掉线响应更快
- 运营商的NAT,超过5mins没有消息,就会清除NAT映射,强行掐端长连接
IM中读扩散和写扩散的优缺点
读扩散
- 读扩散,以会话为单位,消息只存一份,群和会话作为收件箱,群收件箱很多
- 节约存储空间
- 但是每个群和会话都需要单独的序列号
- 用户需要储存对话列表,根据对话id拉取消息
- 如果是feed流面临合并麻烦的问题
写扩散
- 写扩散,以个人为单位发号,消息发给每个人的收件箱,
- feed流简单,直接拉展示
- 储存空间浪费,以个人作为维度发号
- 实时性很好,但是容易出现'写风暴'的现象
只下发id的缺点是什么
- 多次冗余的请求,浪费带宽,从两次变为了3次
- 延时增加,在聊天频率很高的情况下,本来只需要下发消息体一次,现在变为下发id,上行请求,下行body,特别是在群聊情况下容易混乱,一次请求没有结束,第二个又来了
- 增大了内存的消耗,必须引入缓存的机制(因为异步化)
- 如果是http请求的话可能出现http的body过大,导致响应时间更加长的情况(应该通过http的压缩)
只下发id的优点是什么,为什么不直接下发消息体

- 有序性的核心保证,拉取返回都是按顺序返回(因为有可能推送顺序问题,丢包的问题)
- 一定程度上保证了必达性,因为即使中间缺失也可以拿到完整正确的
- 一定程度上减轻了写风暴(即群聊的消息大量下发)的压力,减轻IM系统的压力
- 实现异步化拉取,上线拉和在线推的逻辑复用
- 将http和im模块独立,使得IM长连接系统压力减少
- 不需要ack了,pull成为ack,批量下行可以进行压缩,减少流量损耗
如何实现id和消息体两者相结合
双链机制
- 可以改进成为推送body,携带上一条的msg_id,客户端判断上一条是否是,如果是,那么接受这条,更新最新的msg_id,如果不是,那么上行拉取请求,从自己的的msg_id开始拉取,这样可以网络ok直接下发body,减少交互流程,网络不ok恢复成原来的,也可以保证通过双链保证有序性和必达性,这个方法有缺陷,需要查询上一条消息的msg_id,但是在并发写的情况下会出现读到的不一定是最新数据的读写一致性问题
微信机制
推送模型

- 下发ID和下发data两种模式相结合的形式
- 下发模式分为notify和data两种模式,data为数据体模式,notify为下行ID的形势
- data模式明显比notify模式快,但是可能出现消息丢失的现象(除非使用双链,但是双链重试使得效率降低),因此微信采取的data模式时候是在服务端转换的(接入层更改),这部分意味着由服务器保存一份用户接受到了的最新id,然后通过这个id查询你需要的消息体,打包下发
- Data的状态需由客户端触发形成,触发的时机为客户端主动上服务器来做过一次消息收取的请求。由于在Data状态下需由服务器的ConnectSvr主动去ReceiveSvr获取增量消息,服务器必须知道客户端此时的sequence才能做到通过sequence的比较增量下发消息。所以在进入NotifyData状态前,需等待客户端主动做一次消息收取的请求将此时客户端的sequence保存在ConnectSvr中。
- 在Data状态下,客户端必须对服务器下发的每一个Data进行Ack,并且服务器在下发了Data未收到Ack的这段时间内需关闭Data状态(即在图2的2.7和2.8步骤之间不能再做NotifyData下发)
- 直接推送更加快,但是可能出现乱序和丢失的问题,因此需要严格控制下发body的触发条件
如何实现多端接受消息
- 当自己下发消息的时候,将消息的id和to_uid下发,其他端就通过id和to_uid拉取自己的消息体(to_uid是必须的,因为通过to_uid分表),如果是helper类型的只需要下发groupid和msgid
当网络频繁断线(坐地铁怎么处理)
- 断开后不立刻删除状态消息,标记状态为断线,启动超时删除,短时间重连这更新为新连接
如何解决大量定时器占用大量内存资源造成消息卡顿问题
- 传统的计时器使用二叉堆实现,存取的复杂度是log(n),可以考虑使用时间轮实现,计时系统
这个项目的指标
- 日活10W,每个人平均2s就会有一个上行发消息(发消息,拉取的请求,心跳保活的请求综合),日活10W用户每秒约5000请求,峰值月为3倍,QPS大约在15000左右
- 发送的R99大约在100ms(通过connect层的rpc和route层的rpc,session的rpc共同作用,包括逻辑处理和加解密,20ms消息队列延迟),接受到的延迟大约为200ms(测试方法为自己想自己发送请求,两者的时间戳相减,再减去服务器携带的时间戳),时间主要用于消息在消息队列中的延迟(20ms),核心逻辑处理(10ms(mysql插入(1ms))),50ms的双向延迟
- 单机最大并发数大约在5w左右
最大连接数 = (内存大小/单个连接占用内存) * 系统负载因子,如果不够会触发k8s的扩容机制
项目的性能瓶颈在哪里
- 微服务的层层调用(约60ms的延迟)
- 消息在消息队列中的延迟(两个共约40ms延迟)
- mysql的插入,核心层面的逻辑处理(10ms左右)
高并发下可能的问题
- mysql 写的 QPS 大约在几千到上万之间, 如果出现大量的单点的消息发送的情况下, 可能会出现 mq 的消息堆积, 实时性变差
- 一旦mysql 扛不住挂了, 非常容易引起雪崩效应(重试接着失败导致整体服务呈现不可用)
- 继续分表, 以及横向扩容 mysql 是一个思路, 还有个思路是冷热分离, 中间加一层 mongodb, mongodb 存储7天的数据, 异步同步到 mysql, mongodb 能扛住非常大的写压力, 或者考虑底层存储使用 leveldb 这种, 但是这样的话列表的list 也需要使用 leveldb 存储(leveldb 不支持直接的范围查询)
如何实现消息的撤回和审核
- 下发一条新消息,这条消息指向需要撤回的消息,前端收到之后自动撤回消息(通常使用这种)
- 快速,不需要修改消息的原有状态(这部分需要操作缓存和刷盘)
- 不需要更改现有的逻辑代码,代码入侵程度小,实现简单,逻辑复用(只需要发送消息)
- 需要消耗额外的空间去存储一条消息(磁盘是不值钱的,这点损耗可以接受,而且还能记录撤回时间等有用信息)
- 消息本体没有改变,如果是通过接口api请求依旧可以看到消息体
- 这种底层使用leveldb是最好的,这样可以直接set原来的key然后下发消息
- 删除缓存,修改数据库中消息的状态,下发websocket通知在线用户,离线用户拉到的就是已经修改状态了的
- 不需要消耗额外空间储存
- 消息本体改变,可以直接进行过滤,返回的消息内容不可见
- 慢,需要删除消息缓存和修改数据库(通常撤回的消息都是热点消息,因此比较慢),大新系统中不推荐
如何实现消息的已读未读
- 使用一张表每条消息插入一行,然后ack的消息修改对应消息的状态,每个line记录unreadid和readid,messageid(感觉飞书使用的是这种),客户端拉取消息后在拉取消息对应的已读未读状态,需要额外拉取
- 浪费空间,每条消息都对应一行
- 修改方便,可以实现每条消息的每个人识别已读未读,不会出现后面进群的人自动已读前面的消息的情况
- 修改速度慢,如果一个人连续读了100条消息,需要修改这100条的状态,在大群中更加明显
- 因为是另一张表,堆原有业务入侵小
- 需要额外拉取状态
- 群人数没影响
- 使用一条新消息,状态修改,其他不变,指向原消息,这样拉取到这条的时候直接替换原来的消息
- 可以和撤回消息的通道复用,更加简洁
- 极度浪费储存,一个ack对应一条消息(当然可以多个ack对应一个消息但是依旧非常浪费),这里如果底层存储使用的是leveldb,完全可以等到merge时候合并,参考 LevelDB底层
- 不需要额外拉取
- 下发已读的通知,也不需要上线拉取
- 每一条都需要更改一次,和上面一样的问题
- 记录用户的最大ack值,客户端拉取群所有人的最大ack,比较这个group的msgid和ack比较,
- 只能用于group维度发号的情况,不能用于个人收件箱的情况,个人的msgid不是一样的,无法使用,使得使用的范围小
- 当群里人很多的时候,计算和拉取都很麻烦
- 直接在message字段存储加入is_read字段
- 只能用与私聊,群聊人员变动无法使用
- 设计和使用简单
- 如果是最后设计了来说
- 如果是个人会话,个人收件箱+is_read/新消息
- 群会话 群收件箱+记录最大ack值
个人维度和会话维度发号优缺点
个人维度
- 可以实现个人的收件箱,
- 消息储存的冗余,每个群个人的收件箱都需要有一份msg_id,对于大新群聊来说每条消息大量插入每个人的收件箱使得其非常慢(每次插入是log(n))
- 无视会话的数量,每次拉取消息只需要拉取自己的收件箱,实现无感知
- 统计维度消息数量简单,适合用于私聊,不适合用于群聊,私聊不用生成group,可以直接发送,更加简单
- 必须设计新的发号器,用这个做群聊出现风暴的问题
- 拉取历史记录麻烦,自己发的消息查出来需要应用手动合并
会话维度
- 已读未读的实现更加简单,拉取历史消息更加简单(不需要),传播速度更加快,因为只需要插入一次zset
- 每个群维护一个发号器,每个人拉取未读消息麻烦,未读消息数量统计麻烦,适合用于群聊,不适合用于私聊,因为每个人都需要维护一个group,数量变得非常大
- 可以使用mysql id作为发号,需要维护每个人对应每个group的未读消息
- 其实可以结合使用,个人私聊使用个人收件箱,群聊使用群收件箱
微信方案
消息模型
- ack的在进入界面,退出界面,在界面停留几秒都会发送ack
私聊
- 私聊以个人维度发号,和tira中的私聊设计类似
- 这样可以很方便做管理(只需要拉一条时间线上的消息)
- 微信这部分的私聊消息很可能压根没有做MQ,估计为了保证不会丢消息,一定是写消息成功落库之后才会返回前端成功.收件箱为了持久化存储,使用的不是redis这种内存数据库,估计是类似leveldb这种
群聊
实际上微信基本上都是用户一个inbox,使得不支持大群,而且不好做已读未读
- 群聊使用群聊收件箱的机制,和help的机制一样,维护群聊收件箱
- 群聊维度使用群维度发号,以群id维度发号,类似读扩散
helper中为什么需要两个hash而不是一个
- 一个用于记录ack(做已读未读),一个用于记录未读群聊,如果使用一个那么第二个hash就不能删除项,每次拉取都需要遍历hash中所有的session(即群聊),非常低效很慢,分开可以优化未读信息的通知
如何实现容灾
- redis使用集群模式加主从架构加哨兵监控,崩溃时候可以自动切换成为slave的redis成为master
- mysql使用一主一从的双机主备高可用,如果master挂了slave自动成为masterMysql底层原理 > keepalive
- 微服务使用k8s统一管理,如果出现负载过大,会生成新的docker微服务
- 使用mira和普罗米修斯和grafana监控状态,警告接入飞书通知,通过grafana查看请求QPS(记录消息数,成功数,rpc调用平均延时)
- 如果逻辑层连接数据库一直失败(网络波动),尝试次数过多后会将数据写入文件并发出预警(这部分可以变成使用消息队列,只有落库成功才返回处理成功,否则让数据库进行重试)
- 限流器,避免出现服务的雪崩效应(A崩了,B承受A+B的请求也崩了),尝试失败后前端直接显示红点或者进行重试
- redis崩了从mysql拿数据的时候异步缓存到redis(这里可能出现刚上线请求压力大的问题,容易产生缓存雪崩,可以上限流或者提前缓存),这里的缓存是缓存收件箱
长连接维护占用大量的资源,如何优化
- k8s水平扩展增加实例
- 拆分im和http成为两个部分,减低im部分的压力, 这也是下面 helper 的设计原因, 通过拆封 http 服务和 IM 服务有效降低服务负载, 并且解耦 长链接和 http 链接的部分, 有效避免了因为 长链接服务 down 导致所有服务不可用的问题
哪部分架构自己设计的,开发时间人员
- 路由层的具体逻辑自己设计的,参考了openim,goim等
- gennerator自己实现的,设计参考了美团leaf分布式id生成器
- 微服务的划分是参考了之前的im项目
- 一共3+1个人,花了两个月多一点
如何实现优雅退出/升级
- 微服务框架中自己携带有退出函数,接受退出信号
- 如果是 http 服务, 直接通过服务注册平台下线实例, 然后上线新实例解决
- 如果是长连接的部分
- 当出现退出信号的时候,查找所有的长连接,下发特定的通知然后断开长连接,清理长连接部分,客户端收到这个不会提示
- 高级一点的方式是通过 fork + exec + 信号的技术, 通过发送信号升级, 通过 fork+ exec新的程序实现升级, 老的直接 exit (利用的是 fork之后可以基层 socket的特性), 但是普遍比较复杂 + 如果是 k8s + pod 的形式难以执行 ,进程级别倒是适用
- k8s创建新的pod之后发送信号给旧的pod,旧的pod,会有一个最大退出时间的限制(超过直接kill),同理知道所有的pod全部被替换
如果出现错误包格式如何处理
- 直接掐断这个tcp连接,关闭改tcp连接
如何提高系统的高并发及可用性
- 可用性高并发核心还是分布式架构 > 保证高可用性的方法
- 水平扩展微服务提高承载能力
- 使用消息队列实现异步和解耦削峰
- 服务降级的兜底策略
- 数据库的容灾备份
产品迭代过程
- 第一版使用sync_pull打包成一个结构体一起发送
- 自己指定协议的包长度有限制,一次性推送未必足够长,因此采用FIN和LV方法
- 使用redis作为List缓冲,如果一次性发造成失去redis缓冲的作用
- 因为edge_connect同时服务多个用户,太长的包容易让connect长期为这个连接工作
- pull代码逻辑复用
- 因为改成一个一个发送,需要fin告诉客户端发送结束,也需要lv让服务端删除缓存,没有fin包,客户端无法知道什么时候发送结束,无法合适的时机发出lv
- 第一版使用uid作为streamID
- 开始没问题,后来出现多个设备登陆问题出现二元组相同的情况,不支持多端,因此使用雪花ID生成唯一ID或者号段ID,保证连接唯一性
tira-room

流程
- 客户端进入房间之前首先通过https发送请求,携带uid和roomid,后端处理之后返回token(这里也可能是sessionid)
- 客户端和edge建立tcp连接,发送hello包,使用公钥加密(token,cliran),route解密之后下行serran,返回,并且下行event到edge传递private_key以及uid,roomid
- edge判断是否是本地没有订阅的room,如果是就订阅room
- 上行消息发送的时候在edge进行解密,塞到c2r的chan之后立即返回达到异步处理
- c2r只负责拿到roomid作为消息的seq,并且把包装好的消息下行到route,route将这个消息发布到redis的channel(这个channel是以room为维度的,每个room都会有自己的channel)
- edge将这个channel下面的所有连接拿出来依次下发
QA
为什么edge保存privatekey
- 这里和私聊不同的地方在于不同人有不同的private_key,这样route发送一条消息就需要加密非常多次,性能上不可接受,因此在edge下发前自行加解密更加快和方便
为什么不是一个room一个privatekey
- 理论上可以,甚至我觉得在这个聊天室场景下更加好,没有用是考虑了和私聊同样的加解密步骤,改动小,以及安全性的考虑(因为room的privatekey是公共的)
- 如果是一个room一个privatekey,在生成room的时候生成放在session中,可以直接在下行的时候在route加密,这样第一更加贴合私聊的下行方案,更重要的是edge可以做到不感知业务,其实更加好
为什么使用订阅者模型而不是list
- 大量消息和大量订阅者,而且可以忍受消息一定程度的丢失,订阅模型更加合适,如果是list,无法实现消费多次多个edge拿消息
- 参考数据库总结 > redis做消息队列的几种方式以及缺点
helper
群聊实现
c2c翻版
- 使用收件箱逻辑,推送到,个人收件箱,但是检测type为group则在其他表查
- 依旧通过写扩散解决问题
help版本
- 业务上回避generator,更加简洁(但是这样导致做冷热分离很麻烦)
- 通过读写结合来实现

具体流程

- 客户端建立长连接之后,通过http发送上行请求,handle层简单判断之后放到service层
- 进入service复杂逻辑
- 幂等性校验
- 落mysql库获取seqID
- 加入redis缓存
- 加入group的zset(用于记录群里面的消息ID)
- 查询群成员
- 给除了自己以外的所有群成员添加收件箱(收件箱为hashmap结构,key为groupID,val为最新的非自己发送的msgID)
- 获取在线人员的名单
- 通知在线(除了自己)的人,通过edge长连接下发消息
- 异步审核和异步下发微信通知

区别
- 从个人收件箱转为群收件箱,减少了消息的冗余,个人的新消息通知使用个人的redis hash,维护客户最新的ack和最新的消息msgid,通过对比两者的值决定自己是否有新的消息,无法维护客户端最近的ack和最新的消息,缺点是取法具体显示多少条消息未读,优点是拉取历史消息更加方便(因为是基于群维度),而且因为只需要插入一次zset传播速度更加快
- 使用mysqlid作为seqid,不需要generator,因为消息以群维度生成和发送,无上面问题
- 将上行消息http化,实现逻辑更加轻量化,读扩散模型,tira为写扩散模型
- 长连接占用大量内存资源,IO密集型,因此将IM和http拆分成两个系统
产品迭代过程
自己发消息的问题
- 一开始使用set作为收件箱,保存未读group,发现自己发的消息出问题
- 如果im下发,那么会出现自己的消息是未读消息
- 如果不下发,因为拿到的msgid不是最新的(没有自己的msgid),无法ack
解决
- 使用hash作为收件箱,自己的消息不写收件箱,始终使用不是自己发的最新的msgid作为收件箱group的值
为什么使用http 服务和 im 服务拆开两个程序
- 业务逻辑角度上看 , http 服务主要在于 CPU 的逻辑运算和外部调用, 是一个cpu 为主的, IM 维护长连接需要的内存很多, 是内存为主的, 如果放在一个服务上面, 对服务的压力很大, 相当于承载了所有的功能, 拆开降低耦合度, 而且 http 部分迭代非常频繁, 长链接部分比较稳定, 为了避免迭代的异常影响也应该拆开
- 安全性上看 , 加密系统是现成的, 可以直接使用 https 的加密, 维护长连接部分不涉及秘密, 不需要进行加密
- 容灾角度上看, 放在一起一旦程序被kill 意味着IM 完全不可用, 拆开的话即使 IM 挂了 发消息拉消息的功能也不受影响,只是损失实时性, 这部分完全可以通过客户端发现 IM 异常之后走定时拉取的兜底逻辑进行止损
等待改进
- 消息可以类似openIM做冷热分离,避免mysql压力太大,消息的分级存储,14天内的消息可以直接存在leveldb中(毕竟消息的写多,读大多数是缓存读),或者mongodb中(IM系统几乎不涉及事物特性)
- 使用消息队列代替chan和redis的list,保证消息的进一步必达性,如果真的添加消息队列nsq,逻辑层从nsq拿出来后进行处理,拿出就返回ok(因为失败毕竟是少数情况,重新放回不会影响太多的性能,避免大量消息因为没有ack而在等待,最重要的是,需要修改字段标记处理阶段和重试次数),如果处理失败修改继续放入队列延迟重试(这部分可能造成消息的积压),向connect中推送也使用(这个一般不涉及处理连接失败和重试,而且这部分消息丢失的代价较小,因此不一定需要使用消息队列)
- 消息的必达性还是不能真正保证,最好是直接先落库才返回成功
- 没有做已读和未读(可以通过个人收件箱的hash存储自己读到的和最新的来实现)
- 无法确定每个group有多少条未读的消息(可以通过个人收件箱的hash存储自己读到的和最新的来实现)
- 客户端发送消息的顺序可能和服务端处理接收到的顺序不一样,导致接收方乱序(可以通过客户端的client_msg_id递增,服务端保存上一条client_msg_id,如果发现不匹配就返回失败,类似双链的机制,保证消息形成一个链式结构,但是还是无法解决服务端异步发id可能混乱,这里可以考虑将幂等性处理和发消息id放到前面(这两个都不怎么耗时)或者通过滑动窗口的形式,一次性处理多条消息(按照一定顺序),缺点是通讯重试次数太多,性能差)
- 可以改进成为推送body,携带上一条的msg_id,客户端判断上一条是否是,如果是,那么接受这条,更新最新的msg_id,如果不是,那么上行拉取请求,从自己的的msg_id开始拉取,这样可以网络ok直接下发body,减少交互流程,网络不ok恢复成原来的,也可以保证通过双链保证有序性和必达性,如果是直接下发body模式,这个逻辑也可以应用在下行双链保证有序性(每条消息携带上一条消息的id) , 这个的问题是怎么确定上一条 id 是多少 , 除非能保证连续绝对递增
- 没有做限流,太高的qps容易使得系统的消息处理时间大大延长
- 没有做系统的容灾,redis挂了使得未读信息通知消失,mysql挂了会使得消息发送失败当客户端以为成功的事故
- 没有做弱网情况下的优化
- 幂等性应该做双重幂等,redis+数据库private_key设置
- tira-im群聊的扩展性很差,因为按照这个模型,群聊1000个人就要发1000个号,插入1000次zset收件箱,导致写扩散的现象非常明显
- push 实例扩容时候一致性hash 没办法马上让其负载均衡, 很容易出现刚来的负载比较低的问题(因为 tcp长连接没办法直接转移)
参考
- http://www.52im.net/forum.php?mod=viewthread&tid=3631&highlight=%CE%A2%D0%C5
- https://juejin.cn/post/7070290856967667742
match
- 陌生人匹配服务

- api微服务先通过个人的信息计算一堆参数,然后通过rpc调用match微服务
- match将这堆参数拼接成string插入redis,通过这堆参数各种各样的计算,得到不同的zset,(key为时间戳),将个人的匹配信息加入redis(key为uid,val为uid)设置超时时间作为结束匹配的标志,
- 每一个zset中都有协程在brpop,拿出来之后使用这个人的uid加锁,标识已经在匹配了,分配唯一match_id
- 继续从队列中拿出用户进行匹配,成功匹配通过长连接下发匹配成功的通知
- 这部分非常复杂,只是简单的思路,具体的后面有空再看吧
gennerator
- 分布式ID生成器

- 通过提前拿号和异步检查分配的办法(每次分配之后查一下是否已经分配超过60%,如果超过了,异步开协程那下一个号段)解决mysql速度不够快的问题
- 号码一定递增,但是不一定连续(因为如果宕机,下次回复只能拿到下一个号段,无法确定上一个号段是否发完了)
- 通过负载均衡,使得同一个号码的拿取服务全都打到同一台机器上,避免了出现因为多个号段同时发号导致号码不递增的问题
- 通过一致性hash实现自动容灾和恢复,类似[[redis实现#一致性hash算法(一致性哈希)]]
- 构建主机数组,使用二分搜索搜索key对应处理的主机端口ip
- 当处理的机器更改时候(添加或者删除),向旧的机器发送删除内存对应号段的通知(这里需要确保加入的都是新启动的,内存没有号段的,这个特性依赖微服务框架的隔离机制),这里的删除不是新的机器删除,而是框架中自带的client调用端发rpc请求删除
- rpc请求拿到所有的发号机器的ip和port,一致性hash算出自己访问哪一台机器
- 检查是否和上一次请求的机器相同,如果不相同,向上一台机器发送删除的通知,如果因为下线,连接失败没关系,如果在线,会删除缓存中的号段
- 向请求的机器发送rpc请求申请发号
- hash环的计算全部都在client中,和服务端无关
- 使用的是类似锁的机制(实际上使用的是sync.map)
//从本地缓冲池获取已经设置的Segment Getter,并且调用获取设置的segment执行
//检查是否能够生产ids, 无法生成则回源获取segment
if cachedSegmentFn, ok := pool.segments.Load(key); ok {
segment := (cachedSegmentFn.(SegmentIDCacheGetter))()
if segment == nil {
logger.Errorf("Generator segment not found:%s[3]", key)
return nil
}
var isAccord bool
nextIDs, isAccord = nextIDFn(segment, 0)
//满足条件1
if isAccord {
return nextIDs
}
applyed = int64(len(nextIDs))
//重置key对应的segment fn, 否则sync.Map的LoadOrStore无法正确执行
pool.segments.Delete(key)
}
//multi-goroutine情况下并发获取的都是waitGetter,仅当唯一获取了segmentFn的Goroutine完成初始化后返回
var startTime = time.Now()
var initSegment *entity.NamespaceSegment
var wg sync.WaitGroup
wg.Add(1)
waitGetter := func() *entity.NamespaceSegment {
wg.Wait()
return initSegment
}
//only one goroutine to call fn()
//大量协程尝试写入这个sync.map
segmentGetter, loaded := pool.segments.LoadOrStore(key, SegmentIDCacheGetter(waitGetter))
if loaded {
//因为多个协程竞争导致,大部分协程到这个地方,然后进行等待,**注意,这里等待的并不是自己的wg,因为自己的wg压根没有成功存进去,等待的是成功存进去的wg,即拿到执行权限的wg**
//block here wait first getter done
segment := (segmentGetter.(SegmentIDCacheGetter))()
if segment == nil {
return nil
}
nNextIDs, isAccord := nextIDFn(segment, applyed)
if !isAccord {
return nil
}
return append(nextIDs, nNextIDs...)
}
//成功写入的协程到这部分
//Store成功,初始化Request
initSegment = segmentFn()
wrapGetter := func() *entity.NamespaceSegment {
return initSegment
}
pool.segments.Store(key, SegmentIDCacheGetter(wrapGetter))
//完成wg,通知其他协程起来
wg.Done()
////////////////////////////////////////////////
// 这部分是nextIDFn的内容,底层还是使用atomic实现的
func(segment *entity.NamespaceSegment, applyedN int64) ([]int64, bool) {
var apply = n - applyedN
//有效的ID列表, 超出保留的ID列表
var validIDs []int64
var counter *int64
if iCounter, ok := globalCounter.Load(key); !ok {
return nil, false
} else {
counter = iCounter.(*int64)
}
// 注意这里是先进行原子递增,在进行拿出号码,这样可以实现多个协程一起拿的操作
nextID := atomic.AddInt64(counter, apply)
if nextID <= segment.MaxID {
for s := nextID - apply + 1; s <= nextID; s++ {
validIDs = append(validIDs, s)
}
return validIDs, true
} else {
for s := nextID - apply + 1; s <= segment.MaxID; s++ {
validIDs = append(validIDs, s)
}
return validIDs, false
}
负载均衡
类型
- 层次指的是对应网络模型的哪个层次
四层负载均衡
- 通过IP+PORT进行负载均衡,在TCP网络层面进行划分
七层负载均衡(nginx)
- 在四层的基础上(没有四层就没七层)
- 将请求通过应用层协议进行区分和负载均衡
[!question] 垃圾python玛德天天不会对下兼容,天天他妈的报错,和nodejs一个吊样 果然不是用来写大型项目和后端的,兼容性就玩崩
常见错误
ImportError: cannot import name 'html5lib' from 'pip._vendor'
- pip版本太低
curl -sS https://bootstrap.pypa.io/get-pip.py | sudo python3.10
curl -sS https://bootstrap.pypa.iomirrors.aliyun.com/pypi/simple/)
/get-pip.py | sudo python3
设置镜像源
临时
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple <需要安装的包>
永久
pip install pip -U
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
[!NOTE] 清华源403 还是得用阿里的源 Simple Index
虚拟环境创建
创建
pip3 install virtualenv(默认py只带不用安装)mkdir venv;cd venv;python3 -m venv <虚拟环境的路径,可以是.>,在目录下会创建venv文件夹,是虚拟环境的核心文件source venv/bin/activate- 使用
pip3 install -r requirements.txt安装依赖
退出
deactivate
目录关系
- 文件夹需要存在
__init__.py才会被认为是一个包,这种情况下才能被导入,包不能直接运行但是可以通过python3 -m <包名>.<文件名(不带后缀>运行
setup.py
- 是用来构建一个包的方便其他人pip安装
[!tip] 参考 python之setup.py快速了解和使用 - popsicle - 博客园 (cnblogs.com)
requirements.txt生成
pip freeze > requirements.txt不推荐,会生成一大堆乱七八糟的包依赖信息- 推荐方式
pip install pipreqs
pipreqs ./ --encoding=utf8 --force
pip安装
- 运行
$ curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py # 下载安装脚本
$ sudo python get-pip.py # 运行安装脚本
pip镜像加速
- 一次性
pip3 install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple - 永久设置
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
pip config set install.trusted-host pypi.tuna.tsinghua.edu.cn
[!tip] 参考 pip 使用国内镜像源
各种进制的表示
0B00001101 0xff 076
clangd消除警告的方法
- 核心参考官方文档
- 编写项目的
.clangd文件,然后添加需要抑制的内容,这个内容可以根据提示获取
Diagnostics:
Suppress: -Wc++17-extensions
- 头文件检查的,在
.clang-tidy添加
Checks: -misc-definitions-in-headersChecks: -misc-definitions-in-headers
clangd找不到头文件方法
cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=1
- 会生成
compile_commands.json - clangd索引会生成
.cache文件夹
clang-format格式化方法
- 傻逼clangd-format必须制定
-style=file才会根据.clang-format格式化,否则直接 - vim文件可以参考
https://raw.githubusercontent.com/llvm-mirror/clang/master/tools/clang-format/clang-format.py
" BEGIN CLANG-FORMAT CONFIG
" imap <C-K> <c-o> :pyf /home/zhuling/code_standards/format/clang-format.py<cr>
nmap <leader><leader>f :pyf /home/zhuling/code_standards/format/clang-format.py<cr>
function! Formatonsave()
let g:clang_format_path = "/home/zhuling/code_standards/format/clang-format"
let l:formatdiff = 1 " 保存文件时针对改动的代码进行格式化,历史代码不动
"let l:lines="all" "如果保存文件时也希望对历史代码做格式化,可取消该行的注释
pyf /home/zhuling/code_standards/format/clang-format.py
endfunction
autocmd BufWritePre *.h,*.cc,*.cpp call Formatonsave()
" END CLANG-FORMAT CONFIG
compile_commands.json生成方法
- cmake,
apt install cmake
cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=1
- bear,
apt install bear
如何编译的在前面加上
bear --,类似bear -- make,bear make
- clang,
apt install clang
clang -MJ compile_commands.json source.cpp
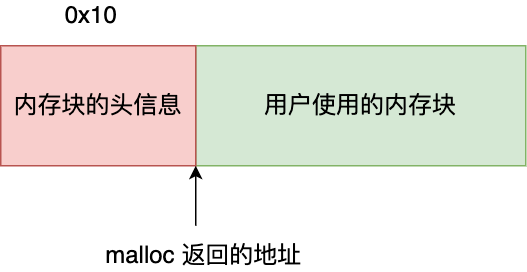
malloc
C++多态的多种实现
- 重载。函数重载和运算符重载,编译期。
- 虚函数。子类的多态性,运行期。 在继承关系中,对于父类的方法我们也同样使用。但是正常来说,我们希望方法的行为取决于调用方法的对象,而不是指针或引用指向的对象有关。
- 模板,类模板,函数模板。编译期
智能指针
weak_ptr
- weak_ptr<T> 模板类中没有重载 * 和 -> 运算符,这也就意味着,weak_ptr 类型指针只能访问所指的堆内存,而无法修改它。
- weak_ptr主要针对shared_ptr的空悬指针和循环引用问题
- 空悬指针问题:有两个指针p1和p2,指向堆上的同一个对象Object,p1和p2位于不同的线程中。假设线程A通过p1指针将对象销毁了(尽管把p1置为了NULL),那p2就成了空悬指针。
- weak_ptr不控制对象的生命期,但是它知道对象是否还活着。如果对象还活着,那么它可以提升为有效的shared_ptr(提升操作通过lock()函数获取所管理对象的强引用指针);如果对象已经死了,提升会失败,返回一个空的shared_ptr
- 当 weak_ptr 类型指针的指向和某一 shared_ptr 指针相同时,weak_ptr 指针并不会使所指堆内存的引用计数加 1;同样,当 weak_ptr 指针被释放时,之前所指堆内存的引用计数也不会因此而减 1。也就是说,weak_ptr 类型指针并不会影响所指堆内存空间的引用计数
static作用
- 如果用 static 关键字修饰的话,该变量便会存 放在静态数据区,其生命周期会一直延续到整个程序执行结束
- 用 static 对全局变量进行修饰改变了其 作用域范围,由原来的整个工程可⻅变成了本文件可⻅
- 用 static 修饰函数,情况和修饰全局变量类似,也是改变了函数的作用 域
- 对类中的某个函数用 static 修饰,则表示该函数属于一个类而 不是属于此类的任何特定对象;如果对类中的某个变量进行 static 修饰,则表示该变量以及所 有的对象所有,存储空间中只存在一个副本,可以通过;类和对象去调用。
强制转换
dynamic_cast
- 用于指针或者引用父类转子类,如果转失败返回NULL
static_cast
- 和C的强制转换差不多
const_cast
- 用于去除和加上const
reinterpret_cast
- 完成任意指针类型向任意指针类型的转换
others
- string的substring函数第二个参数是len长度而不是pos
push_back和emplace_back区别
- push_back 接受一个对象,将其拷贝(或移动)到容器中,而 emplace_back 接受一组参数,直接在容器中构造对象。
- push_back 调用对象的拷贝构造函数(或移动构造函数),将对象拷贝(或移动)到容器中,而 emplace_back 调用对象的构造函数,在容器中直接构造对象。
- 使用 emplace_back 比 push_back 更高效,因为它避免了对象的拷贝(或移动)操作,直接在容器中构造对象。此外,emplace_back 还可以支持可变参数,可以方便地构造带有多个参数的对象。
- emplace_back 的参数必须和对象的构造函数参数匹配,否则会编译错误。而 push_back 接受的是一个对象,因此可以隐式转换类型
编译顺序

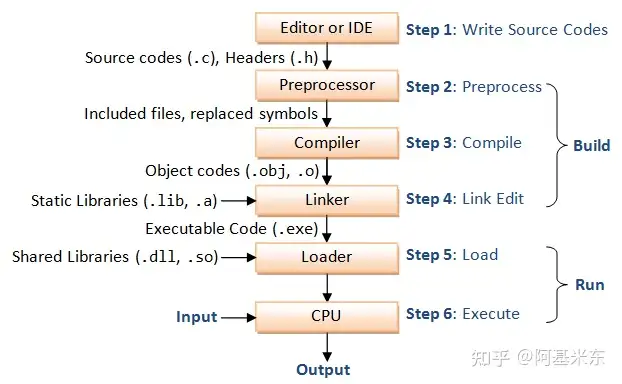
预处理
- 将所有一起编译的
.c文件合并 - 将宏展开计算,将注释以及删除无用字符
- 将头文件内容插入到源文件(因为#include也是宏,本质还是宏展开),头文件路径的添加可以通过
-I - 通过这个步骤的带一个文件包含了精简化后的所有的源代码(当然还是不包括库的)
编译
- 这一步将上一步得到的源代码进行编译成为汇编代码
- 这一步只会检查代码的正确性,不会检测所需要的函数是否有实现,如果函数没有定义,但是引用了会在这里报错,但是定义了,使用了,没有实现,这里还不会报错
汇编
- 汇编器会将汇编代码转换成二进制指令,同时生成与指令相关的符号表和重定位表
链接
- 这一步非常重要,链接器会解析所有目标文件中的符号,包括函数名、变量名等,并为每个符号分配一个唯一的地址。由于不同目标文件中的符号地址可能会相互引用,链接器需要对这些符号进行重定位,即将符号的地址修改为正确的地址。链接器还会将程序所依赖的库文件链接到可执行文件中,以便程序在运行时可以调用库函数。
- 定义了使用了没有实现的函数会在这里被发现,包括引用了外部的
.a静态库但是没有通过-l加入也是在这里发现,一般是白色的undefine的错误,链接器会检查每个跳转的是否ok - 这一步中如果需要加入
.a(linux)或者.lib(win)的路径,可以通过-L,对应-l通常就是静态库的名字
右值引用
类型
- 左值指存储在内存中、有明确存储地址(可取地址)的数据;
- 右值是指可以提供数据值的数据(不可取地址);右值又分为纯右值(prvaule),亡值(xvalue),纯右值指的是类似1,2这种纯数字,这种不能纯数字不能被修改,亡值指的是类似函数返回值,函数参数,临时变量这种临时构建,非引用返回的临时变量、运算表达式产生的临时变量、原始字面量和 lambda 表达式,这部分可以被右值引用修改
- 右值引用可以延长生命周期如下面,可以减少临时对象的构建
int&& value = 520;
class Test{
public:
Test(){
cout << "construct: my name is jerry" << endl;
}
Test(const Test& a){
cout << "copy construct: my name is tom" << endl;
}
};
Test getObj(){
return Test();
}
int main(){
int a1;
int &&a2 = a1; // error
Test& t = getObj(); // error
Test && t = getObj();
const Test& t = getObj();
return 0;
}
- 可以通过移动构造函数减少不必要的构造
std::move
- 将数据转化为右值,标记对象为临时对象
- 本身上并没有什么效率提升,仅仅只是一个转换为右值的功能,但是因为可以转换为右值,可以调用右值的构造函数,右值的构造又可以避免对象的拷贝(虽然左值也可以实现,但是左值更多是copy而不是move,因此会有const,右值就没有const),具体参考
::运算符
- 表示使用某个命名空间下的操作
- 如果前面没有命名空间表示全局的意思,全局的命名空间
宏中使用do{}while(0)原因
- 使用do{...}while(0)构造后的宏定义不会受到大括号、分号等的影响,总是会按你期望的方式调用运行
如果仅仅使用func1();func2(); 遇到使用if加单行语句就会出问题
构造函数=default的作用
- 用于标记使用默认的构造函数,如果有的构造函数和编译器默认生成的一样,字节使用=default(特别是拷贝构造函数)
C++代码计算运行时间
- 参考示例
int main() {
// "start" and "end"'s type is std::chrono::time_point
time_point<system_clock> start = system_clock::now();
{
std::this_thread::sleep_for(std::chrono::seconds(2));
}
time_point<system_clock> end = system_clock::now();
std::chrono::duration<double> elapsed = end - start;
std::cout << "Elapsed time: " << elapsed.count() << "s";
return 0;
}
奇形怪状的错误
type nofind 错误
- 一定需要考虑是不是头文件重复包含的问题 A头文件和B头文件都include了对方,导致顺序出问题了,可以考虑用extern 声明避免nofound
the vtable symbol may be undefined because the class is missing its key function
- 类中的第一个虚函数没有实现,导致虚函数表没有办法实现
warning:#pragma once in main file
- 不要编译头文件,带着头文件编译就会有这个错误,确保g++的命令接的全是.cpp的文件
multiple definition of
- 核心是因为头文件中包含了实现(理论上应该放到cpp文件中)
- 因为C++编译器是按照 .cpp文件变异成为.o文件,如果多个cpp引用同一个头文件,每个.o文件都有一份实现,最后.o链接的时候就会出问题
- 但是下面几种情况是例外的
- 内联函数的定义
- 因为内联函数直接被替换了, 不会出现函数的概念
- class/struct/union 定义的函数
- 类里面的函数实现如果放在头文件中默认变成内联的,直接替换不会出问题
- const 和 static 变量
- static限制了变量的作用域,该变量仅在引用.h的源文件中有效,也就是说.h被引用了几次这个变量就被定义了几次,且各变量之间互不影响(各变量具有不同的内存地址)。这种方法不适用于定义全局变量,因为它们不是同一个变量。
- const 默认就是static类型的变量
- 内联函数的定义
[!tip] 参考 zhuanlan.zhihu.com/p/577994847 注意头文件规则,避免链接错误:重复定义(multiple defination) - bw_0927 - 博客园 C++ multiple definition 总结 - 简书
socket broken pipe问题
- 对已经关闭的socket 执行二次写的时候会出现, 可以通过
signal(SIGPIPE, SIG_IGN);解决
如何给random函数设置随机的seed
#ifdef __i386
__inline__ uint64_t rdtsc()
{
uint64_t x;
__asm__ volatile ("rdtsc" : "=A" (x));
return x;
}
#elif __amd64
__inline__ uint64_t rdtsc()
{
uint64_t a, d;
__asm__ volatile ("rdtsc" : "=a" (a), "=d" (d));
return (d<<32) | a;
}
#endif
- 使用嵌入式汇编来获取CPU的时间戳计数器(TSC)的值。TSC是一个递增的64位计数器,它记录了从电源启动或者最近一次复位以来的时钟周期数。64位架构中,由于TSC的值超过了32位寄存器的容量,所以需要使用两个32位寄存器来存储TSC的高位和低位,并将它们进行位移和合并操作,最后返回一个完整的64位值
sizeof和strlen区别
- sizeof计算char* 类型时候计算的是指针的长度,而不是字符串长度,strlen则看作是字符串,但是字符串不计算
\0,因为\0被视为字符串结束的位置 - sizeof计算char[]类似的时候计算的是字符串长度,而且包括
\0
C++协程实现
- 底层还是通过linux提供的API makecontext实现的,实现可以参考
multiple definition of问题
- 不要把全局变量以及全局方法的定义放在头文件里!!!!,这样就会出错
- 核心是因为编译器编译分开每一个cpp的时候直接他妈的展开了所有的头文件,放在一起编译就不会有问题
- 但是class的静态函数就没问题
spdlog的问题
显示一大堆nodefine的问题
[!tip] 参考 https://blog.csdn.net/CSSDCC/article/details/121854773 https://fmt.dev/latest/usage.html#usage-with-cmake
- 可以直接在makefile中添加
-lfmt手动链接,makefile
代码规范
核心参考Google C++规范 #代码规范
- 注意头文件和对应的源文件实现要放在同一个文件夹中, 不要用愚蠢的include文件夹
命名
- 枚举enum的命名 应当和常量 或宏 一致: kEnumName 或是 ENUM_NAME.
- 宏的命名不要以下划线开头,因为这是C语言标识符保留的
- 变量使用下划线命名法+小写
- 函数和类使用驼峰法+首字母大写
- 命名空间使用全小写,不要出现下划线
- 类内部属性使用下划线命名法+下划线的后缀
player_pos_
Class
- 类应该public放在前面(因为这是直接暴露给使用者的),private放在后面
- set值方法
set_pos(Pos pos)使用 set+属性名字 小写 - get值方法直接使用
pos()使用小写名字 - 类内部属性使用下划线命名法+下划线的后缀
player_pos_
项目组织规范
- 参考 GitHub - chenxuan520/cppnet: Lightweight C++ network library
- 第三方引用的仓库, 如果是编译类型的, 通过 submodule 添加到 third_party , 然后编译时候一起编译, 如果是二进制类型的, 通过脚本进行下载引入即可, 不要直接放到仓库中
- hpp 和对应的 cpp 放在同一文件夹
- test 文件夹是必要的, 作为单元测试存在
错误标识
- 通过返回RC,然后设置RC到string的转移,大多数使用这种办法
- 麻烦,但是标准程度高
- 返回特定的Err结构体,类值go的error,
- 标准,但是通用型差
- 返回int标识类型,参数中携带std::string& err_msg标识错误信息,微信支付方法
- 通常小于0标识系统错误,大于0标识逻辑错误
有用的宏
[!tip] 这些宏必须经两层包装才能被使用
__LINE__ :当前行数
__func__ :当前函数名
__FILE__ :当前文件名
__COUNTER__ :计数器,会随着调用递增
Lambda 表达式捕获
- 默认是使用
=捕捉所有的值拷贝,使用&捕捉所有的引用拷贝 - 如果使用
[x]默认只捕获这个值拷贝,[&x]默认只捕获这个引用拷贝
内存泄漏检查工具 valgrind
- 安装
apt install valgrind - 使用
valgrind --tool=memcheck --leak-check=full <二进制文件> - 注意 这个和cmake > 内存泄漏检查sanitize 冲突不要一起使用
参考(重要)
- project-setup
- files
- https://blog.csdn.net/weixin_51609435/article/details/126571057
基本容器
vector
- 底层为数组
- 新建时初始化一片空间
- 插入元素引起扩容的时候,gcc会申请2倍的空间,拷贝原有数据
- 释放原来空间
deque
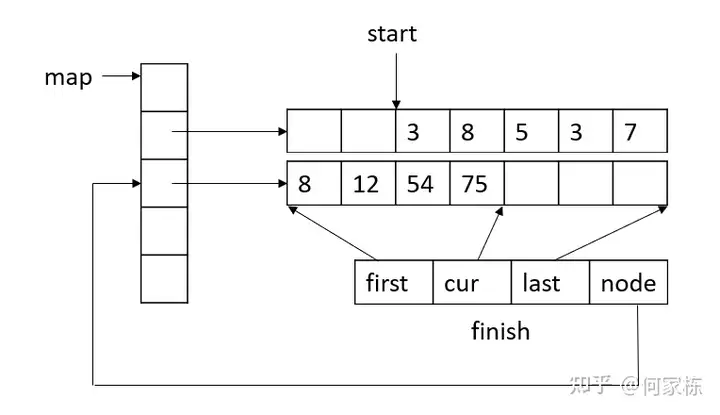
- 底层为map+数组的结构,通过分段存储的结构解决队列进出频繁的问题,本质上还是类似vector的结构
list
- 双向链表
set map
- 底层为红黑树
unordered_set unordered_map
- 底层为hash,使用哈希桶的方法,使用拉链法解决hash冲突
stack queue
- 底层都是deque经过改装适配
priority_queue
- 底层还是vector,然后使用堆排实现
参考
- https://zhuanlan.zhihu.com/p/359878588
架构图

- 连接先通过tcpserver建立连接,使用epoll+多线程的模式
- 读取完整的http报文,出错直接返回请求错误
- 将报文交给deahttp处理,解析http报文,
- 路由通过trie树进行域名的泛匹配
多态的实现
虚函数表
- 虚函数表可以理解为就是一个函数指针数组
functype ptr[] - 虚函数表内部存放的是函数指针,而不是函数地址
- 无论是基类还是子类,(前提有虚函数)都有一个自己的虚函数表,继承时候会直接复制基类的虚函数表
- 重写时候会改写虚函数表里面指针指向的函数地址,达到多态作用
- 子类添加新的虚函数(不是重写,而是新的)会追加在虚函数表最后
- 父类指针拿到子类对象时候,对着表格拿到函数指针,但是实际上拿到的是子类的虚函数表,因此函数指针也是指向子类的,因此实现多态
- 多重继承时候会有多个虚函数表
面向过程区别
- 面向对象是以功能来划分问题,而不是以步骤解决
三大特性
封装
- 类仅仅通过有限的方法暴露必要的操作,也能提高类的易用性
- 增强代码可读性和可维护性
继承
- 代码复用,将这些相同的部分,抽取到父类中,让两个子类继承父类
[!tips] 注意点 继承的时候所有虚函数不要加const, 因为不确定子类重写的时候会不会需要更改, 加上是不合适的
多态
- 提高了代码的可扩展性。
- 只需要根据父类指针调用函数,不用关心子类的具体实现
底层模型
虚拟继承
- 解决菱形继承的问题
- A作为base类会被放在最下面,作为共享部分,然后与base不同部分放在上面
D VTable
+---------------------+
| vbase_offset(32) |
+---------------------+
struct D | offset_to_top(0) |
object +---------------------+
0 - struct B (primary base) | RTTI for D |
0 - vptr_B ----------------------> +---------------------+
8 - int bx | D::f0() |
16 - struct C +---------------------+
16 - vptr_C ------------------+ | vbase_offset(16) |
24 - int cx | +---------------------+
28 - int dx | | offset_to_top(-16) |
32 - struct A (virtual base) | +---------------------+
32 - vptr_A --------------+ | | RTTI for D |
40 - int ax | +---> +---------------------+
sizeof(D): 48 align: 8 | | D::f0() |
| +---------------------+
| | vcall_offset(0) |x--------+
| +---------------------+ |
| | vcall_offset(-32) |o----+ |
| +---------------------+ | |
| | offset_to_top(-32) | | |
| +---------------------+ | |
| | RTTI for D | | |
+--------> +---------------------+ | |
| Thunk D::f0() |o----+ |
+---------------------+ |
| A::bar() |x--------+
+---------------------+
多线程
- 当一个thread对象既没有detach也没有join时候,thread释放(可以是因为栈对象自动释放)后会直接中断程序
- thread提供参数之后不能通过引用传递,但是可以通过指针传递,因为thread构造参数时候直接使用拷贝
- condition_variable的wait调用后,会先释放锁,之后进入等待状态;当其它进程调用通知激活后,会再次加锁
std::unique_lock和std::lock_guard类似,第一个更加灵活,但是性能更加差- 条件变量的用法通常为生产者消费者模型,多个线程用同一个锁+条件变量阻塞
- bind函数可以将函数和参数进行绑定生成一个新的函数对象,这样适配接口就会更加方便
void fun1(int n1, int n2, int n3)
{
cout << n1 << " " << n2 << " " << n3 << endl;
}
struct Foo {
void print_sum(int n1, int n2)
{
std::cout << n1+n2 << '\n';
}
int data = 10;
};
int main()
{
//_1表示这个位置是新的可调用对象的第一个参数的位置
//_2表示这个位置是新的可调用对象的第二个参数的位置
auto f1 = bind(fun1, _2, 22, _1);
f1(44,55);
Foo foo;
auto f = std::bind(&Foo::print_sum, &foo, 95, std::placeholders::_1);// 第二个参数必须是对象作为this指针
f(5); // 100
}
- thread是可以移动的move,但是不能复制copy
条件变量和信号量的区别
- 条件变量支持广播方式唤醒等待者;而信号机制不支持,只能一个一个通知
- 条件变量只能结合互斥量做同步用;信号机制除了做同步,还能用于共享资源并发访问加锁
- 条件变量是无状态的,如果唤醒早于等待,则唤醒会丢失;信号机制是有状态的,可以记录唤醒的次数
多线程demo
class ThreadPool{
private:
std::queue<std::function<void(void)>> task_que_;
std::condition_variable cond_;// 条件变量,通常和锁一起使用
std::mutex que_mut_;// 队列锁
std::vector<std::thread> arr_thread_;
std::atomic<bool> is_close;
std::atomic<int> busy_num_;// 多线程操作,原子变量
public:
ThreadPool(int thread_num){
is_close=false;
for (int i = 0; i < thread_num; i++) {
arr_thread_.emplace_back(std::thread(Consumer,this));// 本身就是右值,可以不适用std::move,如果是左值而且使用emplace_back的话需要std::move避免thread的复制行为
}
}
ThreadPool():ThreadPool(5){}
~ThreadPool(){
is_close=true;
cond_.notify_all();
for(auto& thread_now:arr_thread_){
thread_now.join();
}
}
void Add(const std::function<void(void)>& call_back){
std::lock_guard<std::mutex> guard(que_mut_);
task_que_.emplace(call_back);
cond_.notify_one();
}
private:
static void Consumer(ThreadPool* pool){
if (pool==nullptr) {
return;
}
auto& cond=pool->cond_;
auto& mut=pool->que_mut_;
std::function<void(void)> task{nullptr};
while (1) {
{// 这个作用域结束que_mut_自动释放,为了避免锁的占用
std::unique_lock<std::mutex> unique(pool->que_mut_);
cond.wait(unique,[&]()->bool{return !pool->task_que_.empty()||pool->is_close;});// wait函数首先通过第一个参数拿到锁的控制权,然后不会加锁或者解锁,会等待条件变量的到来,条件变量到来后尝试加锁(多个线程最后只有一个能拿到锁),拿到之后判断第二个参数是否为true,如果为true就继续执行,否则就解开锁继续等待
if (pool->is_close) {
return;
}
task=pool->task_que_.front();
pool->task_que_.pop();
}
pool->busy_num_++;
if (task!=nullptr) {
task();
}
pool->busy_num_--;
}
}
};
void PrintFunc(int print_num){
std::cout<<"run:"<<print_num<<std::endl;
}
int main()
{
ThreadPool pool;
for (int i = 0; i < 20; i++) {
pool.Add(std::bind(PrintFunc,i));// std::bind的作用是生成一个新的函数对象,这个对象可以直接提供参数,达到参数简化的目的
}
sleep(2);
return 0;
}
参考
- 深度探索C++对象模型
Git 其他类型操作
分支重命名
本地
git branch -m <old_branch_name> <new_branch_name>
远程
git push origin <new_branch_name> //新建分支
git push origin -d -f <old_branch_name> //删除旧的分支
回滚
git reset --hard(强制) dhcsdvbhfsjb
git reset dhcsdvbhfsjb
Tag
git tag v1.0.1 #为当前打tag
git push tags #推送tag
git tag #查看tag信息
- 删除tag
# 当前
git tag -d <tag_name>
# 远程
git push origin --delete <tag_name>
pull警告
git config pull.rebase false
git merge
merge 回退
git reset --merge
git merge --abort
merge前检查冲突
git merge --no-commit
revert和reset区别
-
revert 生成一次操作相反的commit, 达到回滚的目的
-
reset直接向前移动指针ref
cherry-pick
-
作用: 将分支的某一次提交应用到别的分支上
-
用法
git checkout branch # 切换向改变的分支
git cherry-pick <commitHash> # 提交的hash
or
git cherry-pick <branch>#默认最近的提交
git cherry-pick <HashA> <HashB> # 一次添加多个提交
git cherry-pick <HashA..<HashB> # 一次添加一系列提交
git stash
- 作用
用于临时保存目前的状态,紧急切换分支
- 使用
git stash #保存
git stash save "test-cmd-stash" # 添加stash信息
git stash list # 列出
git stash apply # 应用stash
git stash apply stash@{2} # 应用stash
git排序文件大小
git rev-list --objects --all | git cat-file --batch-check='%(objecttype) %(objectname) %(objectsize) %(rest)' | sed -n 's/^blob //p' | sort --numeric-sort --key=2 | cut -c 1-12,41- | $(command -v gnumfmt || echo numfmt) --field=2 --to=iec-i --suffix=B --padding=7 --round=nearest
删除git已经跟踪文件
删除
git filter-branch --force --index-filter 'git rm -r --cached --ignore-unmatch path-to-your-remove-file' --prune-empty --tag-name-filter cat -- --all
推送
git push origin master --force --all
排序
git rev-list --objects --all | grep "$(git verify-pack -v .git/objects/pack/*.idx | sort -k 3 -n | tail -5 | awk '{print$1}')"
简单删除
-
git rm --cached readme1.txt 删除跟踪,并保留在本地。
-
git rm --f readme1.txt 删除跟踪,并且删除本地文件。
-
不会删除以前的提交记录
Checkout检出文件
- git checkout (commit_id 为空则默认上一次) -- (需要签出文件名)
二分法查错
- 选定查找范围
git bisect start [终点] [起点]
- 判定该提交为好/坏
git bisect good/bad
gc
- 打包一些老的提交以压缩空间
git gc
[!important] 运行这个命令之后默认只会gc 2个星期前的object,而且danging悬空的对象因为有reflog 导致无法被直接删除,如果需要删除悬空对象,需要运行
git gc --prune=0这个命令的意思是gc从现在开始的对象,以及最开始需要运行git reflog expire --expire-unreachable=0 --all这个命令的意思是立刻清空reflog里的所有从当前head不可达对象(unreachable)的引用(reflog entries)。使得gc可以正确运行
fsck
- 运行
git fsck --lost-found查找所有的悬空对象
cat-file
- 查看hash对应obj内容
git cat-file -p 1234
git cat-file -t 1234
删除本地远程分支
git pull --prune
检查是否冲突
git merge --no-commit --no-ff
# 取消
git merge --abort
Git reflog
- 记录指针每一次发生改变的记录,用于找回分支以及reset hard
Git commit --amend
-
后面不需要添加任何参数
-
修改上一次提交的内容(用于这次修改想合并到上一个修改),不能用于已经提交远程的修改
Squash
git merge --squash, 合并,但只保存一次提交记录
修改默认远程分支
- git branch --set-upstream-to=origin/master master
Rebase
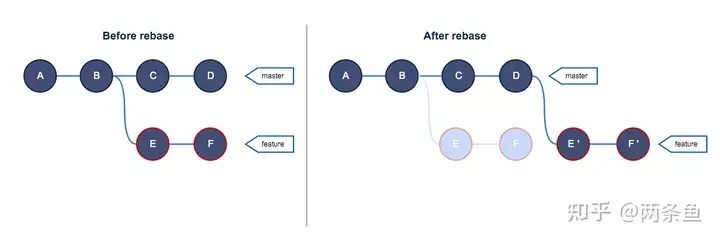
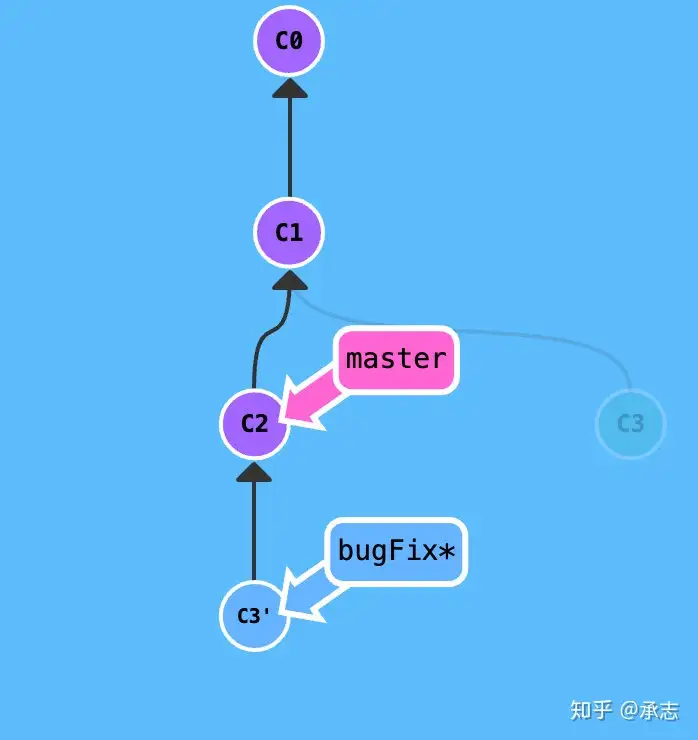
- 在feature中
git rebase master,实际上是直接修改了拼接上的位置 - 通过
git rebase --abort停止正在进行中的 rebase
操作
解决合并冲突(尽量少用)
# demo
git checkout feat/some-thing
git rebase master
# resolving git conflicts.....
git checkout master
git merge feat/some-thing
- 切换分支
- rebase master,如上图,将feat分支的base更改为当前的master(实质上是将自己额外的提交拿出来放到当前master的头部),此时新添加的commit会相应的进行合并并生成新的提交记录(和原来的hash不一样,不是同一个提交)
优点
- 操作简单,方便解决冲突
缺点
- 多人使用同一分支会出现灾难
- test环境依旧无法使用,只适用于正式环境
简化提交记录
- !!一旦推送远程,禁止rebase!!
- 不推荐使用这个用法,因为很麻烦而且有可能冲突,不如分支合并到master再squash
- 查看自己的日志,找到需要合并到的hash
- 使用
git rebase -i <commit>命令进行交互式 rebase,或者git rebase -i HEAD^n (n为需要更改的提交数量) - 编辑窗口需要更改的版本前改成s
远程和本地代码合并
用于本地有提交,远程也有提交,pull下来时候的merge
pull=fetch+merge,因此运行git fetch- 执行
git rebase,将本地的commit,拿出来放到远程的头部
禁忌(黄金法则)
- 不要在已经推送到远程的提交进行rebase!!,
- 永远不要rebase共享分支,非常容易造成提交丢失
Submodule
[!important] 注意 submodule的路径不要放在ignore里面, 因为是submodule自己管理的
- 子模块,通过
git submodule add <repository-url> <path>添加,添加后会生成.gitmodules文件
[submodule "third_party/googletest"]
path = third_party/googletest
url = https://github.com/google/googletest.git
branch = release
[submodule "third_party/benchmark"]
path = third_party/benchmark
url = https://github.com/google/benchmark
- 通过
git clone --recurse-submodules这个命令递归clone - 已经拉取的仓库通过
git submodule update --init --recursive --depth=1拉取 - 更新版本需要进入文件夹中主动
git pull
创建
- git submodule add <model_url>
git submodule add -b <branch> <remote> <path>不指定分支就不传-b <branch>
拉取
- git clone url --recurse-submodules
删除
- git submodule deinit project-sub
- git rm project-sub
- 参考
出现'you must specify a branch'
- pull的时候加上分支,如
git pull gitee master
git只回退某个文件或者文件夹
-
回退文件:
git checkout HEAD <file>或者git checkout -- <file>,推荐第一种,这里的HEAD可以直接换成commit-id,这样就是回退到某个地方 -
回退文件夹
git checkout <commit_id> -- <folder_path>
git 命令分页问题
-
git config --global pager.branch false -
参考https://blog.csdn.net/albertsh/article/details/114806994
-
全局设置
git config --global core.pager -
单个命令设置
git config --global pager.branch false
git删除tag
git tag -d <tag_name> #本地tag
git push origin -d <tag_name> # 远程tag
git统计个人代码行数
#!/bin/bash
printf "\n1. 项目成员数量:"; git log --pretty='%aN' | sort -u | wc -l
printf "\n\n2. 按用户名统计代码提交次数:\n\n"
printf "%10s %s\n" "次数" "用户名"
git log --pretty='%aN' | sort | uniq -c | sort -k1 -n -r | head -n 5
printf "\n%10s" "合计";
printf "\n%5s" ""; git log --oneline | wc -l
printf "\n3. 按用户名统计代码提交行数:\n\n"
printf "%28s %18s %18s %18s\n" "用户" "总行数" "添加行数" "删除行数"
git log --format='%aN' | sort -u -r | while read name; do printf "%25s" "$name"; \
git log --author="$name" --pretty=tformat: --numstat | \
awk '{ add += $1; subs += $2; loc += $1 - $2 } END { printf "%15s %15s %15s \n", loc, add, subs }' \
-; done
printf "\n"
printf "\n%25s " "总计:"; git log --pretty=tformat: --numstat | \
awk '{ add += $1; subs += $2; loc += $1 - $2 } END { printf "%15s %15s %15s \n", loc, add, subs }'
[!tip] 参考 https://cloud.tencent.com/developer/article/2087250
git/ssh 设置代理
[!tip] 参考 https://ericclose.github.io/git-proxy-config.html 非常详细
http/https
git config http.proxy http://127.0.0.1:7890
git config http.proxy socks5://127.0.0.1:7891
ssh
这部分也可以用作ssh连接的代理 如果ssh push不上去可以试着把 .ssh/config 里面github内容注释掉 可以先用
ssh -T git@github.com检测是否能够连接
- 编辑~/.ssh/config
Host github.com
User git
ProxyCommand nc -X 5 -x 127.0.0.1:7891 %h %p
# `%h` 和 `%p` 将会被自动替换为**目标主机名**和 **SSH 命令指定的端口**
# -X 是指定默认socket5,不指定也可以
- 或者,SSH连接的代理
# 如果代理服务器需要认证,可以使用 nc 的升级版 ncat 指定代理服务器的用户名和密码
ssh -o ProxyCommand="ncat --proxy-type http/socks4/socks5 --proxy proxy.net:port --proxy-auth proxyuser:proxypwd %h %p" user@server.net
[!tip] 出任何问题看参考文章,很详细
git打包代码压缩包
git archive --output=<output-path>.zip HEAD
# or
git archive --output=<output-path>.tar HEAD
git LF的问题
-
参考# window git crlf lf 换行符问题
// 提交时转换为LF,检出时转换为CRLF git config --global core.autocrlf true // 提交时转换为LF,检出时不转换 git config --global core.autocrlf input // 提交检出均不转换 git config --global core.autocrlf false // 拒绝提交包含混合换行符的文件 git config --global core.safecrlf true // 允许提交包含混合换行符的文件 git config --global core.safecrlf false // 提交包含混合换行符的文件时给出警告 git config --global core.safecrlf warn参考
- https://www.cnblogs.com/hushaojun/p/16001784.html
出现refusing to merge unrelated histories
- 两个仓库不同而导致的,需要在后面加上--allow-unrelated-histories进行允许合并,即可解决问题
- 本质上应该并不会出现这个问题(如果是clone的),考录重新clone仓库
出现 error: remote unpack failed: index-pack failed
- 把
.git文件夹删除之后重建就可以了, 参考 git - Github push error: unpack failed: index-pack abnormal exit - Stack Overflow
出现 RPC failed; HTTP 502 curl 22
- 参考 error: RPC failed; HTTP 502 curl 22 The requested URL returned error: 502 Proxy Error fatal:_curl: (22) the requested url returned error: 502-CSDN博客 和 【已解决】Bug12. Git过程中RPC failed; HTTP 500 curl 22 The requested URL returned error: 500
unset http
unset https
git config --global http.postBuffer 524288000
git 附注标签
- 实际上就是标签出现注释的内容
git tag -a <tag> -m <message>
临时修改提交人员信息
git commit --author="Your Name <your@email.com>"
查看某个文件某次提交不同
- 和当前不同
git diff <commit-id> <file> - 两个提交之间不同
git diff <commit-id> <commit-id> <file>
git clone 拉取指定分支
git clone -b <branch> <remote_url>
git 分页器
- 使用某些git 命令会出现新的窗口, 需要 q 才能推出, 使得麻烦(比如branch 和tag)
- 单独屏蔽某个命令
git config --global pager.branch false - 全部屏蔽, 关闭功能
git config --global core.pager ''
[!tip] 参考 解决git命令会将结果输出到单独窗口必须按q才能退出的问题_git config --global core.pager-CSDN博客
设置init默认分支名
git config --global init.defaultBranch mastermaster比main好多了, 政治正确是最愚蠢的东西
修改 commiter
- 单个修改(单个仓库, 全局需要加上
--global#快捷命令
git config user.name chenxuan
git config user.email 1607772321@qq.com
- 批量修改, 改完推远程需要
-f
git filter-branch --env-filter '
OLD_EMAIL="xxx@yyy"
CORRECT_NAME="chenxuan"
CORRECT_EMAIL="1607772321@qq.com"
if [ "$GIT_COMMITTER_EMAIL" = "$OLD_EMAIL" ]
then
export GIT_COMMITTER_NAME="$CORRECT_NAME"
export GIT_COMMITTER_EMAIL="$CORRECT_EMAIL"
fi
if [ "$GIT_AUTHOR_EMAIL" = "$OLD_EMAIL" ]
then
export GIT_AUTHOR_NAME="$CORRECT_NAME"
export GIT_AUTHOR_EMAIL="$CORRECT_EMAIL"
fi
' --tag-name-filter cat -- --branches --tags
[!tip] 参考 单独或批量修改commit的author信息场景1: 单独修改1个或几个少量commit的author信息。 1.配置正 - 掘金
获取提交的tag信息
git describe --tags --always返回结果如果这个commit 有tag直接返回tag, 否则返回类似v0.0.9-6-gc314ce1v0.0.9代表上一个最近的版本- 6 代表过去了6个commit
- g 没什么实际作用, 指示是git
c314ce1代表最近 commit 的 hash值
只stash 暂存区, 清除工作区
git checkout .
出现 no word lists can be found for the language
- 在
~/.gitconfig文件中加上
[gui]
spellingdictionary = none
Svn
目录结构
├── current
├── format
├── fsfs.conf
├── fs-type
├── min-unpacked-rev
├── rep-cache.db
├── rep-cache.db-journal
├── revprops
│ └── 0
│ ├── 0
│ ├── 1
│ └── 2
├── revs
│ └── 0
│ ├── 0
│ ├── 1
│ └── 2
├── transactions
├── txn-current
├── txn-current-lock
├── txn-protorevs
├── uuid
└── write-lock
- svn记录版本和上一个版本的区别(git直接保存两者)
- svn 创建分支方法是直接复制一份(git只是创建一个指针)
Git远程分支跟踪
- 远程没有分支,本地也没有分支
git checkout -b test #创建并切换到新分支
git push --set-upstream origin test #推送到远程分支,并且跟踪远程分支
-
远程已经存在分支,本地不存在对应分支
- 创建本地关联远程分支 #快捷命令
git checkout -b newtest origin/test
git pull
- 另一种方法
git fetch origin master:master
git push --set-upstream origin test or git branch --set-upstream-to=test
清除分支
- 可以使用以下命令清除本地已经被删除的远程分支:
git remote prun e origin
- 这个命令会清除本地已经不存在于远程仓库的远程分支。如果只想清除特定的远程分支,可以使用以下命令:
git remote prune origin --dry-run --prune=<remote-branch-name>
- 其中,
<remote-branch-name>是要清除的远程分支名称,--dry-run参数会显示将要执行的操作,而不是实际执行。
查看远程分支对应
git branch -vv
工具
vimdiff
配置
git config merge.tool vimdiff # 指定vimdiff作为默认mergetool
git config merge.conflictsytle diff3 # 设定mergetool风格
git config mergetool.prompt false # 取消打开文件时的warning显示
git config mergetool.keepBackup false # 设置禁止生成orig
- 此为本地配置,若要全局配置加上--global
使用
- git mergetool
界面
- 出现四个窗口
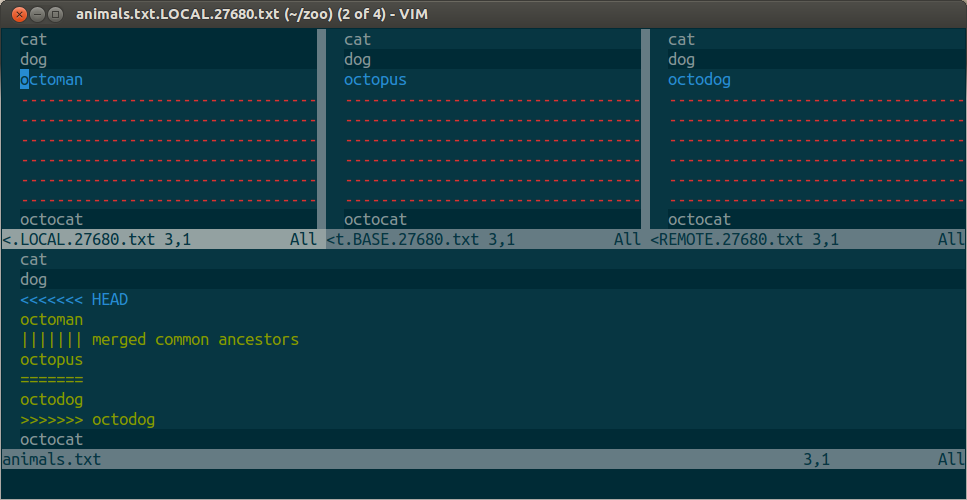
- 从左到右分别为
- 当前分支内容local
- 两个分支共同祖先内容base
- 要合并分支内容remote
- 下面为修改的窗口
修改
- 直接修改
- 命令修改
:diffg RE " get from REMOTE
:diffg BA " get from BASE
:diffg LO " get from LOCAL
- 下一个冲突(]c)
退出
- :wqa 如果还有文件会继续自动打开下一个
lazygit
- 使用<space>进入选择,j/k上下移动,<enter>选择
冲突解决
起merge分支
- 一种通用的办法,无论是master还是test都可以使用
- 方法参考开发规范 > 开发流程
优点
- 通用,无论是test环境出问题还是master都可以使用
- 提交记录整洁
缺点
- 太麻烦和繁琐了,涉及到很多分支,到时候需要一个一个删除
rebase大法
- 具体原理参考gitothers > Rebase
- 相当于冲突的分支rebase到master当前上(这个只能用于没有推送到远程分支情况下,不推荐)
git rebase master # 此时在自己的分支上
优点
- 提交记录整洁
- 操作简单
缺点
- 只能在master使用,不能在test上使用(会出大问题,因为本来是基于master的)
- 这个只能用于没有推送到远程分支情况下,不推荐
直接merge大法
- 当分支出现冲突的时候,直接将merge master
git merge master # 此时在自己的分支上
优点
- 和rebase底层原理是一样的,因此也有操作简单
缺点
- 只能在master使用
- 提交记录会变得诡异,自己的log和master的log合并了
直接修改冲突
- 直接在test分支上解决冲突然后直接commit
优点
- 简单方便
缺点
- 只能在test实现,不能在master操作
- 很容易导致直接在test分支开发的坏习惯
总结
- 如果需要统一解决方式
- 使用merge分支是最统一的
- 如果需要最简单快速
- master 分支merge master
- test使用直接修改大法
[!quote] 如果是兴趣的角度推荐学一下,但是功利的角度就算了
基本说明
- git 和svn的方式不同,主要使用文件快照的形式储存,更加快速索引
- git 使用sha1生成hash,使用zlib的deflate算法压缩文件
- 具有相同hash值的文件,git认为为同一个文件,只生成一份obj
目录分析
.git
├── branches
├── COMMIT_EDITMSG
├── config
├── description
├── HEAD
├── hooks
│ ├── applypatch-msg.sample
│ ├── commit-msg.sample
│ ├── fsmonitor-watchman.sample
│ ├── post-update.sample
│ ├── pre-applypatch.sample
│ ├── pre-commit.sample
│ ├── pre-merge-commit.sample
│ ├── prepare-commit-msg.sample
│ ├── pre-push.sample
│ ├── pre-rebase.sample
│ ├── pre-receive.sample
│ └── update.sample
├── index
├── info
│ └── exclude
├── logs
│ ├── HEAD
│ └── refs
│ └── heads
│ ├── feat
│ │ └── example
│ └── master
├── objects
│ ├── 18
│ │ └── 605c522c56ea4ebbf2ee17ae702c38e89f37e2
│ ├── 21
│ │ └── c8f9899198b747f5a44bc5f837a15dbe8de639
│ ├── 30
│ │ └── 532454c17b108960baaa779156d4ed06f4700a
│ ├── af
│ │ └── 81445cd6401f394045651a876e9196db61e912
│ ├── e5
│ │ └── 3be081fdea9000576336d0d0dee7b326915ff2
│ ├── info
│ └── pack
└── refs
├── heads
│ ├── feat
│ │ └── example
│ └── master
├── remotes
│ └── origin
│ ├── HEAD
│ └── main
└── tags
└── v0.0.1
description
- 暂时没发现有什么用(似乎和gitweb有关)
branches
- 暂时没发现有什么用
COMMIT_EDITMSG
- 最近的commit 的msg信息,没什么用
info/exclude
- 和.gitignore类似,用于忽略文件
区别在于这个文件不会被提交,一般用于本地忽略文件
hooks
- 一些git的脚本,可以自己进行编写,在对应的时机调用,默认不使用,需要使用去除文件后缀
config
- 配置文件,有关项目git的配置都在这里
[core]
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
[remote "origin"]
url = git@github.com:chenxuan520/gitlearn.git
fetch = +refs/heads/*:refs/remotes/origin/*
HEAD
- 用于指示目前所在的分支以及位置
ref: refs/heads/master
logs
HEAD
- HEAD 记录所有更改记录,包括切换分支
- reflog 查看的位置
0000000000000000000000000000000000000000 21c8f9899198b747f5a44bc5f837a15dbe8de639 chenxuan <1607772321@qq.com> 1668685183 +0800commit (initial): init
21c8f9899198b747f5a44bc5f837a15dbe8de639 21c8f9899198b747f5a44bc5f837a15dbe8de639 chenxuan <1607772321@qq.com> 1668685269 +0800checkout: moving from master to feat/example
21c8f9899198b747f5a44bc5f837a15dbe8de639 21c8f9899198b747f5a44bc5f837a15dbe8de639 chenxuan <1607772321@qq.com> 1668686611 +0800checkout: moving from feat/example to master
refs
- 对该分支的变化操作记录
0000000000000000000000000000000000000000 21c8f9899198b747f5a44bc5f837a15dbe8de639 chenxuan <1607772321@qq.com> 1668685183 +0800commit (initial): init
21c8f9899198b747f5a44bc5f837a15dbe8de639 2f161ef1b5de6a71321f508f91fcb9c95c4e42f7 chenxuan <1607772321@qq.com> 1668687323 +0800commit: 2th
2f161ef1b5de6a71321f508f91fcb9c95c4e42f7 21c8f9899198b747f5a44bc5f837a15dbe8de639 chenxuan <1607772321@qq.com> 1668687356 +0800reset: moving to 21c8f9899198b747f5a44bc5f837a15dbe8de639
objects
info pack
- 用于gc打包文件
- 似乎使用了增量储存的形式(不确定)
使用gc 后
├── objects
│ ├── info
│ │ ├── commit-graph
│ │ └── packs
│ └── pack
│ ├── pack-87f50f248e000319b69ffc78501ce7c4f2e53999.idx
│ └── pack-87f50f248e000319b69ffc78501ce7c4f2e53999.pack
其他
- git 的obj 分有三种
- blob 文件类型
- tree 树类型(文件夹)
- commit 提交类型
- 全都是通过sha1 计算hash值再进行zlib压缩得到
文件权限存储在tree中,这样改动文件权限改动较少
refs
- 里面内容都是引用类型(都是hash指针)
head
- 所有的分支指针位置
remote
- remote指针的位置以及远程分支内容
tags
- tags 所指向提交内容
index
- git 暂存区信息
git过程分析
add
before
├── objects
│ ├── info
│ └── pack
after
├── objects
│ ├── 9c
│ │ └── 595a6fb7692405a5c4a10e1caf93d7a5bd9c37
│ ├── af
│ │ └── 81445cd6401f394045651a876e9196db61e912
│ ├── e5
│ │ └── 3be081fdea9000576336d0d0dee7b326915ff2
│ ├── info
│ └── pack
git reset
├── objects
│ ├── 9c
│ │ └── 595a6fb7692405a5c4a10e1caf93d7a5bd9c37
│ ├── af
│ │ └── 81445cd6401f394045651a876e9196db61e912
│ ├── e5
│ │ └── 3be081fdea9000576336d0d0dee7b326915ff2
│ ├── info
│ └── pack
git reset 不会删除生成的内容 add 似乎只计算文件的hash,不会递归构建tree的obj
- 计算文件hash值,并递归构建tree,生成多个obj
- 更新index的内容
commit
after commit
├── objects
│ ├── 13
│ │ └── d298626d6cad66fd224fe25106a6def17ca9d1
│ ├── 18
│ │ └── 605c522c56ea4ebbf2ee17ae702c38e89f37e2
│ ├── 30
│ │ └── 532454c17b108960baaa779156d4ed06f4700a
│ ├── 9c
│ │ └── 595a6fb7692405a5c4a10e1caf93d7a5bd9c37
│ ├── af
│ │ └── 81445cd6401f394045651a876e9196db61e912
│ ├── e5
│ │ └── 3be081fdea9000576336d0d0dee7b326915ff2
│ ├── info
│ └── pack
- 类似add,生成commit的obj,指针前移
- 更新对应值
过程总结
commit
- 保存提交的msg根目录所有文件和目录的hash
tree
- 保存目录所有文件和目录的hash
blob
- 保存文件压缩后内容
index
- 保存暂存区的文件hash列表
计算过程
- 递归寻找根目录下所有文件
- 计算文件的hash,压缩文件并生成obj,向上传递hash
blob
$ git cat-file -p af81
## this is a log for lean git
- 目录将文件的hash包含,生成类似目录列表,压缩文件并生成obj,并对自己内容生成hash,向上传递
tree
$ git cat-file -p 3053
100644 blob af81445cd6401f394045651a876e9196db61e912 README.md
040000 tree 18605c522c56ea4ebbf2ee17ae702c38e89f37e2 example
- commit 收集hash,像tree一样生成列表,再加上提交信息和上一次提交的hash,压缩文件并生成obj,继续向上传递
commit
$ git cat-file -p 13d2
tree 30532454c17b108960baaa779156d4ed06f4700a
author chenxuan <1607772321@qq.com> 1668689153 +0800
committer chenxuan <1607772321@qq.com> 1668689153 +0800
init
- 修改HEAD的值,并将提交信息记录
QA
如何避免碰撞
- 基本无需避免,两个不同文件产生同一个hash几率太小了.而且git有自动gc功能,进一步避免冲突
恶意碰撞
- git 不会发现文件的不同,因此不会处理hash相同的文件,不会生成obj
为什么空文件夹不会被识别
- tree obj存在意义在于记录包含的文件和文件夹,如果不包含任何文件和文件夹,那么这个tree完全为空就无法计算hash值
参考列表
https://git-scm.com/docs https://git-scm.com/book/zh/v2 https://zhuanlan.zhihu.com/p/106243588 https://developer.aliyun.com/article/761663
Git 项目开发规范
作者
chenxuan
流程

分支策略
- master主分支,用于发布环境分支,和release班次高度一致
- test分支,用于测试环境分支,一般可以自动CICD
- release分支,用于生产环境分支,只能通过master合并进入
- fix/* 分支,用于修补线上bug分支
- feat/* 分支,用于开发功能分支
- refactor/* 分支,用于重构代码
四大环境
-
生产环境
用于部署成品的环境,master分支
-
测试环境
用于部署测试,test分支
-
开发环境
用于本地进行测试,一般需要连接公司VPN开发
-
发布环境
用于版本封闭测试,发布大版本前的综合测试
开发流程
- git clone remote-url 克隆仓库
- 拉取最新代码
- git fetch origin master:master 不在master
- git pull origin master 在master
- 开发
-
创建新分支
- git checkout -b feat/xxx master 开发新功能
- git checkout -b fix/xxx master 修补bug
- git checkout -b refactor/xxx master 重构
-
推送新分支
- git push origin xxx
-
合并到test分支
前提是在开发环境测试没有问题
- git fetch origin test:test
- git checkout test
- git merge xxx(自己的分支)
- 没有冲突
- git push 推送分支
- 产生冲突
- git checkout -b merge/xxx # 这个命令在test分支上
- git merge xxx
- 解决冲突
- git push origin xxx
- git checkout test
- git merge merge/xxx
- 没有冲突
-
提出master的merge request
前提是在测试环境没有问题
- 产生冲突和test解决方式类似
- review没有问题,合并分支到master,结束开发
- review出问题
- 继续修改代码,解决问题再次请求合并
-
- 开发完毕,删除分支
- git push origin :xxx(远程分支名字)
- git branch -d xxx(本地分支名字)
提交规范
格式
type(scope) : subject
type
- feat: 新特性或功能
- fix: 缺陷修复
- docs: 文档更新
- style: 代码风格或者组件样式更新
- refactor: 代码重构,不引入新功能和缺陷修复
- perf: 性能优化
- test: 单元测试
- chore: 其他不修改 src 或测试文件的提交
scope(optional)
- 用于说明 commit 影响的范围,比如数据层、控制层、视图层等等,视项目不同而不同
subject
- 简易描述该commit做了什么
MR规范
- 在仓库提交mr时候,应该注明修改或者添加了什么功能(相当于提交的总结,需要比commit message详细)
1. fix:删除了审核的部分
2. feat:完善了测试环境自动推送脚本
注意事项
- 提交merge request前必须经过测试环境检验
- test分支代码不能合并到master分支
- test分支可以直接合并,master分支必须经过审核
- 不要在test分支直接进行开发!
- 禁止使用姓名缩写命名分支
- 一旦分支合并入master,请删除分支,避免分支上二次开发
- release需要保证和master高度一致,如果出现冲突,回退release到上一个tag再进行merge(正常情况下不可能出现冲突)
- master是所有的核心,代码release是正式环境代码
- 其他知识点
缺点
- 一旦有人不遵守流程,规范回来会非常麻烦
- test和master分支始终有差异,测试环境的版本和正式环境的版本还是不一样,理论上应该有一个版本的测试分支(可以叫做pre-master),该分支始终和master使用同一个版本,并且领先master一个大版本,先向pre-master合并,经过测试该大版本没有问题之后进行向master合并,因此最新版添加了release分支
大厂规范
- 大厂只有 master 分支和 feat/fix/test 特性分支,不存在test环境,大厂通常都是直接每个分支分别编译成docker分别部署的,主要是有钱有机器,直接每个分支都是一套独立的测试环境,test分支直接可以忽略,然后测试的时候因为会有回归化测试,客户端测试,因此release分支也省略了
修改为VIM/EMACS模式
set -o vi,set -o emacs
原生快捷键
编辑
- Ctrl + a :移到命令行首
- Ctrl + e :移到命令行尾
- Ctrl + f :按字符前移(右向)
- Ctrl + b :按字符后移(左向)
- Alt + f :按单词前移(右向)
- Alt + b :按单词后移(左向)
- Ctrl + xx:在命令行首和光标之间移动
- Ctrl + u :从光标处删除至命令行首
- Ctrl + k :从光标处删除至命令行尾
- Ctrl + w :从光标处删除至字首
- Alt + d :从光标处删除至字尾
- Ctrl + d :删除光标处的字符,(如果没有字符,退出终端)
- Ctrl + h :删除光标前的字符
- Ctrl + y :粘贴至光标后
- Alt + c :从光标处更改为首字母大写的单词
- Alt + u :从光标处更改为全部大写的单词
- Alt + l :从光标处更改为全部小写的单词
- Ctrl + t :交换光标处和之前的字符
- Alt + t :交换光标处和之前的单词
重新执行命令
- Ctrl + r:逆向搜索命令历史
- Ctrl + g:从历史搜索模式退出
- Ctrl + p:历史中的上一条命令
- Ctrl + n:历史中的下一条命令
- Alt + .:使用上一条命令的最后一个参数
控制命令
- Ctrl + l:清屏
- Ctrl + o:执行当前命令,并选择上一条命令
- Ctrl + s:阻止屏幕输出
- Ctrl + q:允许屏幕输出
- Ctrl + c:终止命令
- Ctrl + z:挂起命令
Bang (!) 命令
- !!:执行上一条命令
- !blah:执行最近的以 blah 开头的命令,如 !ls
- !blah:p:仅打印输出,而不执行
- !$:上一条命令的最后一个参数,与 Alt + . 相同
- !$:p:打印输出 !$ 的内容
- !*:上一条命令的所有参数
- !:p:打印输出 ! 的内容
- ^blah:删除上一条命令中的 blah
- ^blah^foo:将上一条命令中的 blah 替换为 foo
- ^blah^foo^:将上一条命令中所有的 blah 都替换为 foo
其他
- 插入tab按键<c-v><tab>
'和"在shell的区别
- 单引号('):
- 在单引号内部,所有的特殊字符都会被原样输出,包括变量和命令替换。
- 单引号内部的内容会被视为纯粹的字符串,不会进行任何解释或替换。
- 单引号字符串中的变量名和命令替换会被视为普通字符,不会被执行。
- 双引号("):
- 在双引号内部,变量和命令替换会被执行,并将其结果替换为实际的值。
- 双引号内部可以包含变量、命令替换以及转义字符(例如
\n表示换行)。 - 双引号内部的内容会被解释和替换,而不是原样输出。
bashrc不加载
- 运行
echo $SHELL观察是否是 bash - 如果不是,用 chsh 更改
- 如果是,更改
~/.profile文件 - 写入下面内容
if [ -n "$BASH_VERSION" ]; then
# include .bashrc if it exists
if [ -f "$HOME/.bashrc" ]; then
. "$HOME/.bashrc"
fi
fi
命令行补全设置
#!/bin/bash
# 检查当前 shell 是否为 Zsh,如果是则初始化 bashcompinit
if [[ -n "${ZSH_VERSION}" ]]; then
autoload -U +X bashcompinit && bashcompinit
fi
# 解析 ini 文件,返回所有 section 名称
parse_ini_sections() {
local ini_file="$1"
if [[ -f "$ini_file" ]]; then
# 使用 grep 提取所有 section 名称
grep '^\[\w*\]' "$ini_file" | tr '[' '/' |tr -d ']'
else
echo 'complete wrong'
fi
}
# 补全函数
_ai_completion() {
local cur prev ini_file sections
COMPREPLY=()
cur="${COMP_WORDS[COMP_CWORD - 1]}"
prev="${COMP_WORDS[COMP_CWORD - 2]}"
# 请将此处修改为你实际的 ini 文件路径
ini_file="${HOME}/.vim/plugged/vim-ai-doubao/roles-example.ini"
sections=$(parse_ini_sections "$ini_file")
COMPREPLY=( $(compgen -W "$sections" -- "$cur") )
return 0
}
# 关联补全函数和命令,这里假设命令名为 ai
complete -F _ai_completion ai
- 然后在 bashrc 中 source 即可, 或者创建
~/.bash_completion文件, 补全内容放到里面也可以, 参考 linux 命令行自动补全
参考
gitlab
安装runner
- 由于是通过runner自动拉取,不需要runner能够公网访问
sudo apt install gitlab-runner安装包(这个方法的包可能很老,不推荐)或者
# Download the binary for your system
sudo curl -L --output /usr/local/bin/gitlab-runner https://gitlab-runner-downloads.s3.amazonaws.com/latest/binaries/gitlab-runner-linux-amd64
# 太慢的话可以换成 https://gitee.com/mirrorvim/userful-tools-2/releases/download/gitlabrunnerv1.0.0/gitlab-runner-linux-amd64
# Give it permissions to execute
sudo chmod +x /usr/local/bin/gitlab-runner
# Create a GitLab CI user
sudo useradd --comment 'GitLab Runner' --create-home gitlab-runner --shell /bin/bash
# Install and run as service
sudo gitlab-runner install --user=gitlab-runner --working-directory=/home/gitlab-runner
sudo gitlab-runner start
- 运行下列代码注册,token从gitlab项目
setting->CI/CD->runner->Specific runners获取- 名字要取,方便识别
- 出现选择executor的时候根据需要选择,一般为docker或者shell
- tag一定要写,执行时候需要指定tag
- 配置文件保存在: "/etc/gitlab-runner/config.toml"
- 如果配置有问题就取消注册删除
sudo gitlab-runner register --url https://gitlab.dian.org.cn/ --registration-token $REGISTRATION_TOKEN
sudo gitlab-runner verify
# 取消注册删除
sudo gitlab-runner unregister -name=helpertest
- 检查是否运行成功,如果出现unmark的情况,运行
sudo systemctl unmask gitlab-runner.service
gitlab-runner status
gitlab-runner: Service is running
sudo systemctl status gitlab-runner.service
sudo systemctl start gitlab-runner.service
ps aux|grep gitlab#这个命令一定需要出现gitlab-runner run
- 如果发现还是无法自动获取任务执行
sudo nohup gitlab-runner run &
上传公钥
- 因为CICD会自动拉取仓库,因此必须runner确保有权限拉取仓库
- 服务器使用`ssh-keygen -t rsa``生成公钥
- 在gitlab项目中
setting->repository->Deploy keys中添加- 这里如果出现冲突"Deploy keys projects deploy key fingerprint has already been taken"
- 把别的地方的删掉放在这里才是正确的地方
- "sudo gitlab-runner unregister -name=helpertest"
[!important] 创建其他仓库配置 其他仓库中添加服务器的权限应该在这里添加,其他地方添加太愚蠢了
- 如果runner需要访问服务器还要将公钥加入服务器
编写.gitlab-ci.yml
- 一般哪个分支需要CICD这个分支就放在哪个分支上
- 点击stage再点击某个阶段可以看到日志
- 只要处在这个文件的分支推送,如果文件中没有指定分支,那么都会执行
stages:
- deploy #这里可以一次定义多个stages,下面依次执行
deploy:
stage: deploy
tags:
- helper-cicd #这里需要指定创建时候runner的tag
script:
- ./auto_push.sh #需要执行的命令
only:
- test #只有在特定分支上才会执行
修改默认配置(optional)
- 配置文件为
/etc/gitlab-runner/config.toml - 时间间隔为
check_interval,通常设置为10 - 如果出现了奇怪的参数修改
/etc/systemd/system/gitlab-runner.service的内容 ,然后sudo systemctl daemon-reload,然后sudo systemctl start gitlab-runner.service - demo
concurrent = 1
check_interval = 10
shutdown_timeout = 0
[session_server]
session_timeout = 1800
[[runners]]
name = "seedcup"
url = "https://gitlab.dian.org.cn/"
id = 28
token = "eJenV431nsLuWf6utrjQ"
token_obtained_at = 2023-06-06T03:03:15Z
token_expires_at = 0001-01-01T00:00:00Z
executor = "shell"
[runners.cache]
MaxUploadedArchiveSize = 0
github
- 个人公有仓库无限时间
- 私有仓库free用户2000分钟每月,pro用户3000分钟每月
创建文件
- 需要在线项目中开启,项目首页->setting->Actions->General->Allow All
- 项目目录下创建
.github/workflows文件夹 - 在该文件夹下创建任意数量任意名称的
.yml文件,github会自动遍历所有的yml文件进行构建 - 推送到github就会自动执行cicd
文件格式
- 可以参考 qiniuserver/.github/workflows/build_and_release.yml at master · chenxuan520/qiniuserver · GitHub
- 如果想要多个平台编译构件参考 Github Action 快速构建 Electron 应用_github action打包electron-CSDN博客
- ==该文件不要存在空行,不然容易一直pending,此外runs-on最好是latest==
[!tip] 参考 Endless 'Waiting for a runner to pick up this job...' for windows-latest · community · Discussion #78802 · GitHub 踩坑: "Waiting for a runner to pick up this job"-腾讯云开发者社区-腾讯云
name: test #名称随意
on:
push: #设置触发规则
branches:
- main
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout code #这部分是为了从github自动clone代码
uses: actions/checkout@v2
- name: Install build tools #这部分是安装依赖,不过看着办的
run: |
sudo apt-get update
sudo apt-get install -y build-essential
- name: Run test #需要执行的命令
run: |
cd test
make
./main
高阶内容
添加github_token权限
cicd时候github会自动有一个token,不需要自己去创建token
- 因为这个token默认没有写权限,如果不添加,无法执行下面的创建release的过程
- 打开仓库界面 -> Setting -> Action -> General -> Workflow permissions -> 点击 Read and write permissions
设置自动部署创建release的流程
这一步依赖上面的权限设置
- 编辑yml文件,demo如下
name: build_and_release #名称随意
on:
push: #设置触发规则
branches:
- main
- master
tags:
- 'v*'
pull_request:
branches:
- main
- master
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout code #这部分是为了从github自动clone代码
uses: actions/checkout@v4
with:
fetch-depth: 0 # Number of commits to fetch. 0 indicates all history for all branches and tags.Default: 1
submodules: true
- name: Install build tools #这部分是安装依赖,不过看着办的
run: |
sudo apt-get update
sudo apt-get install -y build-essential curl
- name: Run test #需要执行的命令
run: |
make
- name: Release
uses: softprops/action-gh-release@v2 #具体参考https://github.com/softprops/action-gh-release
if: startsWith(github.ref, 'refs/tags/') # 设置为有tag才进行上传
with:
# body_path: commit-message.log
# body: Auto Create Release 这两个都是设置release信息的,一个是从path文件读取,一个是直接写入
files: |
LICENSE
设置github-page自动部署
- 开启github-action 仓库界面 -> Actions -> Enable
- 添加token的权限:仓库界面 -> Setting -> Action -> General -> Workflow permissions -> 点击 Read and write permissions
- 设置page: 仓库界面 -> Setting -> Pages -> Build and deployment -> Source 设置为 Github Actions
- 配置文件里面添加下面的内容
# Deploy job
deploy:
# Add a dependency to the build job
needs: build
# Grant GITHUB_TOKEN the permissions required to make a Pages deployment
permissions:
pages: write # to deploy to Pages
id-token: write # to verify the deployment originates from an appropriate source
# Deploy to the github-pages environment
environment:
name: github-pages
url: ${{ steps.deployment.outputs.page_url }}
# Specify runner + deployment step
runs-on: ubuntu-latest
steps:
- name: Deploy to GitHub Pages
id: deployment
uses: actions/deploy-pages@v4 # or specific "vX.X.X" version tag for this action
跨平台编译
- 基本想法是使用矩阵工作流设置不同平台
name: build_and_release #名称随意
on:
push: #设置触发规则
branches:
- main
- master
tags:
- 'v*'
jobs:
build:
strategy:
matrix: # 会分开成两个任务分别执行
os: [ubuntu-latest, macos-latest]
runs-on: ${{ matrix.os }}
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Go env prepare
uses: actions/setup-go@v5
with:
go-version: '^1.20'
check-latest: true
- name: Install build tools in Ubuntu
if: matrix.os == 'ubuntu-latest'
run: |
sudo apt-get update
sudo apt-get install -y build-essential curl
- name: Install build tools in MacOS
if: matrix.os == 'macos-latest'
run: |
brew install curl
- name: Run build
run: |
make
mv goweb goweb-${{ matrix.os }}
- name: Release
uses: softprops/action-gh-release@v2
if: startsWith(github.ref, 'refs/tags/')
with:
body_path: commit-message.log
files: |
LICENSE
goweb-${{ matrix.os }}
[!tip] 参考 goweb/.github/workflows/build_and_release.yml at master · chenxuan520/goweb · GitHub 86. GitHub Actions 第3天:跨平台构建 - Qiwihui's blog 通过 GitHub Actions 实现代码的自动编译和发布 - Undefined443 - 博客园
ssh进入action机器
- 使用 ssl 私钥连接 action 服务器, 需要提前将公钥放在 github上
- name: Setup Debug Session
uses: mxschmitt/action-tmate@v3
timeout-minutes: 15
with:
detached: false
更新 wiki
- 确保 仓库开 wiki 并且至少创建一个界面
- yml加上, path 为 markdown的 文件夹地址 , Home.md 作为默认展示页
- name: Wiki Update
uses: spenserblack/actions-wiki@v0.3.0
with:
# Whatever directory you choose will be mirrored to the GitHub
# .wiki.git. The default is .github/wiki.
path: docs
mirror信息
- 可以在 runner-images/README.md at main · actions/runner-images · GitHub 这里查看每个mirror的包的信息
gitee
[!important] gitee和github的demo可以参考 https://gitee.com/chenxuan520/cppjson
- 直接按照他的指示来操作就ok,很简单
- 构建的时候选择工具->基于镜像的脚本执行,ubuntu的容器地址
ubuntu:22.04(改成hub.atomgit.com/amd64/ubuntu:22.04) 因为愚蠢的 AtomHub , 这样弄下去迟早药丸
- 构建的时候选择工具->基于镜像的脚本执行,ubuntu的容器地址
- 如何要看到所构建记录,需要手动选择master分支(或者需要的分支)
- 创建的文件是在
.workflow目录下的yml - 每个仓库默认200分钟(一共200分钟),每人每月1000分钟
参考
- https://docs.gitlab.com/ee/ci/
- https://zhuanlan.zhihu.com/p/164744104
- https://gitee.com/help/articles/4356
快速输入
- iab ;n chenxuan
按下空格进行替换,c-s-v可以避免删除原先字符
插入模式输入命令结果
- ctrl+r= 表达式
- 正常模式使用
:r! ls
代码折叠
- zf% 按照括号折叠
- zd 删除折叠
- zo 打开折叠
查询按键使用
verbose map <key>
按键等效
- c-m = enter
- c-i = tab
- c-h = backspace
重写该行
- cc
生成递增序列
g <c-a>
命令分割(Vim中)
- Vimscript
| - shell
;
查询变量上一次改变地点
- verbose set <var-name>
vims获取变量值
- let temp=&option
插件下载
nvim/vim python支持
- nvim
pip3 install neovim
pip3 install pynvim
- vim
# mac
brew install vim # 记得后续更改PATH路径
# linux
sudo apt install vim-gtk
nvim系统粘贴板支持
sudo pacman -Syu xclip
sudo apt install xclip
mac vscodevim 长按无法移动
defaults write com.microsoft.VSCode ApplePressAndHoldEnabled -bool false并重启vscode- 如果想恢复
defaults write com.microsoft.VSCode ApplePressAndHoldEnabled -bool true
命令结果插入文件
:r!command
vscode技巧
快捷键
- 强行让copilot补全
alt+\ - 折行
alt+z - 跳转回上次的地方
ctrl+-下次地方ctrl+shift-+
设置字体大小
- 搜索font size,代码和控制台的都在
- 搜索Zoom,目录树的在这里
mac安装vim
- 先安装brew
- brew install wget
- ./shell/install.sh
生成tags 文件插件文档
- 进入 插件 doc 文档, 然后打开 vim
- 运行
:helptags .会自动生成tags文件
vscode vim
配置参考
- vscode + vim 全键盘操作高效搭配方案 - 云崖君 - 博客园
- 核心就是更改 setting.json文件
plugin 和 lazy.nvim
- 一个重要区别就是 plugin 在 init.vim 加载完成后才会开始加载插件, lazy.nvim 正好相反
AI 补全插件
- copliot: 免费额度是每月 2000次
- windsurf: 免费额度超多, 没见到限制 GitHub - Exafunction/windsurf.vim: Free, ultrafast Copilot alternative for Vim and Neovim
- Supermaven: 就是免费的 GitHub - supermaven-inc/supermaven-nvim: The official Neovim plugin for Supermaven
- tabnine: 免费的不确定能不能用 GitHub - codota/tabnine-nvim: Tabnine Client for Neovim
- fittencode code: 也不确定能不能用 GitHub - luozhiya/fittencode.nvim: Fitten Code AI Programming Assistant for Neovim
- 通用的 ai 补全 GitHub - milanglacier/minuet-ai.nvim
- 创建
CMakeLists.txt文件 - 运行构建
mkdir build
cd build
cmake ..
debug
- 文件加入
set(CMAKE_BUILD_TYPE Debug) - 或者 命令行使用
cmake -DCMAKE_BUILD_TYPE=Debug . - 一旦设置了,除非删除cmake缓存build文件,兜着都是debug模式(缓存原因)
内存泄漏检查sanitize
- 在cmake中
dd_compile_options(-fsanitize=address -fsanitize=leak -fsanitize=undefined -fno-omit-frame-pointer)
link_libraries(-fsanitize=address -fsanitize=leak -fsanitize=undefined)
or
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fsanitize=address -fsanitize=leak -fsanitize=undefined -fno-omit-frame-pointer")
link_libraries(-fsanitize=address -fsanitize=leak -fsanitize=undefined)
- 在makefile或者命令行中
g++ -Wall -Werror -std=c++11 -fsanitize=undefined test.cc
- 参考github
选项
#声明要求的cmake最低版本,终端输入cmake -version可查看cmake的版本
cmake_minimum_required( VERSION 2.8 )
#声明cmake工程
project(slam)
# 声明cpp版本
set(CMAKE_CXX_STANDARD 11)
#设置使用g++编译器,这是添加变量的用法set(KEY VALUE)接收两个参数,用来声明变量。在camke语法中使用${KEY}这种写法来取到VALUE
set( CMAKE_CXX_COMPILER "g++")
#设置cmake编译模式有Debug和Release两种PROJECT_SOURCE_DIR项目根目录也就是是CMakeLists.txt的绝对路径
#设置成为debug开启调试
set( CMAKE_BUILD_TYPE "Release" )
#设定生成的可执行二进制文件存放的存放目录,这个永远是相对于本cmakelists的路径
set( EXECUTABLE_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/bin)
#设定生成的库文件的存放目录
set( LIBRARY_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/lib)
#参数CMAKE_CXX_FLAGS含义是: set compiler for c++ language
#添加c++11标准支持,*.CPP文件编译选项,-march=native指定目标程序的cpu架构来进行程序优化
#native就是相当于自检测cpu,-march是gcc优化选项,后面的-O3是用来调节编译时的优化程度的,最高为-O3,最低为-O0即不做优化
#-Ox这个参数只有在CMake -DCMAKE_BUILD_TYPE=release时有效
#因为debug版的项目生成的可执行文件需要有调试信息并且不需要进行优化,而release版的不需要调试信息但需要优化
set( CMAKE_CXX_FLAGS “-std=c++11 -march=native -O3”)
#调试手段message打印信息,类似于echo/printf,主要用于查cmake文件的语法错误
set(use_test ${SOURCES_DIRECTORY}/user_accounts.cpp)
message("use_test : ${use_test}")
#在CMakeLists.txt中指定安装位置, 在编译终端指定安装位置:cmake -DCMAKE_INSTALL_PREFIX=/usr ..
set(CMAKE_INSTALL_PREFIX < install_path >)
#增加子文件夹,也就是进入源代码文件夹继续构建
add_subdirectory(${PROJECT_SOURCE_DIR}/src)
#添加依赖,去寻找该库的头文件位置、库文件位置以及库文件名称,并将其设为变量,返回提供给CMakeLists.txt其他部分使用。
#cmake_modules.cmake文件是把CMakeLists.txt里用来寻找特定库的内容分离出来,如果提示没有找到第三方依赖库可以尝试安装或者暴力指定路径
# 寻找OpenCV库
find_package( OpenCV REQUIRED )
#在CMakeLists.txt中使用第三方库的三部曲:find_package、include_directories、target_link_libraries
include_directories(${OpenCV_INCLUDE_DIRS})// 去哪里找头文件
link_directories()// 去哪里找库文件(.so/.lib/.ddl等)
target_link_libraries( ${OpenCV_LIBRARIES})// 需要链接的库文件
message("OpenCV_INCLUDE_DIRS: \n" ${OpenCV_INCLUDE_DIRS})
message("OpenCV_LIBS: \n" ${OpenCV_LIBS})
find_package(Eigen3 REQUIRED)
#假如找不到Eigen3库,我们就设置变量来指定Eigen3的头文件位置
set(Eigen3_DIR /usr/lib/cmake/eigen3/Eigen3Config.cmake)
include_directories(/usr/local/include/eigen3)
#设置静态连接库的选项
target_compile_options(pthread)
target_link_libraries(executable1 library1 library2)
# 链接静态库,上面用于某一个target
link_libraries(-lpthread)
# 添加可执行文件,相当于编译,可以在这里多加几个add_executable,然后指定不同的main文件,生成多个可执行文件
add_executable(obsidian ${DIR_SRCS})
# 搜索目录下的cpp文件
# 发现一个目录(dir)下所有的源代码文件并将列表存储在一个变量(VAR)中,不会递归查找
aux_source_directory(dir DIR_SRCS)
# 递归搜索所有的cpp文件并添加
file(GLOB SOURCE_FILES "${SOURCE_DIR}/*.cpp ${SOURCE_DIR}/*/*.cpp")
# 宏定义
add_definitions(-D_SHARED_LIBRARY_)
remove_definitions(-D_SHARED_LIBRARY_)
# 设定生成的可执行二进制文件存放的存放目录
set(EXECUTABLE_OUTPUT_PATH ../../bin)
分开编译
- make 编译main.cpp,make local编译local.cpp,
EXCLUDE_FROM_ALL属性用于将local目标从默认的构建目标列表中排除,这样在运行make时就不会编译local目标。
# 设置项目名称和最低版本要求
cmake_minimum_required(VERSION 3.0)
project(YourProjectName)
# 添加可执行目标 main
add_executable(main main.cpp)
# 添加可执行目标 local,并且只在 make local 时编译
add_executable(local local.cpp)
set_target_properties(local PROPERTIES EXCLUDE_FROM_ALL TRUE)
# 如果想为特定目标设置其他编译选项,可以使用 target_compile_options 命令
# target_compile_options(local PRIVATE option1 option2 ...)
# 链接库文件等其他配置...
选项
- 通过
-D传入的变量优先级比set产生的优先级高
变量
CMAKE_CURRENT_SOURCE_DIR当前cmakelist的目录CMAKE_SOURCE_DIR根cmakelist的目录
others
windows下和 MinGW
- cmake运行时候加上
cmake.exe -G "MinGW Makefiles" ., 注意需要将 MinGW 的路径添加到path中
[!tip] 参考 CMake指定MinGW编译器C compiler - 昆山皮皮虾 - 博客园
网络模型
bridge模式
- 配置: 默认配置,
--network=bridge - 通过docker0 网卡,相当于自己构建了一个局域网,由docker0统一负责转发,在表中注册容器端口并转发,另类NAT
- 同时host作为网卡的第一个有效ip可以和容器通讯
[!important] 绑定的ip一定要是0.0.0.0,因为host的localhost在这个模式进入docker之后并不是127.0.0.1,而是网卡的第一个有效ip,容易出错
host模式
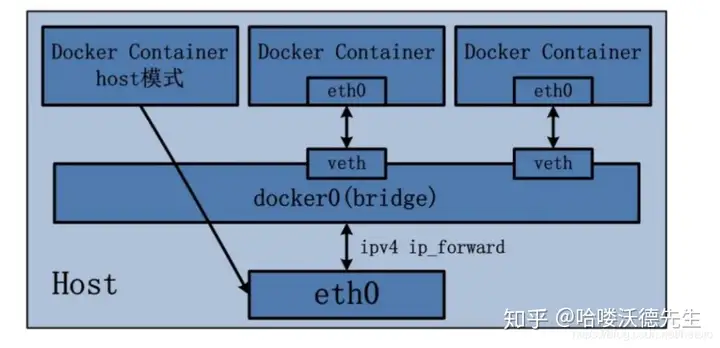
- 配置:
--network=host - 直接和host共享端口,一般不用,因为丧失docker环境隔离性,好处是容器localhost直接和host共享
none模式
- 配置:
--network none - 禁用网络功能,不会在容器创建网卡,只有lo(localhost)
container模式
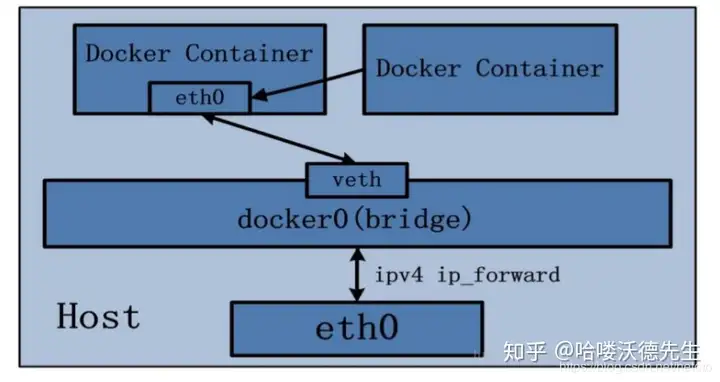
- 配置:
–network=bridge - 和其他容器共享一个网卡,如果依赖容器关了,就只剩下lo,好处是容器共享网卡,可以直接localhost访问其他容器
macvlan 模式
- 需要和host主机使用同一个mac地址,那么就需要用这个构建虚拟网络,不过使用极少
- 将一块物理网卡虚拟成多块虚拟网卡
容器相互通信
自定义网络
docker network create custom_network
- 会产生一个新的bridge(该bridge和docker0处于同一级,是另一个网卡)
- 属于同一个网卡下容器可以直接通过ip相互访问,如果需要通过名字访问,需要设置
--name 容器名字,这样就可以通过名字互相访问 - 网络添加容器
docker network connect 网络名称 容器名称
docker-compose
- 如果没有指定会创建一个上面的自定义网络,会创建一个网卡,并且指定名字,使得容器间可以相互访问,但是其他容器(比如自己起的容器)因为不在同一个网卡,无法直接通信,网桥名称为docker-compose.yml所在目录名称小写形式加上"_default"
- 如果需要compose和其他以及创建好的网卡交互,可以通过加入其网络实现
networks:
persist:
external:
name: bridge2
- 端口可以类似docker0直接映射到host端口
Overlay
- 一种用于跨主机的容器虚拟网络,建立在不同的主机之间容器直接访问
- 太复杂了,一般直接上k8s
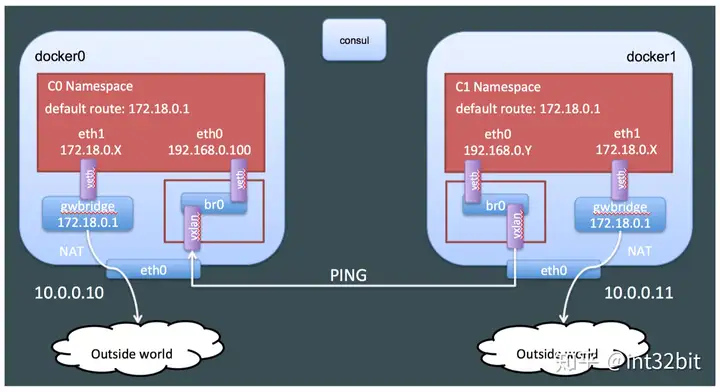
底层模型

- 通过namespace实现资源隔离,通过cgroup实现资源限制,通过写时复制技术(copy-on-write)实现了高效的文件操作
总体架构
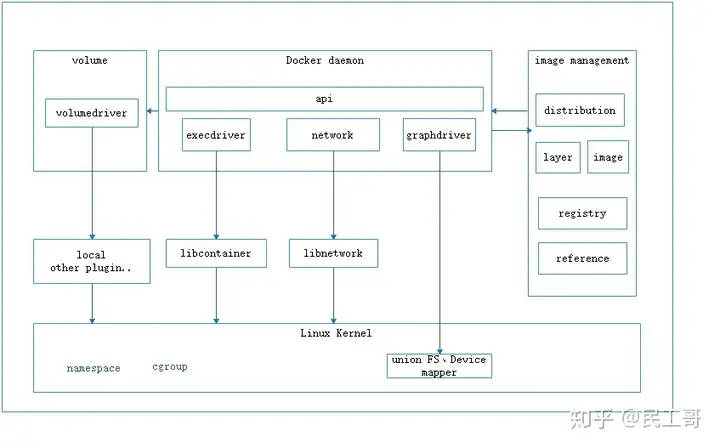
namespace隔离
- 通过namespace实现pid重新分配,以及其他资源的隔离
- 容器实际上就是一个运行中的程序,但是通过dockerd fork生成,对外界环境隔离
- 目录通过linux的/mnt挂载机制实现隔离
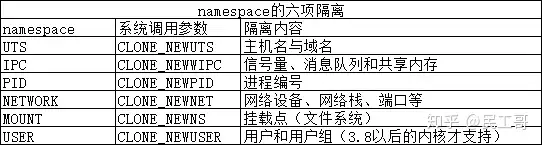
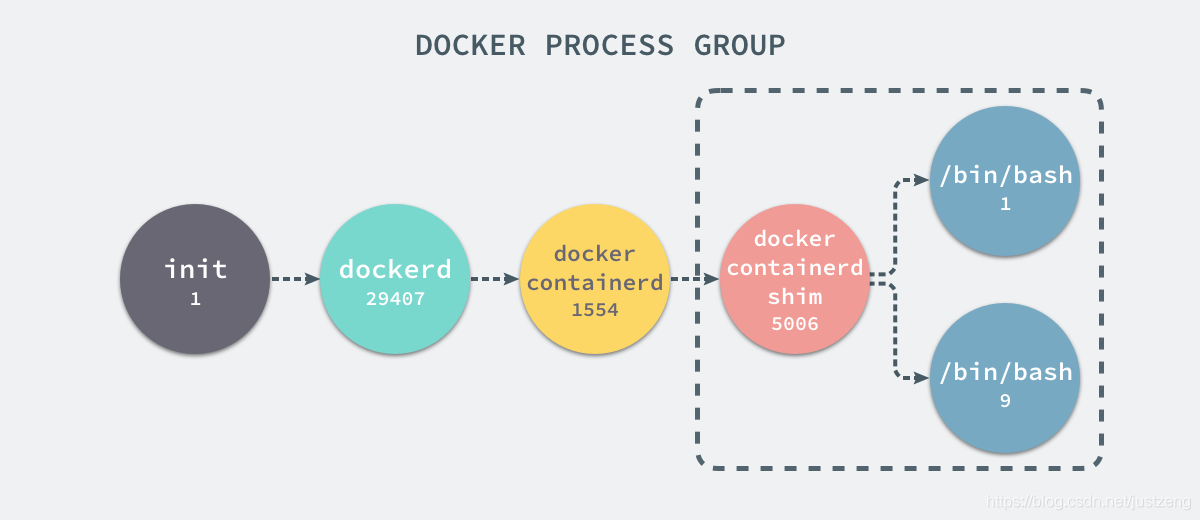
QA
docker如何连接host
linux
- 通过网卡(
ifconfig),获取docker0的ip,例如172.19.0.1,容器中可以直接使用 - 容器启动加上
--add-host=host.docker.internal:host-gateway - compose加上
extra_hosts:
- "host.docker.internal:host-gateway"
- 类似
version: '3.9'
services:
chatgpt:
image: dockerproxy.com/eryajf/chatgpt-dingtalk:latest
container_name: chatgpt
environment:
- APIKEY=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
- MODEL="gpt-3.5-turbo-0301"
- SESSION_TIMEOUT=600
- HTTP_PROXY=http://host.docker.internal:15777
- DEFAULT_MODE="单聊"
ports:
- "8090:8090"
restart: always
extra_hosts:
- host.docker.internal:host-gateway
mac
- 也可以用
docker.for.mac.localhost - mac和windows类似,基于虚拟机,没有docker0网卡
docker alpine中遇到 sh: ... not found
- 因为alpine比较奇怪,不建议使用 >mkdir /lib64 >ln -s /lib/libc.musl-x86_64.so.1 /lib64/ld-linux-x86-64.so.2
connect: permission denied
newgrp docker
sudo gpasswd -a $USER docker
网段冲突
- vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://{阿里云提供}.mirror.aliyuncs.com"],
"bip":"172.19.0.1/16(需要修改的网段)"
}
- 重启docker网络服务
sudo systemctl daemon-reload
sudo systemctl restart docker
更换docker镜像源
- 创建或修改 /etc/docker/daemon.json 文件 (这部分可以通过 docker info 验证是否成功更改)
//all
{
"registry-mirrors": [
"https://registry.hub.docker.com",
"http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn",
"https://registry.docker-cn.com"
]
}
//self
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://自己的.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
//https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors
- 加载重启docker
systemctl restart docker
代理docker pull镜像
因为docker pull是在dockerd守护进程运行的,直接shell的代理不生效
- 运行
sudo mkdir -p /etc/systemd/system/docker.service.d - 编辑
/etc/systemd/system/docker.service.d/http-proxy.conf文件
[Service]
Environment="HTTP_PROXY=http://127.0.0.1:7890"
Environment="HTTP_PROXY=http://127.0.0.1:7890"
- 重启docker,加载配置文件,可以通过
sudo systemctl show --property=Environment docker检查是否运行成功
$ sudo systemctl daemon-reload
$ sudo systemctl restart docker
[!tip] 参考 如何配置docker通过代理服务器拉取镜像 | 自由行 配置docker pull代理_docker pull 代理-CSDN博客
docker安装脚本
微信
sudo docker run -d --name wechat --device /dev/snd --ipc="host" \
-v /tmp/.X11-unix:/tmp/.X11-unix \
-v /D/CACHE/docker/WeChatFiles:/WeChatFiles \
-e DISPLAY=unix$DISPLAY \
-e XMODIFIERS=@im=fcitx \
-e QT_IM_MODULE=fcitx \
-e GTK_IM_MODULE=fcitx \
-e AUDIO_GID=`getent group audio | cut -d: -f3` \
-e GID=`id -g` \
-e UID=`id -u` \
bestwu/wechat
企业微信
sudo docker run -d --name wxwork --device /dev/snd --ipc="host" \
-v /tmp/.X11-unix:/tmp/.X11-unix \
-v $HOME/WXWork:/WXWork \
-v $HOME:/HostHome \
-v $HOME/wine-WXWork:/home/wechat/.deepinwine/Deepin-WXWork \
-e DISPLAY=unix$DISPLAY \
-e XMODIFIERS=@im=fcitx \
-e QT_IM_MODULE=fcitx \
-e GTK_IM_MODULE=fcitx \
-e AUDIO_GID=`getent group audio | cut -d: -f3` \
-e GID=`id -g` \
-e UID=`id -u` \
-e DPI=96 \
-e WAIT_FOR_SLEEP=1 \
boringcat/wechat:work
kafka
version: '2.1'
services:
zookeeper:
image: wurstmeister/zookeeper:latest
ports:
- "2181:2181"
kafka:
restart: always
image: 'bitnami/kafka:2.8.1'
ports:
- '9092:9092'
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
depends_on:
- zookeeper
vscode
- 权限会被更改要非常注意!
docker run -d \
-p 5200:8443 \
--name=code-server \
-e DEFAULT_WORKSPACE=/config/workspace \
-e PASSWORD=123 \
-e SUDO_PASSWORD=123 \
-v /root/vscode/config:/config \
-v /root/code:/config/workspace \
--restart always \
--privileged=true \
linuxserver/code-server:latest
- 推荐
nohup ./code-server-4.89.0-linux-amd64/bin/code-server /root &,然后更改~/.config/code-server/config.yaml为
bind-addr: 0.0.0.0:5201 # 一定是0.0.0.0
auth: password
password: 123
cert: false
user-data-dir: /data/vscode/config
- 设置 ssh 的话吧
cert和cert-key放上文件路径就行 - nginx 配置的话
server {
listen 80;
listen [::]:80;
server_name mydomain.com;
location / {
proxy_pass http://localhost:8080/;
proxy_set_header Host $http_host;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection upgrade;
proxy_set_header Accept-Encoding gzip;
}
}
思源笔记
- 参考笔记方法 > docker部署
trilium
docker run -itd -p 5206:8080 -v ~/trilium/trilium-data:/root/trilium-data zadam/trilium
webdav
docker run --name=webdav -d -e USERNAME=chenxuan -e PASSWORD=123 -v /root/webdev/data:/data --memory="512m" -p 5202:80 --restart=always derkades/webdav
minio
#!/bin/bash
docker run \
-p 5200:5200 \
-p 5201:5201 \
--name minio \
-d --restart=always \
-e "MINIO_ROOT_USER=chenxuan" \
-e "MINIO_ROOT_PASSWORD=123" \
-v /root/minio/data:/data \
-v /root/.minio:/root/.minio \
--memory="512m" \
minio/minio server \
/data --console-address ":5200" -address ":5201
memos
#!/bin/bash
docker run -d \
--init \
--name memos \
--publish 5203:5230 \
--memory="512m" \
--volume /root/memos/memos:/var/opt/memos \
neosmemo/memos:stable
onlyoffice
sudo docker run -i -t -d -p 5204:80 --memory="512m" onlyoffice/documentserver
searxng
- 搜索引擎
docker run --rm \
-d -p 5209:8080 \
-v "${PWD}/searxng:/etc/searxng" \
-e "BASE_URL=http://117.72.72.46:5209/" \
--memory="512m" \
searxng/searxng
uptime-kuma
- 监控工具
docker run -d --restart=always -p 5205:3001 -v /root/uptime-kuma/uptime-kuma:/app/data --name uptime-kuma louislam/uptime-kuma
docker create和run的区别
docker create命令则只是创建一个新的容器,但不会自动启动容器。这意味着可以在容器创建后,使用其他命令对容器进行配置或修改,然后再使用docker start命令启动容器。
- docker run命令会自动创建并启动一个新的容器,而docker create只是创建一个新的容器。
- docker run命令可以指定要在容器内运行的命令,而docker create不会运行任何命令。
- docker run命令会返回容器的输出结果,而docker create只返回容器的ID。
docker run/create/start
- dcoker run相当于创建并启动,等于create+start
- docker start可以启动处于create或者stop状态的容器
docker run -it --rm <image_id> 指令
- 立刻运行,运行之后自动删除
Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running(docker安装)
- 如果不是wsl
systemctl daemon-reload
systemctl restart docker.service
- 如果是wsl(先把apt安装的docker卸载)
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
sudo service docker start
ERROR: client version 1.22 is too old. Minimum supported API version is 1.24
- 该dockers-compose第一行的2改成2.1
docker CMD和ENTRYPOINT区别
- ENTRYPOINT相当于自带使用
sh运行,优先级比CMD高,参考下图
docker如何实现镜像迁移
- 使用
docker save -o image.tar image_name导出镜像为压缩包 scp传输过去docker load -i /path/to/image.tar目标机器加载镜像
docker 查看容器占用内存情况
docker stats交互式,加上--no-stream 只返回当前的状态- 参考 Docker容器资源的占用情况 - 知乎
目前可用镜像库
- DockerHub容器镜像库|应用容器化
- 国内的 Docker Hub 镜像加速器,由国内教育机构与各大云服务商提供的镜像加速服务 | Dockerized 实践 https://github.com/y0ngb1n/dockerized · GitHub
docker stats
- 监控容器资源使用情况
- 使用 'memory'
docker 设置自动重启
- 重启的设置
--restartalways:总是重启on-failure[:max-retries]:仅失败时重启unless-stopped:除非手动停止,否则重启-
no:默认策略,不自动重启。
- 如果是没运行的容器
docker run --restart <策略类型> [其他参数] 镜像名
- 如果是已运行的容器更改类型
docker update --restart <策略类型> 容器名称或ID
docker镜像提交流程
1. 镜像打包
docker commit <容器ID> <新镜像名称>:<标签>tag这里直接数字,不要v开头
2. 上传到服务器
- 阿里云的参考官网就行
docker启动常见参数
-e key=val:设置环境变量,一个变量一个-e-d:设置后台运行--memory="512m":设置最大使用内存--cpu=2:设置最多使用的cpu数量
参考
- https://zhuanlan.zhihu.com/p/212772001
- https://juejin.cn/post/7041923410649153543
- https://www.cnblogs.com/BillyLV/articles/12896624.html
- https://www.cnblogs.com/crazymakercircle/p/15400946.html
- https://zhuanlan.zhihu.com/p/363419059 (重要)
加载
调试out
- gdb a.out
调试core
- 生成core
ulimit -c unlimited(只对一个终端有用)
# 如果设置了没生成用这个看下生成的目录
cat /proc/sys/kernel/core_pattern
# 如果想生成当前目录或者没权限
sudo sysctl -w kernel.core_pattern=core # 临时改为生成 core 文件
- gdb (程序名) (core名字)
调试程序
- gdb attach pid
运行
带着gui
- gdb -tui (a.out)
设置arg
- set args 运行时参数
常用
- r 开始运行
- c 运行到断点
- n 下一步
- s 进入函数
- until 跳出循环
- fin 结束函数
- bt backtrace 显示当前调用堆栈
- where 查看core目前位置的调用栈
打印
源代码打印
- list num(打印num行附近代码)
- list 打印代码,一直回车一直打
变量打印
- print (打印一切)
断点
设置
- b 11(普通断点)
- b 11 if some>=0(条件断点)
- tb 11(临时断点,只用一次失效)
删除断点
- delete (可以指定断点编号)
查看断点
- info break
多线程
查看线程信息
- info thread
切换线程
- thread id
查看调用帧
- info frame
- backtrace
显示汇编
修改布局
- layout asm
显示函数汇编
- disas /m functionname
查看目前汇编
- x/i $pc
- display /3i $pc
i line 13
disassemble 0x4004e9, 0x40050c
退出 q
GCC
常用指令
-g:生成调试二进制文件-DDEBUG=10:设置宏的值-I:include,添加头文件,如-I/home/user/include-l:直接链接静态库,类似-lfmt -lpthread-L:编译程序按照指定的路进去寻找库文件,一般的在-L的后面可以一次用-l指定多个库文件。如-L../lib-D:设置宏,类似-D SSL
makefile
固定变量
- $^ 表示所有的依赖文件
- $@ 表示生成的目标文件
- $< 代表第一个依赖文件
.PHONY
- 标识某个是目标而不是命令
.PHONY: clean ALL
@+指令
- 隐藏指令执行结果(不显示到输出)
demo
all:main
cc=g++
obj_source=./main.cpp ../util/config.cpp ../server/game/game.cpp
obj=main
header=-I../util
link=-lfmt
.PHONY:main
main: $(source)
$(cc) -g $(obj_source) -o $(obj) $(link) $(header)
[!quote] 参考 https://zhuanlan.zhihu.com/p/575852387
nginx
- 七层负载均衡器,可以通过访问的域名转发
- 重新加载配置命令为
nginx -s reload nginx -t检查配置文件是否正确
配置文件解析
以下这部分server是放在http块中的
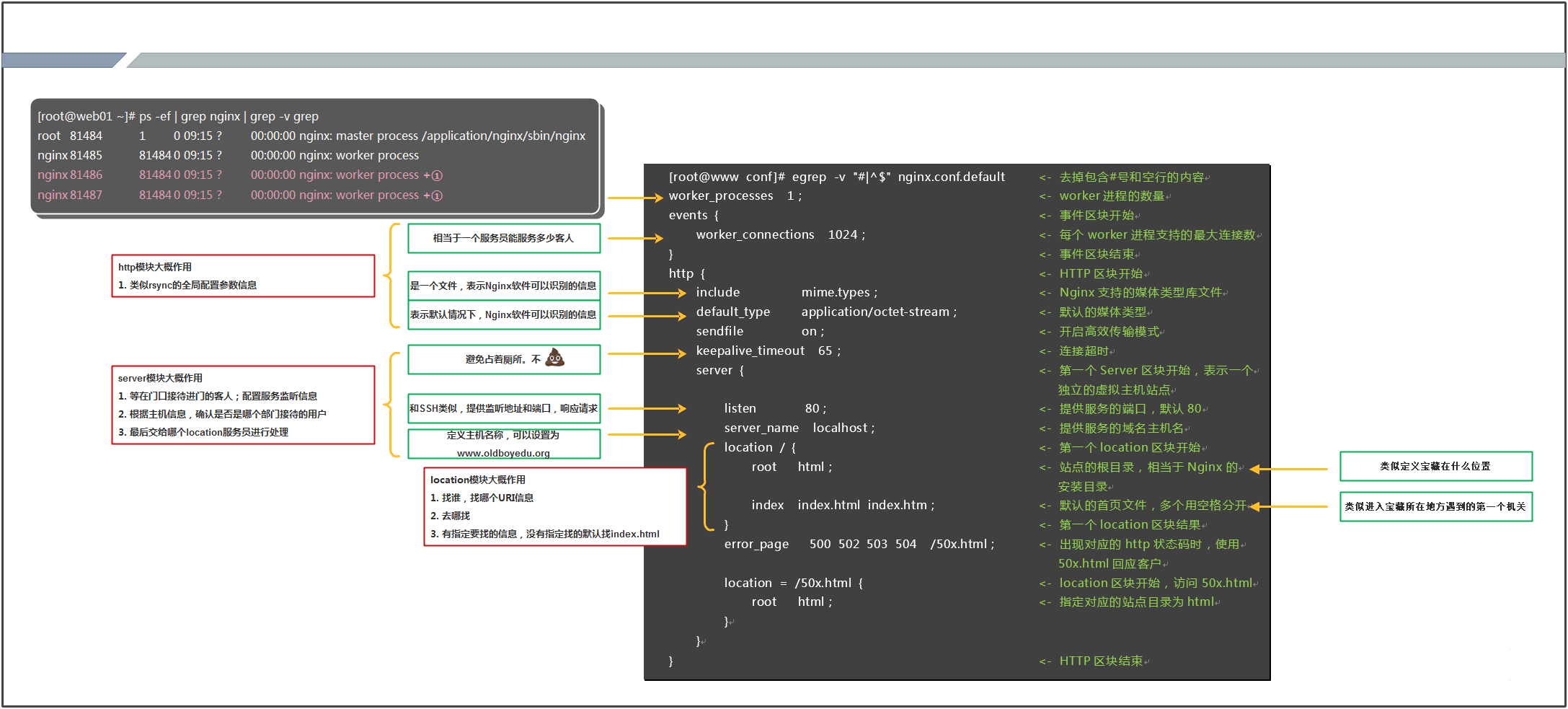
server{
listen 80;
server_name _;#配置访问的域名,依赖七层负载均衡
location /api/ {
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header REMOTE-HOST $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://127.0.0.1:5200;
}
# 会优先匹配长的(/api和/优先/api,一样长优先匹配先定义的)
location / {
root /data/frontend/dist;
add_header Cache-Control "private, no-store, no-cache, must-revalidate, proxy-revalidate";
try_files $uri $uri/ /index.html;# 这行是找不到自动跳到index.html
index index.html;
}
location /file/ {
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header REMOTE-HOST $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://127.0.0.1:5200;
}
}
https ssl配置
# 80 端口配置转发
server{
listen 80;
server_name chenxuanweb.top;
return 302 https://$host$request_uri;
}
# ssl 443 端口配置
server{
listen 443 ssl;
server_name chenxuanweb.top;
ssl_certificate /root/ssl/note.chenxuanweb.top.pem;
ssl_certificate_key /root/ssl/note.chenxuanweb.top.key;
ssl_session_timeout 5m;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers ECDHE-RSA-AES129-GCM-SHA256:HIGH:!aNULL:!MD5:!RC4:!DHE;
ssl_prefer_server_ciphers on;
location / {
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header REMOTE-HOST $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://127.0.0.1:6888;
}
}
cdn http 转 https 配置
server {
server_name sslcdn.xxx.top;
# 1. 开启 Gzip 压缩(如果图片是 SVG 或未压缩的,很有用)
gzip on;
gzip_types image/svg+xml;
location / {
proxy_pass http://cdn.xxx.top;
proxy_set_header Host cdn.xxx.top;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# 2. 必须开启缓存!减少对源站的拉取,同时加速本地响应
# 即使有时候慢,有缓存也会比没缓存快
proxy_cache_valid 200 302 7d;
# 3. 关键优化:控制连接超时,快速释放占用的带宽资源
proxy_connect_timeout 5s;
proxy_read_timeout 10s;
proxy_send_timeout 10s;
# 4. 限制单个 IP 的并发连接数(防止刷新过猛)
# limit_conn addr 3;
# 5. 限制单连接带宽(非常重要!)
# 如果不限速,一个图片请求就会抢走所有 128KB 流量,导致其他请求(如 CSS/JS)全部卡死。
# 限制每个请求最多 40KB/s,这样可以保证同时加载 3 张图。
limit_rate 40k;
}
listen 443 ssl;
# ... ssl 配置保持不变 ...
# 6. 开启 TCP 优化
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
}
常见问题
403
- 权限问题,考虑配置文件第一行的
user更改为root,然后重启 - 大概率是因为文件夹的权限不是755 可以检查一下
错误日志查看
tail /var/log/nginx/error.log
反向代理的四个斜杠
- 整体如下文,核心就是
- proxy_pass 代理地址端口后无任何字符(就是类似 http://ip:port ) 转发后实际地址:代理地址+访问URL接口路径部分。
- proxy_pass 代理地址端口后有目录(就是类似 http://ip:port/abc/ 包括 / ),转发后实际地址:代理地址+访问URL目录部分去除location匹配目录。
- location部分如果有 /,并且代理地址端口后有字符或者目录(包括 /),那么意思是将 location_path/* 转发到 proxy_pass/path* 进行访问, 其中*为请求的静态资源,此时 proxy_pass/path 后面必须有 / 否则会直接拼接导致错误. 如果此时代理地址端口后无字符或者目录,会自动追加localtion部分的location_path,使得变得正确
- location 部分没有 /,基本和有的差不多,但是如果是 http://ip:port/ 的出现双斜杠问题
二、location匹配路径末尾有 /
此时proxy_pass后面的路径需要分为以下四种情况讨论:
(1)proxy_pass后面的路径只有域名且最后没有 /
location /sta/
{
proxy_pass http://192.168.1.1;
}
外面访问:http://外网IP/sta/sta1.html
相当于访问:http://192.168.1.1/sta/sta1.html
(2)proxy_pass后面的路径只有域名同时最后有 /
location /sta/
{
proxy_pass http://192.168.1.1/;
}
外面访问:http://外网IP/sta/sta1.html
相当于访问:http://192.168.1.1/sta1.html
(3)proxy_pass后面的路径还有其他路径但是最后没有 /:
location /sta/
{
proxy_pass http://192.168.1.1/abc;
}
外面访问:http://外网IP/sta/sta1.html
相当于访问:http://192.168.1.1/abcsta1.html
(4)proxy_pass后面的路径还有其他路径同时最后有 /:
location /sta/
{
proxy_pass http://192.168.1.1/abc/;
}
外面访问:http://外网IP/sta/sta1.html
相当于访问:http://192.168.1.1/abc/sta1.html
总结
- 两个都加上斜杠!!!,并且proxy_pass 后面的路径补充完整(带着api,除非需要截取)
location /nacos/ {
proxy_pass http://127.0.0.1:5000/nacos/;
}
# or
location / {
proxy_pass http://127.0.0.1:5000/;
}
[!tip] 参考 Nginx 带不带斜杆的区别最全分析 Nginx 故障排查之斜杠(/) --(附 Nginx 常用命令) nginx proxy_pass后的url加和不加反斜杠‘/’的区别 | ActPi's Blog
https 和http同时配置混乱
[!question] 问题 当nignx 同时配置 http 和 https 服务时候, 假设 a.b.com 是 http 的, c.b.com 是https 的, 但是浏览器输入 a.b.com 的时候默认走 https的 443, 出现提示证书无效的问题
- 通过在 443 端口上配置加上类似下面的操作就行
# 443端口通用配置 - 非c.b.com的域名重定向到HTTP
server {
listen 443 ssl default_server;
server_name _;
# 使用默认证书
ssl_certificate /path/to/default_cert.pem;
ssl_certificate_key /path/to/default_key.pem;
# 对非c.b.com的域名重定向回HTTP
if ($host != 'c.b.com') {
return 301 http://$host$request_uri;
}
# c.b.com的请求应该由上面的特定server块处理
return 403; # 如果到达这里,说明配置可能有问题
}
代理https的原理
Charles抓包工具
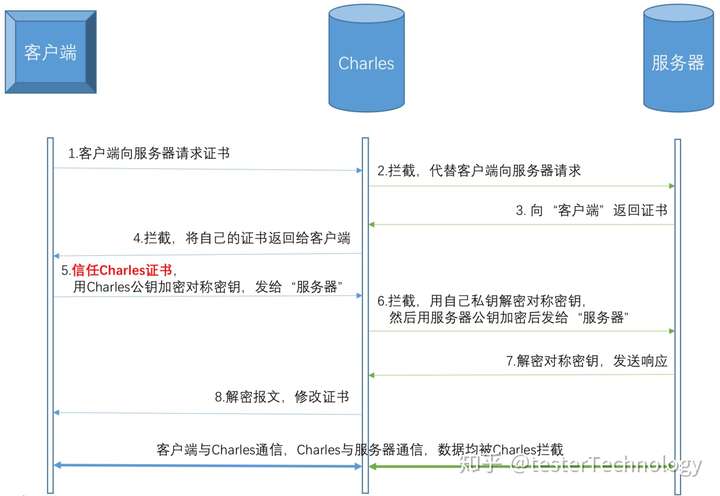
- 客户端向服务器发起HTTPS请求
- Charles拦截客户端的请求,伪装成客户端向服务器进行请求
- 服务器向“客户端”(实际上是Charles)返回服务器的CA证书
- Charles拦截服务器的响应,获取服务器证书公钥,==然后自己制作一张证书,将服务器证书替换后发送给客户端==。(这一步,Charles拿到了服务器证书的公钥)
- 客户端接收到“服务器”(实际上是Charles)的证书后,生成一个对称密钥,用Charles的公钥加密,发送给“服务器”(Charles)
- Charles拦截客户端的响应,用自己的私钥解密对称密钥,然后用服务器证书公钥加密,发送给服务器。(这一步,Charles拿到了对称密钥)
- 服务器用自己的私钥解密对称密钥,向“客户端”(Charles)发送响应
- Charles拦截服务器的响应,替换成自己的证书后发送给客户端
- 至此,连接建立,Charles拿到了 服务器证书的公钥 和 客户端与服务器协商的对称密钥,之后就可以解密或者修改加密的报文了。
实现的核心
-
客户端首先需要加入charles的CA证书,实际上的核心是伪造了证书,步骤是
- 自己制造证书,域名什么的都写上去,计算哈希值,然后用自己的私钥加密后写入证书,假装是Charles发的ssl证书
- 客户端拿到之后根据Charles的CA公钥进行验证,发现没问题
-
验证和加密过程参考### 握手流程
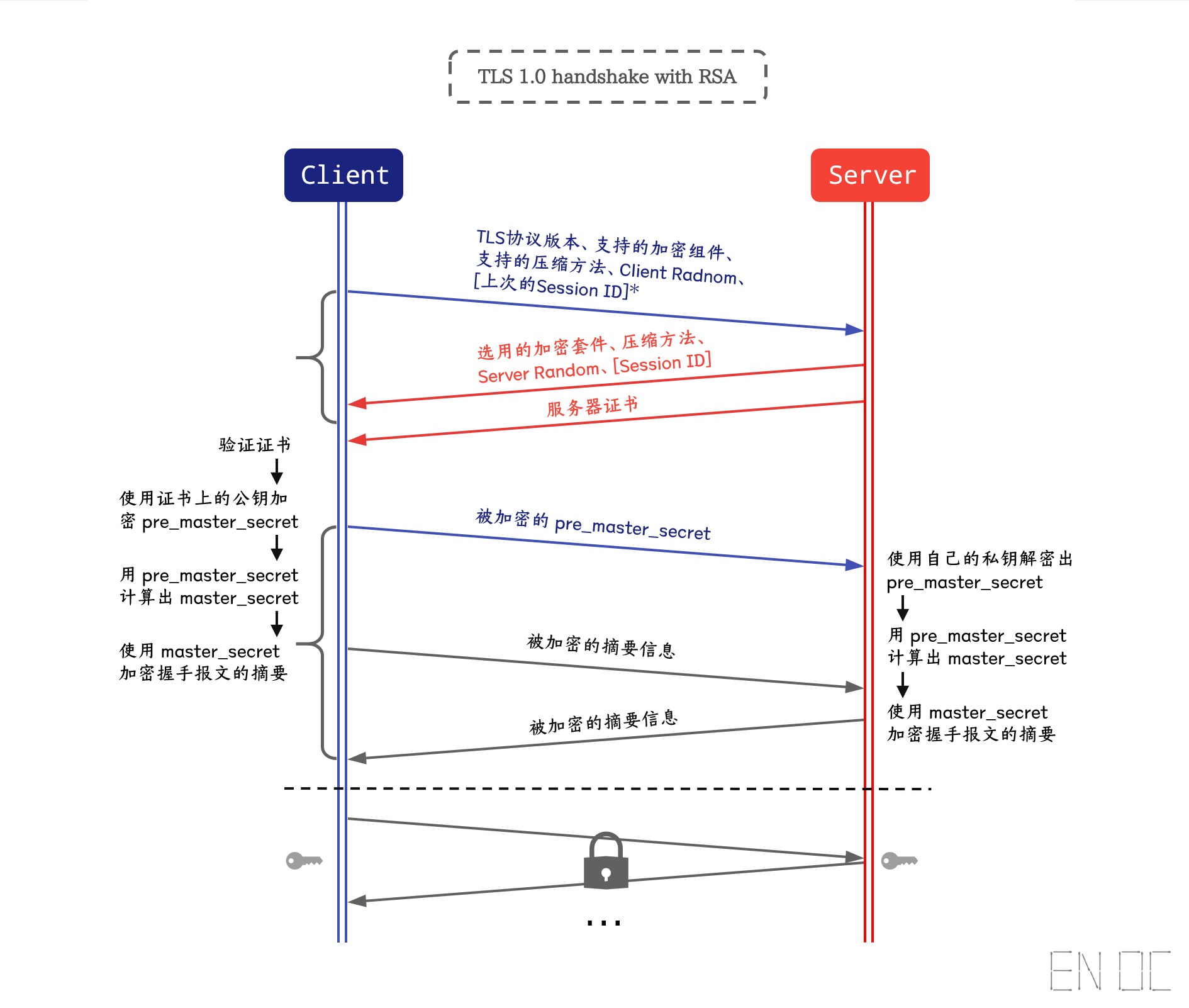
-
客户端发起请求,发送clirand
-
服务端发送签名证书,公钥,serrand
-
客户端校验证书合法性
- 证书签发会对内容进行hash计算签名值,然后对签名进行私钥加密,并把加密后的签名加到证书
- 客户端根据证书CA获取签发的机构的公钥,对签名解密,获取hash值
- 客户端自己对证书hash,比较hash是否相同,相同则信任^[https://www.zhihu.com/question/37370216]
因为CA的私钥是未知的,伪造证书无法生成相同hash值
-
客户端再生成secretrand,并且使用公钥加密,发送到服务端
-
服务端进行私钥解密得到secretrand,将三个随机数连接并进行hash算法,得到值作为加密密钥,进行对称加密^[https://www.cnblogs.com/enoc/p/tls-handshake.html]
-
中间人进攻
- 实际上就是上面代理的原理,也就是https防火墙的原理
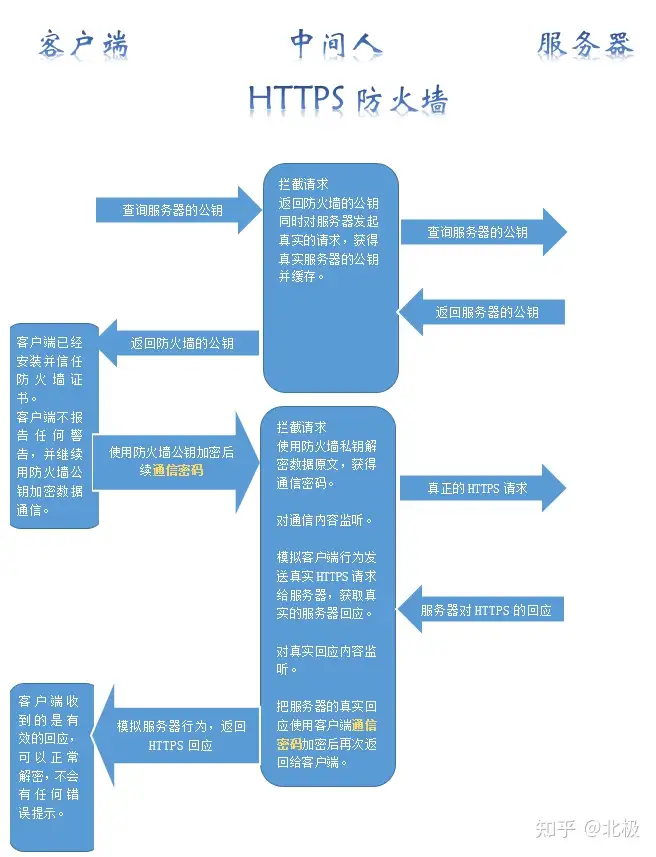
- 这部分需要进攻的难点在于
- 同时掌握证书+网关硬件,才能做到完整的中间人攻击,一般来说,只有在公司(电脑+网络都属于公司)的情况下才能做到
- 需要模拟真实的https,如果出现大量请求,会很慢
参考
- https://zhuanlan.zhihu.com/p/372610935
- https://www.jianshu.com/p/405f9d76f8c4
- https://zhuanlan.zhihu.com/p/412540663
堡垒机连接
- 堡垒机连接 #快捷命令
ssh username@目标机器IP -p 22 -J username@跳板机IP:22
- 多个堡垒机,使用空格分割
文件夹大小排序
- 文件夹大小排序 #快捷命令
du -sh ./* | sort -rn
使用默认应用打开
see index.html
查看文件MIME类型
file --mime-type (file-name)
修改文件默认打开方式
alias open='xdg-open'
mimetype filename- 加到~/.config/mimeapps.list
[Default Applications]
inode/directory=nautilus.desktop
video/x-matroska=mpv.desktop
mdbook
#!/usr/bin/env python3
# coding=utf-8
#!/usr/bin/python3
# coding=utf-8
import os
import sys
result = "#Summary\n\n"
is_sort = True
def createBook(file, tab, path):
global result
if is_sort:
file.sort()
for name in file:
temp = os.path.splitext(os.path.basename(name))[0]
dirname = path+name
if os.path.isdir(dirname):
base = path+name+"/README.md"
if os.path.isfile(base) == False:
base = ""
if os.path.isfile(dirname+".md"):
base = dirname+".md"
result = result+tab+"- ["+temp+"]("+base+")\n"
createBook(os.listdir(dirname), tab+"\t", path+name+"/")
else:
if name == "README.md" or name == "SUMMARY.md":
continue
# 获取文件的非后缀部分
file_path = os.path.splitext(dirname)[0]
if os.path.isdir(file_path):
continue
# 获取文件的后缀
file_ext = os.path.splitext(dirname)[1]
if file_ext != ".md":
print("Warning:", dirname, "is not md file,ignore")
continue
base = path+name
result = result+tab+"- ["+temp+"]("+base+")\n"
def main():
global result
if len(sys.argv) == 1:
print("Usage: python3 update.py {dir_path}")
return
dir_path = sys.argv[1]
if os.path.isdir(dir_path) == False:
print("dir is not exist")
return
os.chdir(dir_path)
if os.path.isfile("./SUMMARY.md"):
os.remove("./SUMMARY.md")
if os.path.isfile("./README.md"):
result = result+"- [README](./README.md)\n"
createBook(os.listdir("."), "", "./")
f = open("./SUMMARY.md", "w+")
f.write(result)
f.close()
os.chdir("..")
print(" create ok")
if __name__ == "__main__":
main()
磁盘挂载
垃圾ibus
- ibus-daemon -r -d -x## fcitx词库
- https://zhuanlan.zhihu.com/p/508797663
fcitx ctrl-;
- https://zhuanlan.zhihu.com/p/113980639
fcitx候选词调整
- 配置 -> 双击 ->候选词顺序全部调整为快速
fcitx全角半角
sudo apt-get install fcitx-ui*然后重启打开输入法就可以看到选项了- 傻逼fcitx如果需要设置的话需要在输入法中设置
拼音这个输入法进行设置,右键点击,需要出现大一点的画面才能进行设计,太愚蠢了,其他的输入法无法进行设置,推荐默认半角,全角都是傻逼
bashrc和profile
~/.bash_profile是交互式、login 方式进入 bash 运行的~/.bashrc是交互式 non-login 方式进入 bash 运行的
如果只需要执行一次,推荐放入profile,否则通通放入bashrc login方式使用的是登录系统获得的顶层shell no-login使用套娃的shell
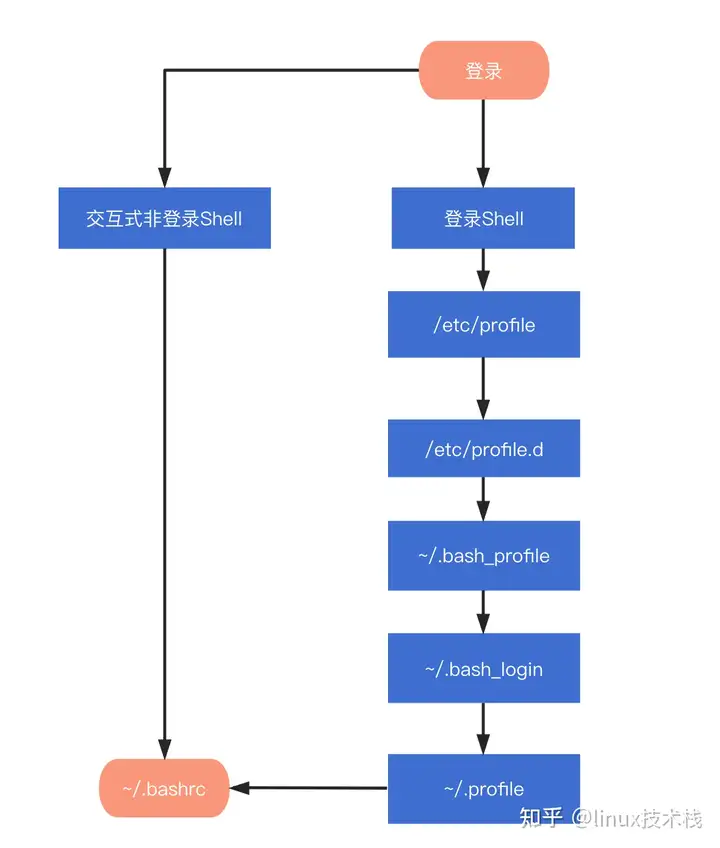
mint开机错误
vim /etc/default/grub- 修改
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"为GRUB_CMDLINE_LINUX_DEFAULT="quiet splash loglevel=3" sudo update-grub
mint非显卡驱动问题
sudo apt dist-upgradesudo apt upgrade>upgrade:系统将现有的 Package 升级,如果有相依性的问题,而此相依性需要安装其它新的 Package 戒影响到其它 Package 的相依性时,此 Package 就丌会被升级,会保留下来. dist-upgrade:可以聪明的解决相依性的问题,如果有相依性问题,需要安装/移除新的 Package,就会试着去安装/移除它. (所以通常 dist-upgrade 会被认为是有点风险的升级)
key证书生成pem证书
openssl rsa -in (key name).key -out (new name).pem
自签名证书 openssl 生成
openssl req -x509 -newkey rsa:4096 -sha256 -nodes -keyout privkey.pem -out cacert.pem -days 3650
[!tip] 参考 openssl生成pem数字证书_openssl使用tls1.2生成pem-CSDN博客 Openssl生成自签名证书,简单步骤 - 凝雨 - Yun
stderr和stdout区别
- stderr不缓存,直接输出到屏幕
- stdout行缓冲,等一行再输出
禁用密码登录
- 修改SSH的配置文件/etc/ssh/sshd_config
- 将
PasswordAuthentication yes修改为PasswordAuthentication no
查询进程的完整路径
- 获取进程的pid,可以使用
lsof,ps aux|grep {name}等方式 - 运行
ls -l /proc/{pid}/exe
将docker容器日志保存
docker logs 容器id &> $(date '+%Y%m%d%H%M%S').log
1> 或 > :把STDOUT重定向到文件
2> :把STDERR重定向到文件
&> :把标准输出和错误都重定向
>& :和上面功能一样,建议使用上面方式
source和直接运行区别
- 直接执行脚本文件:当直接执行脚本文件时,操作系统会新建一个子进程来运行脚本文件,这个子进程将作为父进程的一个子进程存在。因此,父进程无法访问子进程中定义的变量和函数。而且,子进程中对环境变量、当前目录等的修改也不会影响到父进程。
- 使用source命令调用脚本文件:当使用source命令调用脚本文件时,脚本文件中定义的变量和函数将在当前shell环境中生效,而不是在一个新的子进程中被执行。因此,通过source命令调用脚本文件可以实现在当前shell环境中定义变量、函数等操作,同时也可以访问在其他地方定义的变量和函数。
xmodmap使用
按键重新映射
1. 获取键码
- xev
2. 获取按键名字
- xmodmap -pke | grep 键码 (所有键码)
- xmodmap -p 获取修饰按键信息
3. 设置按键映射
remove lock = Caps_Lock # 将产生lock的按键列表中除去caplock按键
add control = Caps_Lock # 将ctrl按键列表中添加Caps_Lock按键
keycode 66 = Control_L # 将66(原来是caplock)映射按键名字为Control_L
firefox阅读模式
- 我平等的鄙视csdn和已经所有现在还在csdn上发文的人
about:config后reader.parse-on-load.enabled则只为true- 网页url前加上
about:reader?url=
firefox阻止不安全混合
- https网页中相互先有http请求的内容自动拦截,解决办法
将caplock映射为中英文切换
- 将caplock设置为menu按键(使用系统设置或者xmodmap)
- 将menu按键设置为中英文切换按键(使用输入法设置)
触控板设置mac类似手势
#cmd
# libinput-gestures-setup start|stop|restart|autostart|autostop|status|remove
#install
# sudo gpasswd -a $USER input(remember to boot)
# git clone https://github.com/bulletmark/libinput-gestures.git
# cd libinput-gestures
# sudo ./libinput-gestures-setup install
#uninstall
# libinput-gestures-setup stop autostop
# sudo libinput-gestures-setup uninstall
#update config
# libinput-gesture-setup restart
#doc
# https://github.com/bulletmark/libinput-gestures
gesture swipe up 3 xdotool key Ctrl+Alt+Down(这部分快捷键根据键盘设置的快捷键进行)
gesture swipe left 3 xdotool key Ctrl+Alt+Tab
gesture swipe right 3 xdotool key Shift+Ctrl+Alt+Tab
ssh长时间无操作自动断开
以下操作只需要执行一个
客户端
vim ~/.ssh/config
Host *
ServerAliveInterval 30
ServerAliveCountMax 2
- 重新启动终端ssh
服务器
- sudo vim /etc/ssh/sshd_config
- 查找以下注释字段取消注释或直接添加至文件
ClientAliveInterval 60
ClientAliveCountMax 3
zotero黑暗模式设置
- 插件链接,步骤参考
- 如果找不到pdf的按钮可以通过
alt+shift+c去快速切换模式(zoter-dark-7插件有):7.0.0-beta.65+b047f3d90 (64-bit) 0.1.0-2
zotero同步设置
- 参考【工程笔记】搭建Zotero同步服务器 - 知乎
- 搭建webdev参考docker > docker安装脚本
批量替换文件内容
mac 需要
brew install gnu-sed然后用gsed
- sed+grep
sed -i "s/{查找内容}/{替换内容}/g" \`grep "{查找内容}" -rl ./ --exclude-dir=".git"\`
- sed+find
#!/bin/bash
# 检查参数数量
if [ "$#" -ne 2 ]; then
echo "Usage: $0 <old_string> <new_string>"
exit 1
fi
# 在当前目录及其所有子目录中查找并替换目标字符串
# 根据操作系统设置sed命令参数
if [[ "$OSTYPE" == "darwin"* ]]; then
# 如果是Mac,使用空字符串作为备份后缀
find . -path './.git' -prune -o -type f -exec sed -i '' "s|$1|$2|g" {} +
else
# 如果是Linux,省略备份参数
find . -path './.git' -prune -o -type f -exec sed -i "s|$1|$2|g" {} +
fi
echo "String replacement completed."
为clash默哀
- https://clashxhub.com/clash-backup-download/
- CharlesWolff6/airport: 翻墙机场推荐 (github.com)
- Releases · libnyanpasu/clash-nyanpasu · GitHub
clash linux设置
- 解压后运行,将链接放到
clash ->profiles中并点击download - 默认绑定顶端口为7890,这个可以自己设置,在
clash->general第一个设置就是,用lsof -i:8889看一下是否更改成功 - 在
网络设置-> 网络代理 -> 设置为手动设置并且全部更改为127.0.0.1:8089 - 退出clash的时候记得关闭网络代理
html格式化
#!/bin/bash
clear
echo $1
cat $1 > HTML
echo -n "cat HTML " > CMD
#eval $(cat CMD)
TAGS=$(cat HTML |sed 's/</\n</g' |awk -F " " '{print $1}' |grep -v "</\|?\|&&\|!" |awk -F "<|>" '{print $2}' | sort -u |xargs);
echo $TAGS;
for tag in ${TAGS[@]}; do cmd="|sed 's/<$tag/\n<$tag/g'"; echo -n $cmd >> CMD; done;
#cat CMD;
eval $(cat CMD) | tee -a HTML
rm CMD
rm HTML
打包下载gitlab库
- token需要去setting生成
#!/usr/bin/env python3
# coding=utf-8
import requests
import os
from urllib.parse import urlparse
base_url=input("Enter Gitlab Group Url: ")
parsed_url = urlparse(base_url)
domain = parsed_url.netloc
group = parsed_url.path.strip('/').split('/')[-1]
base_url = f"https://{domain}/api/v4/"
token=input("Enter Gitlab Access Token: ")
param=input("Enter Git Clone Param (optional): ")
def gitlab_api_request(endpoint, params=None):
# base_url = "https://gitlab.demo.cn/api/v4/" # 请替换为你的 GitLab 实例 URL
# token = "demo" # 请替换为你的 GitLab 私有访问令牌
headers = {"PRIVATE-TOKEN": token}
response = requests.get(base_url + endpoint, headers=headers, params=params)
if response.status_code == 200:
return response.json()
else:
raise Exception(f"GitLab API request failed with status code {response.status_code}: {response.text}")
def clone_project(project, path='.'):
project_path = os.path.join(path, project['path_with_namespace'])
project_url = project['ssh_url_to_repo'] # 使用 SSH 克隆链接
# Clone the project
os.system(f"git clone {param} {project_url} {project_path}")
def clone_group_recursive(group_id, path='.'):
group_info = gitlab_api_request(f"groups/{group_id}")
group_name = group_info['name']
group_path = os.path.join(path, group_name)
os.makedirs(group_path, exist_ok=True)
# Clone projects in the group
projects = gitlab_api_request(f"groups/{group_id}/projects")
for project in projects:
clone_project(project, group_path)
# Recursively clone subgroups
subgroups = gitlab_api_request(f"groups/{group_id}/subgroups")
for subgroup in subgroups:
subsubgroup_id = subgroup['id']
clone_group_recursive(subgroup_id, group_path)
if __name__ == "__main__":
# group_id = input("Enter GitLab Group ID: ")
destination_path = input("Enter Destination Path (default is current directory): ") or '.'
clone_group_recursive(group, destination_path)
print(f"Cloning of GitLab Group {group} and its subgroups completed.")
agent refused operation
- 出现这个问题看一下私钥是不是600的权限,大部分是.ssh权限的设置出问题了
termux
- ubuntu系统搭建参考
- root用户
termux-chroot命令 - 电脑远程连接手机termux参考
pkg install opensshsshd # 开启ssh连接- 复制ssh密钥
ssh -p 8022 <user>@<IP地址>
- termux访问手机文件夹,参考文章
pkg install termux-apitermux-setup-storagecd ~/storage
linux文件目录
系统目录作用
.
├── bin -> usr/bin # 可执行文件的文件夹
├── boot # 这个目录用来存放系统启动所需文件、内核, 开机菜单以及所需配置的文件等
├── dev # 存放外设,例如串口等
├── etc # 配置目录,例如nginx
├── home # 家目录
├── lib -> usr/lib # 存放着系统最基本的动态连接共享库
├── lib32 -> usr/lib32 # 32位动态库
├── lib64 -> usr/lib64 # 64位动态库
├── libx32 -> usr/libx32
├── lost+found # 一般情况下是空的,当系统非法关机后,这里就存放了一些文件
├── media # 自动识别一些设备,例如U盘、光驱等等,当识别后,Linux 会把识别的设备挂载到这个目录下
├── mnt # 挂载目录
├── opt # 给主机额外安装软件所摆放的目录
├── proc # 存储的是当前内核运行状态的一系列特殊文件,这个目录是一个虚拟的目录,它是系统内存的映射
├── root # root用户默认目录
├── run # 临时文件系统,存储系统启动以来的信息。当系统重启时,这个目录下的文件应该被删掉或清除。
├── sbin -> usr/sbin # root使用的bin
├── srv # 存放一些服务启动之后需要提取的数据。
├── swapfile # 交换文件
├── sys
├── tmp
├── usr # usr 是 unix shared resources(共享资源) 的缩写
└── var # var 是 variable(变量) 的缩写,这个目录中存放着在不断扩充着的东西,我们习惯将那些经常被修改的目录放在这个目录下。包括各种日志文件。
- 用户自定义desktop地址
~/.local/share/applications/ 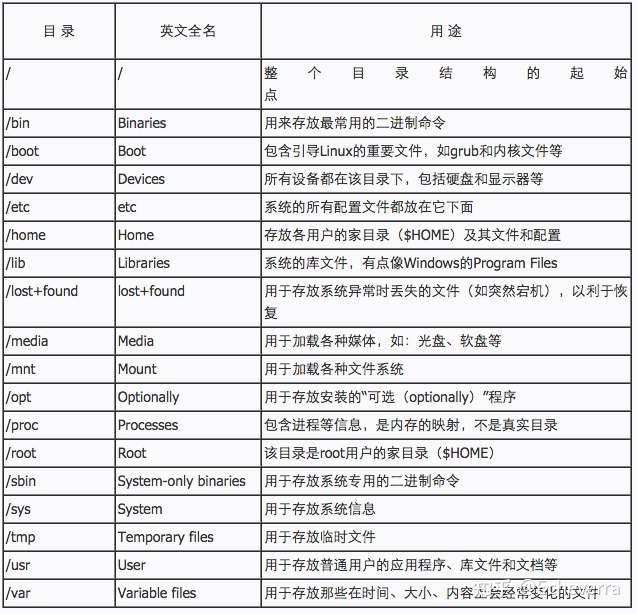
ssh github无法连接
- 首先检查ssh时能能通,参考常用命令 > DNS
- 尝试使用443端口进行push
- 编辑~/.ssh/config
- 插入代码
- 再次尝试是否能push
Host github.com
Hostname ssh.github.com
Port 443
User git
- 如果还有问题开梯子之后设置git代理,这部分参考gitothers > git 设置代理
有时,防火墙会完全拒绝允许 SSH 连接。 如果无法选择使用具有凭据缓存的 HTTPS 克隆,可以尝试使用通过 HTTPS 端口建立的 SSH 连接克隆。 大多数防火墙规则应允许此操作,但代理服务器可能会干扰。
ssh免密登录失败
- 大概是权限问题,排查思路参考解决SSH免密登录配置成功后不生效问题-百度开发者中心
- 主要通过
/var/log/auth.log查看问题
Clash 终端代理
- 一次性设置,关闭终端自动取消
export https_proxy=http://127.0.0.1:8889;
export http_proxy=http://127.0.0.1:8889;
export all_proxy=socks5://127.0.0.1:8889;
- 删除变量用unset
unset https_proxy
unset http_proxy
unset ftp_proxy
unset all_proxy
[!tip] 参考 https://docs.github.com/zh/authentication/troubleshooting-ssh/using-ssh-over-the-https-port
clash git ssh 代理
[!tip] 参考 解决机场禁用 22 端口导致 github 无法 ssh 问题 - 闻道录
- 实际上就是编辑
~/.ssh/config文件, 将下面这几行放开就行
# Host github.com
# Hostname ssh.github.com
# Port 443
# User git
#
# Host github.com
# User git
# ProxyCommand nc -X 5 -x 127.0.0.1:7890 %h %p
npm
查看包的所有历史版本
- 运行
npm view <包名> versions
yarn/npm install 下载不了
- 把 yarn.lock 直接删掉或者将其里面的链接替换成国内镜像的
- 具体参考 使用yarn安装依赖包出现“There appears to be trouble with your network connection. Retrying...”超时的提醒 - Qubernet - 博客园
npmmirror 屏蔽 top 域名
- nginx 反向代理的时候加上
add_header Referrer-Policy "no-referrer"; - 类似
location / {
proxy_pass http://127.0.0.1:3210;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $host;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
add_header Referrer-Policy "no-referrer";
}
}
OCR
- 安装:
sudo apt install tesseract-ocr,安装语言包sudo apt-get install tesseract-ocr-chi-sim - 使用
tesseract <需要ocr的图片> stdout -l chi_sim
jsDelivr失效问题
- 静态连接中的cdn.jsdelivr.net/npm 换成 unpkg.com 仅限npm部分,或者改成fastly.jsdelivr.net/npm 也可以
- unpkg.com 速度还是很慢, unpkg.com 换成 s4.zstatic.net/npm 参考CDNJS/UNPKG/JSDelivr 太慢用不了,换成这些国内高速镜像-阿里云开发者社区
- 这两个沙币玩意都不大行 , 现在方案是通过 BootCDN - Bootstrap 中文网开源项目免费 CDN 加速服务 铂特优选 这个, 这个再挂就只能全部自己静态缓存了
- 其他的考虑更换其他的cdn
- 如果是单个文件可以考虑使用 gitee 的 release cdn 还蛮好用的
博客跨域图片问题
- html中加上
<meta name="referrer" content="never">
[!tip] 参考 隐藏来源 禁用Referrer 的方法 - 枫若 - 博客园
kill
- #快捷命令 kill快速杀死某个进程
kill -9 `ps aux |grep mirrormaker|awk '{print $2}'`
软件收集
- #推荐软件/linux
- 浏览器插件:
查看程序占用哪几个端口
- #快捷命令 查看程序占用哪几个端口
lsof -i -P | grep ssh
/lib64/libstdc++.so.6: version 'CXXABI_1.3.8‘ not found
- libstdc++库的问题,找到正确的so文件
mkdir -p ~/.local/lib64;cp <right so file> ~/.local/lib64创建文件夹export LD_LIBRARY_PATH=$HOME/lib64:$LD_LIBRARY_PATH设置环境变量,推荐加入~/.bashrc之后source立刻生效
/libc.so.6: version GLIBC_2.34' not found
sudo vi /etc/apt/sources.list- 添加
deb http://th.archive.ubuntu.com/ubuntu jammy main #添加该行到文件 - 运行升级
sudo apt update
sudo apt install libc6
[!tip] 参考 version `GLIBC_2.34‘ not found简单有效解决方法_glibc 2.34 not found-CSDN博客
ras密钥生成
- #快捷命令
ssh-keygen -t rsa生成ras公私钥
Bad owner or permissions on .ssh/config
chmod 600 ~/.ssh/config
ssh远程执行命令
- 使用
ssh <name>@<ip> "要执行的bash命令"
gitbook下载
- 使用工具fuergaosi233/gitbook2pdf: Grab the contents of the gitbook document and convert it to pdf (github.com)
- ps:似乎有的没办法生成,只有旧版的支持
docker部署
推荐使用这种
本地部署
一大堆问题,不推荐
pip install -r requirements.txt && python3 gitbook.py <url>- 错误解决:
fatal error: ffi.h: No such file or directoryERROR: launchpadlib 1.10.13 requires testresources, which is not installed.OSError: dlopen() failed to load a library: cairo / cairo-2 / cairo-gobject-2 / cairo.so.2OSError: cannot load library 'pango-1.0':- 其他的安装依赖包基本上差不多,缺什么就apt 安什么
- 中文pdf乱码的问题
- 中文全部乱码 · Issue #71 · fuergaosi233/gitbook2pdf (github.com)
apt-get install fonts-wqy-zenhei language-pack-zh-hans
- 中文全部乱码 · Issue #71 · fuergaosi233/gitbook2pdf (github.com)
正则表达式
前瞻,后顾,负前瞻,负后顾
// 前瞻:
exp1(?=exp2) exp1后边是exp2就匹配
// 后顾:
(?<=exp2)exp1 exp1前边是exp2就匹配
// 负前瞻:
exp1(?!exp2) exp1后边不是exp2就匹配
// 负后顾:
(?<!exp2)exp1 exp1前边不是exp2就匹配
查找上次内存吃太多的命令
sudo cat /var/log/syslog | grep -i "out of memory"
rust
cargo加速
- 编辑
$HOME/.cargo/config - 修改为
[source.crates-io]
replace-with = 'mirror'
[source.mirror]
registry = "sparse+https://mirrors.tuna.tsinghua.edu.cn/crates.io-index/"
rust-analyzer Fetching metadata
- 运行
rm -rf ~/.cargo/.package-cache
bing Access Denied
- windows 下参考 https://answers.microsoft.com/zh-hans/microsoftedge/forum/all/bing%E4%B8%BB%E9%A1%B5%E6%89%80%E6%9C%89%E6%90%9C/5a7036e7-e5e8-433c-8363-38c42e12d8e7
Snap卸载
apt remove --autoremove snapd- 如何在Ubuntu中完全移除Snap-腾讯云开发者社区-腾讯云
apt出现restart选项
- 编辑
/etc/needrestart/needrestart.conf文件 - 找到下面这行, i 代表交互式重启 a 代表自动重启, l 代表列出,直接改成 l
#$nrconf{restart} = 'i';
日志清理
- 通过下面的命令实现,具体参考Linux /var/log/日志文件太大,清理journal就行_/var/log很大,能删除吗-CSDN博客
journalctl --vacuum-time=2d
journalctl --vacuum-size=500M
快速配置nginx的https证书
certbot
使用的是let's encrypt 和 certbot,目前只支持nginx和apache
- 安装
apt install certbot python3-certbot-nginx
- 使用
certbot --nginx按照提示进行填写 - 运行
crontab -e然后添加0 0 1 * * /usr/bin/certbot renew --quiet,这样每个月第一天都会尝试进行更新
acme.sh
使用的是let's encrypt 和 acme.sh
- 下载
curl https://get.acme.sh | sh,不推荐,因为服务器难连github,推荐方式git clone https://gitee.com/neilpang/acme.sh.git;cd acme.sh;./acme.sh --install -m <自己的邮箱> - 参考创建阿里云AccessKey_访问控制(RAM)-阿里云帮助中心获取阿里云的secret id和key,如果没有用户首先创建用户,然后对用户进行授权,搜索权限dns全部选择
export Ali_Key="xxx" && export Ali_Secret="xxx"设置环境变量,然后设置./acme.sh --issue --dns dns_ali -d example.com -d *.example.com获取证书- 安装证书(证书的默认位置在
/root/.acme.sh/<域名>),更新证书用--renew,pem文件本质是通用的
./acme.sh --installcert -d <domain>.com --key-file /etc/nginx/ssl/<domain>.key --fullchain-file /etc/nginx/ssl/fullchain.cer --reloadcmd "service nginx force-reload"
- 参考
run.sh,
export Ali_Key=""
export Ali_Secret=""
domain=""
mkdir ~/cert
./acme.sh --issue --dns dns_ali -d $domain -d *.$domain
./acme.sh --installcert -d $domain --key-file ~/cert/$domain.key --fullchain-file ~/cert/$domain.cert
- 如果要更新 nginx 之类的, installcert 的时候得加上
--reloadcmd "sudo nginx -s reload", 定时任务得加上, 或者直接半个月重启 nginx(推荐这种)
[!tip] 参考 acme.sh使用阿里云DNS申请Let’s Encrypt的https证书_acme.sh 阿里云-CSDN博客
证书管理
- 非交互式
certbot \
--non-interactive \
--standalone \
--email mymail@provider.com \
--agree-tos \
--no-eff-email \
--domains mydomain.com \
--installer nginx
- 展示证书
certbot certificates - 更新证书
certbot renew - 撤销证书
certbot revoke --cert-name <证书名字>
[!tip] 参考 如何使用 Let's Encrypt 和 Certbot 获取免费的 SSL/TLS 证书 在 Ubuntu 22.04 上使用 Let‘s Encrypt 配置 Nginx SSL 证书_ubuntu let's encrypt-CSDN博客
clash server服务器配置
- 上 Release 1.18 · Kuingsmile/clash-core · GitHub 下载最新的 clash-core(gitee上有这两个文件的压缩包)
- 从 Country.mmdb 下载文件,放到
~/.config/clash/(没有就创建这个文件夹) - 创建
~/.config/clash/config.yml,将自己的clash的配置文件(某个长长profile粘贴进入) - 运行二进制文件,配置终端代理如下,参考Clash 终端代理
export http_proxy=http://127.0.0.1:7890
export https_proxy=http://127.0.0.1:7890
export all_proxy=socks5://127.0.0.1:7890
PhantomJS部署
无头浏览器截图神器, 用于直接保存网络快照
- 下载二进制文件下载 | PhantomJS或者 gitee
- 注意以下,运行二进制之前需要添加
export OPENSSL_CONF=/dev/null - 网页截图参考下面js,将js文件作为参数传入二进制就可以了
var page = require('webpage').create();
page.open('https://www.gov.cn/', function() {
page.render('result.png');
phantom.exit();
});
- 总结shell脚本
#!/bin/bash
export OPENSSL_CONF=/dev/null
# read url from first argument,if not set ,exit and print usage
# read result name from second argument,if not set,use result.png
if [ -z $1 ]; then
echo -e "Usage: $0 <url> <result_name>\n\turl: the url to capture\n\tresult_name: the name of the result file\n
Snapshot the website from url and save it as a png file\n"
exit 1
fi
if [ -z $2 ]; then
result_name="result.png"
else
result_name=$2
fi
url=$1
tmp_file=`mktemp`
echo -e "var page = require('webpage').create();page.open('$url', function() { page.render('$result_name'); phantom.exit(); });" > $tmp_file
~/file/app/others/phantomjs-2.1.1-linux-x86_64/bin/phantomjs $tmp_file
Obs
扩展屏录制
- 来源那里双击屏幕捕捉,设置就可以了
画质设置
- 文件 -> 设置 -> 视频 -> 输出分辨率
KeeWeb
手机端推荐使用keepass2android
webdev同步指南
- 坚果云获取帐号密码, more -> webdev
- 设置 -> 存储 -> 点击始终重新加载文件,保存方式为 以PUT方式覆盖文件
- 主界面输入信息
- 然后回到主界面是让你输密码的,而不知报错返回的
- 调整为中文(通过插件那里下载plugin)
markdown
- github 插入视频的方法为
<video src="" controls="controls" width="500" height="300"></video>记得前面后面空一行,参考 使用Markdown语言在博客的文章中添加视频 · GitHub
输入法
- linux 下 sunpinyin是最好用的,以及需要使用fictx框架进行安装
chrome
安装
sudo apt install chromium-browser直接安装
清除单个网页缓存
- F12 -> application -> 存储 -> 清除网站数据

黑暗模式
- 参考 zhuanlan.zhihu.com/p/494984745
- 打开
chrome://flags/然后搜索darkmode就可以了
存储限制
- 需要将“关闭所有窗口时清除 Cookie 及网站数据”开关关闭
[!tip] 参考 chrome浏览器存储空间只有300MB左右的解决方法
插件推荐
- floccus
- floccus bookmarks sync - Chrome 应用商店
- 书签同步插件, 必备
- doubao
- 豆包,浏览器 AI 助手 - Chrome 应用商店
- 不是最聪明的, 但是是功能最多的最简单的
- save-working-session
- Save Working Session - Chrome 应用商店
- 用来临时保留会话, 后续重新打开的
- markdownload
- MarkDownload - Markdown Web Clipper - Chrome 应用商店
- 网页直接转 markdown的, 剪藏必备, 不过看起来很久没更新了, 有个替代的
- chromium-web-store
- Release 1.5.4.3 · NeverDecaf/chromium-web-store · GitHub
- 如果用的是 ungoogled-chromium, 用来打开插件商城的
- Replace Google CDN
- Replace Google CDN - Chrome 应用商店
- 修改 google cdn 的, 避免网页一直卡着加载
- 腾讯翻译
- 腾讯翻译 - Chrome 应用商店
- 不咋用了, 都是 doubao 直接上的
- Ruffle - Flash Emulator
- Ruffle - Flash Emulator - Chrome 应用商店
- 解决 flash 不可用问题的, 都是回忆
- User-Agent Switcher and Manager
- User-Agent Switcher and Manager - Chrome 应用商店
- 用于切换浏览器 agent 的, 有时候有用
- Automa
- Automa - Chrome 应用商店
- 流程化自动化浏览器操作的, 有时候非常有用
服务器问题
no route to host 无法连接
- 防火墙的问题
sudo systemctl stop firewalld.service关闭就可以了
github
github 真的是太好用了. 真的是赛博活佛, 不得不说这玩意比gitee那种纯垃圾好用多了
在线编辑器
- 在 仓库 界面 按下
.自动打开类似vscode的界面, 在线编辑更改小细节更加简单
codespace
- 更加炸裂的功能, 基本上就是云上开发机器, 对某个仓库
Code->CodeSpace打开, 直接一分钟初始化一个环境出来, 可以直接运行并下载文件, 可以绑定端口进行转发- 意味着未提供可执行文件的仓库完全可以在codespace直接编译, 完全不需要在本地仓库进行编译(特别是前端的项目)
- 以后如果要改造github项目直接fork然后创建space的了,不需要弄麻烦的本地编译环境了
- 免费额度是15 GB/月存储 120 每月核心小时数
- 修改 codespace规格在 Sign in to GitHub · GitHub
[!tip] 参考 GitHub Codespaces 快速入门 - GitHub 文档 关于 GitHub Codespaces 的计费 - GitHub 文档
CICD
最新的 release链接
- 类似
https://github.com/<username>/<reponame>/releases/latest/download/<assetname>
excalidraw
支持latex 和中文 搭建
- 仓库链接 GitHub - chenxuan520/excalidraw: excalidraw 中文支持latex 公式版 可以直接通过这个链接下载release成品
- latex:
- 通过原仓库的 GitHub - excalidraw/excalidraw at danieljgeiger-mathjax 分支部署实现
- 中文:
- 参考 使用excalidraw搭建自己的中文手写画板_excalidraw教程-CSDN博客 中的方式, 如果shabicsdn变成vip了可以直接参考 result.png
- 或者直接参考 feat:add chinese fonts · chenxuan520/excalidraw@ad4a3bf · GitHub 这个提交的改动
- 需要注意的是, 如果要 修改 icon 上 Remix Icon - Open source icon library 选择喜欢的icon, 选择copy svg , 将 path 里面的部分copy 放到icon的path中 参考 feat: add icon · chenxuan520/excalidraw@49f4729 · GitHub
- 修改这种仓库的代码最好的方式是使用 codespace
[!tip] 相关网站 Excalidraw | Hand-drawn look & feel • Collaborative • Secure Remix Icon - Open source icon library
卸载 deb包
apt list --installed | grep -i chrome查询, 然后apt remove卸载掉
[!tip] 参考 zhuanlan.zhihu.com/p/548692652
ping: Temporary failure in name resolution
- dns 解析的问题, 在
/etc/resolv.conf最后加上nameserver 8.8.8.8即可
[!info] 可选DNS服务器 1、百度公共DNS服务IP:180.76.76.76 2、阿里云DNS,223.6.6.6 还有一个223.5.5.5这一个PING值50多 3、腾讯DNS:119.29.29.29 4、 电信:首选:101.226.4.6 5.联通:首选:123.125.81.6 6.移动:首选:101.226.4.6 7.铁通:首选:101.226.4.6 8.114 DNS 114.114.114.114
查询进程的父进程
通常用于某个傻逼进程开了守护进程, 杀了自动重启的问题
ps -ef第三列就是父进程pid, 第二列是本身的pid
cloudflare
- 真正的赛博活佛, 我绝不吝啬使用最好的语言去夸赞这家公司, 或者说国内互联网公司能做到他的十分之一的都没有, 真正的大善人
- worker 相当于海外服务器免费使用, 只要个域名什么都准备好了, 有点太好了, 绝对是最好的项目, 相当于 faas 云函数, 而且是免费的
- 我部署了类似 news, aichat , libretv 这种项目
- SSL 全部给你上完了, 直接一步到位, 不用申请乱七八糟的 ssl证书
- KV 存储非常好用, 相当于数据库的存储了
- R2存储这块用处不大, 慢并且超额还有账单, 不推荐绑卡, 避免某天账单就寄过来 , free 超了最多是不可用, 毕竟不是核心业务,无所谓
- worker 相当于海外服务器免费使用, 只要个域名什么都准备好了, 有点太好了, 绝对是最好的项目, 相当于 faas 云函数, 而且是免费的
- 服务器= worker , 数据库= kv , ai 功能内置且免费额度非常高 ,SSL 自己提供, ,自带高防, 免费上人机验证 ,域名可以在spaceship 购买 45/10年的 xyz, 真的要什么自行车
重定向域名
- 域名 -> 规则 -> 重定向规则 -> 解析配置成 192.0.2.1
部署 lockfile would have been modified by this install
- 环境变量设置
YARN_ENABLE_IMMUTABLE_INSTALLS为 false 就行
clawmail 配置
- userid 是 邮箱, 安装最后一步可以选位置, 错过只能删除
~/.claws-mail重新配置 - qq 邮箱选择 imtp, 别选pop3 , imap.qq.com 和 smtp.qq.com, 密码得生成
- 重要的一点是
- ssl 这个地方都得从默认改成使用 ssl, 不然无法使用
加密匿名邮箱
- Tutanota 推荐这个, 无需任何信息即可注册账号, 匿名性非常强 Tuta:免费开启电子邮件、日历和联系人隐私保护功能 | Tuta
webdav 搭建
- 使用 webdav: A simple and standalone WebDAV server
- 在nginx 内部配置内容为
location / {
proxy_pass http://127.0.0.1:8080;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header REMOTE-HOST $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $host;
proxy_redirect off;
client_max_body_size 200m; # enable large file upload
# Ensure COPY and MOVE commands work. Change https://example.com to the
# correct address where the WebDAV server will be deployed at.
set $dest $http_destination;
if ($http_destination ~ "^https://example.com(?<path>(.+))") {
set $dest /$path;
}
proxy_set_header Destination $dest;
}
AI cli
- GitHub - QwenLM/qwen-code: Qwen Code is a coding agent that lives in the digital world.
- iflow 快速开始 | 心流开放平台
- GitHub - ConardLi/easy-llm-cli: An open-source AI agent that is compatible with multiple LLM models
- nslookup github.com
快捷查询dns服务器
- ping github.com
网络连接尝试
- host -v xxx.com
域名详细信息查询
- dig github.com
详细域名信息查询
- 网络链路检测 #快捷命令
mtr ip 或者 traceroute 域名 (mac上mtr需要sudo)
- ssh连接检测 #快捷命令
ssh -T -v git@github.com 要是DNS 被污染了可以编辑 /etc/resolv.conf(临时的) 或者 /etc/systemd/resolved.conf(永久的) 改成 8.8.8.8 和 114.114.114.114 Ubuntu修改DNS方法(临时和永久修改DNS) - 安全兔 - 博客园
虚拟内存
- (https://www.cnblogs.com/tocy/p/linux-swap-cmd-summary.html),(https://www.cnblogs.com/akuo-123/p/8036268.html)
wget
- 打包下载命令
wget -r -p -np -k https://www.lunarvim.org/ #快捷命令 -R 可以指定不下载的类似,比如-R pdf -A 可以指定只接受的类型
[!tip] 参考 https://zhuanlan.zhihu.com/p/380793959
dpkg
- 无root权限安装deb包
- 新建一个目录
dpkg -x example.deb example#快捷命令
- 有root权限
sudo dpkg -i example.deb
添加用户
useradd --shell /bin/bash -p qwer1234 -d /home/chaiquan chaiquan#快捷命令
查看系统架构
uname -a,基本上inter,amd都是x64架构,可以直接使用amd64或者x64
telnet
用法
telnet ip/域名 端口,就是TCP连接到该端口,此时可以直接在命令行输入发送的内容,回车直接以tcp包发送,响应再按回车后直接输出在控制台- 这个命令只会建立简单的TCP连接,即使是443端口,也不会自动建立https连接
realpath
- 查看文件的真实路径
service和systemd
- Linux系统下的/etc/init.d。/etc/init.d 目录下的脚本文件用于管理服务,这些脚本文件位于 /etc/init.d 目录下,并以服务的名称命名。service命令本质就是通过去
/etc/init.d目录下执行相关程序实现,实际上service类似一个脚本,找init.d目录下的文件执行 - init 是一个守护进程,它持续运行,直到系统关闭。它是所有其他进程的直接或间接的父进程。
- 启动时间长。init 进程是串行启动,只有前一个进程启动完,才会启动下一个进程。
- 启动脚本复杂。init进程只是执行启动脚本,不管其他事情。脚本需要自己处理各种情况,这往往使得脚本变得很长。
service nginx start
- systemctl 是一个新的系统服务管理工具,它是 systemd 系统和服务管理器的一部分。systemd 是一个用于 Linux 启动进程的系统和服务管理器。相比之下,systemctl 拥有更加全面的功能,可以用于控制服务的状态,查看服务的状态,重启和重新加载服务,并在服务失败时自动重启服务
- Systemd 这个名字的含义,就是它要守护整个系统。使用了 Systemd,就不需要再用 init 了。Systemd 取代了initd(initd 的PID 是0) ,成为系统的第一个进程(Systemd 的PID 是1),其他进程都是它的子进程。
systemctl start nginx
jq命令
- 用于命令行解析json数据,结果可以通过".key.arr[0].subkey"获取
echo '{"Name":"CloudNativeOps","Owner":"GoOps","WebSite":"https://bgbiao.top/"}' | jq .Name
ln命令
ln -s source_file(已经存在的文件) soft_link_name(需要创建的链接)
time命令
time ls用于很方便计算命令耗时
rsync
- 同步文件命令,但是支持断点续传(scp不支持)
date
- 获取当前时间 可以通过
date +"%Y%m%d%H%M%S"调整格式,参考shell编程-date命令详解(超详细)_shell date-CSDN博客
curl
config demo
# demo config for curl
# more infomation,read https://catonmat.net/cookbooks/curl
# and https://www.ruanyifeng.com/blog/2019/09/curl-reference.html
# update by chenxuan 2023-01-08 22:44:17
# use it by: curl -K ./demo.curl
# INPUT
# url :request url
url="chenxuanweb.top"
# request -X: curl method(GET,POST,PUT etc)
request="GET"
# user-agent -A:sign for firefox
# can be change in -H option
# user-agent="User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0"
# cookie -b:cookie gor request
# cookie-jar -c:save cookie infile
# cookie="foo1=bar;foo2=bar2"
# cookie=cookie.txt
# cookie-jar=cookie.txt
# head of request -H
header="Content-type: application/json"
header="Accept: text/html,application/xhtml+xml,application/xml;"
header="Connection: keep-alive"
# header="Authorization: test"
# referer -e:referer
# can be change in -H option
# referer="https://google.com?q=example"
# user -u:user pwd and name,make it to Authorization(Basic model)
# user="bob:12345"
# get -G:get request query
# if exist,-d standfor query(https://google.com/search?q=kitties&count=20)
# get
# body for post -d
# data-binary <data> HTTP POST binary data
# data-raw <data> HTTP POST data, '@' allowed
# data-urlencode <data> HTTP POST data url encoded, make <space>encode
# recommand use file to send body,such as json file
# data = @req.json
data='login=emma&password=123'
# upload file -F
# form="file=@photo.png;type=image/png;filename=me.png"
# options
# proxy -x [protocol://]host[:port] Use this proxy(default http)
# proxy="socks5://james:cats@myproxy.com:8080"
# insecure -k:if exist,donnot check https
insecure
# location -L:if exist,follow website redirects
location
# verbose -v:visual model,for debug
# open it can see request
# trace :save msg for debug
# verbose
# trace="a.txt"
# show-error/silent -S/-s: show error/silent
# show-error
# silent
# output
# include -i:if exist,print res header
include
# outputfile -o:make result into file(like wget)
# if open it,close include is better
# output="a.txt"
# vim: ft=cfg et ts=2 sts=2 sw=2
crontab
- 定时任务执行工具
- 使用
select-editor进行更改默认的编辑器
f1 f2 f3 f4 f5 program
- 其中 f1 是表示分钟,f2 表示小时,f3 表示一个月份中的第几日,f4 表示月份,f5 表示一个星期中的第几天。program 表示要执行的程序。
- 当 f1 为 * 时表示每分钟都要执行 program,f2 为 * 时表示每小时都要执行程序,其馀类推
- 当 f1 为 a-b 时表示从第 a 分钟到第 b 分钟这段时间内要执行,f2 为 a-b 时表示从第 a 到第 b 小时都要执行,其馀类推
- 当 f1 为 */n 时表示每 n 分钟个时间间隔执行一次,f2 为 */n 表示每 n 小时个时间间隔执行一次,其馀类推
- 当 f1 为 a, b, c,... 时表示第 a, b, c,... 分钟要执行,f2 为 a, b, c,... 时表示第 a, b, c...个小时要执行,其馀类推
* * * * *
- - - - -
| | | | |
| | | | +----- 星期中星期几 (0 - 6) (星期天 为0)
| | | +---------- 月份 (1 - 12)
| | +--------------- 一个月中的第几天 (1 - 31)
| +-------------------- 小时 (0 - 23)
+------------------------- 分钟 (0 - 59)
0 0 1 * * 每个月的第一天午夜(0 点)执行一次
0 0 * * 0 每周日的午夜(0 点)执行一次
tar
- 一定要去到目录下tar打包,不然会带着路径信息,或者用-C也行
tar -zcvf ~/vim-fast/vim.tar.gz -C ~/.vim/plugged ./*
tmux
核心
- 所有tmux按键以ctrl+b为基础
- d 退出当前会话
- " 上下分屏
- % 左右分屏
- 上下左右 转到窗口
- c-b :set -g mouse on 设置鼠标支持
~/.tmux.conf默认的配置文件位置
命令行
下面的命令行直接通过 tmux+指令实现
- attach 连接会话
开启TrueColor设置
- 关联Vim技巧的TrueColor设置
- 通过
echo $TERM查找终端类型 - 编辑
~/.tmux.conf添加
set -g default-terminal "xterm-256color"
#set -g default-terminal "screen-256color" # 如果使用screen-256color则用这条指令
set-option -ga terminal-overrides ",*256col*:Tc"
- 重启tmux
[!tip] 参考 Vim在tmux中颜色改变/不同的问题
三剑客
grep
- `-C` 后面跟一个数字,表示在匹配行的前后都显示这么多行。如果希望显示所有行,可以使用一个足够大的数字
sed
awk
- awk默认分割符是空格,可以通过
-F自动分隔符-F ':', - 格式:
awk [-F field-separator] 'commands' input-file#快捷命令 - commands中的内容才是真正的awk,通常使用
'{print $1}' - awk使用的是列处理,sed是行处理的
[!tip] 参考 https://www.cnblogs.com/along21/p/10366886.html
[!quote] mac感想 刚开始觉得mac非常好用, 到后来mac天天内部卡死才发现 如果我愿意花这么贵的钱买普通笔记本然后装linux系统, 他比mac稳定好用一万倍 苹果生产的无论是 apple 还是 mac 都是贵但是用处不大的垃圾
好用软件
#推荐软件/mac
lemon cleaner
- 清理空间的, 虽然是腾讯的但是开源挺好用的
inputsourcepro
- 自动根据场景应用切换输入法
- 更新:非常垃圾,不建议使用
keyboardholder
- 比上面那个垃圾好用
- KeyboardHolder
ohmyzsh
sh -c "$(curl -fsSL https://raw.github.com/robbyrussell/oh-my-zsh/master/tools/install.sh)"
- 或者
sh -c "$(curl -fsSL https://gitee.com/mirrors/oh-my-zsh/raw/master/tools/install.sh)"
item2
- mac上的好用终端
- 右键劫持可以通过设置解决 setting -> pointer -> binging
- 左键 command 劫持也是一样的地方
- 左键聚焦可以通过 General / Selection uncheck the option "Clicking on a command selects it to restrict Find and Filter" 关闭这个选项就可以了
- vim上本体乱码运行下面,或者添加到环境变量
export LC_ALL=en_US.UTF-8
export LANG=en_US.UTF-8
homebrew
- 包管理工具,必装不解释
按键映射鼠标滚轮 Karabiner-Elements
- Karabiner-Elements
- github链接
- Install Karabiner-Elements from their official website.
- Open Karabiner-Elements and go to the "Simple Modifications" tab.
- Click on the "+" button to add a new modification.
- From the "From key" dropdown menu, select "fn" key.
- From the "To key" dropdown menu, select "left_control" key.
- Enable the modification by checking the checkbox next to it.
- Save the changes and the fn key will now work as the ctrl key.
- 滚轮的设计(不要安装 Reverse Scroll 会让mac变得非常卡)
- device -> modify event -> Flip mouse vertical wheel
beekeeper studio
- mysql控制工具
zsh 插件
- oh-my-zsh 只带插件 z 插件 在终端跳快速跳转到指定目录的oh-my-zsh插件:z与wd | 凡·间
- 高亮插件 GitHub - zsh-users/zsh-syntax-highlighting: Fish shell like syntax highlighting for Zsh.
- 自动补全插件 GitHub - zsh-users/zsh-autosuggestions: Fish-like autosuggestions for zsh
输入法卡死
- 'cursoruiviewservice' Not Responding and … - Apple Community 傻逼mac, 一大堆的bug, 稳定性堪忧, 只能重启
清除mac信息
- 删除所有钥匙串 打开钥匙串应用全删了
- 参考https://www.zhihu.com/question/25497798
mac按键映射
- Karabiner-Elements
- 将mac的傻逼的fn映射成为ctrl
- github链接
- Install Karabiner-Elements from their official website.
- Open Karabiner-Elements and go to the "Simple Modifications" tab.
- Click on the "+" button to add a new modification.
- From the "From key" dropdown menu, select "fn" key.
- From the "To key" dropdown menu, select "left_control" key.
- Enable the modification by checking the checkbox next to it.
- Save the changes and the fn key will now work as the ctrl key.
.DB_store
- 目的在于存贮目录的自定义属性,例如文件的图标位置或者是背景色的选择等等。
# 禁止生成,重启mac
defaults write com.apple.desktopservices DSDontWriteNetworkStores -bool TRUE
# 重新生成
defaults delete com.apple.desktopservices DSDontWriteNetworkStores
mac关闭chrome左滑返回
- 参考mac 关闭chrome浏览器双指返回手势,触控板双指前进后退手势设置-腾讯云开发者社区-腾讯云
- 核心就是关闭下面的内容

mac安装ctags
- 运行
brew install universal-ctags不是直接ctags
mac 安装 gnu系列
brew install coreutils以及brew install gnu-sed
[!tip] 参考 macos - How to have GNU's date in OS X? - Ask Different
Mac pip3 error: externally-managed-environment
鼠标滚轮翻转
- 使用Scroll Reverser for macOS 这个软件
mac设置go版本
mac 关闭右下角打开便签的功能
- 设置搜索
触发角关闭
煞笔 CursorUIViewService
- 使用
sudo defaults write /Library/Preferences/FeatureFlags/Domain/UIKit.plist redesigned_text_cursor -dict-add Enabled -bool NO - 或者使用
sudo mkdir -p /Library/Preferences/FeatureFlags/Domain && sudo /usr/libexec/PlistBuddy -c "Add 'redesigned_text_cursor:Enabled' bool false" /Library/Preferences/FeatureFlags/Domain/UIKit.plist
- 卡顿的时候, 不要用输入法, 点开活动监视器, 找到简体中文输入法, 结束进程, 就可以恢复正常
- windows用的很少,真难用
excel公式
在Excel中,你可以使用各种函数和公式进行计算。以下是一些常见的Excel计算公式的例子:
- 基本数学运算符:
- 加法:
+,例如=A1+B1 - 减法:
-,例如=A1-B1 - 乘法:
*,例如=A1*B1 - 除法:
/,例如=A1/B1
- 加法:
- SUM 函数(求和):
- 用于将一列或一行数字相加。
- 例如,
=SUM(A1:A10)将对A1到A10单元格范围内的数字求和。
- AVERAGE 函数(平均值):
- 用于计算一组数字的平均值。
- 例如,
=AVERAGE(B1:B10)将计算B1到B10范围内数字的平均值。
- IF 函数(条件语句):
- 用于根据条件执行不同的操作。
- 例如,
=IF(A1>10, "大于10", "小于等于10")将根据A1的值返回不同的结果。
- VLOOKUP 函数(垂直查找):
- 用于在数据表中查找某个值并返回该值所在行的相关信息。
- 例如,
=VLOOKUP(A1, D1:E10, 2, FALSE)将在D1到E10范围内查找A1的值,并返回找到的值所在行的第二列的内容。
- COUNT 函数(计数):
- 用于计算指定范围内的数字个数。
- 例如,
=COUNT(A1:A10)将计算A1到A10范围内的数字个数。
- CONCATENATE 函数(连接文本):
- 用于将两个或多个文本字符串连接在一起。
- 例如,
=CONCATENATE(A1, " ", B1)将连接A1单元格和B1单元格中的文本,中间以空格分隔。
wsl问题
wsl2ip获取
- wsl2和windows属于同级系统,相当于虚拟机了,已经不是wsl1类型的子系统(wsl1可以直接连接端口),host连接wsl2使用
wsl -- ifconfig eth0的命令得到的ip地址,wsl2是完整的内核,wsl1并不是,因此wsl1是子系统,和windows使用相同的端口和网卡,但是wsl2使用非windows的网卡 - 或者在wsl2中使用
ip a |grep "global eth0"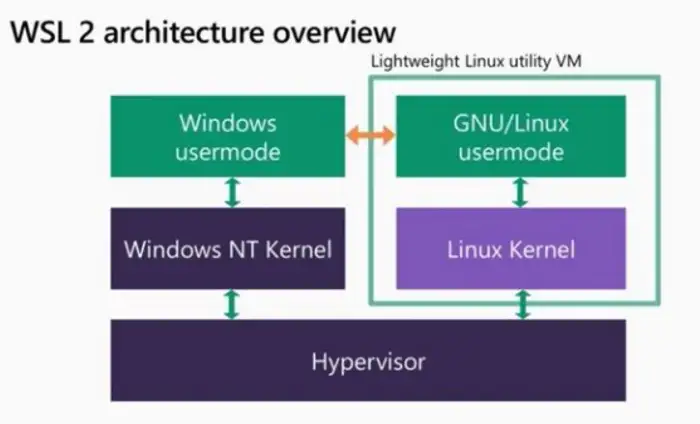
wsl和nvim粘贴板设置
- 在配置文件加上,之后y默认就是系统的粘贴板
augroup Yank
autocmd!
autocmd TextYankPost * if v:event.operator ==# 'y' | call system('/mnt/c/Windows/System32/clip.exe', @0) | endif
augroup END
- 或者运行下面命令并且在 init.vim中添加
set clipboard=unnamedplus
curl -sLo/tmp/win32yank.zip https://github.com/equalsraf/win32yank/releases/download/v0.0.4/win32yank-x64.zip
unzip -p /tmp/win32yank.zip win32yank.exe > /tmp/win32yank.exe
chmod +x /tmp/win32yank.exe
sudo mv /tmp/win32yank.exe /usr/local/bin/
Input/output error
- 重启wsl
wsl --shutdown
wsl
有用软件
- 按键映射:GitHub - microsoft/PowerToys: Windows system utilities to maximize productivity #推荐软件/win
- windows terminal
window git crlf lf 换行符问题
// 提交时转换为LF,检出时转换为CRLF
git config --global core.autocrlf true
// 提交时转换为LF,检出时不转换
git config --global core.autocrlf input
// 提交检出均不转换
git config --global core.autocrlf false
// 拒绝提交包含混合换行符的文件
git config --global core.safecrlf true
// 允许提交包含混合换行符的文件
git config --global core.safecrlf false
// 提交包含混合换行符的文件时给出警告
git config --global core.safecrlf warn
参考
- https://www.cnblogs.com/hushaojun/p/16001784.html
idea
问题
idea重启报一大堆错
- 清除缓存
任务栏天天卡死
- 那纯粹是任务栏的傻逼资讯导致的,参考Win10任务栏卡死,无响应,点不动解决方法 - 知乎 (zhihu.com)删除
windows他妈的总是加一个毛用没有的垃圾功能能拖卡电脑,无论是defender还是更新还是资讯,最近加的功能毫无用处,微软一帮废物
windows Terminal
- 左右分屏:Alt+Shift+=
- 上下分屏:Alt+Shift+-
wps强制登录问题
表现为如果不登录,编辑功能都无法使用
- 卸载wps重装,或者修改注册表,参考如何看待WPS不登陆就无法编辑的情况? - 知乎 (zhihu.com)
浏览器bing重定向问题
- 关了浏览器重开
- 清除bing的cookie
- 傻逼edge,用Firefox
所有方案
UUID
通常不用来作为分布式id,更多作为临时幂等串
- UUID的生成算法基于时间戳、节点ID和随机数等多个因素,能够在分布式系统中保证消息id的唯一性,是一个字符串
优点
- 唯一性比较好,生成无需联网,本地就可以生成,全球唯一(绝大概率)
缺点
- 是一个字符串而不是int导致查询索引都非常慢
- 不能保证递增性,没什么业务相关含义
Snowflake
通常用于只需要保证唯一性不需要绝对递增性的场景(如订单id)
- 大名鼎鼎的facebook雪花id生成算法,生成方法如下
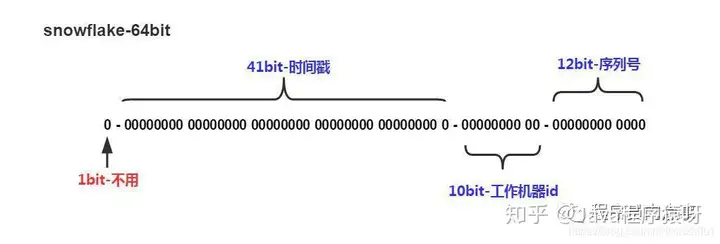
优点
- int64类型,检索更加快速
- 生成快,通过拼接生成
- 蕴含这时间戳和机器id,通过这个快速定位机器和时间
缺点
- 无法保证绝对的递增性(趋势递增还是有的,因为时间戳)和连续性
- 时钟回拨可能导致出现重复id的问题
- 解决时钟回拨的问题可以参考,实际上还是通过定时上报时间(比如3s),本地关闭NTP时间同步,然后新上线检查自己的时间和之前上报的时间差距

- 解决时钟回拨的问题可以参考,实际上还是通过定时上报时间(比如3s),本地关闭NTP时间同步,然后新上线检查自己的时间和之前上报的时间差距
这里的时钟回拨是因为本地的时间可能出现漂移但是机器上的时间校准协议自动校准导致出现时间回拨
百度UidGenerator

- delta seconds (28 bits) 这个值是指当前时间与epoch时间的时间差,且单位为秒
- worker id (22 bits) 生成worker id,需要创建一张表,机器启动之后先数据库中的表插入一条数据,获得一个自增id . 所有实例重启次数是不允许超过4194303次(即2^22-1),否则会抛出异常
- sequence (13 bits) 每秒下的并发序列,13 bits可支持每秒8192个并发
DefaultUidGenerator
流程
- 如果时间有任何的回拨,那么直接抛出异常;
- 如果当前时间和上一次是同一秒时间,那么sequence自增。如果同一秒内自增值超过2^13-1,那么就会自旋等待下一秒 (其实这个部分普通的雪花算法也可以用,但是普通雪花用这个也解决不了快速重启重复id的问题)
- 如果是新的一秒,那么sequence重新从0开始;
- 简单粗暴直接通过获取当前时间比较避免始终回拨
[!question] 缺点 性能不够好,拒绝采样次数可能很多
CachedUidGenerator
这个和上面是两种generator
- RingBuffer Of Flag 标识位,表示目前UID数组的状态
- 其中,保存flag这个RingBuffer的每个slot的值都是0或者1,0是CANPUTFLAG的标志位,1是CANTAKEFLAG的标识位。每个slot的状态要么是CANPUT,要么是CANTAKE。以某个slot的值为例,初始值为0,即CANPUT。接下来会初始化填满这个RingBuffer,这时候这个slot的值就是1,即CANTAKE。等获取分布式ID时取到这个slot的值后,这个slot的值又变为0,以此类推。
- 保存唯一ID的RingBuffer有两个指针,Tail指针和Cursor指针。
- Tail指针表示最后一个生成的唯一ID。如果这个指针追上了Cursor指针,意味着RingBuffer已经满了。这时候,不允许再继续生成ID了。
- Cursor指针表示最后一个已经给消费的唯一ID。如果Cursor指针追上了Tail指针,意味着RingBuffer已经空了。这时候,不允许再继续获取ID了。
- RingBuffer Of UID 保存生成的id
流程
- 根据每秒的大小生成两个buffer
- 构造RingBuffer,默认paddingFactor为50。这个值的意思是当RingBuffer中剩余可用ID数量少于50%的时候,就会触发一个异步线程往RingBuffer中填充新的唯一ID,这个线程中会有一个标志位running控制并发问题),直到填满为止
- 初始化填满RingBuffer中所有slot
- 开启buffer补丁线程,每次触发填充的时候都自动添加1s然后生成一堆id慢慢填进去,填满为止
// fill the rest slots until to catch the cursor
boolean isFullRingBuffer = false;
while (!isFullRingBuffer) {
//获取生成的id,放到RingBuffer中。
List<Long> uidList = uidProvider.provide(lastSecond.incrementAndGet());
for (Long uid : uidList) {
isFullRingBuffer = !ringBuffer.put(uid);
if (isFullRingBuffer) {
break;
}
}
}
关键点
- 解决时钟回拨的关键: 在满足填充新的唯一ID条件时,通过时间值递增得到新的时间值(lastSecond.incrementAndGet()),而不是System.currentTimeMillis()这种方式,而lastSecond是AtomicLong类型,所以能保证线程安全问题。在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制; 采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费,最终单机QPS可达600万。
- 自增列:UidGenerator的workerId在实例每次重启时初始化,且就是数据库的自增ID,从而完美的实现每个实例获取到的workerId不会有任何冲突。
- RingBuffer:UidGenerator不再在每次取ID时都实时计算分布式ID,而是利用RingBuffer数据结构预先生成若干个分布式ID并保存。
- 时间递增:传统的雪花算法实现都是通过System.currentTimeMillis()来获取时间并与上一次时间进行比较,这样的实现严重依赖服务器的时间。而UidGenerator的时间类型是AtomicLong,且通过incrementAndGet()方法获取下一次的时间,从而脱离了对服务器时间的依赖,也就不会有时钟回拨的问题
[!question] 缺点 因为是使用自己的时间因此很可能导致其中的时间含义并不准确(不是系统时间),但是这部分可以使用隔一段时间进行系统时间校验解决,中期也不会重复id,因为work id不同
MongoDB
- objectId的前4个字节时间戳,记录了文档创建的时间;接下来3个字节代表了所在主机的唯一标识符,确定了不同主机间产生不同的objectId;后2个字节的进程id,决定了在同一台机器下,不同mongodb进程产生不同的objectId;最后通过3个字节的自增计数器,确保同一秒内产生objectId的唯一性

优点
- 唯一性比较好,生成无需联网,本地就可以生成,全球唯一(绝大概率)
缺点
- 是一个字符串而不是int导致查询索引都非常慢
- 不能保证递增性,没什么业务相关含义
Mysql
- 直接用插入的id作为只增id
优点
- 简单,保证递增性,唯一性,连续性
缺点
- 数据库压力大,如果不需要存储的数据浪费存储空间
- 插入数据库还是很慢的过程
Redis
- 通过一个key的incr加lua生成id
优点
- 快,无需数据库io操作,递增性,连续性
缺点
- 当redis宕机,无论是RDB还是AOF都会出现不是最新的id,导致无法判断最新的id发到什么地方了,无法保证绝对唯一性
- 一致AOF插入incr,redis回复时间过长
Leaf
-
通过提前拿号段的形式,就算宕机只会导致不连续,而不会重复
gennerator
- 分布式ID生成器
- 通过提前拿号和异步检查分配的办法(每次分配之后查一下是否已经分配超过60%,如果超过了,异步开协程那下一个号段)解决mysql速度不够快的问题
- 号码一定递增,但是不一定连续(因为如果宕机,下次回复只能拿到下一个号段,无法确定上一个号段是否发完了)
- 通过负载均衡,使得同一个号码的拿取服务全都打到同一台机器上,避免了出现因为多个号段同时发号导致号码不递增的问题
- 通过一致性hash实现自动容灾和恢复,类似[[redis实现#一致性hash算法(一致性哈希)]]
- 构建主机数组,使用二分搜索搜索key对应处理的主机端口ip
- 当处理的机器更改时候(添加或者删除),向旧的机器发送删除内存对应号段的通知(这里需要确保加入的都是新启动的,内存没有号段的,这个特性依赖微服务框架的隔离机制),这里的删除不是新的机器删除,而是框架中自带的client调用端发rpc请求删除
- rpc请求拿到所有的发号机器的ip和port,一致性hash算出自己访问哪一台机器
- 检查是否和上一次请求的机器相同,如果不相同,向上一台机器发送删除的通知,如果因为下线,连接失败没关系,如果在线,会删除缓存中的号段
- 向请求的机器发送rpc请求申请发号
- hash环的计算全部都在client中,和服务端无关
- 使用的是类似锁的机制(实际上使用的是sync.map)
//从本地缓冲池获取已经设置的Segment Getter,并且调用获取设置的segment执行 //检查是否能够生产ids, 无法生成则回源获取segment if cachedSegmentFn, ok := pool.segments.Load(key); ok { segment := (cachedSegmentFn.(SegmentIDCacheGetter))() if segment == nil { logger.Errorf("Generator segment not found:%s[3]", key) return nil } var isAccord bool nextIDs, isAccord = nextIDFn(segment, 0) //满足条件1 if isAccord { return nextIDs } applyed = int64(len(nextIDs)) //重置key对应的segment fn, 否则sync.Map的LoadOrStore无法正确执行 pool.segments.Delete(key) } //multi-goroutine情况下并发获取的都是waitGetter,仅当唯一获取了segmentFn的Goroutine完成初始化后返回 var startTime = time.Now() var initSegment *entity.NamespaceSegment var wg sync.WaitGroup wg.Add(1) waitGetter := func() *entity.NamespaceSegment { wg.Wait() return initSegment } //only one goroutine to call fn() //大量协程尝试写入这个sync.map segmentGetter, loaded := pool.segments.LoadOrStore(key, SegmentIDCacheGetter(waitGetter)) if loaded { //因为多个协程竞争导致,大部分协程到这个地方,然后进行等待,**注意,这里等待的并不是自己的wg,因为自己的wg压根没有成功存进去,等待的是成功存进去的wg,即拿到执行权限的wg** //block here wait first getter done segment := (segmentGetter.(SegmentIDCacheGetter))() if segment == nil { return nil } nNextIDs, isAccord := nextIDFn(segment, applyed) if !isAccord { return nil } return append(nextIDs, nNextIDs...) } //成功写入的协程到这部分 //Store成功,初始化Request initSegment = segmentFn() wrapGetter := func() *entity.NamespaceSegment { return initSegment } pool.segments.Store(key, SegmentIDCacheGetter(wrapGetter)) //完成wg,通知其他协程起来 wg.Done() //////////////////////////////////////////////// // 这部分是nextIDFn的内容,底层还是使用atomic实现的 func(segment *entity.NamespaceSegment, applyedN int64) ([]int64, bool) { var apply = n - applyedN //有效的ID列表, 超出保留的ID列表 var validIDs []int64 var counter *int64 if iCounter, ok := globalCounter.Load(key); !ok { return nil, false } else { counter = iCounter.(*int64) } // 注意这里是先进行原子递增,在进行拿出号码,这样可以实现多个协程一起拿的操作 nextID := atomic.AddInt64(counter, apply) if nextID <= segment.MaxID { for s := nextID - apply + 1; s <= nextID; s++ { validIDs = append(validIDs, s) } return validIDs, true } else { for s := nextID - apply + 1; s <= segment.MaxID; s++ { validIDs = append(validIDs, s) } return validIDs, false } - 分布式ID生成器
优点
- 快速,提前在内存中直接发
- 绝对递增性和保证唯一性
- 可以通过hash环进行容灾
缺点
- 宕机会出现不连续的情况
- mysql拿的一下出现抖动以及缓慢(可以通过提前拿号缓解)
微信方案
实现
- 底层也是基于mysql号段模式,不够提前拿号
- 模型还是存在一个问题:重启时要读取大量的max_seq数据加载到内存中。为了解决这个问题,微信使用的方式是相邻uin的用户一起使用同一个发号器

容灾
微信
- 使用主从容灾的办法,出现问题及时切换
- 因为svrkit的路由机制,因此最多试错一次就可以拿到正确的信息(不过这样利用率低)
企业微信
- 使用一致性hash,类似tira-others > gennerator,但是容灾的方式更加的简单
- 请求到服务器,服务器首先查看自己缓存中是否存在这个号的号段,每次读取都必须需要访问数据库一次(这里理论上性能很差,但是实际上用的是分布式kv,开销不是很大)
- 如果不存在,给数据库的max_id向前移动一步,如果存在但是和数据库版本不一样也会移动

参考
- https://www.infoq.cn/article/wechat-serial-number-generator-architecture
- https://tech.meituan.com/2017/04/21/mt-leaf.html
- https://zhuanlan.zhihu.com/p/152179727
CAP理论
C - Consistency 一致性
- 一致性是指写操作后的读操作可以读取到最新的数据状态,当数据分布在多个节点上,从任意结点读取到的数据都是最新的状态。
A - Availability 可用性
- 可用性是指任何事务操作都可以得到响应结果,且不会出现响应超时或响应错误。
- 所有请求都有响应,且不会出现响应超时或响应错误
P - Partition tolerance 分区容忍性
- 通常分布式系统的各各结点部署在不同的子网,这就是网络分区,不可避免的会出现由于网络问题而导致结点之间通信失败,此时仍可对外提供服务,这叫分区容忍性。
- 分区容忍性分是布式系统具备的基本能力(分布式要解决的问题之一就是单点故障,因此这个不可或缺)
结论
- 在所有分布式事务场景中不会同时具备 CAP 三个特性,因为在具备了P的前提下C和A是不能共存的

证明
- A发消息使得N1的val变为V1,但是由于网络问题(属于P的需求),V1无法通知N2的val
- 此时B对N2的val进行访问,现在B有两种选择
- 返回旧结果给B,等网络恢复再进行更新(放弃一致性,返回旧结果,AP)
- 等待网络恢复,拒绝马上返回结果(放弃可用性,CP)
- 因此系统无法做到同时具备CAP三个特性
设计
CA
- 放弃分区容忍性,即不进行分区,不考虑由于网络不通或结点挂掉的问题,则可以实现一致性和可用性。那么系统将不是一个标准的分布式系统,最常用的关系型数据就满足了CA,日常一般使用的都是CA(即非分布式系统)
AP
- 放弃一致性,追求分区容忍性和可用性.要求系统返回的结果不一定是最新的.一般用于实时性要求不这么高的场景,比如退款之类,保证最终一致性,类似消息队列的无限重试就是这个(保证一定执行,但不保证马上执行),分布式事务常用这个
CP
- 放弃可用性,追求一致性和分区容错性,zookeeper和etcd(raft)其实就是追求的强一致,用于一致性要求很高的场所(银行之间的转账),就是很多时候宣传的高可用性(因为无法到达100%)或者强一致性都是这个体系
示例
A给B转账,事务1:扣A钱,事务2:加B钱 CA解决方案: 放在同一个系统,用mysql事务保证CA 就是单体结构 AP解决方案: 1成功后,如果2不成功,那么把2扔到消息队列无限重试(也可以是其他的办法),这期间,A和B都可以该操作账户(只是数据未必真实) CP解决方案: 1成功后,2不成功的话,A和B账户因为事务并没有成功出现不可用的情况,只有等到结束才能拿到数据(此时数据真实,但是中间时间不可用)
分布式事务问题
- 因为cap存在使得系统无法也不可能达到100%可用性,无法满足事务的ACID的基本要求
分布式事务解决方案
2PC两阶段提交
[!NOTE] 在mysql中这部分的是通过XA协议进行交互的
步骤
- 准备阶段(Prepare phase):事务管理器给每个参与者发送 Prepare 消息,每个数据库参与者在本地执行事务,并写本地的undo/redo日志,此时事务没有提交。此时mysql事务对所需资源自动进行上锁
- 提交阶段(commit phase):如果事务管理器收到了参与者的执行失败或者超时消息时,直接给每个参与者发送回滚(Rollback)消息;否则,发送提交(Commit)消息;参与者根据事务管理器的指令执行提交或者回滚操作,并释放事务处理过程中使用的锁资源.必须在最后阶段释放锁资源。
缺点
- 一旦事务多起来,到处都是mysql预留的资源锁(prepare这部分实际上通过mysql的事务实现),损耗性能
- 代码侵入度大,不利于代码维护
Seata
区别
- 将数据库层面的业务剥离到额外的业务层面,业务代码入侵度小
- 一阶段直接提交事物,通过锁和补偿性提交避免脏读问题,性能更加好
TCC
TCC 是 Try、Confirm、Cancel 三个词语的缩写
步骤
- Try,首先预留资源,比如在数据库资源的status修改使其不能被其他事务使用,如果出错直接跳到Cancel取消资源的预留(修改status成为可使用)O
- Confirm,提交事务,通常情况下,采用TCC则认为 Confirm 阶段是不会出错的。即只要Try成功,Confirm一定成功,如果不成功需要重试或者人工.
- Cancel,取消事务,如果try失败,直接cancel.默认认为TCC的cancel阶段不会出问题,出问题需要重试或者人工
优点
- 通过状态取代事物,相当于乐观锁取代悲观锁,进一步提升性能,两阶段变为三阶段,在应用层面解决
缺点
- 代码入侵性强,实现难度大
- 状态复杂,需要实现不同的回滚策略
可靠消息一致性
- 如何保证事务的消息传递出去,以异步的方式完成交易
- 解决因为重复导致的幂等性问题
本地消息表
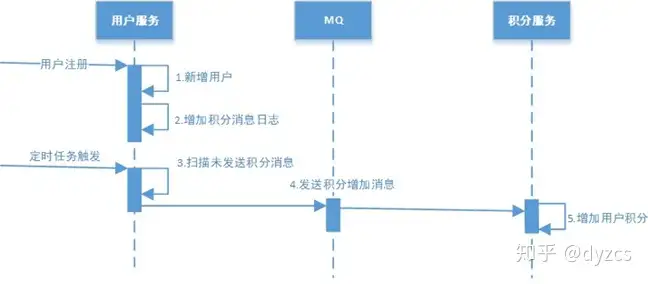
- 先在自己的表存储消息,然后把消息扔到MQ中,等待MQ重试发送消息,回ACK就不再发,基于MQ保证至少被消费一次,如果MQ反馈成功就删掉记录,否则一直定时发
最大努力通知
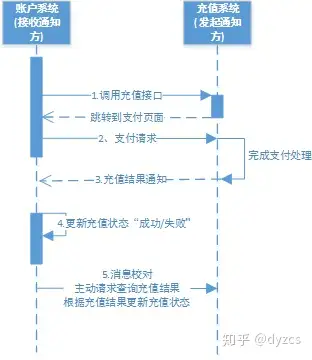
- 发起通知方通过一定的机制最大努力将业务处理结果通知到接收方。
- 一定的消息通知重试机制(基于MQ)
- 消息校验机制,消费者自己向生产者索取
总结
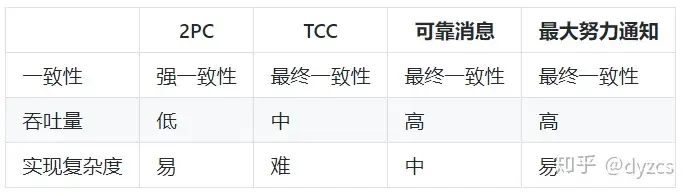
- 2PC 阻塞协议,很难用于并发较高以及子事务生命周期较长(long-running transactions) 的分布式服务中。
- TCC 在应用层面实现,可以用于支付,转账的高性能和一致性场所
- 可靠消息 适合执行周期长且实时性要求不高的场景,避免了同步阻塞的操作
- 最大努力通知 是分布式事务中要求最低的一种,适用于一些最终一致性时间敏感度低的业务(比如支付成功通知等)
微信支付
- 使用两阶段提交+MQ事务的方法保证最终一致性,分为主事务和从事务,主事务成功后,不停尝试执行从事务
- 如果是面对面转账这种强一致性的多主事务,需要使用mysql的事务机制,加上TCC的机制
- 如果为代扣的这种事务就是先创单(主事务),然后延迟打钱(从事务)
事件中心
- 底层是消息队列

- 解耦,就是对事务分主次:
- 主事务一般是核心逻辑,逻辑重,同步调用;
- 从事务一般是次要逻辑,逻辑轻,异步调用。
- 第一阶段是prepare,将消息暂存到事件中心,但是不发布,等待二次确认;prepare后,业务执行主事务(一般是rpc远程调用),成功就发commit给事件中心,投递消息到从事务;失败就发rollback给事件中心,不做投递。
- 这里需要两阶段提交的原因是:我们常规理解的入队操作,也就是一阶段提交,无论是放在主事务执行前,还执行后,都无法保证最终一致。考虑如下场景
如果是先做主事务,再入队,那可能入队前就宕机了; 如果是先入队再做主事务,那可能主事务没做成功,但从事务做成功了。
- 所以无论哪种做法都有问题,二阶段提交是必须的。
反查
- 如果prepare后没有进行commit或者rollback(消息丢失或者系统重启),事件中心就会主动下发消息询问主事务执行的结果
普通消息
- 普通消息直接通过事务中心执行所有事务
- 两个必须要用事务消息的场景:
第一是事务逻辑复杂,也就是发生逻辑失败的概率大,比如扣款前要检查余额是否足够,如果余额不足,那在异步流程中重试多少次都是失败。
第二是事务不可重入,例如业务系统入队时并未确定一个唯一事务ID,那各事务就无法保证幂等,假设如果其中一个事务是创建订单,不能保证幂等的话,重试多次就会产生多个订单;所以这里需要用事务消息,明确一个分布式事务的开始,生成一个唯一事务ID,让各个事务能以这个事务ID来保证幂等。
事件中心设计
- 事件中心的本质是队列驱动事务,所以要满足常见的队列功能,比如多订阅、出队有序、限速、重试等等
- 订阅者用于执行从事务

- Producer是发布者,Consumer是消费者,Consumer用推模式将消息推给Subscriber订阅者,这都是比较好理解的。然后来看Store,队列存储Store的实现选择了Paxos,是因为Paxos能保证副本一致,可避免乱序/去重问题,非常适合队列模型。Paxos协议的正确运行需要同步刷盘,副本同步数3份,这能提高数据可靠性。朴素Paxos的性能不是很好,所以通过批量提交的方式保证写入性能。
- 接着来看Scheduler,Scheduler是Consumer的协调者,通过与Consumer维持心跳,定义Consumer的生死,实现容灾;同时收集Consumer负载信息,实现负载均衡。Sched还依赖分布式锁Lock来选举master,只有master提供服务,自然实现容灾和服务一致性。
- 最后来看Lock,Lock是一个分布式锁,不仅用来给Scheduler选master,他还服务于Consumer,防止负载均衡流程中多个消费者同时处理一条队列。
- 这里Consumer的负载均衡流程也是一个二阶段提交,第一阶段是Consumer先跟Scheduler确定自己该处理哪些队列,第二阶段是访问Lock对队列抢锁,只有抢到锁后才能开始处理。
- kv查无记录时反查业务。只有确认commit,Consumer才会投递消息给订阅者。

多个主事务
-
类似TCC的机制,预锁资源的方法
这里也可以通过补偿的方式,但是中间态会短暂暴露
-
事务预写的具体做法是,将主事务1中会导致逻辑失败的部分,提前到prepare前执行,从而减少prepare...commit/rollback之间的事务个数。主事务1的执行结果在提交前并不对外可见,所以即使该结果不回滚,也不破坏一致性。与TCC中的Try操作类似。

优缺点
优点
- 减低耦合度和业务入侵性,相当与把本地的事务表存储在MQ中
- 吞吐量大,不会涉及2pc的阻塞问题
缺点
- 从事务默认可以通过重试成功(因为没有提供主事务补偿的机制),导致不能覆盖所有应用场景
- 需要提供反查的接口,增加复杂度
参考
- https://zhuanlan.zhihu.com/p/263555694
- https://www.cnblogs.com/cbvlog/p/15458737.html
分布式总览
分布式核心
- 核心就是所有的中心化,单体的所有架构都会出现明显的中心故障的问题,导致可用性下降的问题,去中心化是分布式的核心思想
保证高可用性的方法
1. 解耦
- 使得就算一个程序panic,不会影响其他的程序,微服务框架 > svrkit
2. 隔离
- 解耦的目的就是为了隔离,避免出现一个panic所有都panic的问题
3. 异步
- 削峰,避免大流量导致雪崩,消息队列
4. 备份
- 容灾策略,避免出现机房着火数据丢失,类似分布式架构 > GFS
- 微信使用的是分布式数据库(leveldb+类raft)
5. 重试
- 需要有可用性就必须有重试,因为分布式架构下,网络波动是不可避免的,这又牵扯到幂等性的处理
6. 熔断
- 保护机制,避免因为一个微服务不可用导致整条链路故障,熔断通常伴随着降级,因为不能访问了
7. 补偿
- 分布式事务情况下,类似兜底办法,容许错误
8. 限流
- 保护机制,避免服务过载导致雪崩,限流算法 > 微信过载保护
9. 降级
- 保护机制,服务降级,将有限的资源用在更加紧急的地方
10. 多活
- 容灾策略,一般通过两地三机房,同时配上负载均衡,避免崩了一个业务不可用
mit6.824
MapReduce
- 主要解决分布式计算的问题
- 通过一个中心化的MapReduce程序分配map任务和Reduce
流程

- MapReduce 框架首先将输入文件划分为 M 片,每片通常为 16MB 到 64MB 大小。随后会启动集群中的机器(进程)。
- 集群中的一个进程是一个特殊的 master 进程。剩余的 worker 进程都由 master 分配任务。一共有 M 个 map 任务和 R 个 reduce 任务需要分配。master 会挑选空闲的 worker,一次分配一个 map 任务或者一个 reduce 任务。
- 被分配到 map 任务的 worker 读入对应分片的输入,从输入中解析出键值对,并分别将其传给用户定义的 map 函数。map 函数返回的中间键值对会被暂时缓存在内存里。
- worker 内存中缓存的键值对,会被分片函数分成 R 个分片,并周期性地写进本地磁盘。这些键值对在磁盘上的位置会被发生给 master,master 负责将位置发送给被分配到 reduce 任务的 worker。
- 当一个 reduce worker 接收到 master 发送的这些位置,它会向保存这些内容的 map worker 发送 RPC 请求来读取这些内容。当一个 reducer worker 读取完所有的中间数据,就会将其根据 key 进行排序,这样所有相同 key 的数据就会聚合在一起。这种排序是必要的,因为通常许多不同的 key 会由同一个 reduce 任务处理。如果数据过大,可能会使用外部排序。
- reduce worker 遍历有序的中间数据,对遇到的所有 key,都会将 key 和对应的值集合传给用户定义的 reduce 函数。reduce 函数的输出会被追加到一个最终的输出文件(每个 reduce 分片一个)。
- 当所有的 map 任务和 reduce 任务都完成后,MapReduce 的任务也就完成了。
GFS
- 一个 GFS 集群还包括一个 Master 节点和若干个 Chunk Server
- 主要负载为大容量连续读、小容量随机读以及追加式的连续写
- Chunk Server储存数据的分片(64MB为一片),每个文件对应的chunk和对应的偏移量由master储存
- 读取文件中的内容或者追加写入都是通过Chunk,Chunk通过又备份,多个备份之间有一个主的备份(Primary),这个Chunk Server负责写入,和master维护租约(60s)
- master负责管理和存储chunk数据,在对数据进行操作之前都会写日志
- 文件与 Chunk 的 Namespace
- 文件与 Chunk 之间的映射关系
- 每个 Chunk Replica 所在的位置
数据一致性
- 如果一次写入操作成功且没有与其他并发的写入操作发生重叠,那这部分的文件是确定的(同时也是一致的)
- 如果有若干个写入操作并发地执行成功,那么这部分文件会是一致的但会是不确定的:在这种情况下,客户端所能看到的数据通常不能直接体现出其中的任何一次修改
- 失败的写入操作会让文件进入不一致的状态
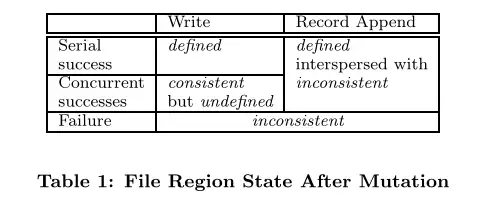
数据更改
覆写
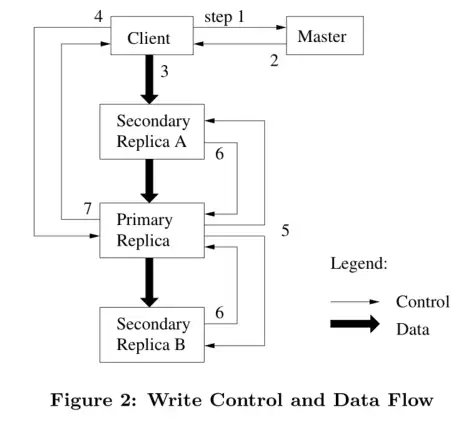
- 客户端向 Master 询问目前哪个 Chunk Server 持有该 Chunk 的 Lease
- Master 向客户端返回 Primary 和其他 Replica 的位置(master只负责帮客户端发现Chunk server)
- 客户端将数据推送到所有的 Replica 上。Chunk Server 会把这些数据保存在缓冲区中,等待使用
- 待所有 Replica 都接收到数据后,客户端发送写请求给 Primary。Primary 为来自各个客户端的修改操作安排连续的执行序列号,并按顺序地应用于其本地存储的数据
- Primary 将写请求转发给其他 Secondary Replica,Replica 们按照相同的顺序应用这些修改
- Secondary Replica 响应 Primary,示意自己已经完成操作
- Primary 响应客户端,并返回该过程中发生的错误(若有)
追加
- 客户端将数据推送到每个 Replica,然后将请求发往 Primary
- Primary 首先判断将数据追加到该块后是否会令块的大小超过上限:如果是,那么 Primary 会为该块写入填充至其大小达到上限,并通知其他 Replica 执行相同的操作,再响应客户端,通知其应在下一个块上重试该操作
- 如果数据能够被放入到当前块中,那么 Primary 会把数据追加到自己的 Replica 中,拿到追加成功返回的偏移值,然后通知其他 Replica 将数据写入到该偏移位置中
- 最后 Primary 再响应客户端
- 当追加操作在部分 Replica 上执行失败时,Primary 会响应客户端,通知它此次操作已失败,客户端便会重试该操作。和写入操作的情形相同,此时已有部分 Replica 顺利写入这些数据,重新进行数据追加便会导致这一部分的 Replica 上出现重复数据,不过 GFS 的一致性模型也确实并未保证每个 Replica 都会是完全一致的。
- GFS 只确保数据会以一个原子的整体被追加到文件中至少一次。由此我们可以得出,当追加操作成功时,数据必然已被写入到所有 Replica 的相同偏移位置上,且每个 Replica 的长度都至少超出此次追加的记录的尾部,下一次的追加操作必然会被分配一个比该值更大的偏移值,或是被分配到另一个新的块上。
快照
- 快照操作的实现采用了写时复制(Copy on Write)的思想:
- 在 Master 接收到快照请求后,它首先会撤回这些 Chunk 的 Lease,以让接下来其他客户端对这些 Chunk 进行写入时都会需要请求 Master 获知 Primary 的位置,Master 便可利用这个机会创建新的 Chunk
- 当 Chunk Lease 撤回或失效后,Master 会先写入日志,然后对自己管理的命名空间进行复制操作,复制产生的新记录指向原本的 Chunk
- 当有客户端尝试对这些 Chunk 进行写入时,Master 会注意到这个 Chunk 的引用计数大于 1。此时,Master 会为即将产生的新 Chunk 生成一个 Handle,然后通知所有持有这些 Chunk 的 Chunk Server 在本地复制出一个新的 Chunk,应用上新的 Handle,然后再返回给客户端
删除
- 当用户删除某个文件时,GFS 不会从 Namespace 中直接移除该文件的记录,而是将该文件重命名为另一个隐藏的名称,并带上删除时的时间戳。在 Master 周期扫描 Namespace 时,它会发现那些已被“删除”较长时间,如三天,的文件,这时候 Master 才会真正地将其从 Namespace 中移除。在文件被彻底从 Namespace 删除前,客户端仍然可以利用这个重命名后的隐藏名称读取该文件,甚至再次将其重命名以撤销删除操作。
- Master 在元数据中有维持文件与 Chunk 之间的映射关系:当 Namespace 中的文件被移除后,对应 Chunk 的引用计数便自动减 1。同样是在 Master 周期扫描元数据的过程中,Master 会发现引用计数已为 0 的 Chunk,此时 Master 便会从自己的内存中移除与这些 Chunk 有关的元数据。在 Chunk Server 和 Master 进行的周期心跳通信中,Chunk Server 会汇报自己所持有的 Chunk Replica,此时 Master 便会告知 Chunk Server 哪些 Chunk 已不存在于元数据中,Chunk Server 则可自行移除对应的 Replica。
优点
- 更加可靠,因为可能存在部分chunk server上的数据master未知,如果master下发命令删除,可能删不干净,由chunk自己进行汇报删除更加可靠
- 周期扫描和删除数据结合,减少资源损耗
- 避免误操作
高可用保证
- Master 会为每个 Chunk 维持一个版本号,以区分正常的和过期的 Replica。每当 Master 将 Chunk Lease 分配给一个 Chunk Server 时,Master 便会提高 Chunk 的版本号,并通知其他最新的 Replica 更新自己的版本号。如果此时有 Chunk Server 失效了,那么它上面的 Replica 的版本号就不会变化。
- Chunk Server 重启时,Chunk Server 会向 Master 汇报自己所持有的 Chunk Replica 及对应的版本号。如果 Master 发现某个 Replica 版本号过低,便会认为这个 Replica 不存在,如此一来这个过期的 Replica 便会在下一次的 Replica 回收过程中被移除。除外,Master 向客户端返回 Replica 位置信息时也会返回 Chunk 当前的版本号
Raft
前提
- 至少一半的机器运行正常
- 广播时间需要<<选举超时时间<<平均故障时间
- 非拜占庭情况下
状态机复制
- 底层是状态机的复制,同一个系统,相同的输入之后得到的状态是相同的
状态转换
- 所有的机器只会是leader(领导者),candidate(候选人),follower(跟随者)
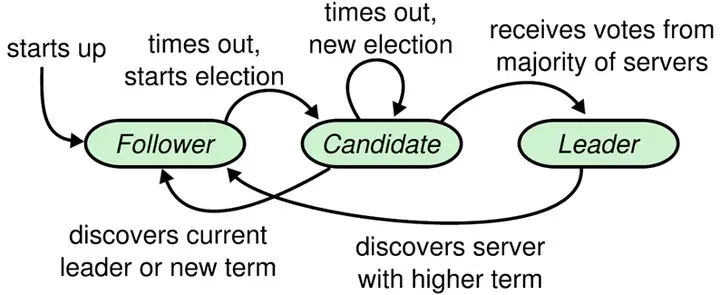
- Raft算法将时间分为一个个的任期(term),每一个term的开始都是Leader选举。在成功选举Leader之后,Leader会在整个term内管理整个集群。如果Leader选举失败,该term就会因为没有Leader而结束。
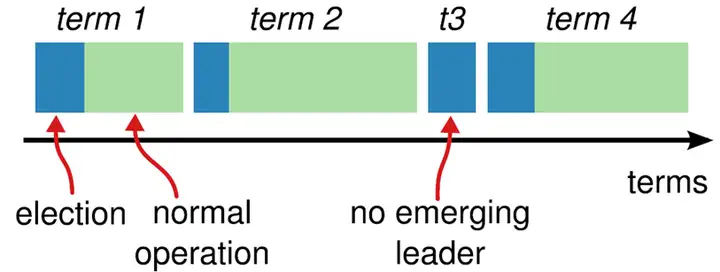
- 只存在两种RPC
- RequestVote RPC : candidate发起,请求投票
- AppendEntries RPC : leader复制日志和心跳保活
- 通讯会交换任期号,如果是follwer发现自己的任期比较小,那么会切换到大的任期号,如果是其他两种发现,会切换为follower
- 节点忽略过期任期号的请求(比如刚复活的进行选举,会选举失败)
领导者选举
- 心跳机制,leader向follower发送心跳包(携带任期号),超过最大时间follower发现没收到心跳之后
- 增大自己的任期号
- 切换为candidate状态,投票给自己,发送RequestVote给其他机器
- 结果三种可能
- 超过半数选票成为leader
- 其他赢了,标志为收到其他leader的心跳包,新leader任期不小于自己的任期号
- 没人获胜,重新选举
- 为了公平和防止进入死循环,选举超时时间会进行随机化(从发现leader没发心跳包,到成为candidate发送rpc的时间随机化)
RequestVote RPC内容
被候选者用来收集选票:
Arguments:
term 候选者的任期
candidateId 候选者编号
lastLogIndex 候选者最后一条日志记录的索引
lastLogItem 候选者最后一条日志记录的索引的任期
Results:
term 当前任期,候选者用来更新自己
voteGranted 如果自己将票投给候选人则为 true。
接受者的实现:
1. 如果 leader 的任期小于自己的任期返回 false。(5.1)
2. 如果本地 voteFor 为空,候选者
日志复制
- 只有leader具有写的权限(即向日志中附加条目),follower的写请求都会重定向到leader
AppendEntries RPC 内容
被 leader 用来复制日志,同时也被用作心跳
Arguments:
term leader 任期
leaderId 用来 follower 重定向到 leader
prevLogIndex 前继日志记录的索引
prevLogItem 前继日志的任期
entries[] 存储日志记录
leaderCommit leader 的 commitIndex
Results:
term 当前任期,leader 用来更新自己
success 如果 follower 包含索引为 prevLogIndex 和任期为
prevLogItem 的日志
接受者的实现:
1. 如果 leader 的任期小于自己的任期返回 false。(5.1)
2. 如果自己不存在索引、任期和 prevLogIndex、prevLogItem
匹配的日志返回 false。(5.3)
3. 如果存在一条日志索引和 prevLogIndex 相等,
但是任期和 prevLogItem 不相同的日志,
需要删除这条日志及所有后继日志。(5.3)
4. 如果 leader 复制的日志本地没有,则直接追加存储。
5. 如果 leaderCommit>commitIndex,
设置本地 commitIndex 为 leaderCommit 和最新日志索引中
较小的一个。
- 只有日志号和任期号才能唯一确定一个日志
日志有两种状态,生成和提交,提交之后不可撤回,只有半数以上节点ack,日志才会变为提交,只有leader同意,follower才能提交,没有生成的日志有可能被替代
- 具体流程
- leader接受到写请求,将日志通过rpc复制到所有的follower中
- 等待超过半数的follower复制成功并且返回ack(就是下一个心跳包)之后,leader会提交日志到版本库,并且返回应用层成功的消息
- leader告诉所有的follower让他们提交
- follower提交
follower宕机
- 如果follower没有响应,leader会不断进行重发到该follower尝试
- follower回复之后会进行一致性检查恢复缺失的日志
当发送一个 AppendEntries RPC 时,Leader会把新日志条目紧接着之前的条目的log index和term都包含在里面。如果Follower没有在它的日志中找到log index和term都相同的日志,它就会拒绝新的日志条目。
leader宕机
- 如果宕机的leader还有日志未提交,那么可能出现其他leader强制性覆盖旧leader未提交的数据
安全性
投票
- 如果投票者手上的日志信息比candidate还新,就会拒绝该请求
相同任期比日志号,不同任期比任期号,日志号不是提交了的日志号,而是存在的日志号码(没有提交的也算)
日志
- leader只会对自己的任期内的日志计算副本数目的提交,上一个任期内的日志不会被马上提交,只有自己产生了新日志才会进行统一提交
成员变更
联合一致
- 采用两阶段的方法避免脑裂问题
- leader发起rpc请求,使整个集群进入联合一致的状态,此时rpc在新旧两个配置都要达到大多数才算成功
- leader发起rpc,整个集群进入新配置状态,能达到大多数就算成功,在新增节点时,需要等待新增的节点完成日志同步才开始成员变更
- 复杂,使用较少
单节点变更
- 完成增加节点的日志同步
- leader发送rpc请求,等待大多数之后就可以提交标识成功
数据读写
- 写请求统一发送到leader
- 读请求到了 follower 后,follower会去向 leader 请求 readindex(也就是当时 leader 的 commitindex), leader 在确认自己还是 leader 之后,就会吧 readindex 发给 follower,follower 会对比自己的 commitindex 和 readindex,只有commitindex 大于等于 readindex 之后,才能读取数据返回.
ETCD
- etcd 就是底层使用raft实现的一个kv类型的数据库,可以保证强一致性,属于CP类型的数据库
参考
- https://raft.github.io/
- https://zhuanlan.zhihu.com/p/32052223
参考
- https://zhuanlan.zhihu.com/p/33944479
- https://pdos.csail.mit.edu/6.824/schedule.html
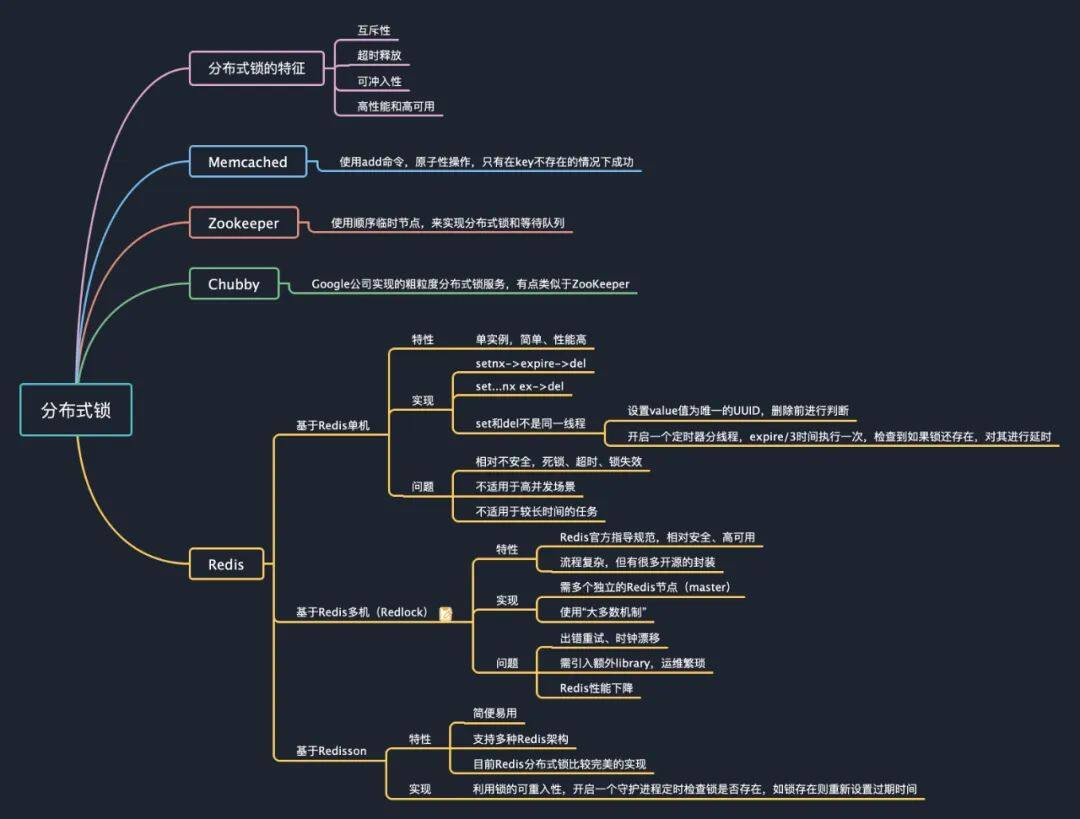
- 幂等性处理用的非常多,避免重复
类型
- Memcached 分布式锁
- Zookeeper 分布式锁,典型强一致性协议的产物,基本和本地锁没区别,但是性能不高
- Chubby, Google 公司实现的粗粒度分布式锁服务,通过 sequencer 机制解决了请求延迟造成的锁失效的问题
- Redis 分布式锁,用的最多的,实现和Memcached类似,都是通过原子操作
Redis单机锁
setNX
- 通过setNX指定锁生存时间
缺点
- 无法保证生存时间内解决事务,解决不了但是锁消失不满足互斥性会造成严重后果
- 如果不加过期时间容易造成死锁(比如程序panic,导致锁无法释放)
Redisson
- 让获得锁的线程开启一个定时器的守护线程,每 expireTime/3 执行一次,去检查该线程的锁是否存在,如果存在则对锁的过期时间重新设置为 expireTime,即利用守护线程对锁进行“续命”,防止锁由于过期提前释放
Redis集群锁
- 上面都无法解决分布式集群下,当master崩了,锁还没有同步的时候,导致新的master没有锁,造成锁失效的事故
Redlock
- 暂时不会,略
参考 info
前言
- 在最近两个周末我尝试进行了两天的 vibecoding, 高强度的 vibecoding,超过 2亿 token 消耗, 确实有了挺过感受和思考
- 现在互联网上到处都是 ai 要替代程序员的说法, 但是我去真正调研和观察我的同事和相关从业人员的时候, 却发现 ai 的渗透率比我想象的要低, 至少在我们真正工作上 coding, 起作用的大多时候还是 类似 copilot 这类的工具而非是 cursor/cluade-code 这种 vibecoding的工具
- 实际上我发现一件事, 那些开源项目或者说小公司的项目,他们通常会觉得 AI 是一个非常有帮助的工具,甚至可以说能完全替代程序员, 但是实际上针对于大厂,类似字节、腾讯这种的员工来说,当他们真正使用这 AI 的时候,他们会发实际上 AI 能发挥的功能是非常有限的(从我的角度观察到的, 比较主观)
- 但我其实比较幸运,我首先本身是大厂的员工,因此我能接触到那些动辄十万乃至百万行的代码。以及我同时在维护着很多开源项目,包括在改写一些自己的小项目之类的,因此我也有需求是去写小项目的。这就给我非常好的机会去体验不同的场景
- 实话实讲,我确实被震惊到了,AI 发展的速度确实是指数级的。现在的 ai 和 22年出 gpt3.5 简直不能同日而语, 现在给我的震撼能和 3年前带给我的相媲美
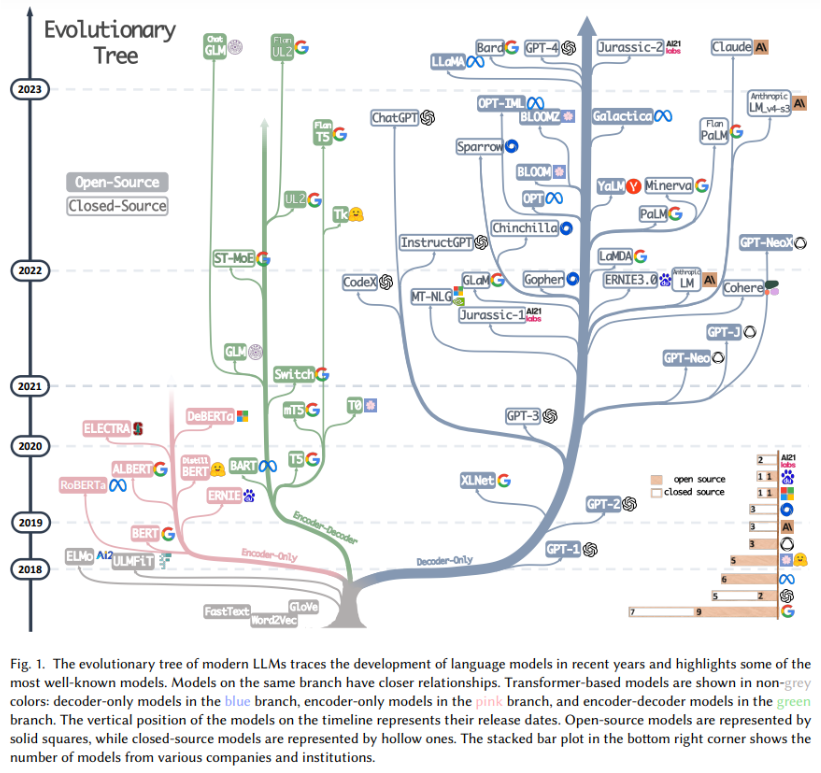
Vibecoding
-
我用 ai coding 尝试主要是在这几方面
- 小型开源项目的修改
- 大型开源项目的修改
- 大型工程项目的修改(公司项目)
- 产品 MVP 版本实现
-
使用的工具主要是
- qwen-cli
- vscode+cline
- gemini-code
- claude-cli
没用 cursor 是因为这玩意太过分了, 现在居然自定义模型都得加钱, 吃相难看, 也没见多大的不可替代性
-
使用的模型主要是
- qwen
- gemini2.5
- claude
- glm4.5
-
我的模式基本都是非必要情况完全不读代码, 基本完全不写代码, 只负责提出要求,和验收成果
感受
AI 目前能做的
- AI 使得成为独立开发者的成本触底了, 你只需要懂得任何一门语言, 你就可以免费让 ai 去给你将脑海里的idea 实现出来, 基本上成本为 0, 当然除非你 idea 太复杂, 否则都是一件非常简单事, 你可以用一张产品图让 ai 做一个满足功能的 app, 前端就更加简单了, 以前你需要找程序员来进行开发, 如果你有了个 idea, 涉及多个方向的你还得找全栈程序员, 现在你只需要上点技巧说出你的梦想, 当然如果你本身是个程序员懂点代码, 这个会更加简单
- 我周末就用 ai 写了非常多的我的项目的前端网页官网, 基本每个几分钟就行, 因为我不是前端工程师, 我虽然也能写, 但是很麻烦, 现在完全没有这些考虑, 现在基本上就是这部分完全 ai 生成. 在4年前我做这些的时候基本上都是找个模板抄下来然后自己去改里面的文字和链接, 现在我截个图复制个链接给 ai , ai 也能搞出一模一样的出来
- 绝大多数的大学生作业之类的都是这类小型的玩具系统, 这种 ai 表现非常好

- 小型项目的修改基本上ai 可以完全解决, 我用 ai 给 GitHub - chenxuan520/MKOnlineMusicPlayer: 这个项目加上了收藏列表和评论详情这些功能, 项目是 php 写的, 我不懂 php, 但是实际上加这些功能我基本看都没看过代码, 全都是 ai 自己加上去的, 这样的 case 很多, 现在很多小型开源项目我们想加一些功能的时候基本上都完全可以自闭环所有修改, 不用等着作者大大去实现 GitHub - chenxuan520/newsnow 包括这个项目也是, 现在修改一个项目的成本非常低了
AI 效果还很差的
- 当单个项目大于 10w 行时候(当然这个估计并不准确,我只能够根据经验来进行一个初步的预估), 当项目存在非常多的历史业务逻辑 , 当项目存在非常多上下游的未知依赖的时候(上面这几个条件实际上就是企业级大规模项目) , ai 的表现是非常灾难的表现
- 整体代码理解力变弱非常多, 可能本质是没办法直接使用 lsp 的原因, 重构基本上每次都会漏改一些代码, 以及经常是 AI 会陷入一些不停的自循环搜索,或者说一些其他的一个问题,经常会把你的代码给改崩。
- 业务逻辑基本上不会改, 基本上属于你让他改一个地方他改了之后并不能发现其他地方会因为这部分导致崩溃, 基本上改着改着问题越改越多了, 代码质量非常差, 基本上是史山

- 上下游依赖接口的时候也不会自己去拉上下游的接口文档来看, 基本上属于自己猜测来进行修改的
- 目前AI 的上下文长度还是不足以支撑编写大型项目。我当时编码时候用的是100万上下文的。Gemini 2.5模型,但是实际上还是不够用,还是会有超越100万上下文的情况。
AI 发展的方向
模型
当年互联网之所以能够突发猛进发展起来,有一个很重要的原因就是网络从2G 变成4G 了,更大的带宽承载了更多的流量,这是整个互联网能够蓬勃发展的基石和底座, 使得流量可以承载视频流的出现。而现在 AI 的时代,模型的质量就是曾经的网络的速度
更大
- 更大的上下文, 没有更长的记忆力, 更长的上下文或者缓存, 基本上大型项目就是痴人说梦, 很简单, 超过 10w 的代码库理解难度是真的比任何一本书大的
- 更加聪明的模型, 现在基本上几乎每家大模型都在往这个方向发展, 让自己变得更加聪明, 让自己能够承载更多的业务, 让自己的模型标准成为行业的标准
更小
- 参数轻量化, 我们现在日常生活中反而见到一些场景的机器人比较少的一个重要原因是, 目前 本地跑大模型成本太高了, 没办法压缩到一个 1w的诊疗台机器人能够跑的起的程度, 跑不了必然需要联网, 但是联网涉及到的问题就会非常多, 隐私以及断网情况下解决, 所以目前让模型变小+二次训练成某个方向的机器人也是一个非常热门方向
- api 价格便宜化, 三年前我觉得 200w 的token 非常多, 基本用不完, 毕竟每天不停聊天也用不了多少, 现在 vibecoding 10分钟吃了 一千万, 两天吃了一个亿的 token, token 怎么都不够用(现在在项目里面用 cli说个 '你好' 都吃10w的token), 这种情况下太高的 token 价格意味着性价比会非常低
应用
10年叫做 互联网+万物, 20年就是 AI+万物
- 现在 'ai+' 的产业全面铺开但是还没全面见效, 就和当年互联网刚开始一样, 但是现在已经出现无数的 ai+ 的创业公司, 无论是 ai+机器人, ai+化妆镜 , ai+衣服试穿, 没有人知道某条路能否走通, 但是毫无疑问的是 'ai+' 这个产业确实会极大程度地影响我们的生活, 几年前 gpt 刚出现时候鲜有人会想到我们现在听的歌是 ai的, 看的视频是 ai生成的,图片是 ai生成的, 评论是 ai写的, 小说也是 ai 生成的, 代码也是 ai 写的, ai 在大家没注意到的角落已经占领了非常多的领域, 养活了非常多的人. 十年前有句话叫做
知先觉经营者;后知后觉跟随者 ;不知不觉消费者, ai 毫无疑问是目前这几年最大的风口, 只是绝大多数没意识到这件事的人都不知不觉成为了消费者 - 但是现在不得不承认, 最好的模型依旧在美国, 无论是 gpt5 , claude, gork ,gemini 对国内模型都是断崖式领先, 但是 qwen 和 deepseek 很大程度上拉高了模型的下限, 所有不如这两款的模型的闭源模型都死了, 因为人家比你好用还开源, 但是上限很明显能感觉到差距, 目前国内 ai 使用覆盖率最高的 doubao 连生成个 crontab 都能做错, gpt5 已经开始揣测用户心思并询问用户是不是需要更多的信息了
对行业的冲击
- 十年前滴滴的出现使得不会用滴滴的出租车司机几乎绝迹, 十年后 ai 的出现使得程序员和十年前的滴滴司机一样的处境, 如果不会用 ai 就不可避免出现落后乃至淘汰的风险
- 当然我不去卖课我也不希望任何人去买 ai 的课程, 纯粹智商税
- 滴滴不会淘汰所有司机, 只会淘汰不用滴滴的司机, ai 也是一样, ai在可见的范围内无法完全或者大规模替代程序员, 原因主要以下几点
- 实际上做程序员的都知道, coding 是整个工作最轻松的部分, 更多的是去了解业务逻辑, 历史逻辑, 和产品测试扯皮, 出问题了背锅, 但是现在及时是这俩面最简单的 coding 的部分 ai 依旧做的还不够, 正像我上面提到的 ai面对大规模代码时候的无力感, 如果你现在做的东西 ai 能提供非常非常大的 coding帮助, 甚至替代你的位置 , 这只能说明你现在做的系统还不够复杂. 当然这部分是 ai 最容易实现的部分
- 其他的方面目前 ai 渗透率更加低了, 比如 ai 还不会遇到不懂的代码上
git blame查谁写的然后一个电话打过去问当时怎么堆出来的, ai 也不会主动去搜索两年前的业务文档看下这玩意是什么意义, 这种情况下写业务代码几乎是不可用的, 本质上还是因为 ai 没有长期学习的记忆能力, 上下文再长还是不够, 毕竟现实世界的上下文几乎是无限的 - ai 现在还不会拒绝 , 也还不会从高内聚低耦合的角度去思考代码, 也就是不会考虑代码的维护性, 一个产品, 做个 MVP版本出来 ai 能做的很快, 但是你用ai迭代 1年之后会变得痛不欲生, 什么需求都能做,不在乎是否合适, 什么代码都能加, 先跑再说, 到最后的结果是,某一天加功能的时候发现怎么加都加不上了, 出现上面代码复杂度过高的情况了
- 还有一点, ai 不能背锅的, 问题代码是使用方承担后果, 这就意味着 ai 必然是程序员的助手而不是替代
程序员该做的
- 关注最新的 ai 进展, 但突破性 ai 应用出来时候第一时间考虑自己能不能用得上并且去尝试, 时刻保持对世界 ai 的敏感性
- 主动去思考自己的工作流程中那些是可以用 ai 进行提效的, 当然这一步几乎所有的互联网产品都在考虑. 但是作为一个程序员, 几乎所有的 ai 产品的最前线都是 coding, 如果长时间不在生活中去主动尝试 ai 在目前的应用, 最后的结果必然是渐渐不用 ai, 最后时落后于这个 ai 的时代
- 本文原文为 Vibecoding - chenxuan'blog, 转载请注明来源, 禁止转载到 CSDN, 其他随意
提示工程
给出明确的具体指令
1. 使用定界符
- 使用类似"""之类的定界符告诉gpt这是需要阅读的材料而不是任务
2. 要求格式化输出
- 比如json的形式,这样你可以直接将结果绑定到结构体,实现rpc功能
- 可以让他给出具体的终端命令,并且和结果格式化成json,这样chatgpt就可以真正调用你的电脑,实现和硬件的交互功能
- 比如html的形式,这样可以直接根据提示返回前端界面
3. 给出例子
- 类似先给出一个example,要求gpt模仿其生成,会更加精确
4. 尝试修改temperature
- temperature是一个参数(在api调用接口时候使用),默认是0,当这个参数越大的时候,结果的精确度越低,但是创造力会更加强大(有点类似bing的创造力模式)
给模型思考的时间
- 如果让模型快速判断快速生成,模型只能生成一个大概的内容,字数和内容深度都不够,因为模型类似人类看一眼而没有思考
1. 描述一个任务的具体步骤
- 通过任务的具体的步骤(其实这个步骤可以通过之前对话生成),每次对话让他解决其中的一个步骤
比如让他写论文,应该第一步让他先写大纲,然后每一条单独去问去写,而不是直接让他写,模糊的目标只有模糊的结果
2. 在模型下结论之前,指导它自己解决
- 比如让他判断计算是否正确时候,可以先让他自己解决,然后对结果进行对比,再下结论,延长模型的思考过程
不停地改善提示语句
- 通过不停微调提示语句,让其扮演一个特定的角色
总结工程
- 这是传统npl算法工程是训练的重点
1. 将总结汇报侧重在某个点
- 比如向某个具体人群的汇报,这样就会更加具象化
2. 可以将大量的数据生成摘要
- 可以用于评论分析方面,这样可以快速简化内容
3. 可以用于情感分析
- 让其对情感进行分析并输出json,方便批量统计数据特性
4. 可以用于判断是否包含某个主题
- 典型的打标行为,给推荐系统打上tag的行为,可以让其堆每个tag打分并格式化成json输出
其他领域
文本翻译
1. 个性化翻译
- 类似转换官方翻译,口语翻译之类的提示词
2. 纠正语法错误
文本扩写
1. 提取情绪并应用情绪
- 扩写之前可以向他提出详细的要求
聊天机器人
- 这部分可以输入自己的信息训练出一个个人的模型
- 假设你是xxx,你会在yyy的场合下做什么
1. 使用system上下文
- system作为上下文的时候,相当于基础设定而不是假设,这样可以让角色的扮演更加真实
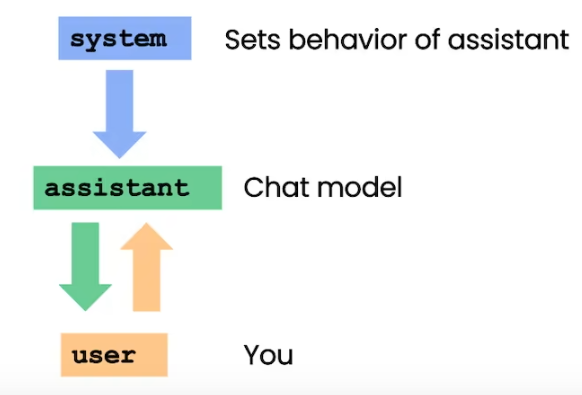
解决问题
核心特点
- 大语言模型特点:垃圾输入,垃圾输出
- 如果我想让你xxx,我应该给你输入什么信息
- how类问题核心在于路径的获取
- 明确目标->寻找路径->获取工具
- why类问题核心在于事实推理
沟通视窗
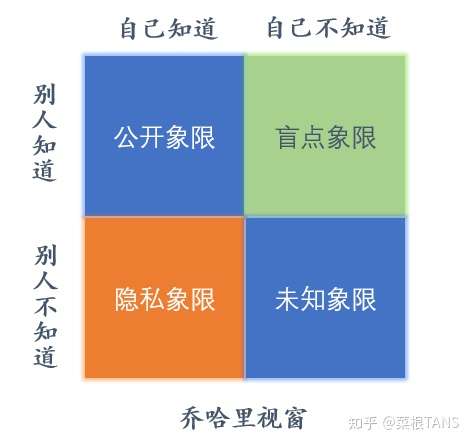
盲区问题(获取信息)
- 我先了解xxx,我应该向你问什么问题
- 列出xxx领域50个概念和解释,详细介绍xxx
公开区域问题(检验/扩充认知)
- 对于xxx,你认为什么是我应该掌握的要点
- 我理解xxx是yyy的,你觉得我的理解对吗
- 我先深入学习xxx,可以推荐一些学习资源和路径吗
隐私区域问题
- 这种得详细描述整体要 ai 去做的事情, 因为这部分如果不详细描述 ai 生成的和你得到的差距很大, 需要一步一步列举
未知象限
- 这部分只能和 ai 一起去探索, 不停改进自己的提示词和技巧和
达克效应
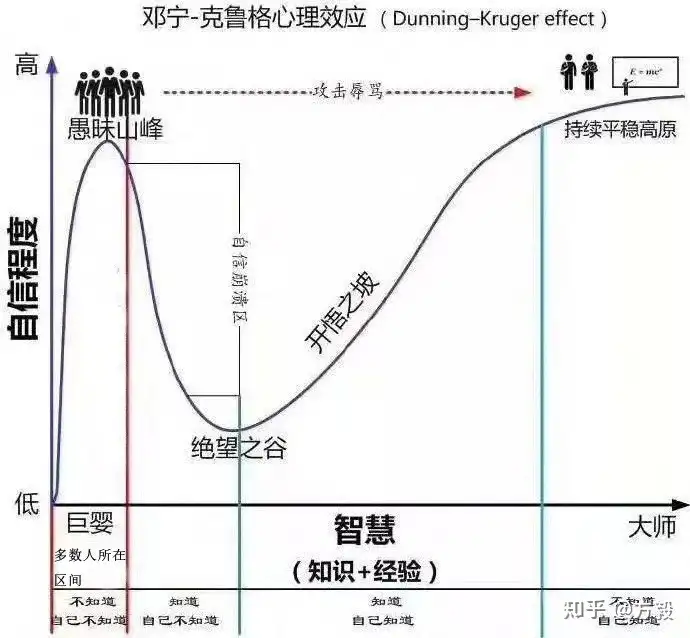
- 使用chatgpt方向提问能力
- 为了测试我对xxx的认识,提问10个问题检验我的水平
- 我已经熟悉xxx,我是否还需要了解什么
隐私区
- 介绍背景后让他分析可能的影响
其他
有趣的用法
- 确认主题->AI思维导图(大纲)->AI文章生成->AIppt生成
提示词类型
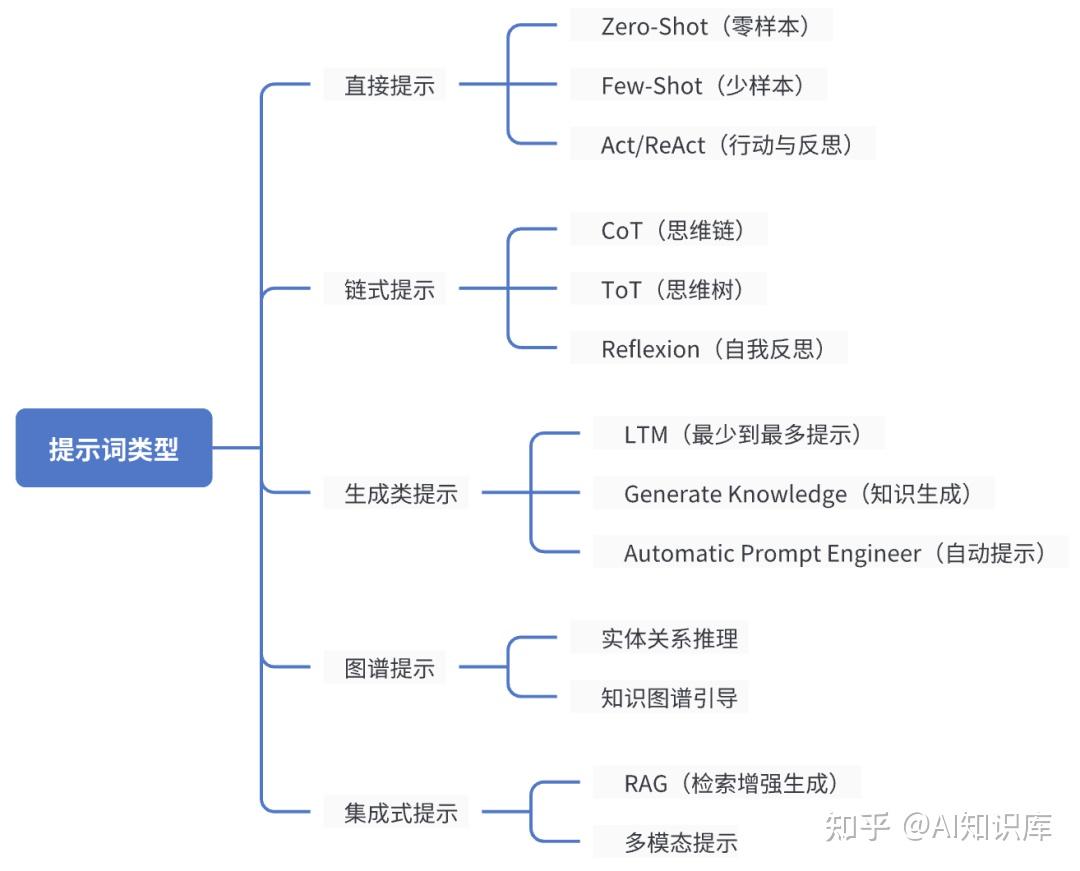
提示词框架
- 参考 prompt 提示词18种框架 20个提示词写作技巧(进阶篇)
- 整体上是
背景/上下文/清晰度(范围)/情况/问题
背景信息:
做事情的上下联系
做事的范围, 受众
问题: 核心要解决的问题
角色
行动
支持: 为大模型提供该行动的额外信息或资源
技术: 具体调用的程序或软件
任务: 具体执行任务
步骤: 期望采取的详细步骤
计划: 行动方案
目的/目标/结果/期望/预期方案
演变/评估
执行后期望演变的样子
行动后对效果的评估或分析
个性
语气
格式:输出格式, 控制回复量
实验/示例: 多个示例,(有示例有时候可以省略语气和格式)
示例
要求生成几个例子
- 相关关键词
Background:背景
Profile:概述
Role:角色
Task:任务
Request:需求
Purpose:目的
Skills:技能
Capabilities:能力
Constrains:约束
Attention:注意事项
Improtant:重要
Goals:目标
Objectives:目的
Definition:定义
Tone:文风
Value:用途
Format:格式
Notes:注释
Insight:见解
Statement:声明
Input:输入
Scenario:场景/脚本
Output:输出
Result:结果
Workflows:工作流
Step:步骤
Action:行动
Expectation:预期
Output indicatot:输出引导
Key result:关键结果
Conntext:上下文
Example:示例
Evole:实验改进
Initialization:初始化
有用技巧/提示词
压制幻觉
- 必须仔细校验无误以后再输出。
- 多用Improtant。
- 思考过程中如有任何不清晰或存疑之处,请勿自己揣测,而应向我提问求证,以保证理解的准确性;
- 这个非常重要,无论什么时候都应该加上
思维链条
这部分其实绝大多数ai工具的系统提示词会自动有
- step by step(一步一步)
- 强制思考
自我检查
- 在正式输出之前,请对整个回答再通读一遍,检查是否有任何错别字、标点误用或者语病等,力求做到完美无瑕。(case, 其他情况自行变通)
输出格式
- 使用markdown输出
- 使用```、---、===、“”等分隔符,区分提示与示例。
- 使用‹›、【】、[]等不同括号区分不同层级的标签
参考:
- https://space.bilibili.com/15467823/video
基本结构

- 通常用 输入层,隐藏层,输出层 3个部分表示
隐藏层深度选择
- 没有隐藏层:仅能够表示线性可分函数或决策
- 隐藏层数=1:可以拟合任何“包含从一个有限空间到另一个有限空间的连续映射”的函数
- 隐藏层数=2:搭配适当的激活函数可以表示任意精度的任意决策边界,并且可以拟合任何精度的任何平滑映射(基本两层就够了,两层基本相当于能够拟合任何函数了)
- 隐藏层数>2:多出来的隐藏层可以学习复杂的描述(某种自动特征工程)
- 层数越深,理论上拟合函数的能力增强,效果按理说会更好,但是实际上更深的层数可能会带来过拟合的问题,同时也会增加训练难度,使模型难以收敛。
神经元个数选择

- 在隐藏层中使用太少的神经元将导致欠拟合(underfitting)。 相反,使用过多的神经元同样会导致一些问题。首先,隐藏层中的神经元过多可能会导致过拟合(overfitting)
- 当神经网络具有过多的节点(过多的信息处理能力)时,训练集中包含的有限信息量不足以训练隐藏层中的所有神经元,因此就会导致过拟合。 即使训练数据包含的信息量足够,隐藏层中过多的神经元会增加训练时间,从而难以达到预期的效果。显然,选择一个合适的隐藏层神经元数量是至关重要的。
[!tip] 参考 如何确定神经网络的层数和隐藏层神经元数量?
梯度下降

- 实际上就是通过根据倒数判断目前处在的位置应该向上还是向下继续行动, 根据对某个参数的偏导代表着这个参数的调整方向, 再和学习率相乘获得调整值
反向传播




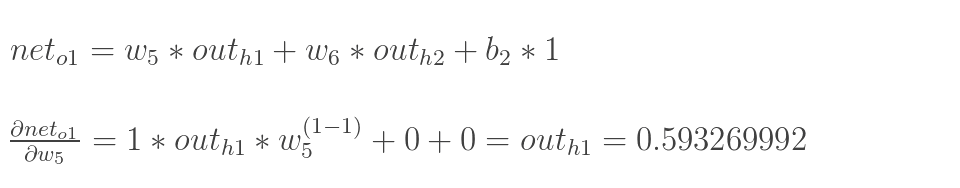

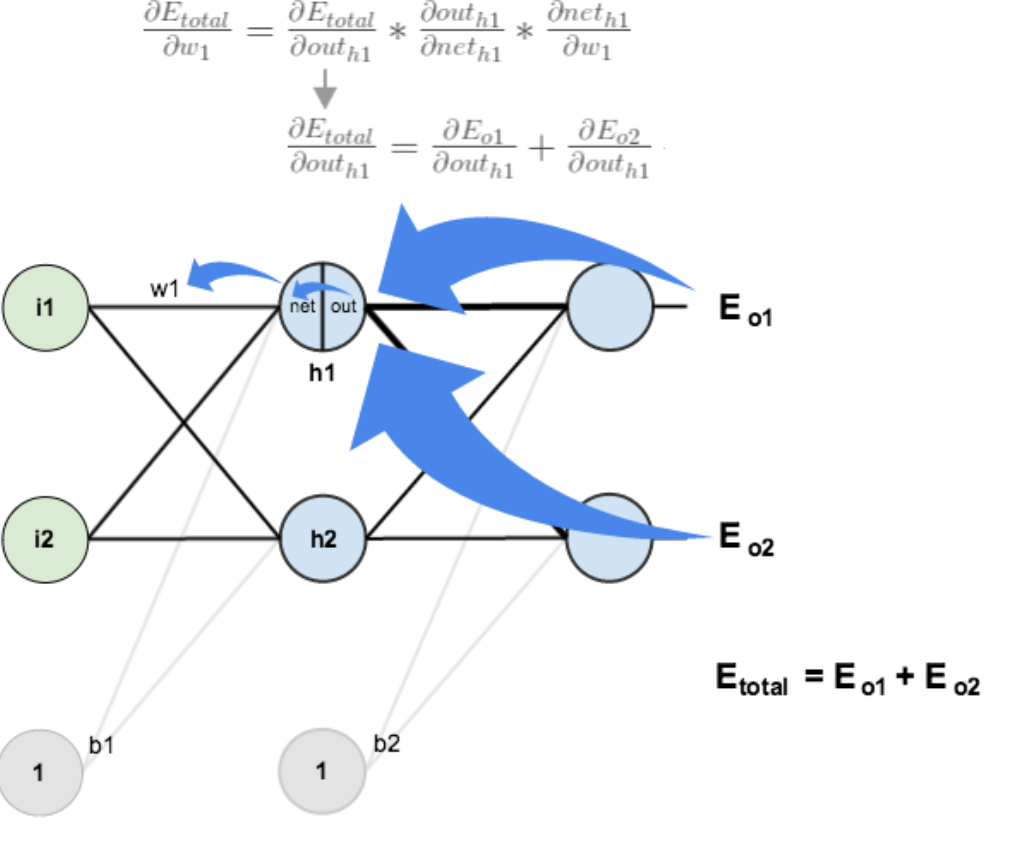
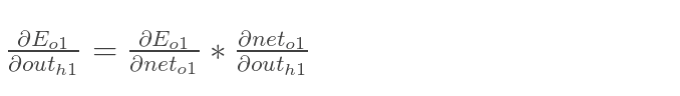

- 实际上就是对某个变量进行求偏导 , 然后根据这个导数的值去调整这个变量的值, 调整的大小就是学习率
- ∇C 作为 对变量 v 的偏导 ,C 作为代价函数 , 这个函数越小越好(这个函数可以变化的) $$C(w,b)\equiv\frac{1}{2n}\sum_{x}|y(x)-a|^{2}$$
∆C ≈ ∇C · ∆v∇C 把 v 的变化关联为 C 的变化,正如我 们期望的⽤梯度来表⽰。但是这个⽅程真正让我们兴奋的是它让我们看到了如何选取 ∆v 才能 让 ∆C 为负数。假设我们选取:∆v = −η∇C- 这⾥的 η 是个很小的正数(称为学习速率)。
∆C ≈ −η∇C·∇C = −η| ∇C |2。 由于|∇C| 2 ≥ 0,这保证了∆C ≤ 0,如果我们按照⽅程的规则去改变 v,那么 C 会 ⼀直减小,不会增加。因此我 们把⽅程 (10) ⽤于定义球体在梯度下降算法下的“运动定律”。也就是说, 计 算 ∆v,来移动球体的位置v: v → v ′ = v − η∇C然后我们⽤它再次更新规则来计算下⼀次移动。如果我们反复持续这样做,我们将持续减小 C 直到 —— 正如我们希望的 —— 获得⼀个全局的最小值。 - Sigmoid函数的求导结果为: $$ S′(x)=S(x)(1−S(x)) $$
[!tip] 参考 一文弄懂神经网络中的反向传播法——BackPropagation - Charlotte77 - 博客园
Softmax回归


- 实际上就是将最终的输出进行归一化处理, 使其可以直接进行交叉熵的计算
拟合问题
- 当出现训练数据损失不停减少, 但是测试数据损失在增加的时候. 说明出现了过拟合的问题
出现问题
训练不拟合
- 很多可能的原因,比如数据太垃圾, 或者学习率太大了 ,或者数据不够, 或者网络太渣了
神经元停止学习
- 表现是, 测试损失和训练损失下降到一定程后后都维持在一个高的位置不变
- 大概率是初始化参数的问题, 全0初始化参数会出现神经元停止学习的问题, 参考 深度学习 | (6) 关于神经网络参数初始化为全0的思考_nn.embedding初始化为全0-CSDN博客
代码参考
[!tip] 参考
入门推荐书籍📚
[!tip] 最推荐的两本书 Neural networks and deep learning 中文版是 GitHub - zhanggyb/nndl: Another Chinese Translation of Neural Networks and Deep Learning 《图解深度学习:可视化、交互式的人工智能指南》(乔恩·克罗恩(Jon Krohn))【简介_书评_在线阅读】 - 当当图书
- 然后学操作可以看 《动手学深度学习》 — 动手学深度学习 2.0.0 documentation 或者书本版
- 如果需要知道纯理论可以看看花书
GPT 原理
参数
- 每个 token 都变成一个向量 , 每个向量维度有 12288 维度

上下文输入
- 输入的 context size 为 2048 ,意味着上下文输入的 token 最大值为 2048个, 这就是为什么大模型遗忘的原因

Temperature
- 就是在输出层输出的时候 , 这个数字越大就意味着输出越平均 , 越可能选择不确定的选项(更有创造性输出)

Gemini-cli
GEMINI.md在当前目录下可以作为项目的上下文, 如果放在~/.gemini/GEMINI.md那么加载什么项目都会带上- 自定义命令的话参考 Custom commands | Gemini CLI , 主要是放在
~/.gemini/commands/里面
Qwen-code
- CLI 命令 | 千问的差不多, 一看就是抄的, 目录变成了
~/.qwen/commands/
Claude-code/Coco
- ctrl+tab 可以切换模式
- default mode: 默认模式, 什么操作都会问下
- plan mode: 只会进行计划不会实际进行操作
- allow mode: 任何写入操作都会被直接允许
- 命令行加上
--dangerously-skip-permissions可以跳过每次都要同意命令的case /rewind命令可以进行回滚代码的操作/resume可以恢复上一个session- skill 本质上也是一大堆提示词, 只不过是自助懒加载的提示词, 共享上下文, 适合上下文关联性强大, 并且对上下文影响小的(类似写个日报之类的)
- subagent 实际上就是新开一个agent 清空所有上下文, 只使用创建 subagent 设置的那些提示词进行工作(包括独立的工具和 skill), 并且过程不会影响当前上下文, 干完了才会反馈, 适合上下文关联性小, 对上下文影响大的(类似独立的代码的 review 这种)
AGENTS.md的文件内容放在仓库目录的话会被自动加载
目录介绍
- CLAUDE.md 可以存在于项目根目录 ./CLAUDE.md,也可以放在 .claude/CLAUDE.md,甚至是全局的 ~/.claude/CLAUDE.md, 相当于每次加载项目都会读的提示词
- settings.json / settings.local.json(环境与权限配置)
- commands 自定义的命令, 和 gemini code 这种差不多
- hooks 和 git 的hooks 差不多, 实际上没啥用
- skills 技能库, 挺有用的, 提示词组合成一个技能, 并且按需通过 agent 自动加载
- agents subagent 的设置, 相当于一个独立的 agent 的角色, 一半是用来角色扮演用的
- rules 这个是存放一些规则的, 如果直接放 md 进去全部加载, 如果是配置些 yaml 就是匹配上才加载
- memorys ai自动进行生成的
[!NOTE] 参考 Claude Code 从 0 到 1 全攻略:MCP / SubAgent / Agent Skill / Hook / 图片 / 上下文处理/ 后台任务_哔哩哔哩_bilibili 管理 Claude 的内存 - Claude Code Docs
微信的tablekv底层就是一个leveldb
应用场景
- 读少写多的情况
- 日志系统
- 消息队列
- 分布式储存
- 缓存
特点
- 底层使用LSM技术构建储存
- 利用了磁盘的顺序写必随机写快的多的特点
- 只提供Get,Put,Delete接口
优点
- 强大的写性能
- 强大的可靠性
缺点
- 牺牲了sql的结构化,完全退化为KV
- 牺牲一定的读性能
- 不支持多线程写入
- 生成很多文件,管理麻烦
WAL
- Write Ahead Log,写入前先写日志,至于日志的刷盘时机可以通过
- 每次写入都做一次
sync,可靠性最高,不会丢数据,但是性能最低; - 每次写入,但是不
sync,数据库崩溃不会丢数据,但是机器崩溃会丢数据,性能高,底层实现是共享内存,即使数据库崩了,内存也不会马上被回收; - 每次写入,不
sync,但是每1s做一次sync,数据库崩溃不会丢数据,但是机器崩溃丢最多1s的数据,性能较高。
- 每次写入都做一次
LSM
- Log-Structured-Merge-Tree
- 分级储存,分为在内存中的MemTable,在磁盘中的SSTable
- 有一个lru缓存用于缓存sstable的热点数据,避免多次io读取,而且是以Data Block为最小单位进行缓存
PUT流程
- 先写日志(顺序写)
- 按照key的字典序排序key,维护一个有序的map,leveldb使用跳表实现,将这个key,val插入跳表(如果已经存在直接更新)
- 判断跳表的容量是否太大,太大将memtable刷成sstable0,新建新的sstable0
- 如果sstable0的数量太多(大概十倍),会将所有的sstable归并合并成一个大的sstable1,相同的key会直接合并(取最新的),sstable1也类似
DELETE流程
- 和PUT的流程类似,只是key的状态打上delete的状态
GET流程
- 计算key的int值,在memtable中查询这个key是否存在,如果存在直接返回,
- 如果不存在,在sstable0层寻找,找不到去sstable1找,找到之后将数据加入LRU缓存,为了避免尽量避免找太多次,每个table都维护布隆过滤器,先经过布隆过滤器,再进行二分查找
索引实现
- 感觉上和B+索引的思想类似,计算索引字段对应的key值,然后构建跳表,key为计算值,val为原来的主键key,查找到主键key之后进行回表查询真实的数据
QA
为什么索引使用有序二分而不是哈希
- 存储的方面,hash磁盘的落地很麻烦,更何况还要用过链表存储解决hash冲突
- 这样设计使得范围查询和排序成为可能,hash无法范围查询
- 因为redis是内存数据库,快是主要的需求,因此用字典,和leveldb有差别
tablekv(Quorum_KV)
- 底层是leveldb,但是套了一层paxos分布式协议,保证高可用性,但是通过LSM树的形式使得具有很快的写入速度,是一个非常厉害的平衡了可用性和速度的数据库(通常这两者是冲突的),但是读的速度比较慢,但是因为微信读写比例接近1:1,因此影响不大
总结
- 很多公司最终都转型到这个数据库上面,大部分数据存储其实使用kv类型就足够了,对ACID业务型需求不是刚需
- mysql这种写入速度完全不满足需求
- redis这种满足需求了但是不可避免存在极端情况下数据丢失,因此不可能作为磁盘的持久化存储方案
- 两者一起使用时之前的解决方案,但是缺点是一致性本质上是CAP的无解问题,解决一致性麻烦太大,如果对强一致性没有太大需求,用这个也可以,但是代码负责心和出错率会增加
- leveldb属于均衡选手,牺牲本来就很快的读性能为写性能让路(在磁盘上),本身携带了缓存的系统,使得相当于将缓存和数据进行了结合,,具有极强的写性能和较强的读性能,因此很多公司最后的数据库选型都是这种
组件对比
| 公司 | 字节 | 腾讯 |
|---|---|---|
| 组件 | abase | tablekv |
| 底层 | RocketDB(底层也是LevelDB改编而来) | LevelDB |
| 上层组件 | 上层通过类似 slots 分配的形式, 每个负责处理的集群再通过主从复制的方式实现一致性的, 只能保证最终一致性, 本质上和 redis的多集群方式类似 redis实现 | 套了一层 paxos 协议, 能够保证强一致性 |
参考
- https://juejin.cn/post/7123922716419178526
- https://zhuanlan.zhihu.com/p/206608102
- https://zhuanlan.zhihu.com/p/361699941
基础操作
连接
mongo admin --host ip --port port
密码验证
- use databasename
- db.auth('name','password')
- mongo密码是在使用某个数据库后才认证的,和mysql不一样
查询
db.collection.find(query, select)
- projection是可选参数,指定了那些字段是需要返回的,若要返回所有字段则不必要指定该参数。
- db.col.find({"name":"chenxuan"}) find by key
- db.col.find({$or:[{"name":"chenxuan"},{"year": 18}]}).pretty() find by or
- db.col.find({"likes": {$gt:50}, $or: [{"name":"chenxuan"},{"year": 18}]}).pretty()
查询可接后缀
- count 统计数量
- pretty 格式化
- limit 限制
- skip 偏移
- sort 排序 sort({KEY:1/-1})
更新
- db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}})
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
- query : update的查询条件,类似sql update查询内where后面的。
- update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
- upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
- multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
- writeConcern :可选,抛出异常的级别。
删除
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
参数说明:
- query :(可选)删除的文档的条件。
- writeConcern :(可选)抛出异常的级别。
deleteMany 相当于jsutOne=false
插入
- db.collection.insertOne()
- db.collection.insertMany()
数据库
- 查询现在数据库
db - 创建新的
use dataname - 删除数据库`db.dropDatabase()``
集合
- 创建
db.createCollection(name) - 删除
db.createCollection(name, options)
管道
lookup
两个集合匹配字段
{
$lookup:
{
from: <collection to join>,
localField: <field from the input documents>,
foreignField: <field from the documents of the "from" collection>,
as: <output array field>
}
}
|from|要联合的另外集合名字| |localField|目前集合的匹配键| |foreignField|另外集合匹配键| |as|作为输出的字段名|
- 注意as生成字段名作为一个数组而不是单个文档,需要用unwind解开
unwind
- { $unwind: field path }
project
- 指定输出的字段
- { $project: { specification(s) } }
match
- 相当于find
- { $match: { $expr: { aggregation expression } } }
addFields
- 添加新的字段值
{
$addFields: {
totalHomework: { $sum: "$homework" } ,
totalQuiz: { $sum: "$quiz" }
}
},
特点
- 面向文档的存储:MongoDB以BSON格式存储数据,支持存储复杂的数据结构,如嵌套文档、数组等。
- 动态模式:MongoDB不需要事先定义数据模型,可以随时添加新的字段和属性,非常适合快速迭代和变更的数据场景。
- 高性能:MongoDB使用内存映射文件存储数据,可以实现高效的读写操作。同时,它支持水平扩展,可以通过增加节点来提高系统的整体性能。
- 丰富的查询语言:MongoDB提供了强大的查询语言,支持丰富的查询操作符和聚合管道,方便进行数据分析和处理。
应用场景
- 整体上来说文档形式数据库适合复杂的,非结构化的,易变的存储需求
- 存储云文档这种变更频繁,格式复杂的内容
- 使用云数据库MongoDB存储用户信息以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能,并且可以作为点赞列表翻到这条朋友圈中。并且,云数据库MongoDB非常适合用来存储聊天记录,因为它提供了非常丰富的查询,并在写入和读取方面都相对较快。
- 使用云数据库MongoDB存储订单信息,订单状态在运送过程中会不断更新,以云数据库MongoDB内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来
总结
- mongdb舍弃的ACID的事务和传统数据库的sql,换取了更加灵活的的保存信息的内容(类似json的格式),使得更加快速的读取和写入,而且开发起来更加简单
- 缺点是作为磁盘非kv数据库无法自持
参考资料
基本结构

运行流程
页结构


结构
- 每个页通过双向链表连接下一个和上一个页,因此页与页之间不需要物理上联系(及不需要一定使用连续磁盘空间)FIL_PAGE_PREV,FIL_PAGE_NEXT
- 页的大小统一为16kb,空闲区域如果分配完后会申请新的页
- 插入的数据不会引起重新排列,由于行数据库有单链表,因此只会修改链表的指向
- 每个页都存在页头和页尾
- 都存在校验和,用于检验页是否被完整传输
页目录
- 在页尾上面,本质是索引
- 每最多8条记录成为一个槽,每个槽记录8条记录中最大的地址,对槽之间查找可以使用二分搜索
类型
- 数据页(B-tree Node)
- undo页(undo Log Page)
- 系统页 (System Page)
- 事物数据页 (Transaction System Page)
- 插入缓冲位图页(Insert Buffer Bitmap)
- 插入缓冲空闲列表页(Insert Buffer Free List)
- 未压缩的二进制大对象页(Uncompressed BLOB Page)
- 压缩的二进制大对象页 (compressed BLOB Page)
行结构
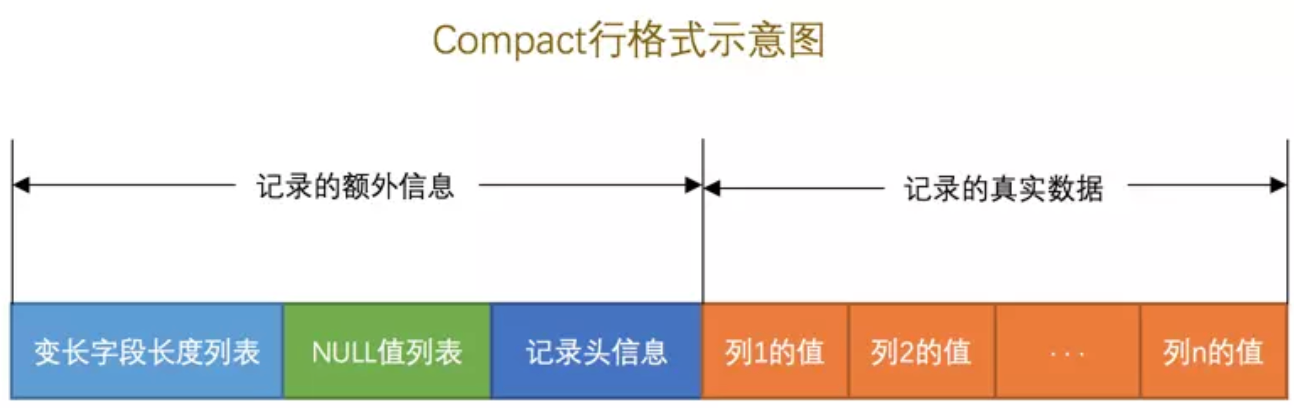
结构
- 页最少两行,分别是头和尾,不存真实数据
- 被删除的行会组成一个垃圾链表
记录头
记录头信息固定占用5个字节也就是40位,不同位代表不同信息,主要有:
- delete_mask 标记该记录是否被删除
- record_type 表示当前记录的类型 0表示普通记录,1表示B+树非叶子节点记录,2表示最小记录,3表示最大记录
- next_record 表示下一条记录的相对位置
删除行时,会先修改next_record为垃圾链表,而不会直接断开
真实数据首列
隐藏列中的信息因为与事务和主键有关,所以很重要,总共占用19个字节,有三列:
- row_id (不必须) 替补主键id
- trx_id 事务id
- roll_pointer 回滚指针
优先使用用户自定义主键作为主键,如果用户没有定义主键,则选取一个
Unique键作为主键,如果表中连Unique键都没有定义的话,则InnoDB会为表默认添加一个名为row_id的隐藏列作为主键。
Null值列表
- 某个列如果为NULL,则直接置位(节省空间)
可变长度列表
- 每个最大两个字节(2^16=65535 每个字符最多4个字节,varchar最大为16383字符)
- 如果存储太大,数据会直接放到溢出页之中,本体只储存溢出页的地址
类型
- Dynamic (5.7.0默认)
- Compact
- Compressed
索引
为什么用B+树
- 二叉树高度太高
- B树(实际上就是二叉树中单节点多个值降低高度)范围查找麻烦(跨层),查询效率不稳定(因为结果可能在不同层)
为什么不用跳表
- B-tree索引可以有效地利用磁盘I/O,主要是因为B-tree索引的节点大小和磁盘块大小相当,跳表不可以
- 访问时间不稳定,因为跳表的索引方法有随机成分
- 只能在单个维度上进行排序,不适合多维范围查询
- 跳表的性能表现更依赖于内存的访问速度(因为需要通过指针访问地址,所以需要全部加载到内存中),对于磁盘存储的数据库来说,跳表不如B-tree
B+树
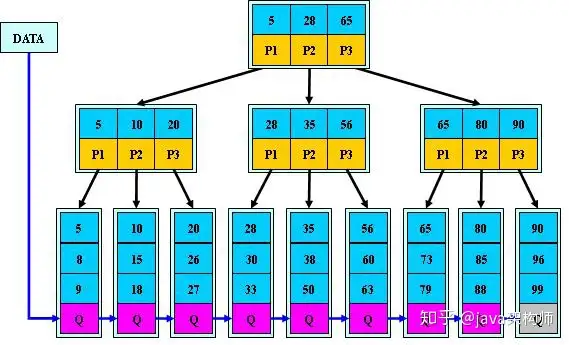
- 所有数据存储在最底层,解决查询效率不一致问题和高度
- 所有的节点都是页,父节点的页的行类型为索引,而且父节点不存储数据,只存储key和下一层页的指针(节约空间)
聚簇索引和非聚簇索引
- 数据库会建立key索引(对于每张表),如果额外出现索引,那么索引的key为要索引的值,val为key
- 非聚簇索引拿到key后还要用key再次在自动生成的索引中再次寻找
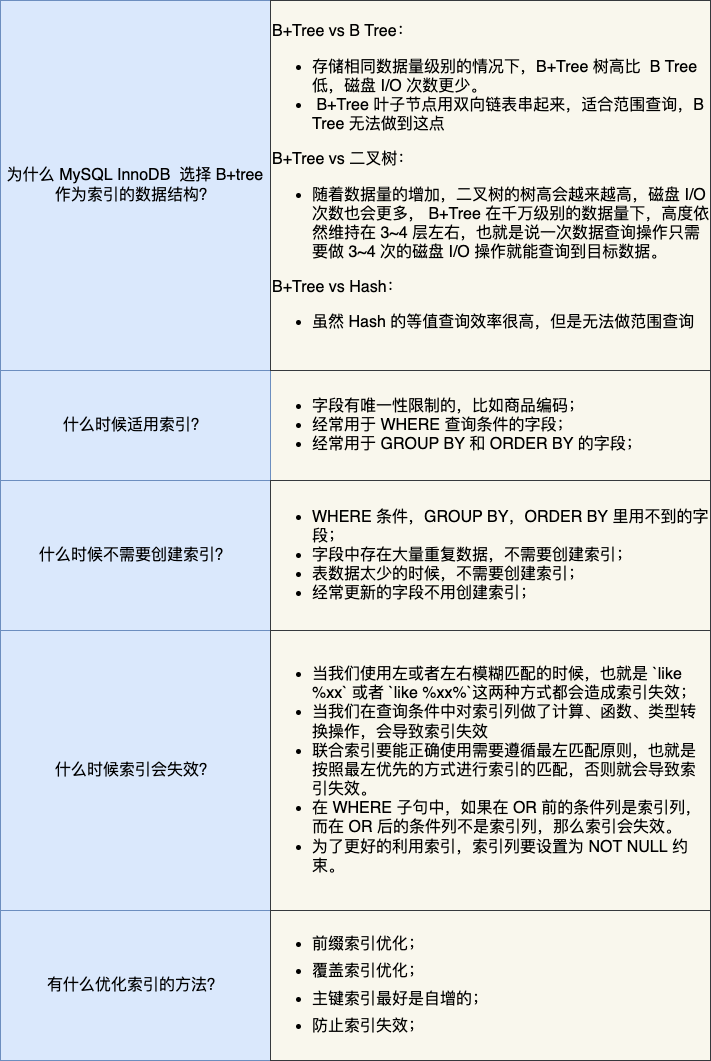
联合索引
- index(a,b,c)为例建立这样的索引相当于建立了索引a、ab、abc三个索引
- 这部分是局部有序的,例如下面,a是有序的,当a相同时候,b是有序的
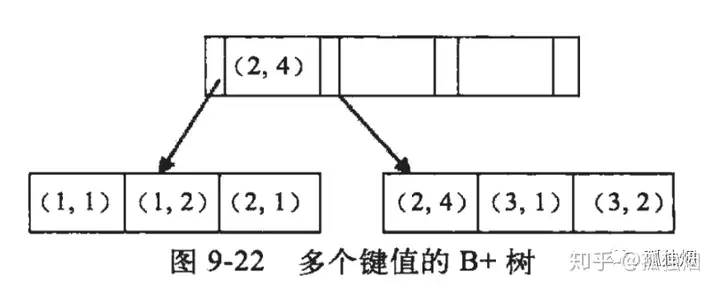
最左匹配原则
- 在 InnoDB 中联合索引只有先确定了前一个(左侧的值)后,才能确定下一个值。如果有范围查询的话,那么联合索引中使用范围查询的字段后的索引在该条 SQL 中都不会起作用
- 意味着重要的有辨识度的字段建立索引的时候需要放在前面(比如姓名)
重要参考
- https://zhuanlan.zhihu.com/p/115778804
覆盖索引
- 普通索引(也叫做二级索引)的查找方式为在普通索引下找到底层之后,拿到key,使用这个key回表查询,如果需要避免回表查询,需要使用覆盖索引,其实只是一种特殊的索引
- 覆盖索引不需要回表查询因为该缩影底层已经包含了需要被查询的数据,==核心是建表的时候二级索引使用联合索引,把需要找到的字段都包含在联合索引中,这样就不需要回表查询==
example:
select a,b,c from table where a=10 and b>10这条语句使用index(a,b,c)可以使用到索引,index(b,a,c)也可以,但是index(c,a,b)不可以
稀疏和稠密索引
- 稠密索引:在密集索引中,数据库中的每个搜索键值都有一个索引记录。这样可以加快搜索速度,但需要更多空间来存储索引记录本身。索引记录包含搜索键值和指向磁盘上实际记录的指针。

- 稀疏索引: 在稀疏索引中,不会为每个搜索关键字创建索引记录。此处的索引记录包含搜索键和指向磁盘上数据的实际指针。要搜索记录,我们首先按索引记录进行操作,然后到达数据的实际位置。
- 这两种索引都要通过折半查找或者叫做二分查找来确定数据位置,不同的是密集索引,只需要通过二分查找到搜索值=索引的索引记录就能确定准确的数据位置,而稀疏索引则需要先定位到搜索值>索引值的最小的那个,然后在通过起始位置去定位具体的偏移量。
- 在大多数场景密集索引查询效率更高,在大多数场景稀疏索引占用空间更小。
- mysql中密集索引决定了表的物理排列顺序,所以一个表只能有且仅有一个密集索引
- 稀疏索引适用于具有大量重复值的列,或者具有大量空值的列。它可以显著减小索引的大小,从而提高查询性能,并减少存储空间的占用。
事务
Atomic原子性
- 事务不可分割,最小操作单元,要么一起成功,要么一起不成功
- 使用undolog保证
undolog
- 使用的是物理记录而不是逻辑记录
- 用于事务失败时候的回滚
- 原始数据会记录在undolog中,然后把修改后的数据事务版本号改成当前事务版本号,并直接修改数据,并把DB_ROLL_PTR 地址指向undo log数据地址
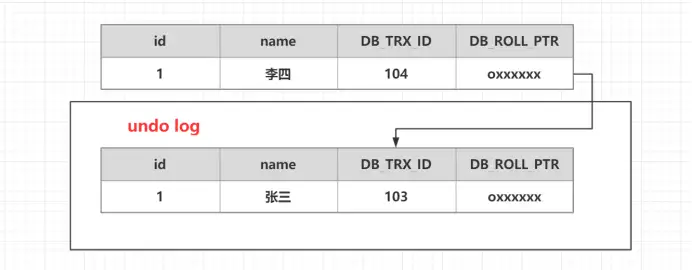
Isolation隔离性
- 事务之间相对隔离,不能相对干扰,不能查看彼此未提交的数据
- 写和写的隔离使用锁,写和读的隔离通过MVCC
查询类型
快照读
- 简单的select操作,属于快照读,不加锁。它读的是记录的快照版本(这个版本跟MVCC有关)
当前读
- 要加锁的特殊的读操作,它读的是记录的最新版本.
-- 共享读锁
select * from table where ? lock in share mode;
-- 排他锁
select * from table where ? for update;
-- 增删改也属于当前读,因为要先看这条记录在不在
insert into table values (…);
update table set ? where ?;
delete from table where ?;
锁

乐观锁,悲观锁
[!important] 优缺点 乐观锁的缺点在于大量并发时候失败次数多,冲突失败概率高,优点是无锁化,运行速度快(在没多少冲突情况下),适用于冲突少的 悲观锁缺点是需要上数据库级别锁,速度慢,优点是失败概率低,适用于冲突多的
- 乐观锁使用类似于version检测的办法(类似状态机),在修改的时候判断状态,
update ... where version=1 - 悲观锁使用行锁,直接锁定该行不能修改,
select …for update,悲观锁的实现→ 参考
共享锁S,排他锁X
- 都是悲观锁,和读写锁类似
Gap Lock间隙锁
- 只存在于可重复读隔离级别,目的是为了解决可重复读隔离级别下幻读的现象。
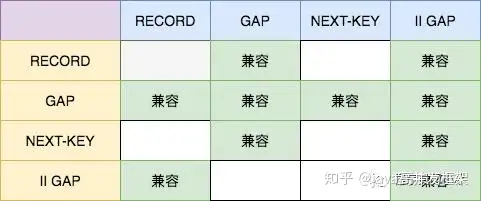 >假设,表中有一个范围 id 为(3,5)间隙锁,那么其他事务就无法插入 id = 4 这条记录了,这样就有效的防止幻读现象的发生。
>间隙锁的意义只在于阻止区间被插入,因此是可以共存的。一个事务获取的间隙锁不会阻止另一个事务获取同一个间隙范围的间隙锁,共享(S型)和排他(X型)的间隙锁是没有区别的,他们相互不冲突,且功能相同。
>假设,表中有一个范围 id 为(3,5)间隙锁,那么其他事务就无法插入 id = 4 这条记录了,这样就有效的防止幻读现象的发生。
>间隙锁的意义只在于阻止区间被插入,因此是可以共存的。一个事务获取的间隙锁不会阻止另一个事务获取同一个间隙范围的间隙锁,共享(S型)和排他(X型)的间隙锁是没有区别的,他们相互不冲突,且功能相同。
加锁过程
- select分为当前读和快照读两种类型,除非加上share或者for update为加S或者X锁,其他都为快照读,不加锁
- update,insert,delete都是当前读,会插入插入意向锁,插入成功之后,上行锁,和gap互相排斥
- 记录锁永远都是加在索引上的,即使一个表没有索引,InnoDB也会隐式的创建一个索引,并使用这个索引实施记录锁。
锁实现原理
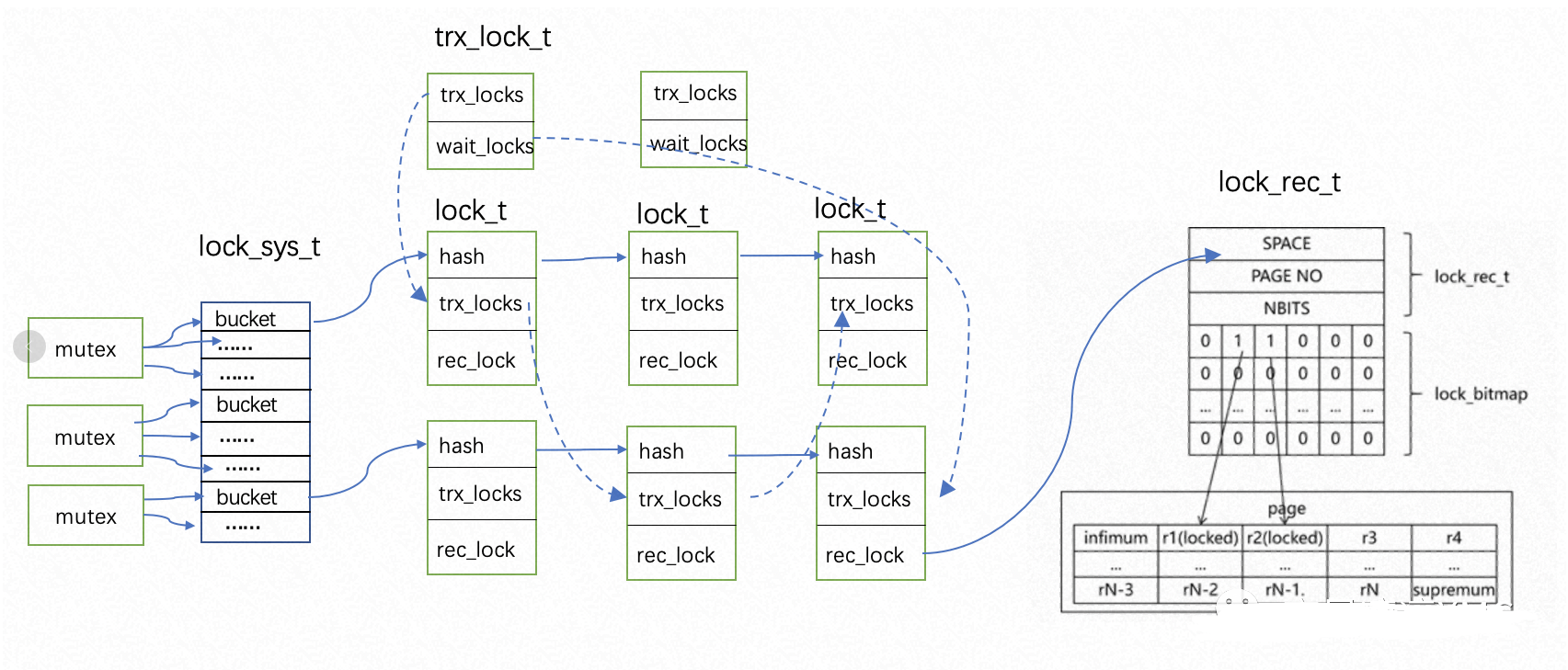
-
每个事务都有一个链表,链表的元素就是锁,通过这样事务可以快速遍历所有自己加的锁.每个锁结构体都记录有自己所在的page
每个事务会维护一个trx_lock_t的结构体,其中trx_locks指向lock_t的链表,通过lock_t的trx_locks双向链表从而将属于同一个事务持有的锁串联起来,因为一个事务有可能在多个page上面持有锁。另外如果一个事务被阻塞,wait_locks指向阻塞的lock_t。
-
通过计算某一行所在的表空间(space),空间中的数据页码(page_no),通过hash计算属于某个bucket(通过拉链法解决hash冲突的问题),通过遍历bucket的元素(一定需要遍历所有,因为一个page可能嫁了很多个锁)并判断是否是同一个page
通过维护一张lock_sys的hash table将所有的lock_t组织起来,根据(space,page_no)通过hash算法计算出一样的hash value 将会放在同一个bucket中,因为hash算法的局限性,不同的(space,page_no)有可能生成同样的hash value,我们知道解决hash冲突通常都是后面拉出一张链表,所以很自然的同一个bucket中的lock_t组成一个链表结构
-
每个lock_t存放了bitmap,每个位对应每一行数据,如果行对应的bit为1说明已经被上锁
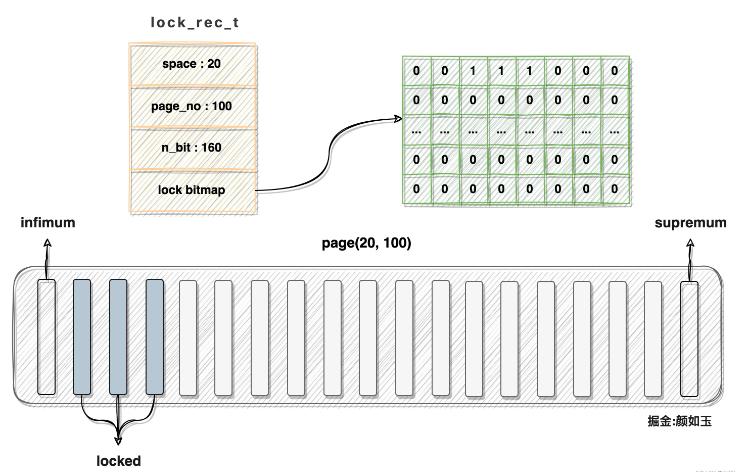
脏读,不可重复读,幻读
- 脏读:读到其他事务还没有提交的数据
- 不可重复读:同一个数据开始读和再次读结果不一样
- 幻读:每次查询到之前没有的数据
不可重复读和幻读区别,不可重复读针对的是update,即对同一行的数据进行操作 幻读针对delete和insert,每次select结果不同,即对一张表进行操作 不可重复读可以通过行锁解决,或者通过乐观锁 幻读需要通过表锁解决
读未提交,读已提交,可重复读,串行读
- 分别对应解决上面三个问题
- mysql默认可重复读,oracle默认读已提交
- RR依旧存在在写场景下的幻读,详情参考
主流方式是使用读已提交,mysql使用的有历史的原因
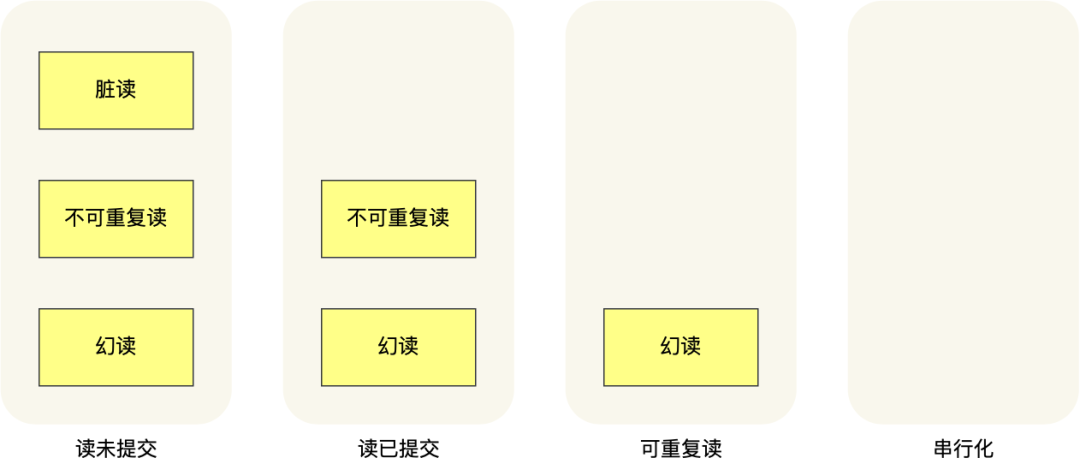
MVCC
- 这种通过「版本链」来控制并发事务访问同一个记录时的行为就叫 MVCC(多版本并发控制)
- 通过版本链控制
- 核心思想尽量避免使用锁
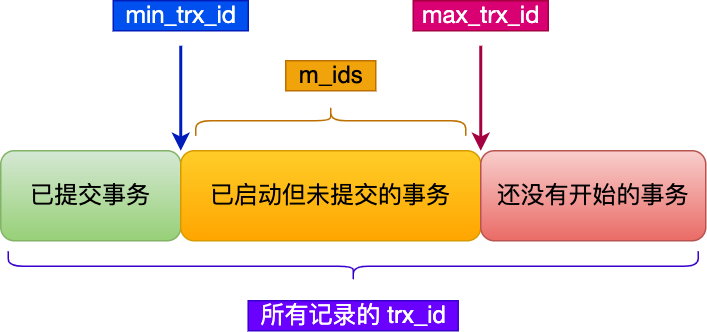
- readview实际上就是,一个固定的数组,记录事务号的信息
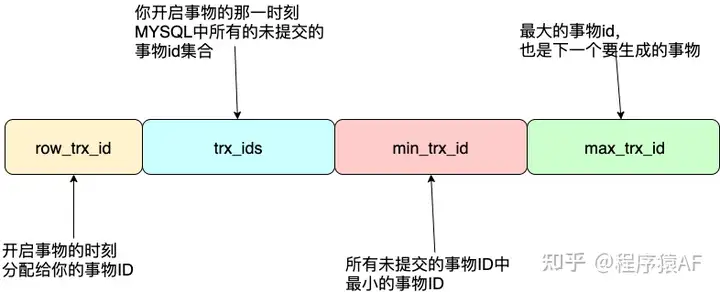
RC和RR流程
- RC中只使用mvcc,不使用gap等锁,只是相当于在undolog中读取提交了事物的快照,RC读取的时候始终读取已提交事务,因此可能出现不可重复读的问题
- RR中只使用mvcc,mvcc中读取事务号小于等于的快照,解决部分幻读问题和不可重复读问题,不上锁依然有幻读问题,快照读的时候使用mvcc(记录第一次读的版本号),因此不出现重复读的问题,RR中涉及当前读的都默认加X锁
- 当前读在 RR 和 RC 两种隔离级别下的实现不一样:RC 只加记录锁,RR 除了加记录锁,还会加间隙锁,用于解决幻读问题。
- 使用gap间隙锁(for update),将查询范围锁定,避免插入和删除(插入意向锁互斥)可以解决幻读问题,仅仅只使用RR不能彻底解决幻读问题
- RC下每一行执行期前重新生成新的readview,因此每次读的都是commit的信息,RR下整个事务执行前生成一次readview,并且整个事务都是这个readview,读的是开启前的commit信息
- update在RC或者RR模式下都会直接加锁,因为要update,直到commit或者rollback,但是RU不会
对于MySQL默认的InnoDB存储引擎而言,在大多数情况下,UPDATE操作都会在更新行上加上排它锁(X锁),这意味着其他事务将无法同时访问该行,直到该事务提交或回滚。因此,在所有事务隔离级别下,都会对被更新的行加锁。 但是,这种锁的类型和范围是受隔离级别影响的。在读取未提交的数据(READ UNCOMMITTED)隔离级别下,其他事务可以读取并修改该行,而在可重复读(REPEATABLE READ)和串行化(SERIALIZABLE)隔离级别下,其他事务将无法读取或修改该行,直到当前事务完成。
Durable持久性
- 事务一旦提交,不会因为外部意外发生变化
- 如果是内存buffer还没写入磁盘就崩了,通过redolog恢复,写道一半崩了导致不完整传输,通过双写缓冲区
redolog
- 相当于在页写入之前先写入redolog buffer,然后redobuffer写入redolog file比页刷入磁盘快(这部分因为redolog是顺序写,表页是随机写,因此写这个更加快)
- redolog作为类似环形缓冲区,通过指针位移进行刷新

- binlog 是追加写,写满一个文件,就创建一个新的文件继续写,不会覆盖以前的日志,保存的是全量的日志。用于备份恢复、主从复制.写的是逻辑
- redo log 是循环写,日志空间大小是固定,全部写满就从头开始,保存未被刷入磁盘的脏页日志。用于掉电等故障恢复.因为 redo log 文件是循环写,是会边写边擦除日志的,只记录未被刷入磁盘的数据的物理日志,已经刷入磁盘的数据都会从 redo log 文件里擦除。写的是实际二进制数据
策略
- 当设置为0,完全不管,等后台1s一次的自动刷,最多丢失1s的记录
- 设置为1,每次提交确认落盘,影响性能,能确保不丢失
- 设置未2,写入os的cache page,操作系统自己决定何时写入,mysql崩没问题,但是操作系统崩会损失记录
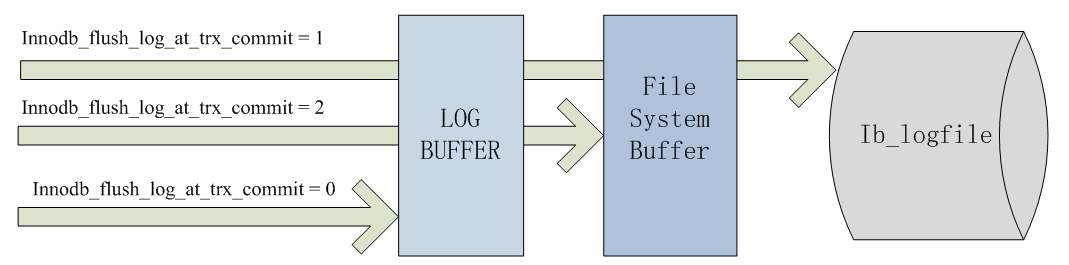
双写缓冲
- 因为mysql页大小和系统页大小不一样,有可能页传输到一半就崩了
- doublewrite缓冲区是一个硬盘存储区域,
InnoDB在将从缓冲池中刷新的page写到InnoDB数据文件中相应的位置之前,会先将这些page写在doublewrite缓冲区。如果在写page的过程中出现了操作系统、存储子系统或意外的进程退出等情况,InnoDB可以在崩溃恢复过程中从doublewrite缓冲区中找到一个完整且正确的page副本
Consistency一致性
- 无论多少事务同时执行以及任何操作,执行前,过程中,执行后的状态都是一致确定的
- 上面三条满足自动满足
日志
binlog
- 在innodb上层的日志系统,并非innodb生成
顺序
写redo 预提交日志 写binlog 日志 写redo conmit日志 redo有两条记录
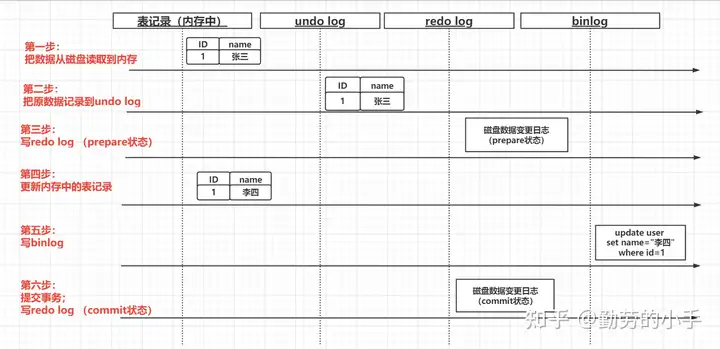
格式区别
- binlog
- 逻辑记录,不可用于崩溃恢复
UPDATE `db_test`.`tb_user` WHERE @1=5 @2='赵白' @3=91 @4='1543571201' SET @1=5 @2='赵白' @3=18 @4='1543571201'
UPDATE `db_test`.`tb_user` WHERE @1=6 @2='赵白' @3=91 @4='1543571201' SET @1=5 @2='赵白' @3=18 @4='1543571201'
UPDATE `db_test`.`tb_user` WHERE @1=7 @2='赵白' @3=91 @4='1543571201' SET @1=5 @2='赵白' @3=18 @4='1543571201'
- redolog
- 物理记录,可以用于崩溃恢复
把表空间10、页号5、偏移量为10处的值更新为18。
把表空间11、页号1、偏移量为2处的值更新为18。
把表空间12、页号2、偏移量为9处的值更新为18。
- undolog
- 记录修改前的原始数据内容,并用指针连接
三大特性
insert buffer
- 用于更新非聚簇索引的,当更新数据时候,一般年需要同时更新索引,但是当索引B+树不在buffer中时,从磁盘读取非常慢
- 因此先写入insert buffer,然后下次加载索引B+树或者定时任务时候在合并到索引中
自适应hash
- innodb存储引擎有一个机制,可以监控索引的搜索,如果innodb注意到查询可以通过建立哈希索引得到优化,那么就可以自动完成这件事.
双写缓冲区
主从复制
- 底层实际上和redis的AOF备份类似,底层使用keepalive保证主从切换
- master服务器将数据的改变记录二进制binlog日志,当master上的数据发生改变时,则将其改变写入二进制日志中;=
- slave服务器会在一定时间间隔内对master二进制日志进行探测其是否发生改变,如果发生改变,则开始一个I/OThread请求master二进制事件
- 同时主节点为每个I/O线程启动一个dump线程,用于向其发送二进制事件,并保存至从节点本地的中继日志中,从节点将启动SQL线程从中继日志中读取二进制日志,在本地重放,使得其数据和主节点的保持一致,最后I/OThread和SQLThread将进入睡眠状态,等待下一次被唤醒。
keepalive
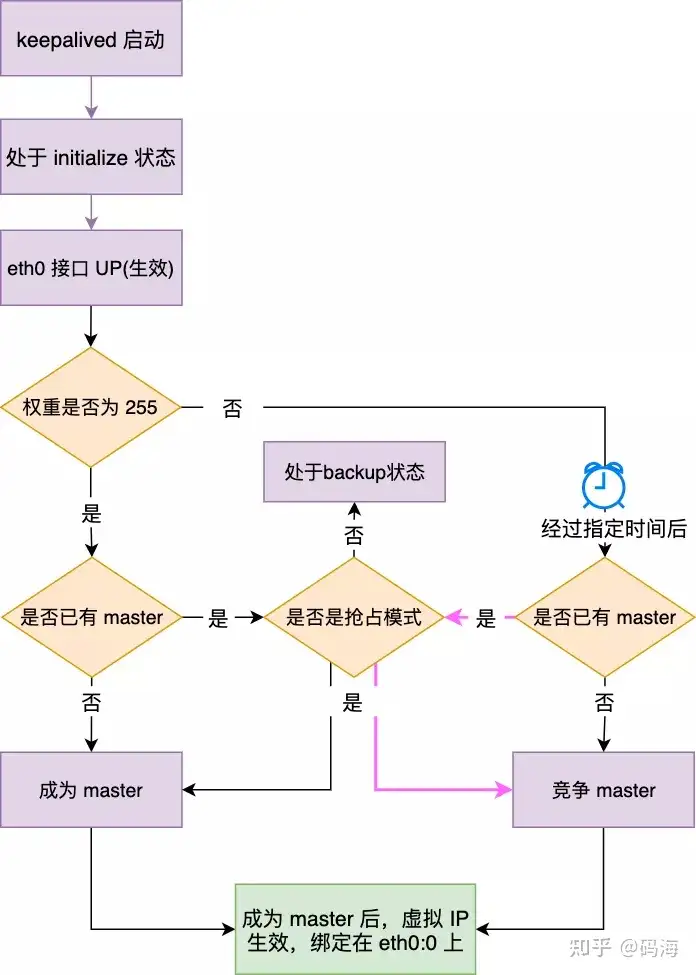
过程
- master需要向所有的slave群发包,如果slave发现太久没有master发送,断定为master宕机,选举出新的master
- 选举过程中slave会交换权重,然后比较权重大小选举出性的master(这里可能出现脑裂问题)
- 发送ARP包给路由器,为了更新由器上的 ARP 缓存,将虚拟 IP 对应的 mac 地址更新为竞选 master 成功的 backup 上的 mac
参考
- https://juejin.cn/post/6974225353371975693
- https://zhuanlan.zhihu.com/p/142139541
- https://www.cnblogs.com/shoshana-kong/p/10516404.html
- https://juejin.cn/post/6931752749545553933
- https://zhuanlan.zhihu.com/p/213770128
- https://zhuanlan.zhihu.com/p/382010436
- https://www.yasinshaw.com/articles/109
- https://www.modb.pro/db/542415 推荐书籍
- MySQL技术内幕:InnoDB存储引擎
本质上就是图数据库的底层原理,和neo4j同类型的数据库
存储
方法
- 切边法:每个顶点都存储一次,但是有的边会被打断分到两台机器上。这样做的好处是节省存储空间;坏处是对图进行基于边的计算时,对于一条两个顶点被分到不同机器上的边来说,需要跨机器通信传输数据,内网通信流量大(因为查询的时候跨机房大量查询边。
- 切点法:每条边只存储一次,都只会出现在一台机器上。邻居多的点会被复制到多台机器上,增加了存储开销,同时会引发数据同步问题。好处是可以大幅减少内网通信量。
- neo4j和 ByteGraph 使用的都点是切点法
- 两种存储计算模式「原生图」和「非原生图」
- 底层的数据存储格式是否Graph-like,简而言之即以图的形式存储图,Native Storage通过将节点和关系写入到“相近”的位置来保证高效地存储,而使用外部存储时(如:外部的DB)认为是Non-Native。
- ByteGraph目前是典型的依赖于KV(ABase/ByteKV)的 非原生图 数据库
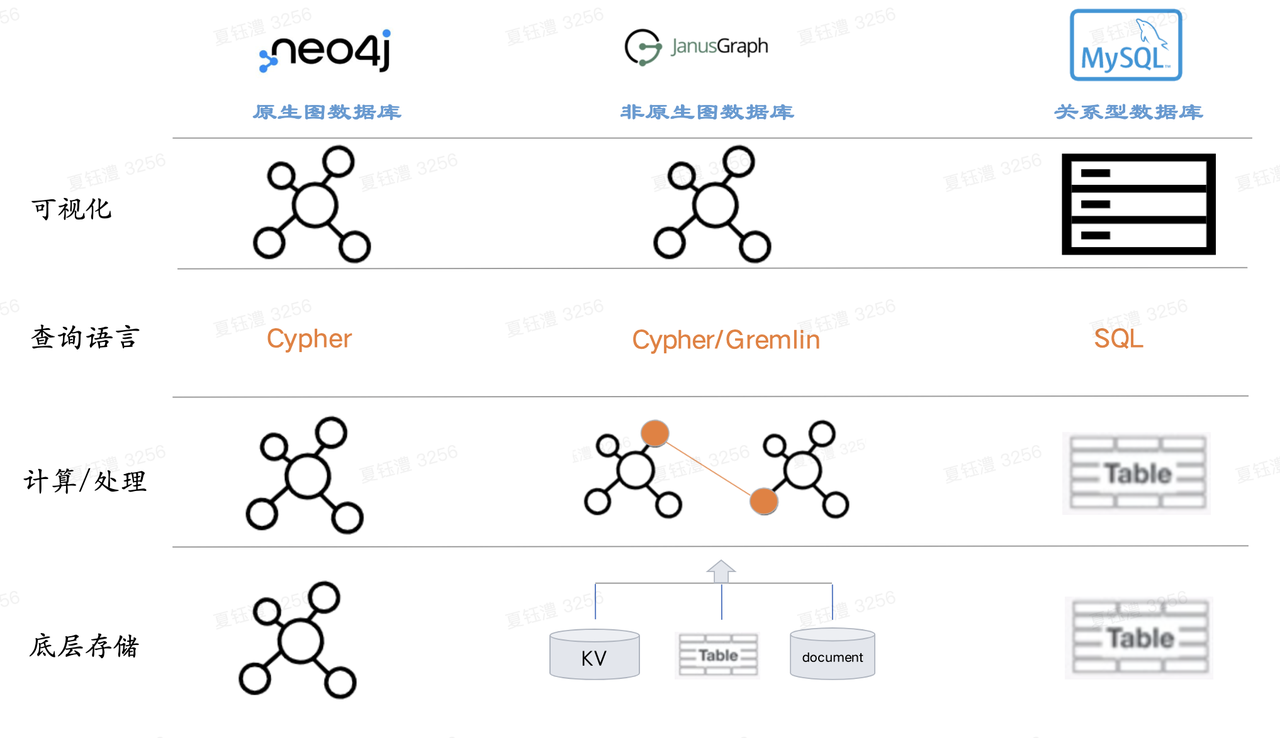
文件
- neostore.nodestore.db:存储 node
- neostore.propertystore.db:存储属性
- neostore.relationshipstore.db:存储关系
- 节点作为node,node之间的关系使用
- 1byte:in-use flag,表明该 node 是否在使用
- 4byte:第一个 relation id(-1表示无)
- 4byte:第一个 property id(-1表示无)
- 5byte:label 信息(可能直接 inline 存储)
- 1byte:reversed
- 节点(指向联系和属性的单向链表,neostore.nodestore.db):第一个字节,表示是否被使用的标志位,后面4个字节,代表关联到这个节点的第一个关系的ID,再接着的4个字符,代表第一个属性ID,后面紧接着的5个字符是代表当前节点的标签,指向该节点的标签存储,最后一个字符作为保留位 .
- 关系(双向链表,neostore.relationshipstore.db):第一个字节,表示是否被使用的标志位,后面4个字节,代表起始节点的ID,再接着的4个字符,代表结束个节点的ID,然后是关系类型占用5个字节,然后依次接着是起始节点的上下联系和结束节点的上下节点,以及一个指示当前记录是否位于联系链的最前面.
- 节点中存储了关系开始的id 和属性开始的id,因为是定长存储,根据id可以直接拿到地址,相当于O(1),再根据关系的双向链表查到所有有关这个点的所有边
- 其实最大的区别在于 图数据库查关系是直接使用广度有限搜索算法的,可以根据id直接定位开始的edge,根据双向链表直接定位到所有的egde,不需要像关系型数据库慢慢查,这点的优势直接体现在可以简单直接找到关注的关系以及共同关注之类的需求
- 属性边和点都是分开存储的,因为定长存储,存储的是id,可以直接根据id算偏移,直接拿到数值点
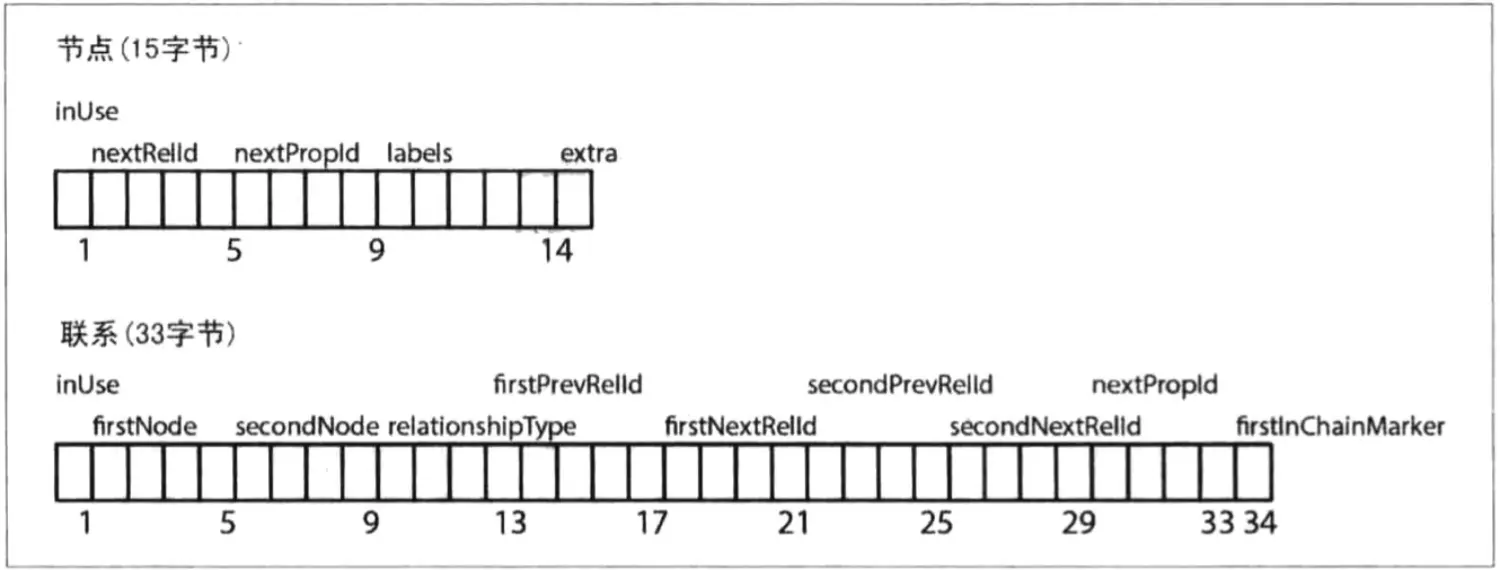
架构
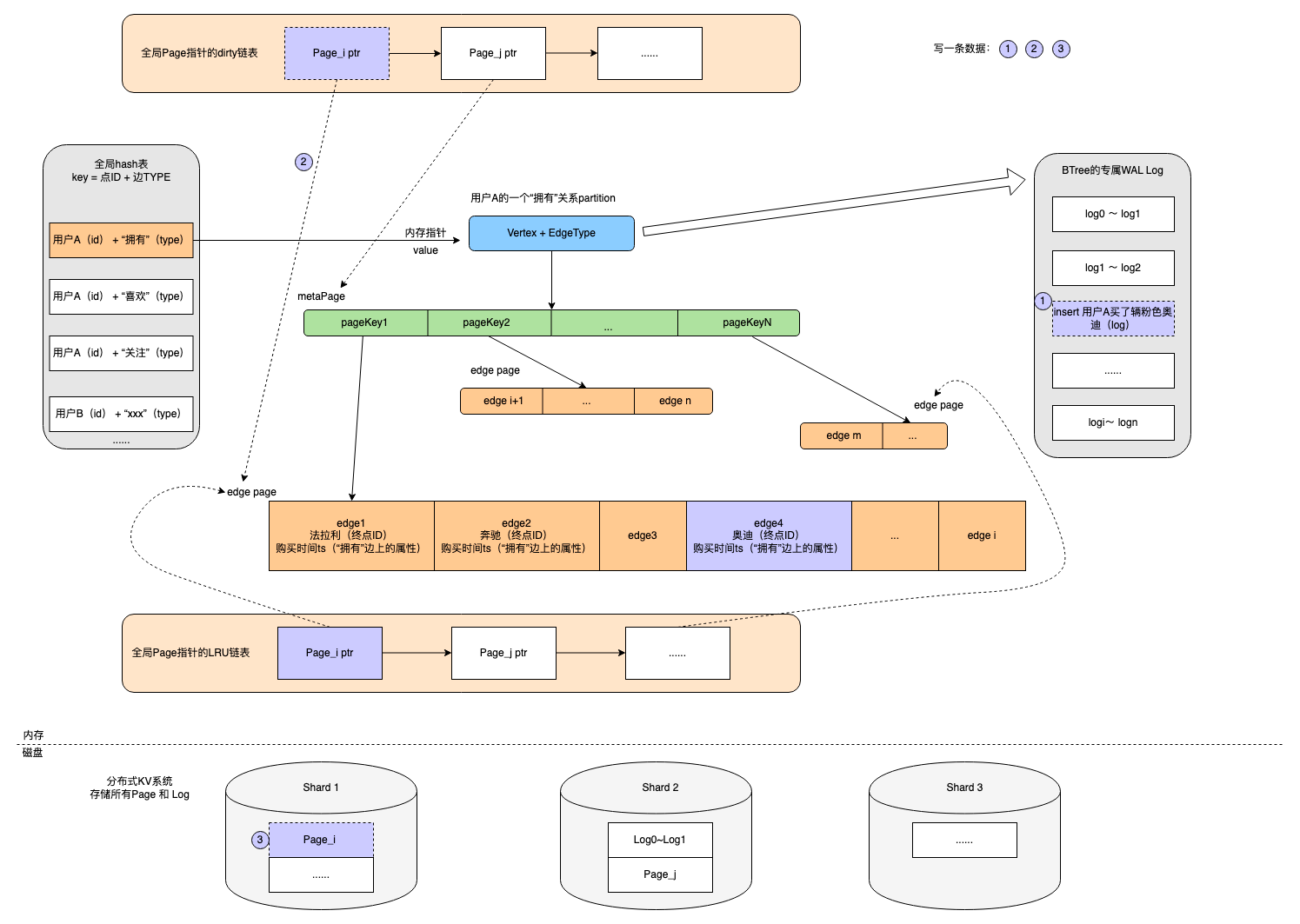
- ByteGraph采用切点法划分出不同的partition,一个partition包含一个起点+所有同类项的出边(包括边属性和终点)。目前BG将起点ID做hash,将不同partition存储在不同的GS节点中。
- 全局hash表
- key可以理解为顶点ID+边类型构成的一个唯一值,value则指向一个partition,实现了确定某个点后快速检索定位对应partition的能力。(因为日使用点切法,同一个点多个 partition,只能使用点+edge属性作为key,相同属性的边存储在同一个partition)
- 节点全局hash表(每个GS实例一份),由于采用「点切法」的原因,点的相关属性信息不可避免的被冗余到不同的「partition」中,为了减少冗余,图中所有点相关信息采用一份全局存储,各个「partition」中仅仅记录点的ID
- 在内存中,partition被组织为BTree模式,其中Btree的根节点和叶子节点在内存中被组织为Page的模式(这里使用btree的原因是不可能能一次拿到包含所有edge的内存拿来一次新存放,太大了,通过组织Btree来进行索引),具体包括以下page:
- metaPage:非叶子节点,存储指向子节点的内存指针,作为BTree的索引节点
- 叶子节点,存储边数据(终点ID+边上的属性),每个page存储边的数量可供配置
- 全局LRU链表中存放指向Page的指针,Page分布于每一个partition的Btree结构中。其中Page按需加载到内存,全局LRU链表对解决数据的冷热沉降非常实用。非热点数据直接存放于磁盘,热点数据常驻内存。
- 全局dirty链表
- dirty链表中存放的是刚刚被修改的Page指针,在数据发生修改的过程中会经历4步如图。
- 内存中的page与磁盘中的page数据采用异步方式同步,会出现数据不一致的现象,对于同一个page的多次写可以一次i/o完成。
- WAL LOG
- 每个Partition/Btree都维护自己的一个WAL log(redo log), 每次写入搭配全局Dirty链表可以实现与磁盘的异步交互。若干条 log会聚合成一个类似Page的结构便于磁盘统一存储
- 在BG中partition的各个结构,BTree、WAL Log等都被组织为Page的模式,底层的磁盘也正是按照这种Page的组织方式来存放数据。Key为顶点ID+边类型+pageKey,value为page内容
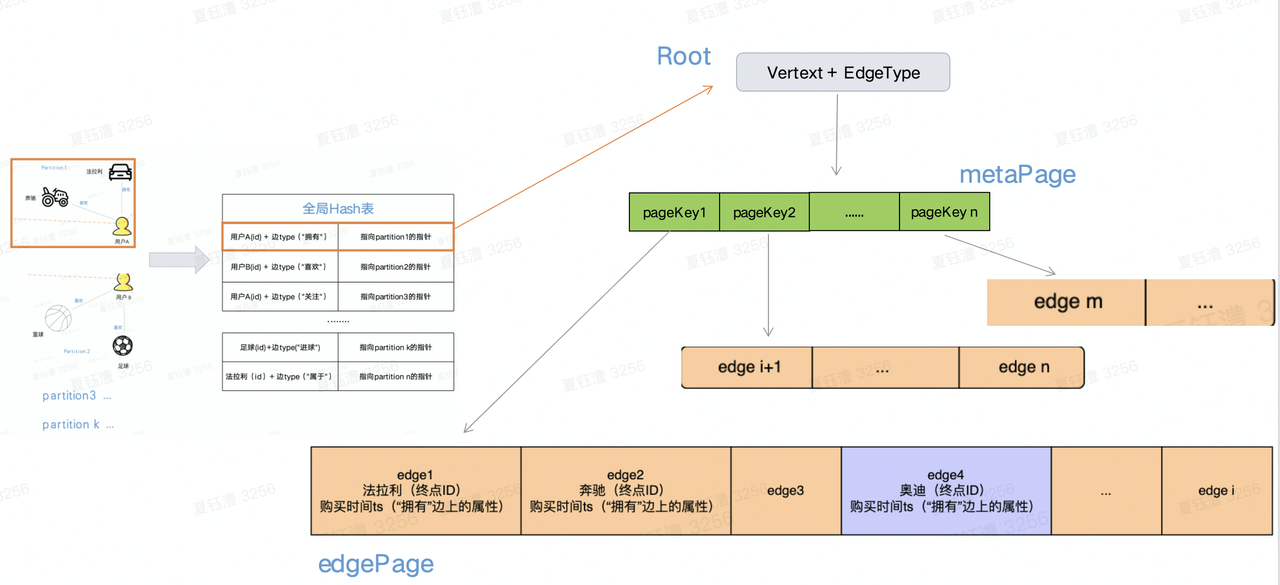
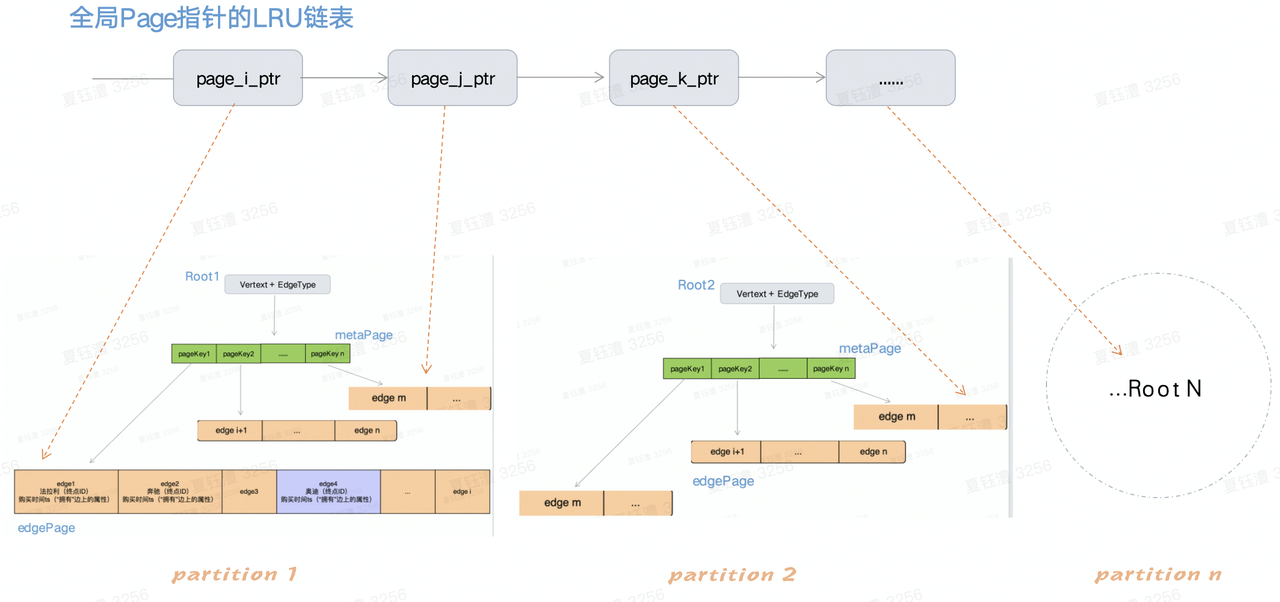
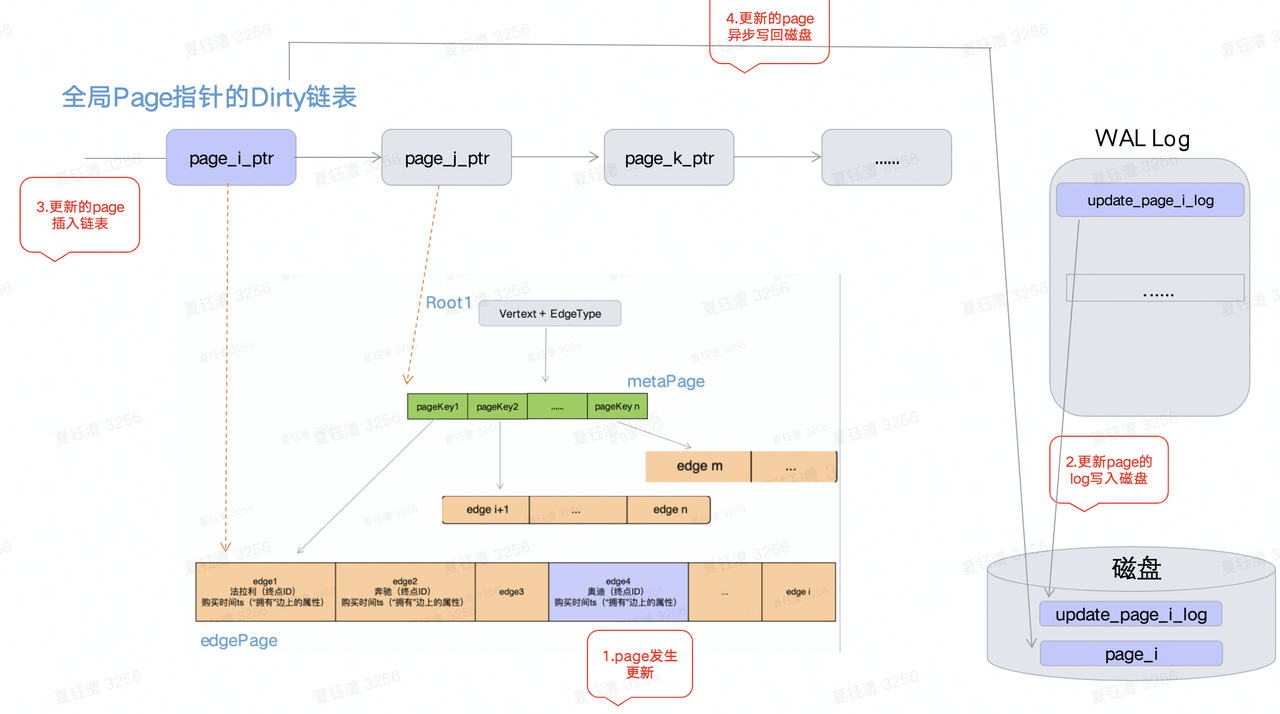
索引
边上的局部属性索引
- 针对同一个起点(局部)的多条出边,根据不同的属性进行排序查询。比如查询用户A最新关注的100个用户 vs 用户A关注中最亲密的100个用户
- 实现方式:通过对边属性作为排序key,建立索引
- 存储:会在磁盘和内存分别存储索引key和被索引的边,存储方式也是Btree+page的方式
- 构建:在增删改原有数据,同时更新索引数据
点的全局属性索引
- 针对图中全部顶点,针对单个或多个顶点属性建立索引,支持对顶点属性等值查找、范围查找、排序需求等。比如查询年龄在18岁的用户
- 实现方式:根据点属性作为排序key,建立索引
- 存储:会在磁盘和内存分别存储索引key和被索引的顶点,存储方式也是Btree+page的方式
- 构建:在增删改原有数据,同时更新索引数据
[!tip] 参考 聊一聊图数据库ByteGraph 图数据库:ByteGraph 图数据库Neo4j技术原理探秘 - 简书
Gremlin
常用图遍历语言
- V():查询顶点,一般作为图查询的第1步,后面可以续接的语句种类繁多。例:g.V(),g.V(‘v_id’),查询所有点和特定点;
- E():查询边,一般作为图查询的第1步,后面可以续接的语句种类繁多;out(edge_type)表示根据给定的边标签来沿外向游走到相邻的那些顶点。
- in(edge_type)表示根据给定的边标签来沿内向游走到相邻的那些顶点。
- both(edge_type)表示根据给定的边标签来沿双向游走到相邻的那些顶点。
- outE(edge_type)表示根据给定的边标签来沿外向游走到相邻的那些边。
- inE(edge_type)表示根据给定的边标签来沿内向游走到相邻的那些边。
- bothE(edge_type)表示根据给定的边标签来沿双向游走到相邻的那些边。
- outV()表示游走到外向顶点。
- inV()表示游走到内向顶点。
- bothV()表示游走到双向顶点。
- otherV()表示游走到其他顶点,这些顶点不包含此顶点从哪移动来的那些顶点。
g.V().has("id", {user_id} ).has("type", 80805890).outE("16").withProperties("out_time")
g.V().has("id", ).has("type", 80805890).outE("16")
g.addE("follow").from( {user_id} , 80805890).to( {item_id}, 80805893) // create a new edge
.setProperty("out_time", 10)
[!tip] 参考 ByteCloud - One-stop development platform for ByteDancer ByteCloud - One-stop development platform for ByteDancer Gremlin图遍历语言简明文档 | BobinSun.蛋总
基础
- Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
- Redis使用引用计数实现内存回收
- Redis 有多个数据库,默认使用数据库0
- Redis使用epoll实现io复用,并且单线程,除了一些备份数据的操作fork多进程,其他均是单线程
内部结构
SDS
struct sdshdr {
// 记录 buf 数组中已使用字节的数量
// 等于 SDS 所保存字符串的长度
int len;
// 记录 buf 数组中未使用字节的数量
int free;
// 字节数组,用于保存字符串
char buf[];
};
- 一个可以存储二进制的字符串结构而已,类似string
- 二进制安全
使用场景
- 所有的key,以及string的Val类型,以及其他类型的字符串存储
链表
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;
} listNode;
- 朴实无华的双向链表
使用场景
- list数据结构
字典
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
typedef struct dictEntry {
void *key;// 键
union {
void *val;// 值
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
- unordered_map,哈希表
- 使用拉链法解决hash冲突

信息
- ht[1]只用于rehash(hash扩容)使用
- size为2的倍数,方便按照倍数扩容
- hash算法使用MurmurHash3
- 计算过程为先算出hash,然后和size &运算(保证不会超出范围),冲突时插入时候优先插入链表头部
rehash
服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于
1; 服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于5
- 渐近式,不会出现突发性能问题(还是用空间换时间)
- 按照倍数扩大
过程
- 为
ht[1]分配空间, 让字典同时持有ht[0]和ht[1]两个哈希表。- 在字典中维持一个索引计数器变量
rehashidx, 并将它的值设置为0, 表示 rehash 工作正式开始。- 在 rehash 进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将
ht[0]哈希表在rehashidx索引上的所有键值对 rehash 到ht[1], 当 rehash 工作完成之后, 程序将rehashidx属性的值增一。- 随着字典操作的不断执行, 最终在某个时间点上,
ht[0]的所有键值对都会被 rehash 至ht[1], 这时程序将rehashidx属性的值设为-1, 表示 rehash 操作已完成。
- 标识开始hash,在每次操作时候进行,按照顺序
- 均为单线程操作
操作
- 查找先在原来的查,找不到再查新的,删除,改变归同时操作两个
- 增加只在新的增加
使用场景
- 键值对的map映射
跳表
跳表
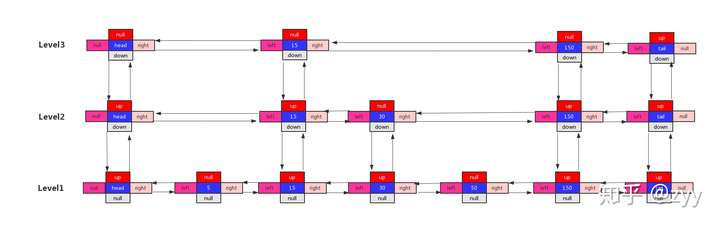
- 就是一个二维链表,从有序链表构建
- 最上层开始查,下一个比他小就向右,否则向下
- 插入数据后random,50%的概率向上插入,递归向上遍历

优缺点
- 实现简单,比平衡树简单多了
- 比B树占用内存更少
- 缓存局部性
确定层数
- level=log2(n) - 1,每一层是下一层的一半
typedef struct zskiplistNode {
// 后退指针
struct zskiplistNode *backward;
// 分值
double score;
// 成员对象
robj *obj;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
}
使用场景
- 需要排序的zset
为什么不用B+树
- 实现简单:跳表相对于B+树来说,实现起来更为简单,代码量也更少。这使得跳表更容易维护和优化。
- 更适合内存访问模式:Redis通常将数据存储在内存中,而跳表更适合于随机访问模式,能够充分利用CPU高速缓存,提高查询效率。
- 查询性能表现优秀:跳表的查找、插入、删除等操作都可以在O(log n)的时间复杂度内完成
- 范围查询不常用
整型数组
- 小型整数list用于节省内存的做法,底层就是数组,略
压缩列表
- listpack,小型只包含整数以及短串的list,节省内存做法.底层就是紧密排列的char数组.略
总结
- string 使用SDS实现
- list 压缩列表(小型)或者链表实现
- hash 使用压缩列表(小型,直接追加在尾部,查找直接遍历),或者字典实现
- set 整型数组或者字典
- zset 压缩列表(直接按照score排序)或者跳表(实际上又用字典再次保存了元素的val->score)实现
单机数据库
过期设置

- 使用另外一个dict储存按键的过期时间,添加过期时间时候插入链表
- 拿出时候和目前的time比较
常见删除策略
- 惰性删除(找key时候看一下,过期返回nil并且删除),对内存不友好
- 定时删除(定时遍历key查),对CPU不友好
redis策略
- 惰性删除和定期删除的结合
- 每个key都执行惰性删除
- 服务器周期性执行删除(每次有最大时间限制,随机抽取)
回收策略
- 当redis内存占用太多了,超过限制了就会触发回收
策略
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(默认),不会准确的删除所有键中最近最少使用的键,而是随机抽取3个键,删除这三个键中最近最少使用的键,抽取值可以设置,使用LFU策略
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
备份
- 实际上redis的备份应该是RDB备份,备份期间产生的请求直接使用AOF追加在文件结尾
RDB备份
- 一种压缩的二进制文件,储存当前redis所有key和val等信息,实现细节较为复杂,略
- 可以使用同步或者异步备份,默认不开启
- SAVE同步执行,BESAVE异步fork执行,因为是fork,读享写复,redis在此期间操作不影响RDB文件
- 优点: 体积小,效率高 缺点:key写入后如果改变无法写入(除非重写)
- 缺点: 最后一次备份可能数据丢失,在两次备份间隔中如果出现宕机,那么中间的数据就会丢失(核心问题是RDB写了之后不能修改导致写的时候发生的请求仅仅用RDB无法记录)
AOF备份
- 一种保存压缩命令的文件,类似状态机,通过重写复原数据库状态
- 默认开始,可以通过重写减少体积
- 优点: 可以实时更新 缺点:文件体积太大
命令编码
- SET key value
*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$5\r\nvalue\r\n,SDS串
命令请求过程
- 客户端编码命令并发送
- 服务端解析命令
- 预备操作(大部分是一些检查)
- 调用命令所在的函数指针(调用处理函数)
- 执行后续操作并发送结果
多机数据库实现
一致性hash算法(一致性哈希)
- 一致性hash都不是缓存机器自身的功能,而是集群前置的代理或客户端实现的。而redis官方的集群是集群本身通过slots实现了数据分片。
实现原理
请求
- 先对机器进行hash后对2^ 32-1取模(这个hash函数可以选择其他的),放到圆环上面
- 数据请求打入时候,顺时针找到下一个node的位置
- 如果出现数据倾斜的时候可以使用虚拟节点
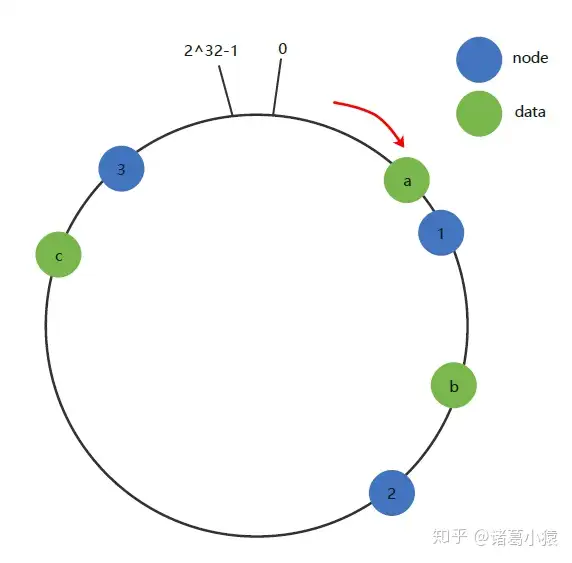
虚拟节点
- 为了使得机器分布均匀使得负载均衡,添加些虚拟节点,节点的ip指向已经存在的机器而非新机器
优点
- 扩容和宕机处理方便,只需要改变一小部分,扩展性强
缺点
- 一致性哈希的某个节点宕机或者掉线后,当该机器上原本缓存的数据被请求时,会从数据源重新获取数据,并将数据添加到失效机器后面的机器,这个过程被称为 "缓存抖动" ,而使用哈希槽的节点宕机,会导致一定范围内的槽不可用,只能通过主从复制加哨兵模式保证高可用。
- 当某台机器宕机时,极易引起雪崩,如上述介绍中删除节点。
- 删除节点就会把当前节点所有数据加到它的下一个节点上。这样会导致下一个节点使用率暴增,可能会导致挂掉,如果下一个节点挂掉,下下个节点将会承受更大的压力,最终导致集群雪崩。
- 哈希槽,一致性哈希算法更复杂
redis运行模式
单机模式
→ 上文
- 优点:简单 缺点:有性能瓶颈
主从复制
- 将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点。
- 读取可以从slave读,但是写入转发到master写
- 优点: 读压力分担给从服务器 缺点:写瓶颈和储存瓶颈都在master服务器上面,宕机之后需要人工干预
哨兵模式
- 哨兵是一种特殊的redis服务器,也有自己的master,通过raft算法选举
- 负责副redis服务器监控,类似心跳包,检查master存活状态,
- 发现master宕机之后马上选举新的master,并且通知slave,实现自动故障恢复
- 优点:宕机自动恢复可靠性高 缺点:在线扩容复杂,还是有主从的缺点
集群模式
- 把key经过hash之后放到16384个slots(一个二进制数组char bits[2048],2048*8=16384)
- 把slots指派给不同的redis master处理,当key到来时候,先计算hash,在发送MOVE重定向到正确的服务器(类似于负载均衡)
- 通过发送自己的二进制bits,告诉别人自己负责的部分
- 优点:动态扩容简单,重新分片即可

MOVE和ASK
- MOVE是槽的时候机器计算key不止自己负责的,就会永久重定向到负责的机器
- ASK则是,临时重定向,代表临时错误,一半不做处理(比如整个集群正在迁移)
崩溃恢复
总结
- 目前通常使用集群模式管理key,然后每个分片通常配置主从模式和哨兵模式,保证高可用性和可靠性
- 首先使用slot的机制(这个也可以换成一致性hash)分配到某些集群,每个集群中使用主从机制工作,同时配备哨兵模式容灾
同步
旧版
- 缺点:断线重链复制东西太多了
新版
- 使用psync命令开始
- 给oper标号,master和slave分别保存目前oper标号
- master保存一段操作的oper到内存(大约1M内存)
- 断线之后slave发送自己目前的oper标号
- master对比,如果内存还保存有,就直接发送内存里对应的内容,否则和旧版一样全发送

独立功能
订阅频道
- 订阅使用字典存储key,val使用链表结构,订阅者会插入链表头
- key更改会先去找有没有订阅者
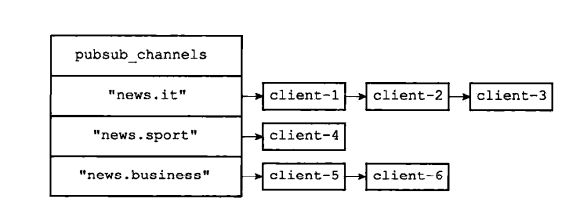
事务
- watch监控变量是否改变,multi开始事务,exec开始执行事务
- 执行前检查watch变量是否改变,改变则不执行事务,执行中途失败不会回滚

- 使用 set 等操作修改key 时候会遍历这个key 对应的watch, 将对应的 REDIS_DIRTY_CAS 打开, 此时提交事务检查这个标识就会发现从而触发

others
慢日志查询
- 记录查询事件超过某个特定事件的操作
监控器
- 客户端可以变为监视器,开始监视服务端的所有操作
参考
- redis设计与实现,https://1e-gallery.redisbook.com/
- https://www.cnblogs.com/zhonglongbo/p/13128955.html
- https://zhuanlan.zhihu.com/p/179266232 推荐书籍
- redis设计与实现
类型说明
index
- 类似mysql的数据库(不是索引)
filed
- 类似表中的字段
document
- 类似数据行,基本数据单元
type
- 类似数据表
原理介绍
倒排索引
- 一般的数据库是通过文章->获取单词(正向索引),这个是通过单词->获取文章列表
- 首先通过单词建立字典树,val为链表或者bitmap
- 查询时候拿出所有词的list或者bitmap,取交集
bitmap和list的优缺点
- bitmap每个key需要维护一个和文章总数大小相同的bit数组,当文章非常多的时候内存不足,但是bitmap与运算非常快,相对于list包含一个文章的代价也比较小(只需要一个bit),适合用于文章总数不是很多,但是文章比较相似(包含的关键字非常多,每个关键词被很多文章包含)
- list每个词出现的文章成一个list,这个list太长时候浪费内存,list做与运算比较慢,需要先排序(当然插入时候就排序也可以)然后两两合并,适合用于文章短,但是很多,内容不一样,每个关键词包含的文章较少,合并通过归并的思想,1和2合并,得到的结果再和3合并
- 因此采用的方案可以是使用List,然后两两合并的时候将list转bitmap,然后通过bitmap的与操作(这样不用排序)
wukong源代码阅读
- 实话实说,没看到什么东西很特别,绝大多数都是上面的东西
- 悟空使用的还是基于list的合并方式
创建索引
{
"name": "message",
"storage_type": "disk",
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "standard"
}
}
}
},
"mappings": {
"properties": {
"content": {
"type": "text" // 定义需要索引的数据名字和类型
}
}
}
}
- curl 创建索index
curl -u admin:cndsjc -X POST -H "Content-Type: application/json" -d '{
"name": "message",
"storage_type": "disk",
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "standard"
}
}
}
},
"mappings": {
"properties": {
"content": {
"type": "text"
}
}
}
}' http://127.0.0.1:10004/api/index
参考
- https://zhuanlan.zhihu.com/p/33671444
- https://geekdaxue.co/read/ZincSearch-doc/search-type 中文文档地址
redis和mysql数据一致性问题
- 无法保证强一致性,只能保证最终一致性
- 根本原因是因为,redis和mysql操作不是原子操作(因为跨系统)
先操作缓存
- 删除redis缓存
- 更新mysql数据库
缺点
- 更新mysql时候其他线程读取mysql,导致旧值存在于缓存中,因为这种可能发生可能性大,因此用的少
先操作数据库Cache Aside Pattern(旁路缓存模式)
- 更新mysql
- 删除redis缓存
优点
- 就算有旧值后面也会被删除
缺点
- 更新mysql时候其他线程读到旧值,但是因为网络波动,在删除缓存后写入旧值,导致旧值存在缓存中(发生概率还是比较小的,用的比较多)
延时双删
- 删除缓存(避免读到旧值,但是通常可省略)
- 更新数据库
- 睡觉一会(几十ms左右)
- 删除缓存(删除可能其他线程写的脏缓存)
优点
- 更大可能性不会出现第二种的问题
缺点
- 时间难以把控
- 性能减低(睡觉的原因)
其他
MQ
- 通过MQ把DB和redis解耦,把删除任务扔到MQ中,通过MQ保证执行的顺序和串行化
为什么不是update而是delete
实际上字节用的就是这种
- 避免A先改,B后改,但是因为网络问题,B先更新缓存,A把旧缓存更新的问题(这个感觉发生可能性比较小)
- 如果写的比较多,那么频繁更新缓存影响性能
解决缓存命中率低
- 如果要求强一致性,那么可以通过分布式锁避免其他线程操作
- 最终一致性,可以DB更新后,更新一个生存时间非常短的缓存,减低影响
总结
- 只能用于一致性要求不这么高,但是更新频繁,读取频繁的情况,比如好友数量,消息热度这种
- 真正账户余额这种还是要么不用redis,直接mysql读(数据小),要么上etcd这种强一致性的数据库
数据一致性的其他解决方案
binlog 删除
- 订阅mysql binlog, 如果出现update 情况就删除 redis 中的数据
- 读时候miss就顺便缓存
优点
- 写操作和 redis接耦
- 删除缓存极端 case 得到缓解
缺点
- 多出一个组件, 复杂性增加
- 更新之前的缓存是脏的, 短时间的错误数据
binlog 更新
- 优点和缺点类似
- 这个将删除改为更新, 但是有个问题时这个依赖 mq 的顺序消费的特性, 都者数据会是错误的
- 这个也会出现一段时间缓存是错误的
read-Through和write-Back
- 相当于外部封装了一层sdk, 所有的操作直接写入缓存之后马上返回, 返回之后缓存再写入 db中, 读的时候也是读缓存, 读取不到 sdk自行处理(感觉相当于封装了一个存储)

facebook 一致性方案
- get 使用 udp 进行连接数据传输, set/delete 使用tcp进行数据传输, udp失败的情况直接当做 cache miss处理
- 使用 lease 机制保证按顺序写入缓存, 针对一个特定的Key,当第一次查询出现Cache Miss的时候,会为它产生一个Lease返回给Client,Client在查询到真正的值之后Set Memcache的时候必须带上这个Lease,这样才能通过合法性检查。多个并发 get 的情况下只有一个能拿到 lease 写入 cache 其他需要等待 cache写入后读取
- 这里可能出现问题时拿到 lease 及进程意外退出, 导致 lease 无法写入, 这里可以通过设置 lease 有效期进行缓解(但是在有效期期间这个 key还是处于失败的状态)
缓存雪崩
- 缓存大规模失效,导致请求大规模打到mysql情况
- 此时mysql宕机,马上重启也会有大量数据导致宕机
产生原因
- redis崩了
- key失效时间设置得都差不多
解决办法
- 失效时间设置好一点(比如加上随机数)
- 熔断保护机制.当流量到达一定的阈值时,就直接返回“系统拥挤”之类的提示,防止过多的请求打在数据库上。至少能保证一部分用户是可以正常使用,其他用户多刷新几次也能得到结果.
缓存击穿
- 某个热点key没了,导致大量请求打到mysql上(mysql存在,redis不存在)
解决办法
- 设置热点key永不过期
缓存穿透
- 大量恶意的不存在的数据请求,导致大量请求持续打到mysql上(mysql不存在,redis不存在)
解决办法
- 其他系统 > 布隆过滤器,一种bitmap,将存在的key或得到结果,如果查询的key和其或结果和原来不一样,说明key不存在
缓存预热
- 在刚启动的缓存系统中,如果缓存中没有任何数据,如果依靠用户请求的方式 重建缓存数据,那么对数据库的压力非常大,而且系统的性能开销也是巨大 的。
mysql索引失效
- 对索引使用左或者左右模糊匹配
- 使用左或者左右模糊匹配的时候,也就是
like %xx或者like %xx%这两种方式都会造成索引失效。因为索引相当于前缀匹配 - 使用左模糊匹配(like "%xx")并不一定会走全表扫描,关键还是看数据表中的字段。如果数据库表中的字段只有主键+二级索引,那么即使使用了左模糊匹配,也不会走全表扫描(type=all),而是走全扫描二级索引树(type=index)
- 对索引使用函数或者进行表达式计算
- 如
select * from t_user where id + 1 = 10;
- 对索引隐式类型转换
- 联合索引非最左匹配
- WHERE 子句中的 OR
redis为什么这么快
- Redis 的大部分操作都在内存中完成,并且采用了高效的数据结构,因此 Redis 瓶颈可能是机器的内存或者网络带宽,而并非 CPU,既然 CPU 不是瓶颈,那么自然就采用单线程的解决方案了;
- Redis 采用单线程模型可以避免了多线程之间的竞争,省去了多线程切换带来的时间和性能上的开销,而且也不会导致死锁问题。
- Redis 采用了 I/O 多路复用机制处理大量的客户端 Socket 请求,IO 多路复用机制是指一个线程处理多个 IO 流,就是我们经常听到的 select/epoll 机制。简单来说,在 Redis 只运行单线程的情况下,该机制允许内核中,同时存在多个监听 Socket 和已连接 Socket。内核会一直监听这些 Socket 上的连接请求或数据请求。一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。
redis做消息队列的几种方式以及缺点
1. LIST+BRPOP
优点
- 消息下发延迟小
- 消息积压下表现好
- 多个程序BRPOP此时有数据只会通知一个程序
缺点
- 消息ack麻烦,无法确定是否成功处理,无法真正保证必达性
- 不能做广播模式
- 不支持重复消费以及分组消费
2. 发布订阅模型
优点
- 多信道订阅,消费者可以同时订阅多个信道,从而接收多类消息,典型的广播模式,一个消息可以发布到多个消费者
- 消息即时发送,消息不用等待消费者读取,消费者会自动接收到信道发布的消息
缺点
- 消息一旦发布,不能接收。换句话就是发布时若客户端不在线,则消息丢失,不能寻回
- 不能保证每个消费者接收的时间是一致的
- 若消费者客户端出现消息积压,到一定程度,会被强制断开,导致消息意外丢失。通常发生在消息的生产远大于消费速度时 可见,Pub/Sub 模式不适合做消息存储,消息积压类的业务,而是擅长处理广播,即时通讯,即时反馈的业务/
3. Stream流模型
[!tip] 参考 https://www.jianshu.com/p/d32b16f12f09 https://zhuanlan.zhihu.com/p/496944314 https://cloud.tencent.com/developer/article/2331486 https://juejin.cn/post/7094646063784525832 https://www.cnblogs.com/coloz/p/13812840.html

使用命令
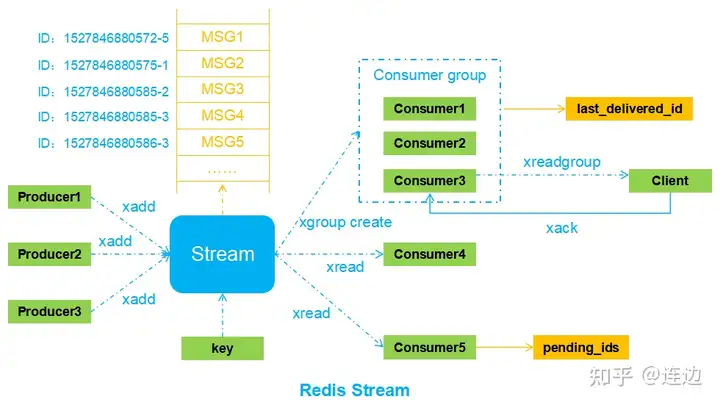
结构体
stream
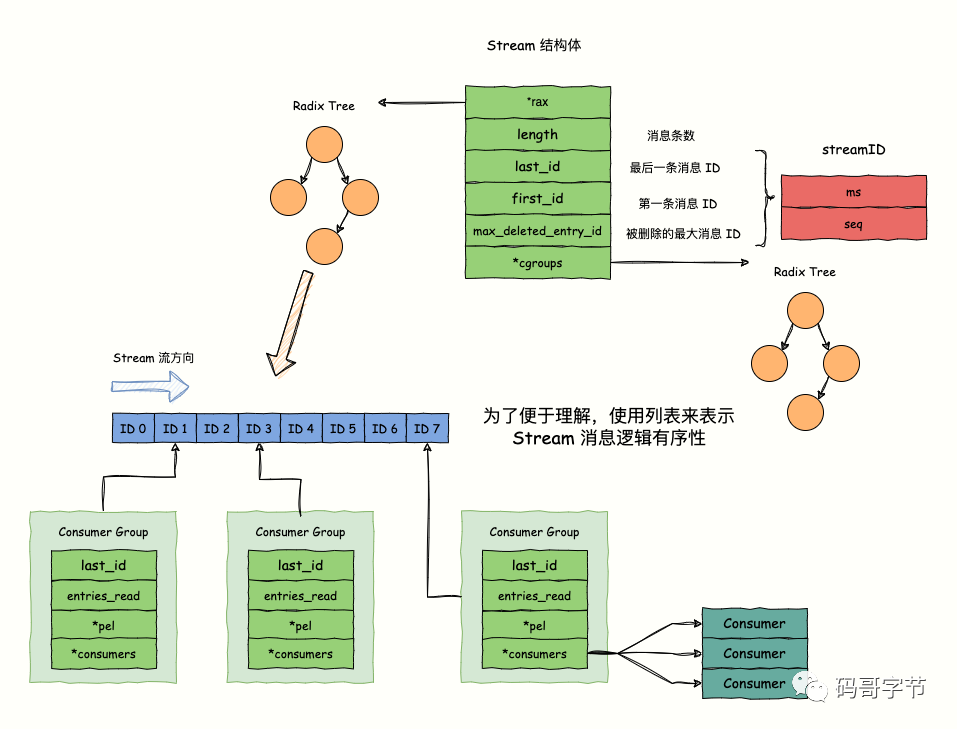
typedef struct stream {
rax *rax; // 是一个 `rax` 的指针,指向一个 Radix Tree,key 存储消息 ID,value 实际上指向一个 listpack 数据结构,存储了多条消息,每条消息的 ID 都大于等于 这个 key 的消息 ID
uint64_t length; // 该 Stream 的消息条数
streamID last_id; // 当前 Stream 最后一条消息的 ID。
streamID first_id; // 当前 Stream 第一条消息的 ID。
streamID max_deleted_entry_id; // 当前 Stream 被删除的最大的消息 ID。
uint64_t entries_added;// 总共有多少条消息添加到 Stream 中,`entries_added = 已删除消息条数 + 未删除消息条数`
rax *cgroups;// rax 指针,也指向一个 Radix Tree ,**记录当前 Stream 的所有 Consume Group**,每个 Consume Group 的名称都是唯一标识,作为 Radix Tree 的 key,Consumer Group 实例作为 value
} stream;
// 结构体,消息 ID 抽象,一共占 128 位,内部维护了毫秒时间戳(字段 ms);一个毫秒内的自增序号(字段 seq),**用于区分同一毫秒内插入多条消息**。
typedef struct streamID {
uint64_t ms;
uint64_t seq;
} streamID;
- stream中使用树和堆 > radix tree实现消息列表而不是list
[!info] 原因
- redis的消息支持根据id删除,因此需要有索引的出现,因此不能单纯用list
- redis的消息支持顺序消费,而且key大量重复,因此不能直接用hash
- 节省空间,而且因为redis默认使用时间戳+顺序编号作为id,公共前缀比较长,可以节省空间
- value的类型是redis实现 > 压缩列表,直接存储的就是消息的id和内容
- listpack的所有key都是增加的,比叶子节点的node大
- 消息的id是(毫秒时间戳-序号)
consumer group
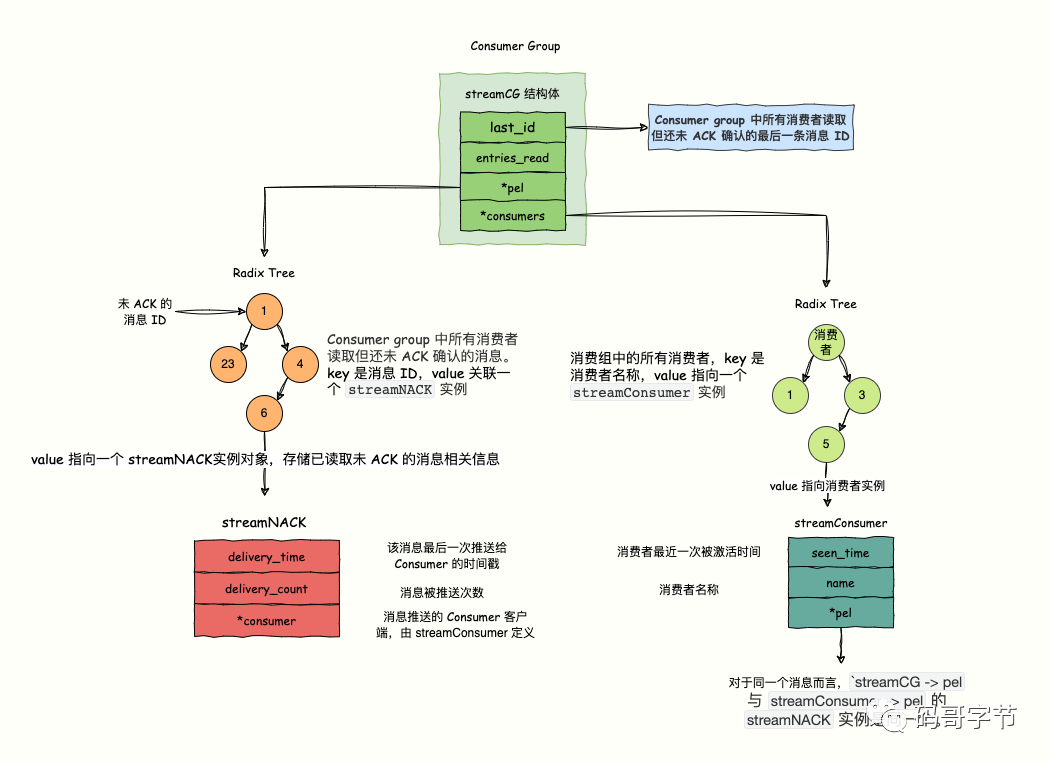
/* Consumer group. */
typedef struct streamCG {
streamID last_id;// **已经获取了,无论是否ack的id**
long long entries_read;
rax *pel;
rax *consumers;// key是消费者name,val是消费者实体
} streamCG;
/* Pending (yet not acknowledged) message in a consumer group. */
typedef struct streamNACK {
mstime_t delivery_time;
uint64_t delivery_count;
streamConsumer *consumer;
} streamNACK;
typedef struct streamConsumer {
mstime_t seen_time;
sds name;
rax *pel;
} streamConsumer;
- 没有ack的消息可能在consumer中的pel和group的pel都记录一次,但是这两个指向的都是同一个streamNACK结构体,因此是共享的
- pel是整个维护必达性的核心结构体,所有没有被ack的数据都会放到这里,保证至少被消费一次
- 消费者和消费者组参考消息队列
Iterator
typedef struct raxStack {读取之后无论是否ack,last_id都会更新
void **stack; /*用于记录路径,该指针可能指向static_items(路径较短时)或者堆空间内存; */
size_t items, maxitems; /* 代表stack指向的空间的已用空间以及最大空间 */
void *static_items[RAX_STACK_STATIC_ITEMS];
int oom; /* 代表当前栈是否出现过内存溢出. */
} raxStack;
typedef struct raxIterator {
int flags; //当前迭代器标志位,目前有3种,RAX_ITER_JUST_SEEKED代表当前迭代器指向的元素是刚刚搜索过的,当需要从迭代器中获取元素时,直接返回当前元素并清空该标志位即可;RAX_ITER_EOF代表当前迭代器已经遍历到rax树的最后一个节点;AX_ITER_SAFE代表当前迭代器为安全迭代器,可以进行写操作。
rax *rt; /* 当前迭代器对应的rax */
unsigned char *key; /*存储了当前迭代器遍历到的key,该指针指向
key_static_string或者从堆中申请的内存。*/
void *data; /* 当前key关联的value值 */
size_t key_len; /* key指向的空间的已用空间 */
size_t key_max; /*key最大空间 */
unsigned char key_static_string[RAX_ITER_STATIC_LEN]; //默认存储空间,当key比较大时,会使用堆空间内存。
raxNode *node; /* 当前key所在的raxNode */
raxStack stack; /* 记录了从根节点到当前节点的路径,用于raxNode的向上遍历。*/
raxNodeCallback node_cb; /* 为节点的回调函数,通常为空*/
} raxIterator;
- 使用还是通过栈+中序遍历节点的方式寻找下一个
整体流程
写入
- 先创建一个stream,创建raxio tree
- 根据last_id,生成要插入的新的ID,找到最大的tree的节点(最右边的节点)
- 判断listpack是否还能插入,能插入能插入
- 不能就根据key创建一个新的listpack
读取
- 所有的读取行为以group的last_id进行读取
- 读取之后无论是否ack,last_id都会更新
- 没有ack的消息都会被扔到pel中和消费者的pel中,被分配给消费者的消息不会再给其他消费者,也只能特定的消费者来ack
[!info] 重发时机
- 检测到消费者有断线的情况
- 消息过期,这部分xadd指定时间
redis如何实现延迟队列
- 使用 zset这个命令,用设置好的时间戳作为score进行排序,使用
zadd score1 value1 ....命令就可以一直往内存中生产消息。再利用 zrangebysocre 查询符合条件的所有待处理的任务,通过循环执行队列任务即可。也可以通过zrangebyscore key min max withscores limit 0 1查询最早的一条任务,来进行消费
如何避免SQL注入进攻
- 预处理:采用预编译语句集
redis和memcached优劣势
- redis支持的数据结构比memcached更加丰富,mem只支持字符串和数字类型
- mem不支持持久化存储,redis支持持久化存储
- mem占用的内存小,redis更多,mem不支持主从复制,mem使用更加简单
微信拿到红包分配
分配算法
- 随机,额度在0.01和剩余平均值*2之间.例如:发100块钱,总共10个红包,那么平均值是10块钱一个,那么发出来的红包的额度在0.01元~20元之间波动。
- 领取红包后继续使用同样的方法计算
幂等性处理
mysql的private key
- 让业务方生成唯一ID,这个ID作为mysql唯一约束,如果插入失败则说明已经处理
mysql乐观锁version
- 先将唯一id插入,下一个请求来的时候查询是否已经插入,如果发现已经插入这说明已经处理(这个不需要使用锁,但是需要在业务层对version进行判断),tira-pay使用的方式就是这个
Redis的setNX
- 将ID拼接一些信息插入redis中,设置3分钟缓存,无法插入则说明已经处理(tira-im使用的方法)
列数据库
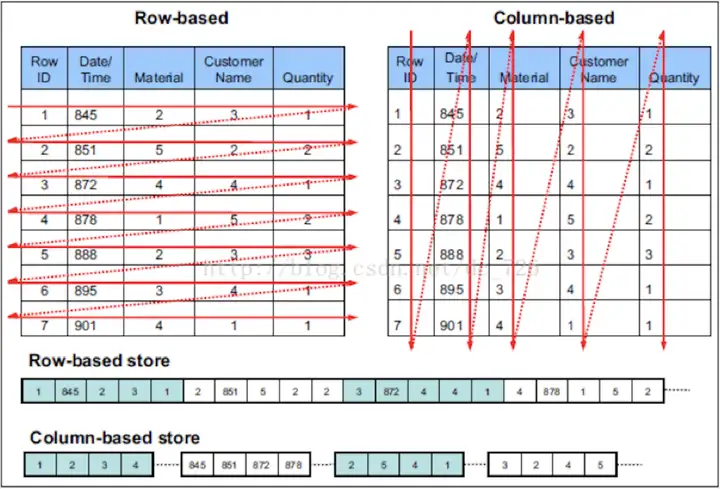
特点
- 读多于写
- 大宽表,读大量行但是少量列,结果集较小
- 数据批量写入,且数据不更新或少更新
- 无需事务,数据一致性要求低
- 灵活多变,不适合预先建模
优点
- 同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
- 更高的压缩比意味着更小的data size,从磁盘中读取相应数据耗时更短
- 更加适合于大量数据的读取分析
缺点
- 一行的全量查询慢(例如查需一个人的所有信息)
- 基本不支持ACID事务
应用场景
hbase 就是列数据库
- 类似数据分析(批量分析某个值的特征),大规模日志存储,大规模打点监控(压缩特性,并且可以接受秒级延迟)用的比较多
- 基本上是数仓和日志在用,通常是 hbase 配合 hadoop(基于mapreduce 的分布式系统基础架构,也是数仓的主要构成)
innodb和myisam的区别
- InnoDB支持事务,MyISAM不支持
- InnoDB支持表、行(默认)级锁,而MyISAM支持表级锁
- MyISAM 中 B+ 树的数据结构存储的内容是实际数据的地址值,它的索引和实际数据是分开的,只不过使用索引指向了实际数据。这种索引的模式被称为非聚集索引。InnoDB 中 B+ 树的数据结构中存储的都是实际的数据,这种索引有被称为聚集索引。
- myisam比较快,但是功能比较少
redis缓存的缺点(微信支付不用)
- 数据的一致性的问题,本质类似CAP,只能保证最终一致性,或者放弃可用性,
- 会有一种错误的安全感,高并发下会出现缓存失效的情况
使用缓存时容易有一种「虚假」的安全感,因为缓存的存在,会认为服务端性能能抗住热点时的请求,所以当缓存失败,峰值又上来之后,很快就把服务打挂了。因此,微信支付内部在做性能测试时,都需要先把缓存关掉。 即使是使用缓存,也只会使用单机的缓存,如同机部署的memcached,因为使用分布式的缓存,有多个写入来源的话,一旦缓存被写坏,排查起来会非常麻烦,因为根本不知道是在哪里被写坏的。
- 掉电丢失记录,可能出现数据的丢失
慢sql
特征
- 数据库CPU负载高。一般是查询语句中有很多计算逻辑,导致数据库cpu负载。
- IO负载高导致服务器卡住。这个一般和全表查询没索引有关系。
- 查询语句正常,索引正常但是还是慢。如果表面上索引正常,但是查询慢,需要看看是否索引没有生效。
查看
- 使用explain可以查看一个语句是否使用了索引
- 打开慢日志查询(会记录每一条执行时间长的sql),一般是由于没有索引,或者索引失效,或者数据量太大造成的
关系型和非关系型数据库区别
- 关系模型可以简单理解为二维表格模型,而一个关系型数据库就是由二维表及其之间的关系组成的一个数据组织。
- 非关系型数据库又被称为 NoSQL(Not Only SQL ),意为不仅仅是 SQL。通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定,常用于存储非结构化的数据。
- 参考
拉取数据时候根据时间戳而不是id
- 现在基本上的拉取方式是 offset+limit,实际上mysql会将所有的数据拉取出来,然后排序好在偏移到offset拿出limit,因此数据量会非常大
- 但是如果是通过时间戳拉取的话,只会根据时间戳的范围进行拉取而不会全量拉取.因此业界通常的做法是通过 begin_time, end_time 拉取,而不是用limit
关系型数据库优缺点
- 采用二维表结构非常贴近正常开发逻辑(关系型数据模型相对层次型数据模型和网状型数据模型等其他模型来说更容易理解);
- 支持通用的SQL(结构化查询语言)语句;
- 丰富的完整性大大减少了数据冗余和数据不一致的问题。并且全部由表结构组成,文件格式一致;
- 可以用SQL句子多个表之间做非常繁杂的查询;
- 关系型数据库提供对事务的支持,能保证系统中事务的正确执行,同时提供事务的恢复、回滚、并发控制和死锁问题的解决。
- 海量数据情况下读写效率低:对大数据量的表进行读写操作时,需要等待较长的时间等待响应。
- 可扩展性不足:不像web server和app server那样简单的添加硬件和服务节点来拓展性能和负荷工作能力。
- 数据模型灵活度低:关系型数据库的数据模型定义严格,无法快速容纳新的数据类型(需要提前知道需要存储什么样类型的数据)。(比如巨大的表格增加字段)
非关系型数据库的优缺点
- 非关系型数据库存储数据的格式可以是 key-value 形式、文档形式、图片形式等。使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。
- 速度快,效率高。 NoSQL 可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘。
- 非关系型数据库具有扩展简单、高并发、高稳定性、成本低廉的优势。
- 可以实现数据的分布式处理。
- 非关系型数据库暂时不提供 SQL 支持,学习和使用成本较高。
- 非关系数据库没有事务处理,无法保证数据的完整性和安全性。适合处理海量数据,但是不一定安全。
- 功能没有关系型数据库完善。
- 复杂表关联查询不容易实现。
为什么mysql2000万行数据之后性能急剧下降
- mysql中索引B+树的高度大约是3,在2000w行数据内,并且页的大小是和磁盘的格子大小相关的
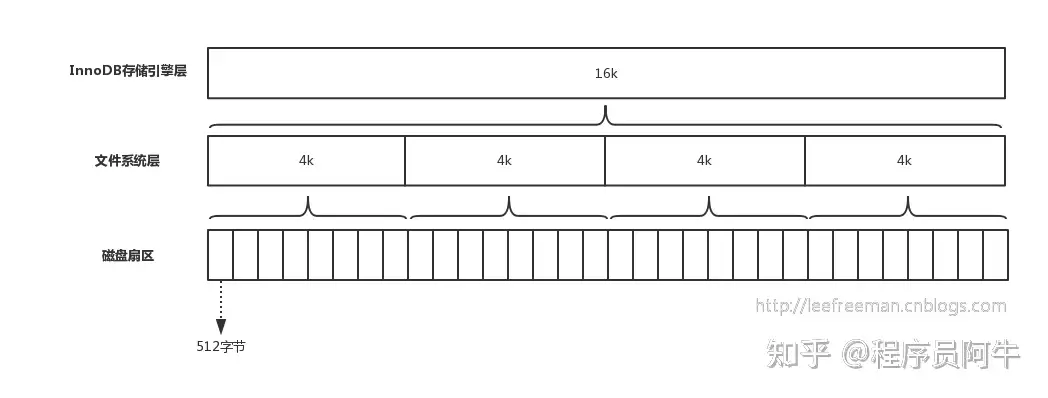
- 2000万行一下时候,基本上都是3层索引(大概是3层索引时候底层数据的极限容纳值),使得查找的效率相差不大
- 超过2000w行之后,B+需要变高,变高导致最底层的8页变成16页,多出16个页面,页面直接从磁盘中读取,导致io次数变多,性能变差,参考
查询的时候limit和offset有什么缺陷
- 数据库实际上是查找了offset+limit条,然后返回最后的limit条,当出现offset非常大的时候(特别是下滑刷新的时候),导致没吃查询的速度变得很慢
- 因此toC的一般使用时间戳的方式select,类似序号的形式,只是序号使用时间戳
mysql 在数据量非常大情况下如何统计行数
- 使用
select table_name,table_rows from information_schema.tables where TABLE_SCHEMA='effect_user_busi' and table_name='user_favorite' LIMIT 1;可以查到大概的数量级(有少量误差)
如何提高秒杀中数据库瓶颈
- 热点行事务想收集多行,然后只需要加锁一次一次性运行多个事务语句直接处理
- 参考 什么是热点行性能优化_云原生数据库 PolarDB(PolarDB)-阿里云帮助中心
如何选择数据库
- 如果出现ACID的需求支持事务性,类似支付这种业务,只能选择mysql,如果流量大或者分布式就用消息队列 和分布式事务,具体参考 支付系统
- 如果出现强一致性和分布式强需求,但是对事物性要求不高,类似 服务注册发现中心,就用etcd,参考 微服务框架 > coa
- 如果需要数据高速读写,但是不需要持久化存储(比如一些临时的排行榜),直接上redis redis实现
- 如果需要数据高速读写,需要持久化存储,但是对数据的一致性要求没这么高的,用redis+mysql 具体参考 数据库总结 > redis和mysql数据一致性问题
- 这样的缺点就是 需要解决一致性问题,以及还有穿透雪崩风险,错误概率大,成本高
- 而且redis一旦出问题挂了,mysql也会马上因为流量太大挂掉
- 如果需要数据较高速读写,需要持久化存储,对数据的一致性要求高的,用leveldb,参考LevelDB底层
- 如果需要灵活的数据结构和更舒适的开发体验,对事务没有强需求,小型项目,数据频繁变化,存储维度多样(有子结构和数组这种),类似文档型数据,用mongodb Mongodb基础
- 如果需要数据高速读写,需要强持久化存储(数据完全不丢失),对数据的一致性要求高的. 那基本是不可能的
- 高速读写意味着只能站在缓存进行,持久化只能在存储进行,一致性高只能在同一个系统进行(不同进程会出现cap问题),导致这三者必须牺牲掉一个或者减少一个去平衡其他两个,leveldb就是其中佼佼者
- 如果数据量非常大,重复率高,需要进行大量存储和离线数据分析(类似用户数据大表的备份,程序日志搜索等),对实时性要求不高(能接受秒级延迟),用列数据库 数据库总结 > 列数据库
- 出现用户大量的关系需要存储,类似关注,特别是共同关注这种需求,业务查询的时候通常以用户维度查询而不会用范围查询(数据分析的需求通常倒入列数据库离线分析),要求高性能查询扩展关系查询,通常用图数据库 Neo4j底层原理
- 如果是关键词搜索,通常使用ES这种倒排索引的数据库 zincsearch底层实现

Mysql Redis DRC 同步
- DRC (Data Replicate Center) 用于数据库的同步数据
- 使用类似从库复制的手法解决 , 同机房有 sync-out 模拟从库消费主库的 binlog , 发送到对机房的 sync-in (当然中间会放 mq) , sync-in 同步binlog到当地的机房
- 如果出现冲突遵循最后更新原则(即按照时间判断这个更新是否生效), 但是核心还是需要避免冲突, 根据用户 did划分机房(不用uid 是处理没有登陆的情况下)
缓存如何优化
- 3级缓存的机制缺点是, 如果遇到热点数据经常需要读取的,就会出现有时候因为没有命中缓存导致缓存穿透的问题
- 实际上这部分如果是少量的热点key可以通过全量缓存到内存中, 然后定时从数据库刷新的办法实现, 这样热点数据缓存命中率是100%
- 至于怎么从3层缓存到这种全量缓存的一种办法是通过检测 QPS, 如果QPS 过高就自动转化为这种形式
- https://juejin.cn/post/6964531365643550751
- https://mp.weixin.qq.com/s/bWofuM5eS2Q8ylF-4AD0kA
- https://zhuanlan.zhihu.com/p/346651831
- https://xiaolincoding.com/mysql/index/index_interview.html#%E4%BB%80%E4%B9%88%E6%98%AF%E7%B4%A2%E5%BC%95
- https://mp.weixin.qq.com/s?__biz=MzUxODAzNDg4NQ==&mid=2247503394&idx=1&sn=6e5b7b2c9bd9002a4b2dfa69273069b3&chksm=f98d8a88cefa039e726f1196ba14210ddbe49b5fcbb6da620778a7497fa25404433ef0b76268&scene=21#wechat_redirect
- https://mp.weixin.qq.com/s?__biz=MzU3ODA4NTc2Ng==&mid=2247484078&idx=1&sn=87a62dbe2d4ca7e56f2e0319465147a3&chksm=fd7bf447ca0c7d51dbbce887ce37ea7088d508b8766e09892706225a49fad06ad3716d48e0e0&token=2107017276&lang=zh_CN#rd
私聊
tira-im
群聊
helper-im
综合
openim
直播聊天室
- 消息扩散比大,同时要保证实时性;
- 成员流动性大,在线状态难维护;
- 不关注历史消息,消息下发后即可删除;
- 消息量大,容忍少量消息丢失;
- 用户爆发量大,需要支持快速水平扩展;
goim(哔站弹幕系统)

结构图

整体流程
- logic是负责处理http请求部分,job相当于异步下发的中间件(逻辑层),comet主要负责长连接以及消息的下发(接入层的感觉)
- comet只关心连接的部分,任何人都有可能连接到任何一个comet
-
通过logic的http接口发送消息,logic直接将消息扔到kafka中
消息的类型,消息的body,发送人,以及房间号
-
job模块拿出来之后放到room的chan中,这部分每一个job、都有可能拿到消息,只会被消费一次,
-
遍历所有的comet,通过rpc异步发送这个消息(这里如果不是广播而是私信就只发布到指定用户在的comet)
-
comet拿到之后遍历所有的bucket(相当于每个用户的连接被放到不同bucket中,这部分可以仔细看看)
-
bucket遍历对应房间chan中的所有连接,下发消息)
特点
- 使用写扩散的机制,发一条将消息体直接下发到每个人
- 消费kafka的时候也是拿出来后直接mark成功,这里涉及丢包的现象毕竟比较少,影响也比较小
- 使用中间件job避免大量消息堆积在kafka中,同时方便扩展job,通过kafka实现消息的削峰,通过job实现消息的分流
- comet中存在大量的chan缓冲作用(基本上每个模块的连接都是通过chan)
- 使用bucket再次进行缓冲和连接的分片,每个连接代表一盒channel
缺点
- 只是改善,依旧存在写风暴的问题,但是通过层层缓冲一定程度减轻了影响
- 中间可能出现丢消息的情况(因为chan满了直接丢弃)
- 轻量化,容易实现,但是有序性和必达性不保证(其实弹幕系统这两个需求也不高)
微信聊天室

- 使用群聊收件箱的机制,以群聊维度发号,消息只存一份
- 客户端携带自己的seq下拉,如果是新用户seq为0,拉取最近的40条消息,否则拉取最新的消息
和goim比较
- 因为只需要下发ID,写扩散压力大大减小
- 读压力放大,因为客户端需要不断申请拉取新的消息
- 引入了存储的部分,消息需要存储,goim不需要存储
- goim使用长连接主动下发push的办法,微信使用HTTP LongPolling(客户端发起收消息请求后,把请求先hold在服务端,等待一段时间,设置为5s,若期间有新消息,则立马返回,若没有则等待结束后返回空消息)
解决读压力太大的问题
- 使用集群缓存的办法解决,通过hash将不同的聊天室hash到不同的缓存集群中,每个集群都缓存了集群负责群的最近1000条消息
- 使用两份写表切换的形式解决读写锁冲突的问题

解决没有长连接统计在线问题
- 设置一个统一的聊天室在线列表缓存svr,当用户有http时候就向svr发送心跳包,实际上这部分还是有可能出现断连消息滞后的问题(只能等待自动过期)
消息通知流程
- 用户根据房间号hash之后得到缓存的集群地点,直接向集群发送请求,集群自己负载均衡之后打到某台机器上
- 请求进入缓存层后,若有新消息,则立刻返回,无须等待;
- 请求进入缓存层后,若没有新消息,将请求加入队列中hold住,每200ms轮询max_seq

微信IM
整体架构图
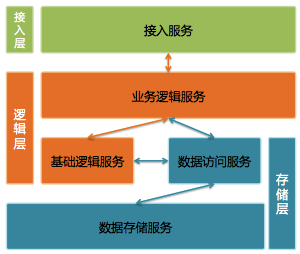
- 微信的消息不进行持久化存储,特别是私聊消息收到ack之后过几天就删除了,无法提供消息漫游的功能,但是QQ可以
- 微信的消息成功的通知是在消息的成功落库之后才进行的,因此可以保证必达性
推送模型
- 下发ID和下发data两种模式相结合的形式
- 下发模式分为notify和data两种模式,data为数据体模式,notify为下行ID的形势
- data模式明显比notify模式快,但是可能出现消息丢失的现象(除非使用双链,但是双链重试使得效率降低),因此微信采取的data模式时候是在服务端转换的(接入层更改),这部分意味着由服务器保存一份用户接受到了的最新id,然后通过这个id查询你需要的消息体,打包下发
- Data的状态需由客户端触发形成,触发的时机为客户端主动上服务器来做过一次消息收取的请求。由于在Data状态下需由服务器的ConnectSvr主动去ReceiveSvr获取增量消息,服务器必须知道客户端此时的sequence才能做到通过sequence的比较增量下发消息。所以在进入NotifyData状态前,需等待客户端主动做一次消息收取的请求将此时客户端的sequence保存在ConnectSvr中。
- 在Data状态下,客户端必须对服务器下发的每一个Data进行Ack,并且服务器在下发了Data未收到Ack的这段时间内需关闭Data状态(即在图2的2.7和2.8步骤之间不能再做NotifyData下发)
- 直接推送更加快,但是可能出现乱序和丢失的问题,因此需要严格控制下发body的触发条件
消息模型
- ack的在进入界面,退出界面,在界面停留几秒都会发送ack
私聊
- 私聊以个人维度发号,和tira中的私聊设计类似
- 这样可以很方便做管理(只需要拉一条时间线上的消息)
- 微信这部分的私聊消息很可能压根没有做MQ,估计为了保证不会丢消息,一定是写消息成功落库之后才会返回前端成功.收件箱为了持久化存储,使用的不是redis这种内存数据库,估计是类似leveldb这种
群聊
实际上微信基本上都是用户一个inbox,使得不支持大群,而且不好做已读未读
- 群聊使用群聊收件箱的机制,和help的机制一样,维护群聊收件箱
- 群聊维度使用群维度发号,以群id维度发号,类似读扩散
朋友圈
- 朋友圈使用写扩散,读扩散大概率出现失败导致刷不出来(因为需要从不同的人拉取,跨idc),但是写可以重试写,容错比较高,选择写扩散
- 朋友圈的评论也是后台拉出来然后进行过滤后返回
惊艳设计
如何解决一大堆群聊消息下发浪费带宽
- 采取按需拉取的方法
- 下发的时候只下发id和摘要,,不会直接下发消息体,这个和私聊不一样,私聊可能直接下发消息体,点开之后才会进行拉取
- 消息序列中允许空洞的出现
- 可以向后台请求空洞中的所有消息消除空洞

- 可以向后台请求空洞中的所有消息消除空洞
如何解决群聊的未读消息计算的问题
- 计算在服务器中进行,遇到未读消息修改收件箱的时候顺手给用户未读数加1,进群之后直接清零
如何解决收件箱崩溃问题
- 一旦出现消息过载导致收件箱绷不住了(比如除夕),使用旁路下发的手段
- 旁路下发不需要写收件箱,直接对消息进行二次加密后直接下发到客户端,能极大增加下发速度
- 使用前提:如果副设备最近 72 小时没有登陆过,那么重新登陆时不会同步最近消息。我们只对满足这个要求的用户推送,则用户不会感知消息未被写入收件箱,同时做到削减收件箱读写量的目标。
- 本质上是因为,微信不提供消息的漫游服务,使得无需长期保存消息,app保存的消息列表就是最终的消息列表
飞书IM
收件箱方案

- 采取每个会话有一个收件箱作为存储
- 每个人也有一个收件箱,每个人的收件箱是专门用来接受命令消息的(更新会话,更新成员等 不直接展示在端上的通知)
- 大部分命令消息是不重要的(更新会话,更新成员等,可以通过拉取接口获取最新数据,命令消息只是保证了及时性),都放到单链中会影响正常消息的拉取效率;sdk拉展示10条消息,原先只需要请求一次,现在可能需要多次;
- 命令消息不展示在端上,也不能更新最近会话排序,如果放到单链中无法和普通消息一样通过最近会话version保证消息不丢
- 还有一个最近会话链,记录当前的会话信息的排序

相关方

已读未读
- 每个会话维护每个人的读取进度,其中包括 [startIndex,endIndex] (start是为了处理中间拉人的情况)
- 下拉的时候对比每个人的endindex就可以获取每个人的读取进度
- 这个已读未读的拉取是定时的,而不会已读进行消息的下发,避免写扩散的现象,目前飞书的设计是每隔1s将会话列表中的已读未读拉取一次更行,这个对时效性要求不高
消息属性
- 表情回复这种都属于消息的属性
- 客户端上报表情修改命令消息,服务端读出对应消息,如果是添加,则append用户到对应表情的点赞用户列表中。如果是删除,则从列表中删除该用户
- 服务端更新消息版本号,写回消息内容。
- 服务端写变更操作到会话链,服务端通知会话成员,消息属性变更(推送消息全量属性,避免端上处理复杂和两端不一致)。
- 在线设备收到推送后,如果本地有消息,则处理属性变更命令,覆盖本地的消息属性。如果本地无消息,则直接丢弃该命令(因为后续拉取到该消息时属性一定是全的)
命令消息
- 类似删除会话这种都是命令消息,命令消息单独写入user链中然后进行统一进行下发
- 类似修改message属性的行为都属于命令消息,比如修改内容,表情回复
- 先写入消息体,对消息体直接进行更改,在写入命令消息触发推送逻辑,推送直接全量推送整个消息,为了避免复杂的情况
- 命令消息只使用一次或者少量次数,没必要和单链一起储存,有关命令消息的更改一定是全量拉取之后完全可以忽略的
流程
- 抖音IM和飞书IM核心区别在于响应的返回不一样,抖音IM写入kafka后作为成功直接返回,飞书IM需要落库等一系列操作才返回,只有下发是异步的. 飞书IM主要使用mysql存储,抖音IM主要使用abase存储,tt主要是走的单链写扩散模式
- 因为飞书IM对于发送QPS没有这么大需求(毕竟是企业用户),但是对于数据持久性要求高
- 使用redis的zset存储收件箱
- redis的hash维护每个chat会话的每个人的读取进度(这个也可以用abase)
- 还要存储这个chat最新的messageid
- 存储个人的阅读进度时候存储 nowpos和beginpos(后面这个为了标识后来加群这种操作)
- 再redis使用list+hash维护一条最近对话的链(这个感觉可以用lru类似)
发送
- 发送时候需要生成message_id以及position,position\需要保证绝对递增,目前应该是使用了mysql的事务机制保证绝对递增性质
- 发送时候先开启事务,在mysql记录对话表中将 last_position+1,这里直接采用乐观锁,失败进行重试(失败次数并不多)
- 插入message表格中(携带position,messageid),position因为绝对递增性,用于不适合用于直接作为messageid
- 端上拉取的时候可以直接根据下发的position判断是否连续以及是否存在空洞
拉取
- 拉取的时候先拉去最近对话的链条(拿到所有的chatid)
- 根据所有的chatid拉取所有所有的chat的读取进度,并且找到自己的读取进度,和判断自己是否存在未读消息
- 将大于本地的id都拉下来,根据自己的进度作为未读计算
- 以及拉取命令消息的收件箱,如果存在就执行,不存在就直接放弃(因为下次拉肯定是最新的)
- 如果是新启动的app(完全没有原始数据),这个时候不需要拉命令消息,因为所有数据都是最新的,直接那最新的命令消息id作为localid
- 如果是有数据的app打开需要根据localid拉取消息(因为不会进行全量拉取,需要进行回放)
- 每隔几s拉取所有chat的读取进度,并且计算已读未读的现实
- 读取之后可以出发更新操作,更新自己的已读的nowpos(这个可以离开chat触发,也可以定时触发)
- 在线推送的时候直接推送消息体,如果qps流量太大触发降级就改为推ID,再上行拉.如果出现空洞(每个消息会携带上一个消息的ID,通过mysql事务性获取chat上一条消息的ID获得,这里依赖消息id的连续递增性或者直接从mysql获取自增id下发,即对mysql中chat的信息进行CAS交换,拿到上一条信息并且把下一条改成自己的)就进行补偿拉取(拉取空洞的内容)
- 这里考虑messageid和index完全可以不需要一直,只要保证messageid完全的递增性就行,这里也可以和插入mysql body作为一个事物去执行
- 直接根据index进行拉取,但是redis还需需要保存index到messageid的映射关系,好处是客户端完全可以根据index是否连续直接判断是否有空缺,可以直接下发消息body
存储
- message实体储存到message_entity 表中.表格使用chatid进行分表(这个就是会话的id)
- 使用abase kv数据库存储 messageid到chatid的关系
- 使用一张mysql表记录chat(会话)的信息(比如最后一个messageid等)
- redis作为zset缓存inbox和message body缓存
数据同步
- 抖音的IM通过 kafka进行数据同步,直接将其重放到不同地区,保证数据一致性
- 飞书的IM根据用户确定选择机房,无论在哪里最后的请求都回到原地的机房(比较慢)
- 即时通讯网 - 即时通讯开发者社区!这个IM网站非常不错,推荐
[!important] 这部分都是看一些系统设计的书籍总结出来的,觉得有点意思的地方,没有自己真正写过,仅供参考
短链系统
- 相当于给定一个长链转化成为短链,用于在推特这种限定字数的帖子的场所放链接
重点
- 如何保证6个字符组成的短域名的唯一性和安全性,避免重复和让别人分析逐个爬取
- 如何选取合适的数据库和存储结构
- 如何实现过期后失效
思路
- 域名的生成几种办法
- hash,太长了大于6个字符,如果截断会有冲突风险
- 自增id,可以使用数据库自增key,大小也满足,唯一性也满足,但是不满足安全性,很容易猜出数据
- 域名最终方法:
- 字符选取{0-9,a-z,A-Z}62个字符(url大小写不敏感,但是服务器处理敏感),组合6个字符有起来有568亿种组合,完全满足要求,考虑到安全性,使用五位数,最后那一位作为校验位(自定义域名直接使用5位)
- 使用自增id,但是生成的id和某个magic num相异或(相当于简单加密),最后转换为62进制
- 生成的数字hash加密(hash中再加上一个magic num),加密最后一位mod62作为最后一个数字
- 数据库选择:
- 因为关系型非常弱对事务没啥要求,没必要选mysql这种,写流量也不小直接上leveldb,再配上短链作为private key和index
- 读流量非常大,一定上redis进行缓存,可以根据域名hash的结果进行一致性hash的负载均衡redis实现 > 一致性hash算法(一致性哈希)
- 过期删除设计:
- 选择记录过期时间,从leveldb读的时候查一下是否过期,过期就返回无效
- 存到redis的时候注意一下使用
min(过期时间-现在,统一缓存时间)作为过期时间
流程
- "写"的时候
- 如果是自定义域名尝试插入康康是否有唯一键冲突,这里不能先查后加,因为出现原子性问题
- 如果是默认直接插入记录获取id,计算之后将结果写入并返回
- "读"的时候
- 根据前5位校验最后一位的正确性,相当于本体的布隆过滤器,不符合直接pass(这样可以尽量避免缓存穿透)
- 从redis中查找是否存在数据,如果不存在就从leveldb拿出来并且缓存到redis(这部分可以设置缓存时间然后每次访问刷新,也可以直接使用LRU或者LFU),将访问记录和信息异步扔到消息队列里面后直接返回
- 后台分析的进程负责消费和分析
细节优化
- 业务上可以提前拿一批号(提前插入空白+status),然后记录先扔道消息队列+redis缓存后直接返回,异步写数据库,避免数据库承受不住压力
- 可以业务层上一个LRU本地缓存,避免redis,这种就是多级缓存的思想了操作系统 > All problems in computer science can be solved by another level of indirection
附近系统
- 地球为界,搜索(以及增加删除等)给定半径范围内附近的地点,然后附加一些打分之类的功能,类似滴滴的功能也可以用这个办法类似
- 数据量大,因为按照地球划分
- 高搜索,低更改
- 第一眼看上去有点像树和堆 > kdtree,但是直接使用kdtree会有直接的问题半径不好处理,kdtree可以找到最近的k个点,但是一旦出现范围查询就不太方便,每个都必须判断是否在范围内,而且很容易出现极度不平衡的问题,参考kdtree的缺点,以及每个地点都是一个节点,浪费空间
思路
- 因为地图是二维的并且不会有变化,因此可以通过网络划分的形式组织起各个地区,其中使用四叉树组织格子
- 每个格子中设置最大地区数量,如果超过了就继续划分格子,实现动态格子划分,刚开始整体地图就一个格子,后面随着地点增多逐渐划分
- 搜索的时候从最顶格的区域进行搜索,首先划定半径的区域,这个区域使用四点定位法,然后找到最小能完全包裹这个区域的node,然后将这个node的数据全部拿出来一个一个算+排序(排序可以根据评分和距离综合排序)


存储
- 地图的存储 准错左上角的点的经纬度,然后宽和高,目前点的id列表直接用指针,因为没什么需要顺序的地方,但是可能经常要改
typedef long long ID
struct Area{
ID area_id;
double longitude // 经度
double latitude // 纬度
// ... 一些乱七八糟的属性省略
}
struct Node{
ID node_id;// 这个id便于后续根据hash进行负载均衡到不同服务器
double longitude // 经度
double latitude // 纬度
double width // 区域宽度
double height // 区域高度
bool isDivided // 是否被划分
Node* children[4] // 继续的小区域
List<ID> area_list; // 存错区域内的建筑id(不使用指针是为了方便分别存储,避免集中化),如果isDivided=false才会存在
};
Geohash
- 从第 0 位开始,偶数位放经度,奇数位放纬度,得到完整的二进制编码:将二进制编码分组(5个一组)并计算出对应的 Base32 编码
- 将二维坐标转换为字符串(Base32编码字符串)的形式,同一个区域方块内的坐标计算结果是相同的
- 长度越长,方格越小.一个GeoHash长度为1的格子包含32个GeoHash长度为2的格子
- 可以这个部分代替上面的经度和纬度的二维保存方法,四叉树直接放这个字符串,然后变成类似==前缀树==的方式存储位置,查询的时候直接比较字符串即可,或者存在数据库中使用like+%的方式查附近的人 树和堆 > trie tree(前缀树)
- 可以通过改变二进制串最后的几个01快速扩区附近的8个格子的hash,意味着可以在O1而不是Ologn的时间获取到附近的区域
文档系统
- 实现类似在线文档的功能,支持写作在线编辑
重点
- 如何实现协作而不冲突
- 如何实现底层的文件系统
思路
- 操作转换:每个提交带上版本号和操作的内容,然后服务器根据更改的版本以及当前的版本变化进行转换(通过类似git diff进行对比),顺序处理请求 #TODO 这里还可以深入探究一下
[!example] 当 A 通过在开头添加 x 来编辑文档时,这个改变将与 A 所看到的最后修订一起发送到服务器。假设此时 B 删除最后一个字符 c ,并且这个改变也是这样发送到服务器。 由于服务器知道修改在哪个版本上进行,因此会相应地调整更改。更具体地说,B 的变化是删除第三个 字符 c ,它将被转换为删除第四个字符,因为 A 在开头添加了 x 。
缓存系统
LRU
![[单调栈和链表双指针#146. LRU 缓存]|LRU]]
LFU
460. LFU 缓存
请你为 [最不经常使用(LFU)](https://baike.baidu.com/item/%E7%BC%93%E5%AD%98%E7%AE%97%E6%B3%95)缓存算法设计并实现数据结构。
实现 `LFUCache` 类:
- `LFUCache(int capacity)` - 用数据结构的容量 `capacity` 初始化对象
- `int get(int key)` - 如果键 `key` 存在于缓存中,则获取键的值,否则返回 `-1` 。
- `void put(int key, int value)` - 如果键 `key` 已存在,则变更其值;如果键不存在,请插入键值对。当缓存达到其容量 `capacity` 时,则应该在插入新项之前,移除最不经常使用的项。在此问题中,当存在平局(即两个或更多个键具有相同使用频率)时,应该去除 **最近最久未使用** 的键。
为了确定最不常使用的键,可以为缓存中的每个键维护一个 **使用计数器** 。使用计数最小的键是最久未使用的键。
当一个键首次插入到缓存中时,它的使用计数器被设置为 `1` (由于 put 操作)。对缓存中的键执行 `get` 或 `put` 操作,使用计数器的值将会递增。
函数 `get` 和 `put` 必须以 `O(1)` 的平均时间复杂度运行。
- 通过有序map记录每一条key的使用频率,自动排序,用hash记录key和val关系,时间复杂度log(n)
- 通过双hash机制,一个hash记录使用频率和一个链表,一个hash记录key和node*,当查询时候,增加使用频率,从hash中的链表拿出,换到下一个使用频率hash的链表,时间复杂度为O(1),重要
- 需要维护一个minFreq的变量,用来记录LFU缓存中频率最小的元素,在缓存满的时候,可以快速定位到最小频繁的链表,以达到 O(1) 时间复杂度删除一个元素。 具体做法是:
- 更新/查找的时候,将元素频率+1,之后如果minFreq不在频率哈希表中了,说明频率哈希表中已经没有元素了,那么minFreq需要+1,否则minFreq不变。
- 插入的时候将minFreq改为1即可。
[!question] 缺点 一个数字一旦积累了次数就很难被替换下来,但是很多时候有的数据遇有时效性 而且消耗大量空间,因为所有出现过的key都要记录频率
[!quote] 场景 如果数据有明显的热点,即某些数据被频繁访问,而其他数据则很少被访问,那么 LFU 算法比较适合。例如,一个视频网站的首页,某些热门视频会被很多用户频繁地访问,而其他视频则很少被访问,这时 LFU 算法就能够更好地满足需求。
SLRU
- 图中的右边部分,两个LRU组成,访问两次放入保护段,只能淘汰淘汰段的部分,保护段超过了旧放回去
- 代码参考gommon/cache/slru/slru.go at main · jiaxwu/gommon · GitHub
- 插入时候查询是否已经在淘汰段,如果在放入保护段,如果已经在保护段更新即可
- 如果不存在且未满(这个满是两个LRU之和和设置的大小),继续放入淘汰段
- 如果已经满,淘汰端最后一个淘汰
- 查询的时候类似,如果访问两次放入保护段
- 保护段长度如果超过选择最后一个放入淘汰段
[!question] 优缺点 一定程度上解决了纯LRU的额外难题,但是还是可能遇到突发流量占领的问题
W-TinyLFU
- 底层用到了 LRU,SLRU,以及布隆过滤器,CountMinSketch
- 所有的元素都需要进行CountMinSketch的次数统计,图中的pk指的是比较访问频率,中间相当于一个tidy的LUF
布隆过滤器
- 相当于bitmap,hash之后结果or后置1,如果得到的结果为0一定存在,但是为1 不一定存在
CountMinSketch
- CountMinSketch计数器的数据结构是一个二维数组,每一个元素都是一个计数器,计数器可以使用一个数值类型进行表示,比如无符号int,4位 最大值是15
- 使用多个hash减低污染,对于增加计数操作,每个元素会通过不同的哈希函数映射到每一行的某个位置,并增加对应位置上的计数
- 读取的时候读多个取最小的数字
频率统计
- 使用 布隆过滤器 作为计数器为1 的计数 使用CountMinSketch 作为计数器为16的计数,先过布隆,减少对本体16计数器的影响
保鲜机制
- 操作过一段时间会进行计数器的减少,减低临时流量的污染行为
- 布隆过滤器清空,计数器减半
[!tip] 参考 W-TinyLFU缓存淘汰策略 - 掘金
输入提示系统

- 底层还是trie
- 用于类似输入提示系统的时候可以和hashmap联合使用,记录trie 的node上对应最高的k个匹配结果
- 然后每周更新排名以达到提高速度的办法,因为对实时性要求没这么高
ssl-tls
握手流程
-
客户端发起请求,发送clirand
-
服务端发送签名证书,公钥,serrand
-
客户端校验证书合法性
- 证书签发会对内容进行hash计算签名值,然后对签名进行私钥加密,并把加密后的签名加到证书
- 客户端根据证书CA获取签发的机构的公钥,对签名解密,获取hash值
- 客户端自己对证书hash,比较hash是否相同,相同则信任^[https://www.zhihu.com/question/37370216]
因为CA的私钥是未知的,伪造证书无法生成相同hash值
-
客户端再生成secretrand,并且使用公钥加密,发送到服务端
-
服务端进行私钥解密得到secretrand,将三个随机数连接并进行hash算法,得到值作为加密密钥,进行对称加密^[https://www.cnblogs.com/enoc/p/tls-handshake.html]
tls1.3
- 双方事先确定好使用哪种椭圆曲线,和曲线上的基点 G,这两个参数都是公开的;
- 双方各自随机生成一个随机数作为私钥d,并与基点 G相乘得到公钥Q(Q = dG),此时小红的公私钥为 Q1 和 d1,小明的公私钥为 Q2 和 d2;
- 双方交换各自的公钥,最后小红计算点(x1,y1) = d1Q2,小明计算点(x2,y2) = d2Q1,由于椭圆曲线上是可以满足乘法交换和结合律,所以 d1Q2 = d1d2G = d2d1G = d2Q1 ,因此双方的 x 坐标是一样的,所以它是共享密钥,也就是会话密钥。
具体流程
- 客户端发起请求,发送clirand
- 服务端发送证书,服务端serrand,告诉客户端选择哪一个椭圆曲线,相当于定好椭圆曲线基点 G,到现在都是明文状态
- 生成随机数作为服务端椭圆曲线的私钥,保留到本地;
- 根据基点 G 和私钥计算出服务端的椭圆曲线公钥,这个会公开给客户端。
- 检验证书合法性,这一步步骤和上文类似
- 客户端会生成一个随机数作为客户端椭圆曲线的私钥,然后再根据服务端前面给的信息,生成客户端的椭圆曲线公钥发给服务端
- 双方都有对方的椭圆曲线公钥、自己的椭圆曲线私钥、椭圆曲线基点 G。于是,双方都就计算出点(x,y),其中 x 坐标值双方都是一样的,x就是第三个随机数最后使用x+clirand+serrand生成对称密钥
每次握手的公私钥都不一样,使得具有前向安全性
QA
- 服务端随机数的作用
- 避免重放攻击
- 攻击路由直接截取https加密后的报文,等下一次再有相同https连接时候,重新发送
- 通过serrand,使得握手得到的secretrand,不同,避免重放
- 避免重放攻击
- 客户端随机数作用
- 和服务端一样避免重放攻击
- 作为salt
- 为什么不用secretrand作为随机数
- 高内聚低耦合,再密钥层面统一方法,和DH加密兼容,模块化
- 如何进攻https协议
tira-im加密
- client生成随机数clirand,和登陆的sessionid,用公钥加密(或者通过jwt使用id作为第三个随机数)上传到服务端
- server得到后解密,先通过session验证客户端身份,生成随机数serrand,并用私钥匙加密serrand,发送serrand和加密后内容
- client用公钥解密内容,比较是否和serrand相等,验证了服务端的身份,并且双方都使用md5(clirand+serrand+sessionid)作为aes对称加密的密钥
区别联系
- 因为app内置公钥,无需发送公钥的步骤
- 通过sessionid代替第三个随机数,使得简化了流程
- TSL需要cli发,ser发,cli发,才能协商成功,im只需要cli发,ser发就可以,简化步骤
- 这个可以复用im的一个req和一个ack的通道
缺点
- 不支持前向加密,所以一旦服务端的私钥泄漏了,过去被第三方截获的所有 TLS 通讯密文都会被破解
- 没有防止重放,RSA算法还是有点过时
- RSA性能不如ECDH,而且要达到非常安全密钥长度很大
- 产生密钥很费事,遭到素数产生技术的束缚,因此难以做到一次一密
微信

访问控制
MMTLS
- 这部分底层原理还是TLS1.3,但是加入时间戳的概念防止重放
- 加解密的过程和加密系统 > MMLAS类似,只是更加复杂
通用加解密
- 用于数据库的mac生成和校验,防止直接对数据库的篡改,以及其他需要业务侧的加解密的服务提供

其他方案
- 直接在代码或者配置文件里面写死密钥(弊端:内部人员可轻易从代码、配置中获得密钥)
- 在共享内存中明文存储密钥(弊端:attach内存,轻易获得)
- 密钥保存在指定运维同事才有权限登录的服务器上,业务进程定期RPC获取密钥缓存至本地(弊端:gdb业务进程轻易获取)
- 在指定运维同事才有权限登录的服务器上保存密钥及部署统一加解密服务,业务每次加解密操作都需要走RPC调用(弊端:RPC存在耗时高、网络波动、网络分区等风险,影响业务的可用性)
密钥svr和agent流程
- 通讯链路使用ECDH协商出来的对称密钥进行AES加密
业务和agent流程

- 通过SCM_RIGHTS,将自己的pid以及eventfda发送给agent
- agent通过pid以及eventfda拿到fd,自己也建立eventfdb,发送给业务
- 业务需要加解密的时候,将需要加解密的content写入共享内存,然后通过eventfda发送共享内存的地址给agent
- agent加解密之后,通过eventfdb将共享内存的地址发送给业务方
容灾
双agent
- 部署两个agent,分为开发Develop版、稳定Stable版。
密钥文件
用户大规模故障导致agent挂了
- SafeKeyBakSvr定期从SafeKeyStoreSvr拉取每个业务对应需要的密钥,按照每个业务一个密钥文件存储起来
- 当出灾时,SafeKeyAgent已无法正常加解密。运维执行事先已备好的shell脚本,将对应业务的密钥文件推送到出灾机器
- 出灾机器的BusinessProcess检测到本地密钥文件存在时,启动容灾机制,直接从密钥文件取得密钥,绕过SafeKeyAgent直接加解密数据
- 待故障恢复后,SafeKeyAgent把容灾的密钥文件删除。BusinessProcess恢复使用SafeKeyAgent进行加解密
- 为了降低出灾时BusinessProcess直接持有密钥所带来的可能泄露风险,待故障恢复后,更新对应密钥的版本,后续加密请求使用最新版本密钥。
临时加解密
- 针对SafeKeyAgent已拉取到密钥,而因为服务过载等原因导致处理超时严重的情况,我们通过后台下发容灾指令,SafeKeyAgent收到容灾指令以后,把密钥写入到共享内存,临时由BusinessProcess从共享内存拿到密钥,直接进行本地加解密,从而快速减轻SafeKeyAgent的服务压力。待故障恢复后,SafeKeyAgent把共享内存的密钥清除,恢复SafeKeyAgent加解密。
模块认证
MMLAS


流程
- client第一次连接的时候使用证书链的认证方式,Client的证书经过CA签名,Server用CA的公钥验证Client证书,再用Client证书中的公钥认证Client用私钥的签名。验证签名通过后看时间戳是否合法,合法则Server得到可信的Client身份了。实际上逻辑还是client调用的时候把证书和公钥都发过去,服务器拿着公钥和证书验证client身份,以及解出随机数,服务端生成服务端随机数之后通过公钥加密,client使用私钥解密的到随机数,并且两者使用对称加密.这种认证方式需要Client一次签名和Server两次验签,在短链接高QPS的场景下肯定是不可接受的。所以在这种认证过程中会协商出对称密钥TicketAuthKey,为后续基于Ticket的认证做准备。
- Server会有一套只有自己知道的密钥称TicketKey,Server用TicketKey把协商出来的对称密钥TicketAuthKey(MD5(cli_ran,svr_cli))和一些信息进行加密,生成Ticket,并把Ticket返回给Client。Client把Ticket和TicketAuthKey保存起来。这里svr不保存ticket以及TicketAuthKey
- 下次Client再向Server发起认证时,只需要用TicketAuthKey对当前时间戳加密,把加密时间戳和Ticket一起给到Server。Server用TicketKey解密Ticket得到TicketAuthKey,再用TicketAuthKey解密得到时间戳,如果时间戳在合理范围内则认证通过(这里是为了防止重放攻击)
- TicketKey并不是每个Server唯一,而是每个模块唯一,一个模块的所有Server共用一套TicketKey。这样Client只要向其中一台Server用证书/私钥认证通过获得Ticket,后续就可以用Ticket往模块中的任意Server发起认证。这种TicketKey只需要对称密钥解密,性能高,确保后台海量服务的高性能。
两者区别
- ssl-tls和tira-im本质上都是tls1.2的产物,底层非对称加密算法都是RSA,现在RSA已经被证明不安全,微信这一套用的是tls1.3使用ECDH和PSK更加先进和安全
- 微信使用时间戳实现防重放效果
端到端加密

- 底层原理就是依赖公钥私钥的不对称加密的性质
流程
- 用户生成密钥,在本地生成非对称RSA密钥
- 将公钥发送到服务器中
- 别人发消息时候先获取服务器中用户的公钥
- 将消息用公钥进行加密
- 用户获得消息后使用私钥解密 ^[https://juejin.cn/post/7330440381278486565]
QA
换主机更换密钥
- 登录之后判断用户密钥是否值当前机器的密钥,如果不是,那么替换密钥,这一步需要登录状态
- 这里可能出现问题是如果用户手机丢了,在他下一次换密钥之间的所有消息都无法解密了
多主机如何同步密钥
- 手机端为主,电脑端登录的时候可以通过手机生成随机6位的数字作为AES对称加密密钥
- 然后AES加密私钥上传到服务器
- 用户在电脑端输入这六位数字,拉取加密后的数据并解密,完成密钥同步
逻辑卷和物理卷
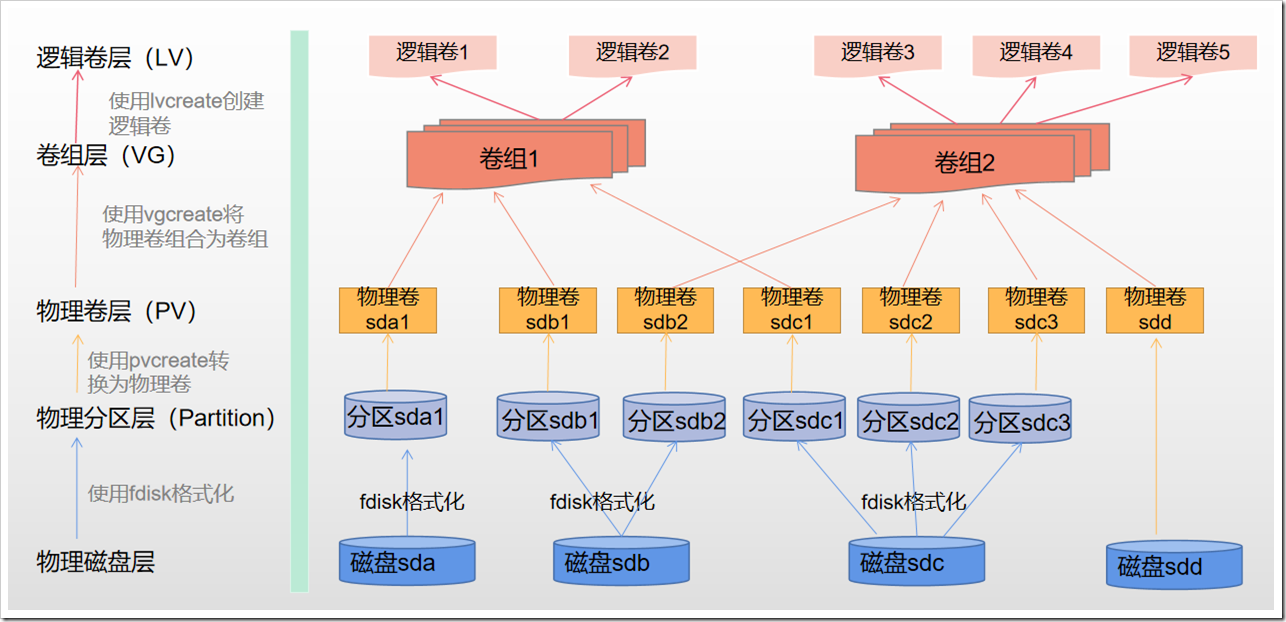
Minio
- 分布式对象存储工具
- 相当于文件管理的中间件,程序上传和下载直接和它对接而不是和系统对接,避免了分布式场景下文件的存储不方便不连通的问题
- #TODO 开了个新坑,找时间后面正好解决掉,感觉对这个兴趣不大,后面用到再解决吧
用户策略设置
- 下面是授权某个bucket,但是其他的bucket都不授权的方法
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:AbortMultipartUpload",
"s3:ListMultipartUploadParts"
// 根据需要,可以添加其他 s3 操作,例如 s3:GetObjectAcl 等
],
"Resource": [
"arn:aws:s3:::<your-bucket-name>",
"arn:aws:s3:::<your-bucket-name>/*"
]
}
]
}
Lustre
项目架构
泳道
[!question] 出现背景
- 关于一个服务上的多个需求的同时测试,存在服务抢占分支测试的问题;
- 不同的业务组在测试时依赖的第三方服务有改动或正在进行新需求测试影响本业务测试。
- 对服务链按需求进行分组复制,并实现逻辑、物理的隔离,使得不同需求的服务链运行在相隔的环境上,逻辑上如同游泳场中的泳道。

实际上就是解决多个微服务多个版本同时进行测试时候环境隔离的问题,服务注册发现只能发生在同一条泳道上
特性
- 泳道相当于提供了多条“请求的跑道”,理解泳道主要在于理解“流量跑到哪去了”:
- 泳道内如果没有部署被调用服务,流量会fallback到骨干 – 比如上图[泳道-2]中的B服务节点 调用了[骨干链路]中的C服务节点
- 泳道内若存在被调用节点,那么流量是一定不会fallback的 (包括不可用的和禁用的) – 比如上图[泳道-2]中的A服务节点 只会调用 [泳道-2]中的B服务节点,即使[泳道-2]中的B不可用,也是不会fallback的
- 骨干环境是一定不会调用到泳道内的 – 比如上图中绝逼不会有 从[骨干链路]到[泳道-2]的调用
- 泳道之间是一定不会互相调用的 – 比如上图中绝逼不会有 [泳道-1]与[泳道-2]之间的调用
MCV架构
model
- 数据库连接层,有关数据库的操作都在这一层
- 这一层出现错误不打日志,向上层传递到control层
control
- 核心逻辑层,实现核心且复杂的逻辑(传统的CURD业务一般这一层很少),需要调用的部分直接调用model层的内容
- 这一层出现的错误需要打日志记录并向上传递到view层
view
- 路由层,直接对接前端的数据,对数据进行基本的合法性校验,转换为内部格式后传递给control层
- 这一层出现错误不打日志,直接将错误返回给客户端
DDD架构
领域驱动模型

interface层
- 接入层和mcv中的view层类似,提供对外的接口
application层
也称为biz层
- 应用层,流程编排服务,不承担业务逻辑,只负责调用和组装application
domain层
- 核心逻辑层面,称为实体,直接操作数据库,以及实体的所有操作,但是不能调用和依赖其他任何的其他domain,降低耦合度,是实现的核心逻辑的地方
- domian之间禁止直接相互调用,必须相互隔离
DAO/Infeastructure层
- 任何数据源,包括数据库或者其他的系统
防腐层

- 核心就是通过独立一个层次为了防止第三方接口污染我们的领域服务,类似设计模式中的适配器模式,完成参数的映射
- 这样可以只更改防腐层的内容,不会影响领域内的内容,其实就是多加了一个中间层
MCV和DDD区别
- mcv被称为失血模型,因为实体的具体逻辑是在service层,如果操作复杂,很容易导致service膨胀,有点面向过程的味道,实体是在model,但是逻辑在service层
- DDD完全是面向对象式,充血模型,充血地方在于domain既是实体也承担了该实体的所有操作,可以想象成为一个类application只用于编排和组合
- DDD更加适合大型系统的开发,MCV更加合适用于小型的系统,DDD实在太复杂了,还引入了类似防腐层的概念
项目指标
服务降级
- 系统有限的资源的合理协调
- 概念:服务降级一般是指在服务器压力剧增的时候,根据实际业务使用情况以及流量,对一些服务和页面有策略的不处理或者用一种简单的方式进行处理,从而释放服务器资源的资源以保证核心业务的正常高效运行。
- 原因: 服务器的资源是有限的,而请求是无限的。在用户使用即并发高峰期,会影响整体服务的性能,严重的话会导致宕机,以至于某些重要服务不可用。故高峰期为了保证核心功能服务的可用性,就需要对某些服务降级处理。可以理解为舍小保大
- 应用场景: 多用于微服务架构中,一般当整个微服务架构整体的负载超出了预设的上限阈值(和服务器的配置性能有关系),或者即将到来的流量预计会超过预设的阈值时(比如双11、6.18等活动或者秒杀活动)
- 服务降级是从整个系统的负荷情况出发和考虑的,对某些负荷会比较高的情况,为了预防某些功能(业务场景)出现负荷过载或者响应慢的情况,在其内部暂时舍弃对一些非核心的接口和数据的请求,而直接返回一个提前准备好的fallback(退路)错误处理信息。这样,虽然提供的是一个有损的服务,但却保证了整个系统的稳定性和可用性。
比如遇到过年抢红包的时候朋友圈的延迟是可以接受的,直接返回没有新的朋友圈,把宝贵的资源用在重要的地方
- 降级分成3种
- 功能降级预案, 对下游某些依赖的功能的降级, 当然这块有时候和熔断一起用, 通常是某个功能模块走兜底或者暂时不可用
- 压力降级预案, 用于应对正常节假日等流量激增, 损耗一定的功能保证服务可用性正常
- 极端降级预案, 最坏的准备, 默认假设是所有下游全部崩溃, 所有的依赖全部完蛋, 只有自己能用的情况下如何给用户返回一些兜底的信息而非直接报错
服务熔断
- 应对雪崩效应的链路自我保护机制。可看作降级的特殊情况
- 概念:应对微服务雪崩效应的一种链路保护机制,类似股市、保险丝
- 原因: 微服务之间的数据交互是通过远程调用来完成的。服务A调用服务,服务B调用服务c,某一时间链路上对服务C的调用响应时间过长或者服务C不可用,随着时间的增长,对服务C的调用也越来越多,然后服务C崩溃了,但是链路调用还在,对服务B的调用也在持续增多,然后服务B崩溃,随之A也崩溃,导致雪崩效应
- 服务熔断是应对雪崩效应的一种微服务链路保护机制。例如在高压电路中,如果某个地方的电压过高,熔断器就会熔断,对电路进行保护。同样,在微服务架构中,熔断机制也是起着类似的作用。当调用链路的某个微服务不可用或者响应时间太长时,会进行服务熔断,不再有该节点微服务的调用,快速返回错误的响应信息。当检测到该节点微服务调用响应正常后,恢复调用链路。
- 服务熔断的作用类似于我们家用的保险丝,当某服务出现不可用或响应超时的情况时,为了防止整个系统出现雪崩,暂时停止对该服务的调用。
比如遇到A依赖B,但是B崩溃了,导致B请求很慢,导致A服务大延迟使用,整条链路上服务都会出问题,为了避免这个情况使用熔断,B模块的请求直接返回失败
吞吐量指标
- 通过响应时间Response Time(如P99,P95),最大每秒请求数(QPS),Concurrency并发数来衡量
QPS
- 每秒响应的请求数,通常用于衡量系统的处理能力。mysql的qps大概在几千到几万左右,redis在十万到百万级
RT
- 按照响应时间从小到大排序, 99%的接口响应时间即为 P99 的时间,通常来说,随着QPS和Con的上升,RT也会上升
Concurrency
- 指系统同时能处理的请求数量,这个也反应了系统的负载能力
测量方法
- 使用性能测试工具对系统进行压力测试,模拟多个客户端同时向服务器发送请求,以获得最高的QPS和网络并发数。在测试过程中,可以逐步增加请求的并发数,直到系统达到极限,即无法再处理更多的请求为止。这时,所得到的QPS和网络并发数即为系统的最高值。
- 在测试中同时监测系统的响应时间,以获得R99值。要获得R99值,可以先计算出所有请求的响应时间,然后按照从小到大的顺序排序,最后取出排在99%位置上的响应时间,即为R99值。
部署方式
Serverless
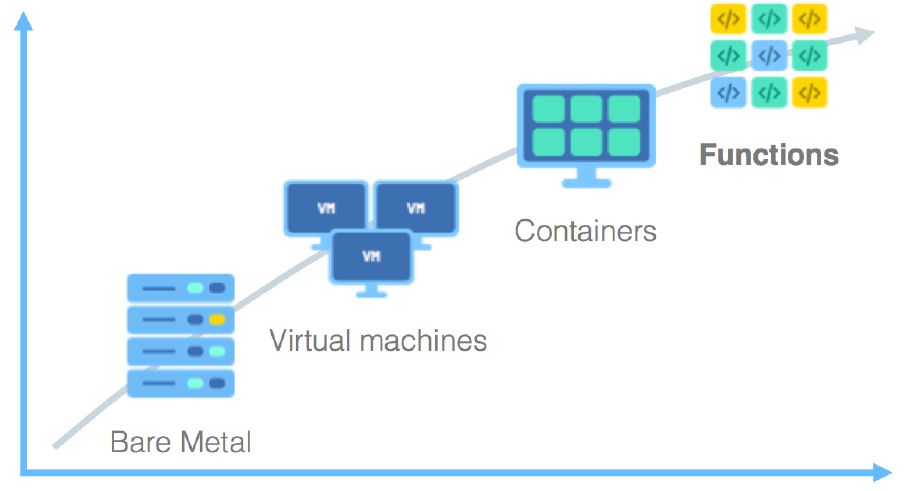
- 实际上是一个转变:实体机器->虚拟机(云服务器)->容器(docker)->云函数(serverless)
- 只需要关注核心逻辑的功能,不需要考虑资源和并发容灾的问题
优缺点
- 更加关注逻辑,将运维的工作完全替代,将扩容等操作交给云服务器厂商
- 不会有资源的浪费,按使用量付费
- 和框架强依赖,一旦换一家云服务器厂商,代码移植麻烦,自己存在的前提是云服务厂商存在
- 大部分是小厂在用
相关工具
工程Git使用
How to create an issue
- https://zhuanlan.zhihu.com/p/75691927
How to create an pr github
代码
兼容性
- 所有的程序和代码必须向下兼容,除非整体所有代码重构,所有对外的接口无论什么情况下都需要向下兼容
- 所有的字段绝对不能删除和更改!,所有的更新不能损坏已有的功能,需要做到绝对的向下兼容
整洁
- 圈复杂度尽量在10以内,保证长久的重构性
- 尽量避免代码重复,抽象成为公共的函数或者部分
个人感想
- 项目只有自己经历过自己去做过,才知道里面的易错点在哪里
- 项目只有上线过,有用户使用,才知道系统的瓶颈在哪里和如何改进
- 自己看懂的项目只知道原理,但是并不知道项目的核心要点目标是什么,核心难点是什么,这样的项目拿出去讲只会露馅,只有自己做过的项目,实际上上线了的项目才能作为核心拿出来讲
系统设计要点
系统设计四步法
- 了解问题并确定设计范围:确认一下这个设计题目的设计重点在什么地方,大概需要承受多大的流量和DAU
- 提出高层次的设计:整体上的架构设计,比如设计用到什么组件,这些组件分别在哪个地方,也可以画个草图
- 设计重点实现的部分:有些部分是这个系统设计的重点,比如短链系统的url hash计算生成,im系统的推拉模型
- 讨论后续问题:比如哪个地方可以优化,性能瓶颈在怎么地方,如何进行水平扩展
三大要点
- 结构性: 怎么划分结构层次, 最重要的性质, 直接决定了整个系统的可维护性以及优雅性, 是系统设计最底层的部分
- 扩展性: 但这个系统承担更多的业务需求, 出现更多的业务场景时候如何应付复杂度的提升, 这个时候时候是否会会损坏系统的结构性和优雅性
- 容灾性: 但出现不可预期的风险时候如何作兜底容灾而不是系统直接 down 掉, 如何减少下游依赖并且默认下游不可用性
- 前面一点是传统的系统设计的基础,也是之前一直学得, 后面两点才是工作之后才发现一样重要的, 特别是当你处理的是高度复杂的业务系统和不停迭代的用户需求以及高可用性的保障时
代码仓库管理方式
- monorepo 和 multirepo
monorepo
- 相当于大型的仓库, 整个项目相关的所有代码都放到一个 git 仓库统一管理, 类似google 就是采用 monorepo
- monorepo可以避免下面 multirepo 出现安全性的问题, 因为 lib 和 src 作为一起的 review 可以轻易发现错误的代码
multirepo
- 目前绝大多数公司采用的方式, 按照 功能/mcv/ddd 来进行划分, 每个git仓库就是一个微服务或者共享的 lib库
- 这种对于 go 来说有个致命的缺点, 不安全性
- go 可以直接通过 go get 将包直接引入, 这种情况下即使是分支也可以直接引入, 但是如果恶意代码放在某个 lib 的 banch 上(这是非常简单的, 创建分支的权限 rd 都有的), 然后通过 go get 引入, 这种情况下 go.mod 只会记录hash 值, 甚至不会计算时间, 这就导致 codereview 所有的 go.mod 的依赖基本是不可能的 , 最后就是可以轻松实现注入恶意代码
参考
- https://zhuanlan.zhihu.com/p/337708438
微服务
定义
微服务,又称微服务架构,是一种架构风格,它将应用程序构建为以业务领域 为模型的小型自治服务集合。
特点和优点
- 解耦—系统内的服务很大程度上是分离的。因此,整个应用程序可以轻松 构建,更改和扩展,这样可以最大程度避免代码堆积难以维护,极大降低程序耦合度
- 组件化—微服务被视为可以轻松更换和升级的独立组件
- 业务能力—微服务非常简单,专注于单一功能
- 自治—开发人员和团队可以彼此独立工作,从而提高速度
- 持续交付—通过软件创建,测试和批准的系统自动化,允许频繁发布软件
- 责任—微服务不关注应用程序作为项目。相反,他们将应用程序视为他们 负责的产品
- 分散治理—重点是使用正确的工具来做正确的工作。这意味着没有标准化 模式或任何技术模式。开发人员可以自由选择最有用的工具来解决他们的 问题
- 敏捷—微服务支持敏捷开发。任何新功能都可以快速开发并再次丢弃
- 接口的定义和实现是分离的,完全不需要等待实现,根据接口就可以进行完整的编程,符合设计模式 > 依赖倒转原则
- 耦合度降低,不同模块开发代码隔离化,业务独立设计,更加灵活,泳道实现的基础
- 接口实现分离,提高开发效率
- 风险隔离,耽搁服务不影响整体,更好做熔断和限流
- 扩展简单,可以按照不同微服务的负载独立化扩展,资源更高效
缺点
- 不可避免的因为rpc调用使得请求的时间被延长,延迟变长
- 链路监控变得复杂和治理难度增加
- 分布式系统带来的问题,CAP定理
常见负载均衡策略
- 简单随机
- 加权随机
- 简单轮询
- 简单加权轮询
- 平滑加权轮询
- 一致性哈希
- 最少活跃数
coa

- 通过etcd的强一致性保证分布式结构下请求打到正确的地方
- 负载均衡以及服务监控状态下线隔离都是通过client实现(coa-client),client自己通过负载均衡选择需要连接的节点
- 如果没有client监控以及这个微服务没有其他的实例,那么租约过期没有续约会直接被删除而不会加到隔离的文件夹(当然自己也会监听其他的同类型的微服务实例)
具体流程
service
- service首先定义好interface(相当于接口定义),使用脚本生成一个interface仓库作为sdk
- 面向接口编程,首先service先在etcd注册service_url,并通过心跳保活维持online租约val为自己的端口号和ip(需要内网,因为无法自己获取外网ip),一旦服务失效心跳过期,online失效,如果有监控这个service_url的微服务(比如客户端),会把这个key放到隔离区
client
- client调用的时候,将所有的online下的key获取,进行负载均衡,计算这个请求给哪个受理,将参数格式化后通过msgpkg协议传输,等待相应结果并返回
QA
coa和go-micro,grpc框架有什么区别
- coa使用go的反射特性,使用redis-msgpack序列化,和其他使用protobuf不一样
- coa只支持go的,其他可以跨语言支持,因此coa框架更加简洁,不会需要
.pb文件,但是扩展性(插件的开发)和兼容性比较差 - micro是一个微服务系统,提供服务的注册与发现的功能,grpc是rpc一个数据传输的方法,是一个rpc框架,coa两者都有,但是更加接近于grpc
缺点
- 强依赖etcd,一旦etcd出问题,所有的rpc都会失败,中心化严重(虽然etcd可以集群部署,但是一旦出现半数崩溃,系统就直接崩溃)
- 服务一旦被隔离,没有很好的解决办法接触隔离,只能人工解除隔离,这样如果出现区域的网络波动导致大面积隔离就会崩溃
优点
- 每次rpc服务发现的都是节点的最新状态,消息滞后的现象出现少
- 不需要中心服务routesvr,中心直接通过etcd实现,简化流程思想
- 小而美的微服务框架,但是可用性不够高,容灾能力差
svrkit
- 微信内部微服务框架,精简版开源地址
服务发现

- 使用很特殊的方式进行,每台机器会部署zkagent,这里采用主动pull模式,zkagent会定时从本IDC的zkagentproxy拉取任务,更新本地配置文件。但是每个server部署还是回向中心的zookeeper,报备更新路由信息
- 机器上所有的发现服务都是直接在本地文件中获取,不会从中心的zookeeper中获取,更加快捷
- 每次rpc调用都会进行上报和监控到routesvr,使得如果出现多次不可用的现象就会进行屏蔽机器

优点
- 极致的可用性,提供中心化的服务发现的服务,的确实现简单,但有巨大单点风险,一旦服务挂了,所有的服务都不可用了。而svrkit 的服务发现是去中心化的,无论是哪个角色: route svr, zookeeper, zkagent, route report thread 挂了,只要本地路由文件没有被删除,都不会影响调用下游服务
- 高容灾能力,及时出现网络波动也能很快恢复正常
缺点
- 实时性不够好,如果服务出现问题,需要足够时间才能发现出问题,然后还需要agent主动pull,因此实时性不够好
- 这个需要大规模系统和完成成熟的配套措施才能解决,不然很容易出问题,只适合大公司使用
服务屏蔽
mmlbapi提供给Svrkit 框架使用,用于收集统计信息和检查路由是否可访问mmlbagent是常驻进程, 负责当前机器上所有模块的访问结果统计数据收集和生成屏蔽策略,并将策略结果和统计数据及mmlbagent的运行情况上报到mmlbcenter.用于判断路由是否故障的统计数据包含:网络连接失败,读失败,写失败,逻辑错误等等。mmlbcenter收集现网所有的mmlbagent的上报, 进行数据合并和入库存储.
- 屏蔽周期:当某个服务实例被故障判断策略确定为异常时,会将该实例摘取掉,
mmlbapi在做路由选择时会忽略掉异常节点 - 探测周期:我们肯定在服务实例恢复之后,就解除屏蔽,但我们不知道服务实例什么时候恢复。因此在屏蔽时,会计算一个故障屏蔽时长,mmlbagent会定期检查屏蔽策略是否超时,需要进行恢复探测。若该路由被故障恢复策略确定为正常时,则解除屏蔽该实例,恢复其为正常;否则则继续屏蔽(Netflix 的Hystrix 熔断组件也提供了类似的熔断-恢复机制)
框架实现(Phxrpc)



过载保护
- 开一个现成一段时间检查一次
- 检查平均响应耗时是不是比设置的大,如果是就调整拒绝率
- 每个请求过来之后随机根据拒绝率直接拒绝
特点
- 没有任何服务注册发现,服务发现全靠client的配置文件
- 一大堆缓冲buf削峰
- 相当于包工头机进行层层分发任务工作
一些感想
微服务正在被滥用
无限长的链路
- 实际上在字节工作了之后, 发现一条链路可以长达 8个微服务才到尽头, 一个微服务调用的延迟可以达到 10ms, 那么仅仅画在网络开销上的延迟就已经到达了 80ms, 而且延迟放大的现象非常严重, 最外层的服务非常容易超时, 一套下来基本延迟得至少 500ms
无限多的负责人
- 每个服务,都有不同的负责人, 中间任何一个微服务出现错误, 都会让这个请求的链路直接断掉, 然后所有上游业务开始不停报警, 经常出现的情况是, 底层存储崩了, 从入口开始一层一层往下拉了无数多的人
混乱的责任划分
- 无限长链路的根本原因是微服务责任的不明确, 之前字节一直是按照 MCV 架构搭建的 工程总结 > MCV架构 这会出现非常大的 bug , 假设 0 入口层, 1逻辑层, 2 存储层
- 理想状态: a0 -> a1 -> a2
- 实际状态: a 服务需要调用到 b 服务提供的接口, b 需要 c 提供的接口, 然后链路就变成下面这样长了, 如果后面再涉及其他业务的调用, 一个入口的 请求路上可能涉及到十几个微服务的调用
a0 -> a1 -> a2
-> b1 -> b2
-> c1 -> c2
想法
- 软件开发没有银弹 : 为了快速迭代, 降低耦合度的代价就是长期的难以维护 , 短期最快和长期维护本质上永远都是冲突的, 很多方案都是用一些折中的方式, 类似 DDD 和字节的流程化
- 参考 https://cloud.tencent.com/developer/article/1396622

分布式向量检索
- 实际上就是一个knn的模型
[!tip] KNN 如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别
kdtree
-
用于快速检索最近的k个点
kdtree
[!tip] 参考 https://www.joinquant.com/view/community/detail/c2c41c79657cebf8cd871b44ce4f5d97
结构
struct kdtree{ Node-data // 数据矢量 数据集中某个数据点,是n维矢量(这里也就是k维) Range // 空间矢量 该节点所代表的空间范围 split // 整数 垂直于分割超平面的方向轴序号 Left // kd树 由位于该节点分割超平面左子空间内所有数据点所构成的k-d树 Right // kd树 由位于该节点分割超平面右子空间内所有数据点所构成的k-d树 parent // kd树 父节点 }- 实际上有点类似Mysql底层原理 > 联合索引,首先选取第一个坐标(这个点中位数最好,不是的话左右两边点数量会有影响),将所有数据大于这个的放在左边,小于这个的放置在右边,建立类似二叉树
- 然后选择第二个坐标,如法炮制,直到所有坐标都放进去
查找过程
- 设 L 为一个有 k 个空位的列表,用于保存已搜寻到的最近点
- 根据 p 的坐标值和每个节点的切分向下搜索,根据第一个属性比较
- 当达到一个底部节点(这里是必须是最底下的节点)时,将其标记为访问过。如果 L 里不足 k 个点,则将当前节点的特征坐标加入 L ;如果 L 不为空并且当前节点的特征与 p 的距离小于 L 里最长的距离,则用当前特征替换掉 L 中离 p 最远的点
- 如果当前节点是整棵树最顶端节点,算法完成,如果不是
- 向上爬一个节点。如果当前(向上爬之后的)节点未曾被访问过,将其标记为被访问过,然后执行 下面的1和2;如果当前节点被访问过,再次向上爬
- 如果此时 L 里不足 k 个点,则将节点特征加入 L;如L 中已满 k个点,且当前节点与 p 的距离小于 L 里最长的距离,则用节点特征替换掉 L 中离最远的点
- 计算 p 和当前节点切分线的距离。如果该距离大于等于 L 中距离 p 最远的距离并且 L 中已有 k 个点,则在切分线另一边不会有更近的点,执行(三);如果该距离小于 L 中最远的距离或者 L 中不足 k个点,则切分线另一边可能有更近的点,因此在当前节点的另一个枝从(1)开始执行.这一步是核心:如果比中线分割线的距离都比目前所有的远就不用找另外一边了,==注意不是中间的点,是中间的分割线,这才是最短距离==
- 向上爬一个节点。如果当前(向上爬之后的)节点未曾被访问过,将其标记为被访问过,然后执行 下面的1和2;如果当前节点被访问过,再次向上爬
缺点
- 对于高维数据不友好,未读高了之后大量数据在边界,使得分割效果不好
- 对于数据分布敏感,如果出现数据集分布不均的问题很容易导致树高低不平影响查询效率,包括后续的添加也会影响高度
- 添加数据之后维护非常麻烦
局部敏感哈希
- 欧式空间中,将高维空间的点映射到低维空间,原本接近的点在低维空间中肯定依然接近,但原本远离的点则有一定概率变成接近的点。

- 选取多个合适的哈希函数,将向量哈希化后放入结果的bukket中
- 相识寻找的时候直接将找多个bukket的and 或者or(看业务需要,大部分是直接and)
- 核心方法是用空间换取时间,计算非常简单
- 缺点
- 并不是完全精确,很可能出现错漏的情况
- 和hash函数关联性强,数据量和会影响整体的效果,数据量大用小桶+and,数据量小用大桶+or
- 点数越多,我们越应该增加每个分桶函数中桶的个数;相反,点数越少,我们越应该减少桶的个数;
- Embedding 向量的维度越大,我们越应该增加哈希函数的数量,尽量采用且的方式作为多桶策略;相反,Embedding 向量维度越小,我们越应该减少哈希函数的数量,多采用或的方式作为分桶策略。
Grose

- 服务的节点只负责提供api和先数据库中写入反馈之类的
- worker负责计算用户最喜欢的物品然后写入数据库中
- master负责收集信息并指挥worker干活
参考
- https://nxwz51a5wp.feishu.cn/docs/doccnsvpGMaaLfmOu1LAmorDH4b
- https://gorse.io/zh/docs/
- 整个支付系统的核心是所有接口的幂等性保证+整个事务的可查性
- 幂等性保证是为了防止重试情况下的多次操作,一般每次操作都需要分配唯一ID保证幂等性
- 可查性是为了保证事务出现宕机之后恢复依旧能恢复到正常状态,主从事务可以直接使用事件中心消息队列,但是多主事务需要维护本地消息表
复式记账法
- 恒等式: 资产=负债+所有者权益
- 等式的左边资产是可用的资源,是公司的权利,而等式的右边是为了解释左边而存在,用来说明资产的来源,是公司的义务
- 核心就是借贷相等,使用记录两次的办法实现.一笔数至少记两次,至少会在两个相关的账户中记录金额相等,借贷相反的记录,两个账户的类型可以是相同的(比如都是负债类账户),也可以是不同的。
数据库设计
个人余额
- 账户ID,这个ID有的平台会有编码规则,比如某些位用来区分个人或者商户,区分币种以及校验位等。
- 币种
- 余额,一般使用币种最小单位。
- 账户状态,比如是正常态、支付或者冻结等。
- 余额版本号,这个字段非常重要,体现了余额的变化过程,是与流水进行关联的关键。
流水信息
当余额发生变更时,需要记录流水,以此来跟踪余额的变化
- 流水ID
- 凭证ID,一般是业务单号(如订单ID、退款单ID等),也就是下面凭证中的ID。
- 发生金额
- 发生币种
- 起始余额
- 终止余额
- 余额版本号,与余额信息中的版本号字段对应。
- 资金方向,标识是入账还是出账。
- 源账户ID
- 目的账户ID
- 交易时间戳
凭证
凭证用来记录交易过程中的信息,是用户交易的依据。凭证对应到支付平台内部的各种单类,比如充值单,体现单,交易单等等。理论上可以放到业务层,不放在账户核心层,这个相当于本地消息表的功能,记录事务目前的状态,也是非常重要
- 凭证ID
- 交易参与方,可能是两方,也可能是多方
- 交易金额、交易类型
- 交易状态,比如支付中,支付成功,转退款等
- 交易渠道
账户
- 个人账户,一个人一个账户,这个被叫做是C账户,是现金账户,个人可以完全支配。
- 商户账户,商户账户因为需要结算等,所以一个商户有两个账户,一个B账户(中介账户,理解为待结算账户),一个C账户(现金账户)。当用户支付时,实际支付到了商户的B账户,这个账户里面的资金商户不能自由支配,待平台结算后(扣除手续费等),资金被转移到C账户,这个账户商户是可以自由支配的,比如可以提现到商户自己的银行卡。
- 银行账户,第三方支付公司为各个银行设置的账户,这个账户是一个总账账户,记录与银行之间的资金变动,一般不记录余额,而只是记录流水,方便跟各个银行进行对账。

分布式事务模型
-
和微信支付的分布式事务类似
微信支付
- 使用两阶段提交+MQ事务的方法保证最终一致性,分为主事务和从事务,主事务成功后,不停尝试执行从事务
- 如果是面对面转账这种强一致性的多主事务,需要使用mysql的事务机制,加上TCC的机制
- 如果为代扣的这种事务就是先创单(主事务),然后延迟打钱(从事务)
事件中心
- 底层是消息队列
- 解耦,就是对事务分主次:
- 主事务一般是核心逻辑,逻辑重,同步调用;
- 从事务一般是次要逻辑,逻辑轻,异步调用。
- 第一阶段是prepare,将消息暂存到事件中心,但是不发布,等待二次确认;prepare后,业务执行主事务(一般是rpc远程调用),成功就发commit给事件中心,投递消息到从事务;失败就发rollback给事件中心,不做投递。
- 这里需要两阶段提交的原因是:我们常规理解的入队操作,也就是一阶段提交,无论是放在主事务执行前,还执行后,都无法保证最终一致。考虑如下场景
如果是先做主事务,再入队,那可能入队前就宕机了; 如果是先入队再做主事务,那可能主事务没做成功,但从事务做成功了。
- 所以无论哪种做法都有问题,二阶段提交是必须的。
反查
- 如果prepare后没有进行commit或者rollback(消息丢失或者系统重启),事件中心就会主动下发消息询问主事务执行的结果
普通消息
- 普通消息直接通过事务中心执行所有事务
- 两个必须要用事务消息的场景:
第一是事务逻辑复杂,也就是发生逻辑失败的概率大,比如扣款前要检查余额是否足够,如果余额不足,那在异步流程中重试多少次都是失败。
第二是事务不可重入,例如业务系统入队时并未确定一个唯一事务ID,那各事务就无法保证幂等,假设如果其中一个事务是创建订单,不能保证幂等的话,重试多次就会产生多个订单;所以这里需要用事务消息,明确一个分布式事务的开始,生成一个唯一事务ID,让各个事务能以这个事务ID来保证幂等。
事件中心设计
- 事件中心的本质是队列驱动事务,所以要满足常见的队列功能,比如多订阅、出队有序、限速、重试等等
- 订阅者用于执行从事务
- Producer是发布者,Consumer是消费者,Consumer用推模式将消息推给Subscriber订阅者,这都是比较好理解的。然后来看Store,队列存储Store的实现选择了Paxos,是因为Paxos能保证副本一致,可避免乱序/去重问题,非常适合队列模型。Paxos协议的正确运行需要同步刷盘,副本同步数3份,这能提高数据可靠性。朴素Paxos的性能不是很好,所以通过批量提交的方式保证写入性能。
- 接着来看Scheduler,Scheduler是Consumer的协调者,通过与Consumer维持心跳,定义Consumer的生死,实现容灾;同时收集Consumer负载信息,实现负载均衡。Sched还依赖分布式锁Lock来选举master,只有master提供服务,自然实现容灾和服务一致性。
- 最后来看Lock,Lock是一个分布式锁,不仅用来给Scheduler选master,他还服务于Consumer,防止负载均衡流程中多个消费者同时处理一条队列。
- 这里Consumer的负载均衡流程也是一个二阶段提交,第一阶段是Consumer先跟Scheduler确定自己该处理哪些队列,第二阶段是访问Lock对队列抢锁,只有抢到锁后才能开始处理。
- kv查无记录时反查业务。只有确认commit,Consumer才会投递消息给订阅者。
多个主事务
-
类似TCC的机制,预锁资源的方法
这里也可以通过补偿的方式,但是中间态会短暂暴露
-
事务预写的具体做法是,将主事务1中会导致逻辑失败的部分,提前到prepare前执行,从而减少prepare...commit/rollback之间的事务个数。主事务1的执行结果在提交前并不对外可见,所以即使该结果不回滚,也不破坏一致性。与TCC中的Try操作类似。
优缺点
优点
- 减低耦合度和业务入侵性,相当与把本地的事务表存储在MQ中
- 吞吐量大,不会涉及2pc的阻塞问题
缺点
- 从事务默认可以通过重试成功(因为没有提供主事务补偿的机制),导致不能覆盖所有应用场景
- 需要提供反查的接口,增加复杂度
参考
- https://zhuanlan.zhihu.com/p/263555694
- https://www.cnblogs.com/cbvlog/p/15458737.html
先借后贷
- 先在mysql中启动事务减少用户金额并生成用户流水
- 异步增加商户的金额并生成商户流水,也是mysql事务实现,如果失败了就重试
- 一定先减少后增加,因为增加一般能成功,扣款不一定

二维码付款
核心代码没有权限看,以下为个人推测
商户扫用户码
-
用户如果开通离线付款就后台下发一批code_id(按照顺序),否则就没每次在线生成一个code,这个code按照唯一key插入数据库中(生成的过程需要验票),这样也可以分为两种code,key和个人的信息,过期时间等加密生成token(这部分也可以使用session)之后发送给用户(这里需要长连接)
-
商家的pos机扫码之后,将token和自己要的钱带上自己的商户票据发送到后台服务器,服务器检测code的有效性(过期时间),商户账户有效性等
-
生成凭证,mysql的一条记录,其中包括了交易目前的状态等信息,生成交易的唯一ID,code_id作为唯一key,防止重入插入,订单的唯一性id可能是 业务+hash(uid)+string(time)+自增id 最后异或的方式生成,可以保证唯一性,也可以参考 分布式ID生成
-
向事务中心publish, 凭证的ID作为key
-
调用扣款的rpc接口作为主事务
- 开启主事务
- 生成流水,插入mysql中的流水中,这里的凭证ID需要作为唯一key防止重入
- 扣用户钱
- 提交主事务
-
如果扣款rpc返回成功,更改订单状态为已扣款(这里需要使用状态机的性质切换)
即使在这里崩溃了,通过事务中心的重查也能在这里进行重试
-
提交commit到事务中心
-
返回客户端成功,并提交事务到事件中心,主流程就不管了,自己编写订阅者订阅消息
- 订阅者调用扣钱的rpc作为从事务
- 从事务开启
- 插入流水ID,这里需要使用凭证ID作为private key防止重入(这里如果出现两个事务都在操作同一个订单必定出现一个成功一个失败,通过mysql保证)
- 商家加钱
- 提交从事务
- 如果加钱不成功判断是否为重入,重入判定为成功(说明已经扣钱成功),如果错误,返回让事务中心进行重试
- 更新订单状态为已加款
- 订阅者调用扣钱的rpc作为从事务
用户扫商家二维码
- 这部分感觉比较普通,因为这个二维码可以随意传播,因此肯定不会放敏感内容(不会放token),可能设置一个session用于标记二维码是否过期以及基本信息等,转账的校验核心在扫码拉起付款界面之后才进行后端校验
微信红包系统

[!help] 这部分可以作为秒杀系统的一个例子demo,秒杀参考
红包金额分配
redis和mysql数据一致性问题
- 无法保证强一致性,只能保证最终一致性
- 根本原因是因为,redis和mysql操作不是原子操作(因为跨系统)
先操作缓存
- 删除redis缓存
- 更新mysql数据库
缺点
- 更新mysql时候其他线程读取mysql,导致旧值存在于缓存中,因为这种可能发生可能性大,因此用的少
先操作数据库Cache Aside Pattern(旁路缓存模式)
- 更新mysql
- 删除redis缓存
优点
- 就算有旧值后面也会被删除
缺点
- 更新mysql时候其他线程读到旧值,但是因为网络波动,在删除缓存后写入旧值,导致旧值存在缓存中(发生概率还是比较小的,用的比较多)
延时双删
- 删除缓存(避免读到旧值,但是通常可省略)
- 更新数据库
- 睡觉一会(几十ms左右)
- 删除缓存(删除可能其他线程写的脏缓存)
优点
- 更大可能性不会出现第二种的问题
缺点
- 时间难以把控
- 性能减低(睡觉的原因)
其他
MQ
- 通过MQ把DB和redis解耦,把删除任务扔到MQ中,通过MQ保证执行的顺序和串行化
为什么不是update而是delete
实际上字节用的就是这种
- 避免A先改,B后改,但是因为网络问题,B先更新缓存,A把旧缓存更新的问题(这个感觉发生可能性比较小)
- 如果写的比较多,那么频繁更新缓存影响性能
解决缓存命中率低
- 如果要求强一致性,那么可以通过分布式锁避免其他线程操作
- 最终一致性,可以DB更新后,更新一个生存时间非常短的缓存,减低影响
总结
- 只能用于一致性要求不这么高,但是更新频繁,读取频繁的情况,比如好友数量,消息热度这种
- 真正账户余额这种还是要么不用redis,直接mysql读(数据小),要么上etcd这种强一致性的数据库
数据一致性的其他解决方案
binlog 删除
- 订阅mysql binlog, 如果出现update 情况就删除 redis 中的数据
- 读时候miss就顺便缓存
优点
- 写操作和 redis接耦
- 删除缓存极端 case 得到缓解
缺点
- 多出一个组件, 复杂性增加
- 更新之前的缓存是脏的, 短时间的错误数据
binlog 更新
- 优点和缺点类似
- 这个将删除改为更新, 但是有个问题时这个依赖 mq 的顺序消费的特性, 都者数据会是错误的
- 这个也会出现一段时间缓存是错误的
read-Through和write-Back
- 相当于外部封装了一层sdk, 所有的操作直接写入缓存之后马上返回, 返回之后缓存再写入 db中, 读的时候也是读缓存, 读取不到 sdk自行处理(感觉相当于封装了一个存储)
facebook 一致性方案
- get 使用 udp 进行连接数据传输, set/delete 使用tcp进行数据传输, udp失败的情况直接当做 cache miss处理
- 使用 lease 机制保证按顺序写入缓存, 针对一个特定的Key,当第一次查询出现Cache Miss的时候,会为它产生一个Lease返回给Client,Client在查询到真正的值之后Set Memcache的时候必须带上这个Lease,这样才能通过合法性检查。多个并发 get 的情况下只有一个能拿到 lease 写入 cache 其他需要等待 cache写入后读取
- 这里可能出现问题时拿到 lease 及进程意外退出, 导致 lease 无法写入, 这里可以通过设置 lease 有效期进行缓解(但是在有效期期间这个 key还是处于失败的状态)
缓存雪崩
- 缓存大规模失效,导致请求大规模打到mysql情况
- 此时mysql宕机,马上重启也会有大量数据导致宕机
产生原因
- redis崩了
- key失效时间设置得都差不多
解决办法
- 失效时间设置好一点(比如加上随机数)
- 熔断保护机制.当流量到达一定的阈值时,就直接返回“系统拥挤”之类的提示,防止过多的请求打在数据库上。至少能保证一部分用户是可以正常使用,其他用户多刷新几次也能得到结果.
缓存击穿
- 某个热点key没了,导致大量请求打到mysql上(mysql存在,redis不存在)
解决办法
- 设置热点key永不过期
缓存穿透
- 大量恶意的不存在的数据请求,导致大量请求持续打到mysql上(mysql不存在,redis不存在)
解决办法
- 其他系统 > 布隆过滤器,一种bitmap,将存在的key或得到结果,如果查询的key和其或结果和原来不一样,说明key不存在
缓存预热
- 在刚启动的缓存系统中,如果缓存中没有任何数据,如果依靠用户请求的方式 重建缓存数据,那么对数据库的压力非常大,而且系统的性能开销也是巨大 的。
mysql索引失效
- 对索引使用左或者左右模糊匹配
- 使用左或者左右模糊匹配的时候,也就是
like %xx或者like %xx%这两种方式都会造成索引失效。因为索引相当于前缀匹配 - 使用左模糊匹配(like "%xx")并不一定会走全表扫描,关键还是看数据表中的字段。如果数据库表中的字段只有主键+二级索引,那么即使使用了左模糊匹配,也不会走全表扫描(type=all),而是走全扫描二级索引树(type=index)
- 对索引使用函数或者进行表达式计算
- 如
select * from t_user where id + 1 = 10;
- 对索引隐式类型转换
- 联合索引非最左匹配
- WHERE 子句中的 OR
redis为什么这么快
- Redis 的大部分操作都在内存中完成,并且采用了高效的数据结构,因此 Redis 瓶颈可能是机器的内存或者网络带宽,而并非 CPU,既然 CPU 不是瓶颈,那么自然就采用单线程的解决方案了;
- Redis 采用单线程模型可以避免了多线程之间的竞争,省去了多线程切换带来的时间和性能上的开销,而且也不会导致死锁问题。
- Redis 采用了 I/O 多路复用机制处理大量的客户端 Socket 请求,IO 多路复用机制是指一个线程处理多个 IO 流,就是我们经常听到的 select/epoll 机制。简单来说,在 Redis 只运行单线程的情况下,该机制允许内核中,同时存在多个监听 Socket 和已连接 Socket。内核会一直监听这些 Socket 上的连接请求或数据请求。一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。
redis做消息队列的几种方式以及缺点
1. LIST+BRPOP
优点
- 消息下发延迟小
- 消息积压下表现好
- 多个程序BRPOP此时有数据只会通知一个程序
缺点
- 消息ack麻烦,无法确定是否成功处理,无法真正保证必达性
- 不能做广播模式
- 不支持重复消费以及分组消费
2. 发布订阅模型
优点
- 多信道订阅,消费者可以同时订阅多个信道,从而接收多类消息,典型的广播模式,一个消息可以发布到多个消费者
- 消息即时发送,消息不用等待消费者读取,消费者会自动接收到信道发布的消息
缺点
- 消息一旦发布,不能接收。换句话就是发布时若客户端不在线,则消息丢失,不能寻回
- 不能保证每个消费者接收的时间是一致的
- 若消费者客户端出现消息积压,到一定程度,会被强制断开,导致消息意外丢失。通常发生在消息的生产远大于消费速度时 可见,Pub/Sub 模式不适合做消息存储,消息积压类的业务,而是擅长处理广播,即时通讯,即时反馈的业务/
3. Stream流模型
[!tip] 参考 https://www.jianshu.com/p/d32b16f12f09 https://zhuanlan.zhihu.com/p/496944314 https://cloud.tencent.com/developer/article/2331486 https://juejin.cn/post/7094646063784525832 https://www.cnblogs.com/coloz/p/13812840.html
使用命令
结构体
stream
typedef struct stream {
rax *rax; // 是一个 `rax` 的指针,指向一个 Radix Tree,key 存储消息 ID,value 实际上指向一个 listpack 数据结构,存储了多条消息,每条消息的 ID 都大于等于 这个 key 的消息 ID
uint64_t length; // 该 Stream 的消息条数
streamID last_id; // 当前 Stream 最后一条消息的 ID。
streamID first_id; // 当前 Stream 第一条消息的 ID。
streamID max_deleted_entry_id; // 当前 Stream 被删除的最大的消息 ID。
uint64_t entries_added;// 总共有多少条消息添加到 Stream 中,`entries_added = 已删除消息条数 + 未删除消息条数`
rax *cgroups;// rax 指针,也指向一个 Radix Tree ,**记录当前 Stream 的所有 Consume Group**,每个 Consume Group 的名称都是唯一标识,作为 Radix Tree 的 key,Consumer Group 实例作为 value
} stream;
// 结构体,消息 ID 抽象,一共占 128 位,内部维护了毫秒时间戳(字段 ms);一个毫秒内的自增序号(字段 seq),**用于区分同一毫秒内插入多条消息**。
typedef struct streamID {
uint64_t ms;
uint64_t seq;
} streamID;
- stream中使用树和堆 > radix tree实现消息列表而不是list
[!info] 原因
- redis的消息支持根据id删除,因此需要有索引的出现,因此不能单纯用list
- redis的消息支持顺序消费,而且key大量重复,因此不能直接用hash
- 节省空间,而且因为redis默认使用时间戳+顺序编号作为id,公共前缀比较长,可以节省空间
- value的类型是redis实现 > 压缩列表,直接存储的就是消息的id和内容
- listpack的所有key都是增加的,比叶子节点的node大
- 消息的id是(毫秒时间戳-序号)
consumer group
/* Consumer group. */
typedef struct streamCG {
streamID last_id;// **已经获取了,无论是否ack的id**
long long entries_read;
rax *pel;
rax *consumers;// key是消费者name,val是消费者实体
} streamCG;
/* Pending (yet not acknowledged) message in a consumer group. */
typedef struct streamNACK {
mstime_t delivery_time;
uint64_t delivery_count;
streamConsumer *consumer;
} streamNACK;
typedef struct streamConsumer {
mstime_t seen_time;
sds name;
rax *pel;
} streamConsumer;
- 没有ack的消息可能在consumer中的pel和group的pel都记录一次,但是这两个指向的都是同一个streamNACK结构体,因此是共享的
- pel是整个维护必达性的核心结构体,所有没有被ack的数据都会放到这里,保证至少被消费一次
- 消费者和消费者组参考消息队列
Iterator
typedef struct raxStack {读取之后无论是否ack,last_id都会更新
void **stack; /*用于记录路径,该指针可能指向static_items(路径较短时)或者堆空间内存; */
size_t items, maxitems; /* 代表stack指向的空间的已用空间以及最大空间 */
void *static_items[RAX_STACK_STATIC_ITEMS];
int oom; /* 代表当前栈是否出现过内存溢出. */
} raxStack;
typedef struct raxIterator {
int flags; //当前迭代器标志位,目前有3种,RAX_ITER_JUST_SEEKED代表当前迭代器指向的元素是刚刚搜索过的,当需要从迭代器中获取元素时,直接返回当前元素并清空该标志位即可;RAX_ITER_EOF代表当前迭代器已经遍历到rax树的最后一个节点;AX_ITER_SAFE代表当前迭代器为安全迭代器,可以进行写操作。
rax *rt; /* 当前迭代器对应的rax */
unsigned char *key; /*存储了当前迭代器遍历到的key,该指针指向
key_static_string或者从堆中申请的内存。*/
void *data; /* 当前key关联的value值 */
size_t key_len; /* key指向的空间的已用空间 */
size_t key_max; /*key最大空间 */
unsigned char key_static_string[RAX_ITER_STATIC_LEN]; //默认存储空间,当key比较大时,会使用堆空间内存。
raxNode *node; /* 当前key所在的raxNode */
raxStack stack; /* 记录了从根节点到当前节点的路径,用于raxNode的向上遍历。*/
raxNodeCallback node_cb; /* 为节点的回调函数,通常为空*/
} raxIterator;
- 使用还是通过栈+中序遍历节点的方式寻找下一个
整体流程
写入
- 先创建一个stream,创建raxio tree
- 根据last_id,生成要插入的新的ID,找到最大的tree的节点(最右边的节点)
- 判断listpack是否还能插入,能插入能插入
- 不能就根据key创建一个新的listpack
读取
- 所有的读取行为以group的last_id进行读取
- 读取之后无论是否ack,last_id都会更新
- 没有ack的消息都会被扔到pel中和消费者的pel中,被分配给消费者的消息不会再给其他消费者,也只能特定的消费者来ack
[!info] 重发时机
- 检测到消费者有断线的情况
- 消息过期,这部分xadd指定时间
redis如何实现延迟队列
- 使用 zset这个命令,用设置好的时间戳作为score进行排序,使用
zadd score1 value1 ....命令就可以一直往内存中生产消息。再利用 zrangebysocre 查询符合条件的所有待处理的任务,通过循环执行队列任务即可。也可以通过zrangebyscore key min max withscores limit 0 1查询最早的一条任务,来进行消费
如何避免SQL注入进攻
- 预处理:采用预编译语句集
redis和memcached优劣势
- redis支持的数据结构比memcached更加丰富,mem只支持字符串和数字类型
- mem不支持持久化存储,redis支持持久化存储
- mem占用的内存小,redis更多,mem不支持主从复制,mem使用更加简单
微信拿到红包分配
分配算法
- 随机,额度在0.01和剩余平均值*2之间.例如:发100块钱,总共10个红包,那么平均值是10块钱一个,那么发出来的红包的额度在0.01元~20元之间波动。
- 领取红包后继续使用同样的方法计算
幂等性处理
mysql的private key
- 让业务方生成唯一ID,这个ID作为mysql唯一约束,如果插入失败则说明已经处理
mysql乐观锁version
- 先将唯一id插入,下一个请求来的时候查询是否已经插入,如果发现已经插入这说明已经处理(这个不需要使用锁,但是需要在业务层对version进行判断),tira-pay使用的方式就是这个
Redis的setNX
- 将ID拼接一些信息插入redis中,设置3分钟缓存,无法插入则说明已经处理(tira-im使用的方法)
列数据库
特点
- 读多于写
- 大宽表,读大量行但是少量列,结果集较小
- 数据批量写入,且数据不更新或少更新
- 无需事务,数据一致性要求低
- 灵活多变,不适合预先建模
优点
- 同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
- 更高的压缩比意味着更小的data size,从磁盘中读取相应数据耗时更短
- 更加适合于大量数据的读取分析
缺点
- 一行的全量查询慢(例如查需一个人的所有信息)
- 基本不支持ACID事务
应用场景
hbase 就是列数据库
- 类似数据分析(批量分析某个值的特征),大规模日志存储,大规模打点监控(压缩特性,并且可以接受秒级延迟)用的比较多
- 基本上是数仓和日志在用,通常是 hbase 配合 hadoop(基于mapreduce 的分布式系统基础架构,也是数仓的主要构成)
innodb和myisam的区别
- InnoDB支持事务,MyISAM不支持
- InnoDB支持表、行(默认)级锁,而MyISAM支持表级锁
- MyISAM 中 B+ 树的数据结构存储的内容是实际数据的地址值,它的索引和实际数据是分开的,只不过使用索引指向了实际数据。这种索引的模式被称为非聚集索引。InnoDB 中 B+ 树的数据结构中存储的都是实际的数据,这种索引有被称为聚集索引。
- myisam比较快,但是功能比较少
redis缓存的缺点(微信支付不用)
- 数据的一致性的问题,本质类似CAP,只能保证最终一致性,或者放弃可用性,
- 会有一种错误的安全感,高并发下会出现缓存失效的情况
使用缓存时容易有一种「虚假」的安全感,因为缓存的存在,会认为服务端性能能抗住热点时的请求,所以当缓存失败,峰值又上来之后,很快就把服务打挂了。因此,微信支付内部在做性能测试时,都需要先把缓存关掉。 即使是使用缓存,也只会使用单机的缓存,如同机部署的memcached,因为使用分布式的缓存,有多个写入来源的话,一旦缓存被写坏,排查起来会非常麻烦,因为根本不知道是在哪里被写坏的。
- 掉电丢失记录,可能出现数据的丢失
慢sql
特征
- 数据库CPU负载高。一般是查询语句中有很多计算逻辑,导致数据库cpu负载。
- IO负载高导致服务器卡住。这个一般和全表查询没索引有关系。
- 查询语句正常,索引正常但是还是慢。如果表面上索引正常,但是查询慢,需要看看是否索引没有生效。
查看
- 使用explain可以查看一个语句是否使用了索引
- 打开慢日志查询(会记录每一条执行时间长的sql),一般是由于没有索引,或者索引失效,或者数据量太大造成的
关系型和非关系型数据库区别
- 关系模型可以简单理解为二维表格模型,而一个关系型数据库就是由二维表及其之间的关系组成的一个数据组织。
- 非关系型数据库又被称为 NoSQL(Not Only SQL ),意为不仅仅是 SQL。通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定,常用于存储非结构化的数据。
- 参考
拉取数据时候根据时间戳而不是id
- 现在基本上的拉取方式是 offset+limit,实际上mysql会将所有的数据拉取出来,然后排序好在偏移到offset拿出limit,因此数据量会非常大
- 但是如果是通过时间戳拉取的话,只会根据时间戳的范围进行拉取而不会全量拉取.因此业界通常的做法是通过 begin_time, end_time 拉取,而不是用limit
关系型数据库优缺点
- 采用二维表结构非常贴近正常开发逻辑(关系型数据模型相对层次型数据模型和网状型数据模型等其他模型来说更容易理解);
- 支持通用的SQL(结构化查询语言)语句;
- 丰富的完整性大大减少了数据冗余和数据不一致的问题。并且全部由表结构组成,文件格式一致;
- 可以用SQL句子多个表之间做非常繁杂的查询;
- 关系型数据库提供对事务的支持,能保证系统中事务的正确执行,同时提供事务的恢复、回滚、并发控制和死锁问题的解决。
- 海量数据情况下读写效率低:对大数据量的表进行读写操作时,需要等待较长的时间等待响应。
- 可扩展性不足:不像web server和app server那样简单的添加硬件和服务节点来拓展性能和负荷工作能力。
- 数据模型灵活度低:关系型数据库的数据模型定义严格,无法快速容纳新的数据类型(需要提前知道需要存储什么样类型的数据)。(比如巨大的表格增加字段)
非关系型数据库的优缺点
- 非关系型数据库存储数据的格式可以是 key-value 形式、文档形式、图片形式等。使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。
- 速度快,效率高。 NoSQL 可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘。
- 非关系型数据库具有扩展简单、高并发、高稳定性、成本低廉的优势。
- 可以实现数据的分布式处理。
- 非关系型数据库暂时不提供 SQL 支持,学习和使用成本较高。
- 非关系数据库没有事务处理,无法保证数据的完整性和安全性。适合处理海量数据,但是不一定安全。
- 功能没有关系型数据库完善。
- 复杂表关联查询不容易实现。
为什么mysql2000万行数据之后性能急剧下降
- mysql中索引B+树的高度大约是3,在2000w行数据内,并且页的大小是和磁盘的格子大小相关的
- 2000万行一下时候,基本上都是3层索引(大概是3层索引时候底层数据的极限容纳值),使得查找的效率相差不大
- 超过2000w行之后,B+需要变高,变高导致最底层的8页变成16页,多出16个页面,页面直接从磁盘中读取,导致io次数变多,性能变差,参考
查询的时候limit和offset有什么缺陷
- 数据库实际上是查找了offset+limit条,然后返回最后的limit条,当出现offset非常大的时候(特别是下滑刷新的时候),导致没吃查询的速度变得很慢
- 因此toC的一般使用时间戳的方式select,类似序号的形式,只是序号使用时间戳
mysql 在数据量非常大情况下如何统计行数
- 使用
select table_name,table_rows from information_schema.tables where TABLE_SCHEMA='effect_user_busi' and table_name='user_favorite' LIMIT 1;可以查到大概的数量级(有少量误差)
如何提高秒杀中数据库瓶颈
- 热点行事务想收集多行,然后只需要加锁一次一次性运行多个事务语句直接处理
- 参考 什么是热点行性能优化_云原生数据库 PolarDB(PolarDB)-阿里云帮助中心
如何选择数据库
- 如果出现ACID的需求支持事务性,类似支付这种业务,只能选择mysql,如果流量大或者分布式就用消息队列 和分布式事务,具体参考 支付系统
- 如果出现强一致性和分布式强需求,但是对事物性要求不高,类似 服务注册发现中心,就用etcd,参考 微服务框架 > coa
- 如果需要数据高速读写,但是不需要持久化存储(比如一些临时的排行榜),直接上redis redis实现
- 如果需要数据高速读写,需要持久化存储,但是对数据的一致性要求没这么高的,用redis+mysql 具体参考 数据库总结 > redis和mysql数据一致性问题
- 这样的缺点就是 需要解决一致性问题,以及还有穿透雪崩风险,错误概率大,成本高
- 而且redis一旦出问题挂了,mysql也会马上因为流量太大挂掉
- 如果需要数据较高速读写,需要持久化存储,对数据的一致性要求高的,用leveldb,参考LevelDB底层
- 如果需要灵活的数据结构和更舒适的开发体验,对事务没有强需求,小型项目,数据频繁变化,存储维度多样(有子结构和数组这种),类似文档型数据,用mongodb Mongodb基础
- 如果需要数据高速读写,需要强持久化存储(数据完全不丢失),对数据的一致性要求高的. 那基本是不可能的
- 高速读写意味着只能站在缓存进行,持久化只能在存储进行,一致性高只能在同一个系统进行(不同进程会出现cap问题),导致这三者必须牺牲掉一个或者减少一个去平衡其他两个,leveldb就是其中佼佼者
- 如果数据量非常大,重复率高,需要进行大量存储和离线数据分析(类似用户数据大表的备份,程序日志搜索等),对实时性要求不高(能接受秒级延迟),用列数据库 数据库总结 > 列数据库
- 出现用户大量的关系需要存储,类似关注,特别是共同关注这种需求,业务查询的时候通常以用户维度查询而不会用范围查询(数据分析的需求通常倒入列数据库离线分析),要求高性能查询扩展关系查询,通常用图数据库 Neo4j底层原理
- 如果是关键词搜索,通常使用ES这种倒排索引的数据库 zincsearch底层实现
Mysql Redis DRC 同步
- DRC (Data Replicate Center) 用于数据库的同步数据
- 使用类似从库复制的手法解决 , 同机房有 sync-out 模拟从库消费主库的 binlog , 发送到对机房的 sync-in (当然中间会放 mq) , sync-in 同步binlog到当地的机房
- 如果出现冲突遵循最后更新原则(即按照时间判断这个更新是否生效), 但是核心还是需要避免冲突, 根据用户 did划分机房(不用uid 是处理没有登陆的情况下)
缓存如何优化
- 3级缓存的机制缺点是, 如果遇到热点数据经常需要读取的,就会出现有时候因为没有命中缓存导致缓存穿透的问题
- 实际上这部分如果是少量的热点key可以通过全量缓存到内存中, 然后定时从数据库刷新的办法实现, 这样热点数据缓存命中率是100%
- 至于怎么从3层缓存到这种全量缓存的一种办法是通过检测 QPS, 如果QPS 过高就自动转化为这种形式
- https://juejin.cn/post/6964531365643550751
- https://mp.weixin.qq.com/s/bWofuM5eS2Q8ylF-4AD0kA
- https://zhuanlan.zhihu.com/p/346651831
- https://xiaolincoding.com/mysql/index/index_interview.html#%E4%BB%80%E4%B9%88%E6%98%AF%E7%B4%A2%E5%BC%95
- https://mp.weixin.qq.com/s?__biz=MzUxODAzNDg4NQ==&mid=2247503394&idx=1&sn=6e5b7b2c9bd9002a4b2dfa69273069b3&chksm=f98d8a88cefa039e726f1196ba14210ddbe49b5fcbb6da620778a7497fa25404433ef0b76268&scene=21#wechat_redirect
- https://mp.weixin.qq.com/s?__biz=MzU3ODA4NTc2Ng==&mid=2247484078&idx=1&sn=87a62dbe2d4ca7e56f2e0319465147a3&chksm=fd7bf447ca0c7d51dbbce887ce37ea7088d508b8766e09892706225a49fad06ad3716d48e0e0&token=2107017276&lang=zh_CN#rd
具体流程
- 核心是通过一层缓存直接隔绝大量无效请求,然后将请求直接串行化,最后实时计算领取到的金额,异步到账实现的
-
发送红包时候分布式事务,主事务先扣钱,从事务发消息+插入红包数据库中一条消息(含有剩余金额和剩余人数)
-
发出后,红包的剩余领取人数将缓存到redis(或者memcache)中
-
抢红包环节,通过redis原子减操作(这部分使用版本乐观锁的机制保证,但是这里涉及可能柔性处理,如果出现冲突可以放行,毕竟这里不涉及真正的金钱,这也是导致进入领红包界面最后没领到的原因),这个部分隔绝了大部分无效的请求,削峰的作用,过了这部分的请求会被扔到队列中串行消费
这部分如果自己上mysql事务锁,大量的请求会因为锁失败,因为高并发的场景下一大堆冲突,如果是在内存中计算会出现程序故障就G了
- 如果拆红包采用乐观锁,那么在并发抢到相同版本号的拆红包请求中,只有一个能拆红包成功,其他的请求将事务回滚并返回失败,给用户报错,用户体验完全不可接受。2. 如果采用乐观锁,将会导致第一时间同时拆红包的用户有一部分直接返回失败,反而那些“手慢”的用户,有可能因为并发减小后拆红包成功,这会带来用户体验上的负面影响。3. 如果采用乐观锁的方式,会带来大数量的无效更新请求、事务回滚,给 DB 造成不必要的额外压力。 总思路是设置多层过滤网,层层筛选,层层减少流量和压力。这个设计最初是因为抢操作是业务层,拆是入账操作,一个操作太重了,而且中断率高。 从接口层面看,第一个接口纯缓存操作,搞压能力强,一个简单查询Cache挡住了绝大部分用户,做了第一道筛选,所以大部分人会看到已经抢完了的提示。 这部分如果缓存失败直接降级成为db操作
-
拆红包环节,通过mysql的事物进行处理,因为请求串行化,基本无锁(但是还是需要直接开启悲观锁),写之后再异步写入cache中领取详情
- 开启主事务
- 查询红包中真正的剩余金额和剩余人数,如果等于0直接返回
- 计算此次请求需要拿的红包金额,这部分直接在内存中计算(实时效率更高,预算才效率低下。预算还要占额外存储)
- 更新数据库记录,余额和人数都减少
- 插入红包流水,用于对账
- 提交主事务
-
到账环节,上面成功之后通过事务中心异步打钱
- 从事务开启
- 插入流水ID
- 钱包加钱
- 提交从事务
其他设计
- 一致性hash将不同的红包请求负载均衡到不同的机器上,同一个红包请求到一台server上
- 数据库分表添加天的维度,用于数据的冷热分离,加上ID,施行双维度分表,而求红包记录储存时间有限,超过时间直接删除
具体来说,就是分库表规则像 db_xx.t_y_dd 设计,其中,xx/y 是红包 ID 的 hash 值后三位,dd 的取值范围在 01~31,代表一个月天数最多 31 天。
对账系统
- 审计的公式:
- 单条流水期初余额 + 交易发生金额 = 期末余额。
- 本条流水期初余额 = 上条流水的期末余额。
- 本条流水的余额版本号 =上条流水的余额版本号 + 1。
实时对账和离线对账
- 实时对账就是一边运行一边对账
- 离线对账是按照天或者小时进行对账
- 单系统核验:核验自己的流水和结果明细是否对的上
- 不同系统对账:核验不同系统的账单是否能对的上(比如扣钱和加钱,有借必有贷,借贷必相等)
优缺点
- 离线对账有零点问题(按照时间对账,时间边缘账单无法对齐),离线对账触发的时候占用大量cpu,一次性处理大量数据,对账问题有延迟,出现性能高峰,因此最好用于单系统本地对账,并且设置对账时间在深夜
- 实时对账系统一直的占用都是类似的,一般不存在性能高峰,但是对账系统会一致占用系统资源,因为不同析用时间可能有偏差,不能用按时间段对账的方法,因此适合不同系统对账,设置一个中心化的分布式实时对账系统,不影响业务的运行
实时对账系统的设计
- 业务写操作之后,启动协程将日志写入mq
- 对账系统拿出记录之后写入数据库,数据库两种表,一种记录单号以及到来的个数,一种记录具体
- 等到某一条单号的记录到来个数到达全部之后(这部分可以设置最长期限,超过进行问询操作),直接开始进行对账,如果对上了直接删除有关这个单号的所有记录,对不上直接报警
离线对账系统的设计
- 设置默认触发时间(比如深夜),开始堆数据库进行查询对账
- 对账方法就是账户明细跟着流水走,康康是否发生跳变
- 零点问题看容忍度,容忍度高的话,零点附近的数据不平认为是零点问题忽略,低容忍度的话,取冗余数据(多取5分钟)对账,如果还是不平就要人工处理
电商秒杀
绝大部分流程和微信红包系统类似
- 通过前置redis的原子减进行流量的初筛
- 然后扔到消息队列里面消费
- mysql进行开启事物悲观锁
- 扣减库存数量
- 添加订单信息(这部分如果不是同一个数据库涉及分布式事务或者mysql进行了热点行的优化就扔到消息队列异步化)
- 返回成功,订单状态为待付款
出现大量库存提速
- 秒杀的速度瓶颈在于mysql的事务,对热点行的频繁上锁 数据库总结 > 如何提高秒杀中数据库瓶颈
- 还有的就是大量流量下p99延迟急剧增加,这种情况下需要进行并发限流 限流算法 > 并发限流
[!tip] 互联网的本质 互联网本质就是加速信息的流通和信息的匹配 那么就会有信息的生产者和消费者, 互联网的功能本质只是打通中间的链路, 让信息流通更加简单快速
创作链路
生产信息的链路
管理平台
平台化管理信息的场所
下发控制
信息的集中分发
可用性
正确性
准确性
这部分是由钟sir妻子上的软件方法课的衍生
黑盒测试
等价类划分
- 首先把可能用到的数据划分为不同的类别,然后再从每一类别里面挑选有代表性的数据用以数据。这样挑选出来的数据就可以代表这一类里面的全部数据。通过这种方式,可以减少测试用例的数量。
- 通常划分为==一个有效等价类和N个无效等价类==
- 考虑了单个输入域、所有可能的取值情况,避免了在设计测试用例时盲目或随机选取输入测试不完整或不稳定的数据
- 缺点是产生的测试用例比较多 #TODO 根据书本补充完
白盒测试
AB测试
- A/B测试(也称为分割测试或桶测试)是一种将网页或应用程序的两个版本相互比较以确定哪个版本的性能更好的方法。AB测试本质上是一个实验,其中页面的两个或多个变体随机显示给用户,统计分析确定哪个变体对于给定的转换目标(指标如CTR)效果更好。

回归测试
- 修改了旧代码后,重新进行测试以确认修改没有引入新的错误或导致其他代码产生错误,就是重新跑所有的case
nsq

[!tip] 参考 https://zhuanlan.zhihu.com/p/115368450 https://nsq.io/components/utilities.html#nsq_to_file
特点
- 使用push的方式推送消息
- 支持集群部署
- topic->channel->protocol(连接),消息层层传递,各个层次通过chan for-select模型连接
和kafka对比
[!tip] 参考 https://zhuanlan.zhihu.com/p/46421050
kafka架构
- 参考组成
注册发现
- kafka使用zookeeper,一种类似raft的强一致性算法保证
- nsq使用nsqlookup,只提供简单注册发现服务(类似http转发的功能,不参与消息传输)
推送
- kafka pull,消费者拉取,阻塞式pull
- 优点:流控简单,消费者要多少拿多少
- 缺点:pull频率把控重要(太慢丢失实时性,太快浪费资源)
- nsq push,有msg马上主动下发
- 优点:及时性很好
- 缺点:流控麻烦,需要额外配置(告知可以处理多少)
存储
- kafka 直接扔到硬盘里,不过因为是循序写,非常快,而且还有操作系统 > 零拷贝文件传输的机制使得更加快
- nsq 除非超过
--mem-queue-size,否则都扔在内存,因此当消息在被写入磁盘之前,NSQ宕机或关闭了进程,会出现丟数据的情况
保证
- Kafka,支持最多一次(At most once)、至少一次(At lease once)、准确一次(Excatly once)三种策略
- nsq,则只支持最常见的一种,也就是至少一次。
备份
- Kafka则通过partition的机制,对消息做了备份,增强了消息的安全性。
- Nsq只把消息存储到一台机器中,不做任何备份,一旦机器奔溃,磁盘损坏,消息就永久丢失了。
顺序
- kafka支持消息顺序消费(消费完A再消费B)
- kafka支持顺序消费的原因是可以指定放入的part,二每个part是一个队列消费的顺序是一定的,可以保证顺序消费
- 返回成功是在写入磁盘中后,因此可以保证顺序消费
- part必须上一条成功之后才会发下一条
- kafka中push时候可以指定key,key相同的会被分配到同一个part,使得同一个key的消息可以按顺序消费,同一个part是有序的
- nsq不支持
- 因为nsq设计的和kafka不一样,nsq每个topic只有一个chan,因此压根没有支持上一条不接受下一条不发的机制(这样会严重影响消息发送的效率)
- 而且nsq中大量使用协程,消息之间的处理也不能完全保证顺序
事务
- kafka支持事务,可以原子性写入多个topic
- nsq不支持
延时器
- nsq使用纯粹的时间堆实现
- kafka主要是时间堆,但是细节上用时间轮来优化
总结
- nsq和专业的消息队列还是有差别的,但是小规模可以用,毕竟轻的多
消息队列作用
- 降低耦合度,通过两个不同模块处理
- 请求之间的缓冲削峰,避免突发流量
- 处理异步化,提高响应速度和体验
消息队列名词
消费者
- 消息消费的一个实例
消费者组
- 每个消费组有一个或者多个消费者
- 每个消费组拥有一个唯一性的标识id
- 消费组在消费topic的时候,topic的每个partition只能分配给一个消费者
nsq的channel类似消费组,protocol类似消费者
redis stream
3. Stream流模型
[!tip] 参考 https://www.jianshu.com/p/d32b16f12f09 https://zhuanlan.zhihu.com/p/496944314 https://cloud.tencent.com/developer/article/2331486 https://juejin.cn/post/7094646063784525832 https://www.cnblogs.com/coloz/p/13812840.html
使用命令
结构体
stream
typedef struct stream {
rax *rax; // 是一个 `rax` 的指针,指向一个 Radix Tree,key 存储消息 ID,value 实际上指向一个 listpack 数据结构,存储了多条消息,每条消息的 ID 都大于等于 这个 key 的消息 ID
uint64_t length; // 该 Stream 的消息条数
streamID last_id; // 当前 Stream 最后一条消息的 ID。
streamID first_id; // 当前 Stream 第一条消息的 ID。
streamID max_deleted_entry_id; // 当前 Stream 被删除的最大的消息 ID。
uint64_t entries_added;// 总共有多少条消息添加到 Stream 中,`entries_added = 已删除消息条数 + 未删除消息条数`
rax *cgroups;// rax 指针,也指向一个 Radix Tree ,**记录当前 Stream 的所有 Consume Group**,每个 Consume Group 的名称都是唯一标识,作为 Radix Tree 的 key,Consumer Group 实例作为 value
} stream;
// 结构体,消息 ID 抽象,一共占 128 位,内部维护了毫秒时间戳(字段 ms);一个毫秒内的自增序号(字段 seq),**用于区分同一毫秒内插入多条消息**。
typedef struct streamID {
uint64_t ms;
uint64_t seq;
} streamID;
- stream中使用树和堆 > radix tree实现消息列表而不是list
[!info] 原因
- redis的消息支持根据id删除,因此需要有索引的出现,因此不能单纯用list
- redis的消息支持顺序消费,而且key大量重复,因此不能直接用hash
- 节省空间,而且因为redis默认使用时间戳+顺序编号作为id,公共前缀比较长,可以节省空间
- value的类型是redis实现 > 压缩列表,直接存储的就是消息的id和内容
- listpack的所有key都是增加的,比叶子节点的node大
- 消息的id是(毫秒时间戳-序号)
consumer group
/* Consumer group. */
typedef struct streamCG {
streamID last_id;// **已经获取了,无论是否ack的id**
long long entries_read;
rax *pel;
rax *consumers;// key是消费者name,val是消费者实体
} streamCG;
/* Pending (yet not acknowledged) message in a consumer group. */
typedef struct streamNACK {
mstime_t delivery_time;
uint64_t delivery_count;
streamConsumer *consumer;
} streamNACK;
typedef struct streamConsumer {
mstime_t seen_time;
sds name;
rax *pel;
} streamConsumer;
- 没有ack的消息可能在consumer中的pel和group的pel都记录一次,但是这两个指向的都是同一个streamNACK结构体,因此是共享的
- pel是整个维护必达性的核心结构体,所有没有被ack的数据都会放到这里,保证至少被消费一次
- 消费者和消费者组参考消息队列
Iterator
typedef struct raxStack {读取之后无论是否ack,last_id都会更新
void **stack; /*用于记录路径,该指针可能指向static_items(路径较短时)或者堆空间内存; */
size_t items, maxitems; /* 代表stack指向的空间的已用空间以及最大空间 */
void *static_items[RAX_STACK_STATIC_ITEMS];
int oom; /* 代表当前栈是否出现过内存溢出. */
} raxStack;
typedef struct raxIterator {
int flags; //当前迭代器标志位,目前有3种,RAX_ITER_JUST_SEEKED代表当前迭代器指向的元素是刚刚搜索过的,当需要从迭代器中获取元素时,直接返回当前元素并清空该标志位即可;RAX_ITER_EOF代表当前迭代器已经遍历到rax树的最后一个节点;AX_ITER_SAFE代表当前迭代器为安全迭代器,可以进行写操作。
rax *rt; /* 当前迭代器对应的rax */
unsigned char *key; /*存储了当前迭代器遍历到的key,该指针指向
key_static_string或者从堆中申请的内存。*/
void *data; /* 当前key关联的value值 */
size_t key_len; /* key指向的空间的已用空间 */
size_t key_max; /*key最大空间 */
unsigned char key_static_string[RAX_ITER_STATIC_LEN]; //默认存储空间,当key比较大时,会使用堆空间内存。
raxNode *node; /* 当前key所在的raxNode */
raxStack stack; /* 记录了从根节点到当前节点的路径,用于raxNode的向上遍历。*/
raxNodeCallback node_cb; /* 为节点的回调函数,通常为空*/
} raxIterator;
- 使用还是通过栈+中序遍历节点的方式寻找下一个
整体流程
写入
- 先创建一个stream,创建raxio tree
- 根据last_id,生成要插入的新的ID,找到最大的tree的节点(最右边的节点)
- 判断listpack是否还能插入,能插入能插入
- 不能就根据key创建一个新的listpack
读取
- 所有的读取行为以group的last_id进行读取
- 读取之后无论是否ack,last_id都会更新
- 没有ack的消息都会被扔到pel中和消费者的pel中,被分配给消费者的消息不会再给其他消费者,也只能特定的消费者来ack
[!info] 重发时机
- 检测到消费者有断线的情况
- 消息过期,这部分xadd指定时间
kafka
组成
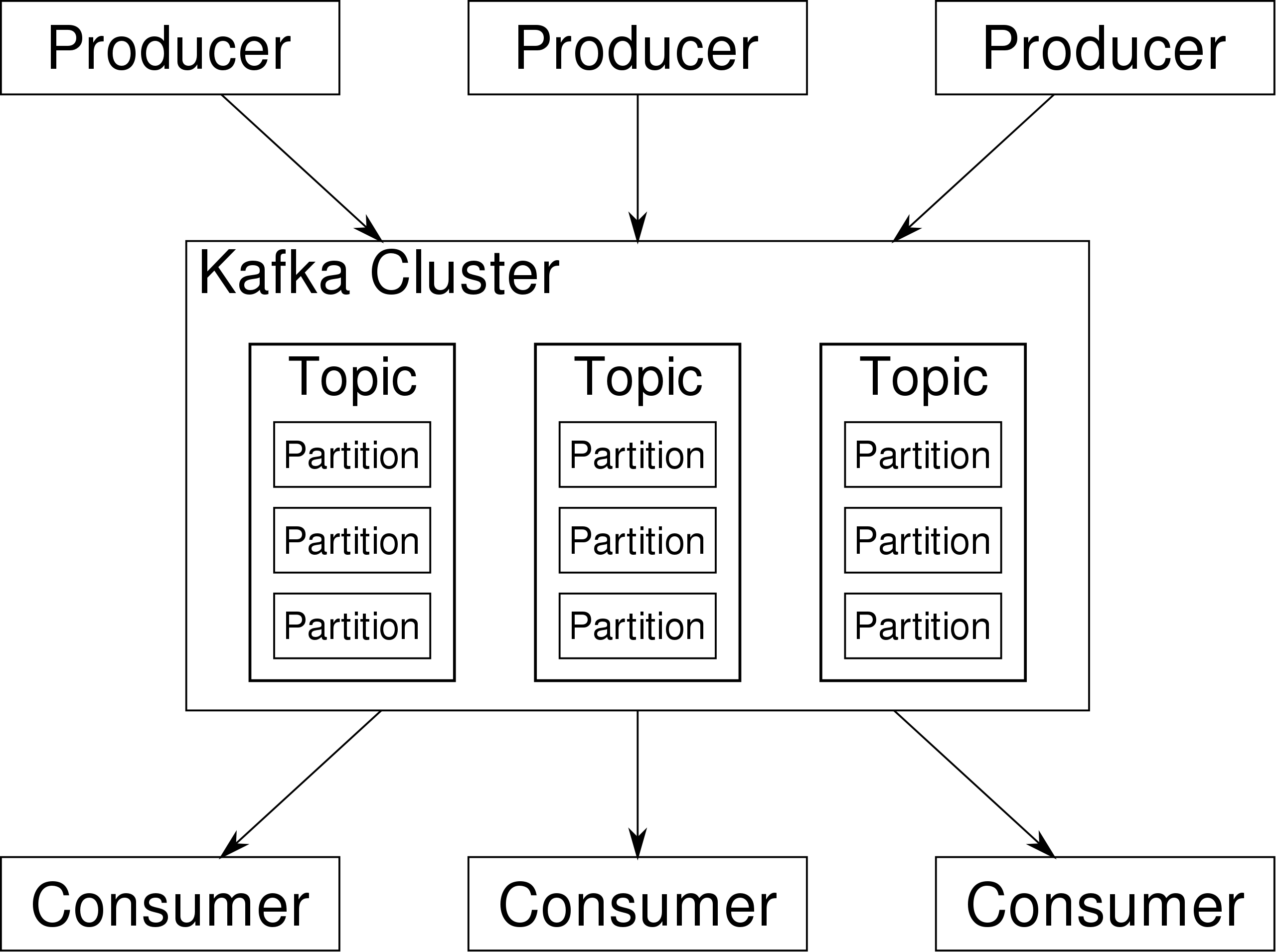
- Broker:一台kafka服务器就是一个broker。一个cluster由多个broker组成。
- 每个topic有多个part,每个part都是一个队列,这个队列的实现是通过文件的写入和偏移量完成的
- 如果消息没有指定part,那么将会负载均衡消息到part
- 储存的结构都是在磁盘中而不是在内存中
- Consumer作为一个消费者组,每个消息只会被一个消费者组消费一次
- Kafka 不会向 Consumer 推送消息。Consumer 必须自己从 Topic 的 Partition 拉取消息。
- 为保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个分区都有若干个副本,一个leader和若干个follower.读写都是向leader中,follower只是作为一个容灾备份,而且==是以partition为单位创建副本,而不是broker==
broker
- 在 Kafka 集群中会有一个或多个 broker,其中有一个 broker 会被选举为控制器(Kafka Controller),它负责管理整个集群中所 有分区和副本的状态。当某个分区的leader副本出现故障时,由控制 器负责为该分区选举新的leader副本。当检测到某个分区的ISR集合发 生变化时,由控制器负责通知所有broker更新其元数据信息。当使用 kafka-topics.sh脚本为某个topic增加分区数量时,同样还是由控制 器负责分区的重新分配(相当于broker中的leader)
分区
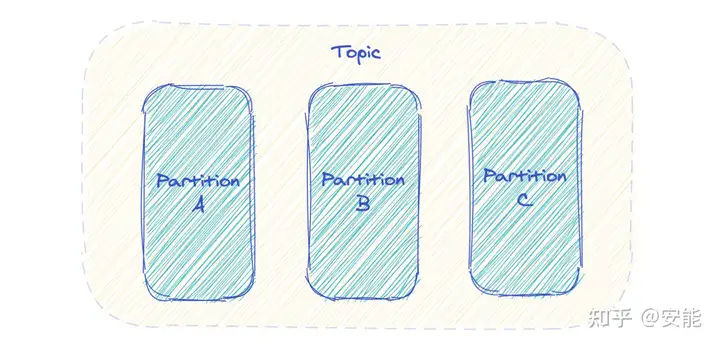
- Kafka 中 Topic 被分成多个 Partition 分区。
- Topic 是一个逻辑概念,Partition 是最小的存储单元,掌握着一个 Topic 的部分数据。topic列表存储在zookeeper中,数据存储在kafka中
- 每个 Partition 都是一个单独的 log 文件,每条记录都以追加的形式写入。
- 默认情况下,每个topic默认一个partition
- 对于一个topic以及订阅他的一个消费组
- 如果partition大于等于消费者数量:每个消费者处理>=1个partition
- 如果partition小于消费者数量:==每个消费者处理1个partition,剩下的消费者闲置,不会出现同一个消费组多个消费者同时处理一个partition==,这样可以保证同一个partition的消息的顺序消费
- kafka尽量保证分区符副本分布的均衡性,即平均每个partition在每个broker上都有一个副本(当然这一堆副本中有一个leader)
分配
这部分是分区到消费者的分配策略
- 参考分配策略
[!tip] 参考 微信公众平台
优势
- 如果把 Topic 的所有 Partition 都放在一个 Broker 上,那么这个 Topic 的可扩展性就大大降低了,会受限于这个 Broker 的 IO 能力。把 Partition 分散开之后,Topic 就可以水平扩展 。
- 一个 Topic 可以被多个 Consumer 并行消费。如果 Topic 的所有 Partition 都在一个 Broker,那么支持的 Consumer 数量就有限,而分散之后,可以支持更多的 Consumer。
- 一个 Consumer 可以有多个实例,Partition 分布在多个 Broker 的话,Consumer 的多个实例就可以连接不同的 Broker,大大提升了消息处理能力。可以让一个 Consumer 实例负责一个 Partition,这样消息处理既清晰又高效。
offset
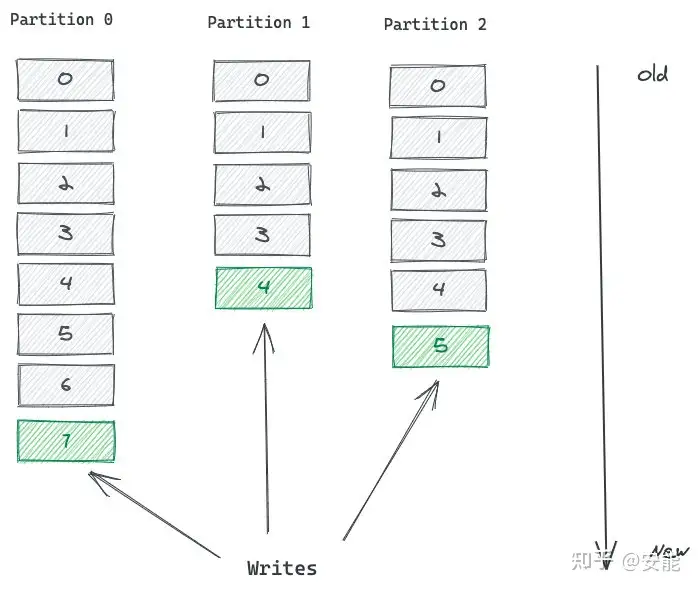
- Partition 中的每条记录都会被分配一个唯一的序号,称为 Offset(偏移量)。
- Offset 是一个递增的、不可变的数字,由 Kafka 自动维护。
- 当一条记录写入 Partition 的时候,它就被追加到 log 文件的末尾,并被分配一个序号,作为 Offset。
- 这个 Topic 有 3 个 Partition 分区,向 Topic 发送消息的时候,实际上是被写入某一个 Partition,并赋予 Offset。
- 消息的顺序性需要注意,一个 Topic 如果有多个 Partition 的话,那么从 Topic 这个层面来看,消息是无序的。
- offset是最后一条已读的消息位置,而不是最前一条未读的消息位置
- 但单独看 Partition 的话,Partition 内部消息是有序的。所以,一个 Partition 内部消息有序,一个 Topic 跨 Partition 是无序的。如果强制要求 Topic 整体有序,就只能让 Topic 只有一个 Partition
- ==每个<partition,group,topic> 这个三元组唯一确定了一个offset,任何一个部分不一样offset都不同==
[!tip] 参考 细说 Kafka Partition 分区 - 知乎 (zhihu.com)
消息
构成


- 时间增量是相对于消息批次的其实时间戳的
- 属性是一些位表示消息的属性(如时间戳的类型,是否压缩等)
- 上面的key是发送者设置的,没有则无
- Kafka 可变长度的具体做法借鉴了 Google ProtoBuffer 中的 Zig-zag 编码方式 #TODO 可以看一下
消息批次

- 这个是位于批量消息最前面的,最后的消息就是多条消息,用于批量发消息节省空间提高空间使用率
- CRC:对于批次内的数据计算校验值
- 增加了 PID、producer epoch、序列号等信息主要是为了支持幂等性以及事物引入的
- 这里的属性占用了两个字节。低3位表 示压缩格式,可以参考v0和v1;第4位表示时间戳类型;第5位表示此 RecordBatch是否处于事务中,0表示非事务,1表示事务。第6位表示 是否是控制消息(ControlBatch),0表示非控制消息,而1表示是控 制消息,控制消息用来支持事务功能
controller
- 每个Broker都会在Controller Path (/controller)上注册一个Watch。 当前Controller失败时,对应的Controller Path会自动消失(因为它是ephemeralNode),此时该Watch被fire,所有“活” 着的Broker都会去竞选成为新的Controller (创建新的Controller Path),但是只会有一个竞选成功(这点由Zookeeper保证)。竞选成功者即为新的Leader,竞选失败者则重新在新的Controller Path上注册Watch。因为Zookeeper的Watch是一次性的, 被fire一次之后即失效,所以需要重新注册.
- 这里因为broker的数量不会多到太离谱,羊群效应的影响没这么大
安装
# 如果版本3.x更改端口 务必再config/server.properties中添加,否则不成功
listeners=PLAINTEXT://127.0.0.1:9092
存储
- index文件是稀疏索引,而且文件名是
- Log 日志在物理上只是以文件夹的形式存储,而每个 LogSegement 对应磁盘上的一个日志文件和两个索引文件,以及可能的其他文件
- 每个 Segment 对应4个文件:“.index” 索引文件, “.log” 数据文件, “.snapshot” 快照文件, “.timeindex” 时间索引文件。这些文件都位于同一文件夹下面,该文件夹的命名规则为:topic 名称-分区号.index, log, snapshot, timeindex 文件以当前 Segment 的第一条消息的 Offset 命名。其中 “.index” 文件存储大量的索引信息,“.log” 文件存储大量的数据,索引文件中的元数据指向对应数据文件中 Message 的物理偏移量。
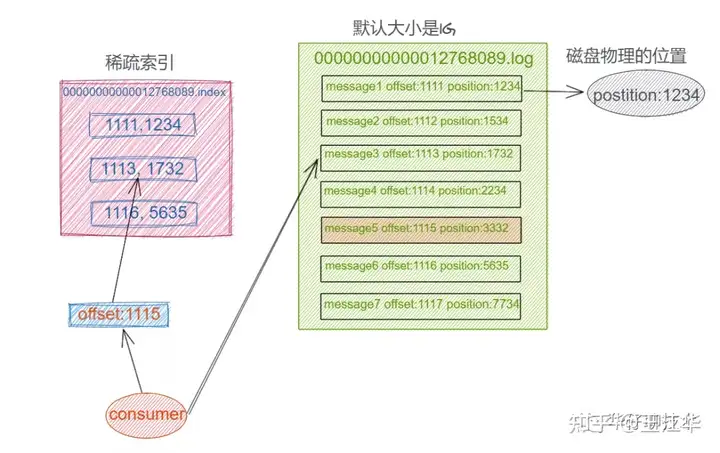
- Kafka 是基于「主题 + 分区 + 副本 + 分段 + 索引」的结构
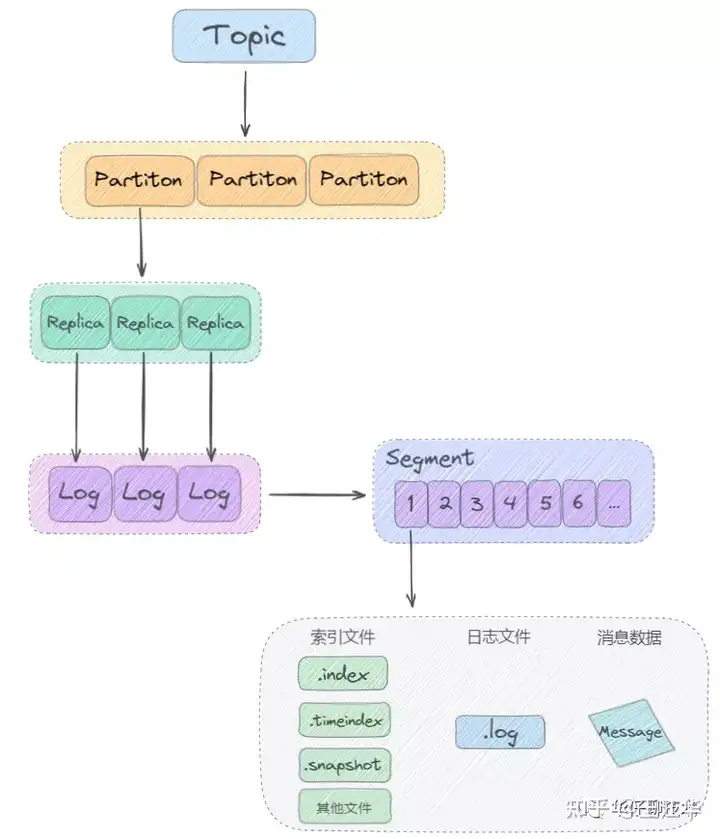
日志写入
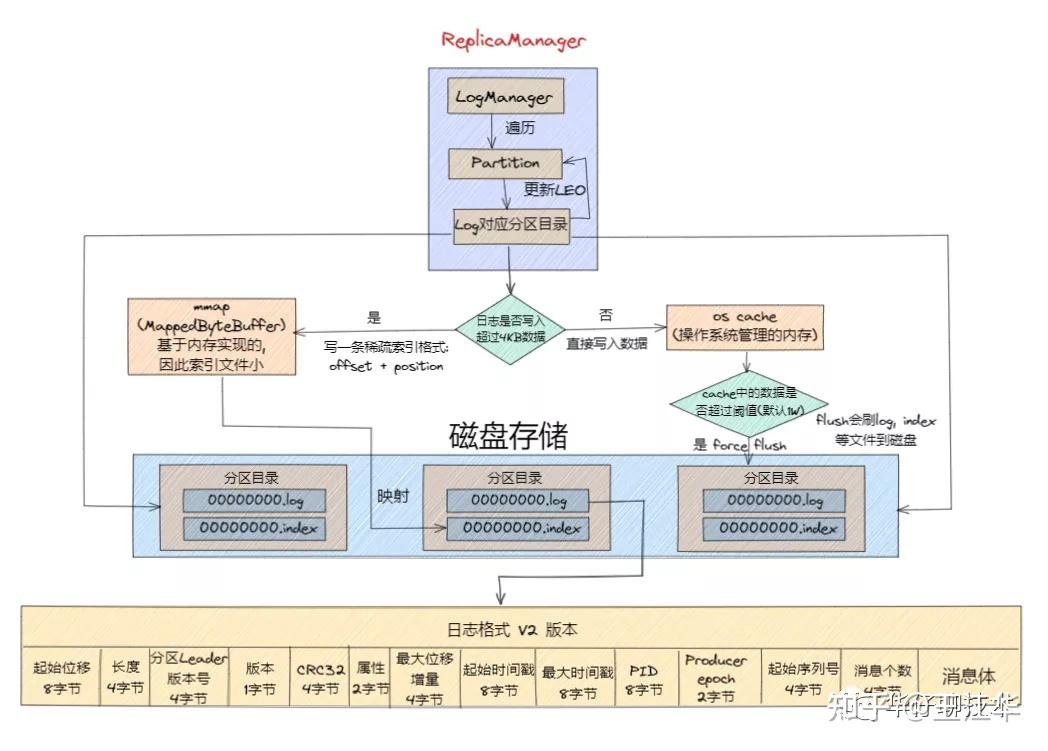
[!tip] 参考 搞透Kafka的存储架构,看这篇就够了 - 知乎
日志清理
- 共有3种策略删除,将日志分段文件添加上“.deleted”的后缀(也包括日志分段对应的索引文件)
- Kafka的后台定时任务会定期删除这些“.deleted”为后缀的文件,这个任务的延迟执行时间可以通过file.delete.delay.ms参数来设置,默认值为60000,即1分钟。
- 基于时间的保留策略
- 基于日志大小的保留策略
- 基于日志起始偏移量的保留策略
- 每个segment日志都有它的起始偏移量,如果起始偏移量小于 logStartOffset,那么这些日志文件将会标记为删除。
日志压缩
- #TODO 这里确定一下如何实现日志压缩的
LSR机制
- LEO( Log End Offset):指的是每个副本最大的offset;
- HW(High Watermark):字面意思高水位,指的是消费者能见到的最大的offset,ISR队列中最小的LEO。
- ISR (In-Sync Replica): 所有与Leader副本保持一定程度同步的副本(包括Leader副本在内)组成ISR,ISR中的副本是可靠的,它们跟随Leader副本的进度。
- OSR (Out-of-Sync Replica): 与Leader副本同步滞后过多的副本组成了OSR,这些副本可能由于网络故障或其他原因而无法与Leader保持同步。
- AR (Assigned Replica): 分区中的所有副本统称为AR,AR=ISR+OSR。
- 消息可以被消费是在HW的位置,而不是ack的位置,有的LSR太久跟不上会被踢到OSR,HW的位置是LSR集合决定的,知道副本追上了才能被加到LSR中
LSR选举
ISR 的全称叫做:In-Sync Replicas (同步副本集), 我们可以理解为和 leader 保持同步的所有副本的集合。所有Partition的Leader选举都由controller决定。
- 只有LSR有资格参加选举,OSR没有(这部分可以配置)
- 一旦leader宕机,会通过controller从Zookeeper中读取当前分区的所有ISR(in-sync replicas)集合,选择PreferredReplica作为当前Partition的leader(就是按照序号选)
[!tip] 为什么不使用类似分布式raft选举或者zookeeper raft适用于保证极高的一致性的前提下选举,可能出现耗时较高的情况,而且因为分为了ISR和OSR两个部分,副本的同步问题得到了解决(相当于LSR任何一个都可以),因此可以直接指定.而且更加简单,raft过于复杂 zookeeper的watch机制可能出现羊群效应(每个副本都在watch和抢夺的情况下,如果宕机的那个Broker上的Partition比较多, 会造成多个Watch被触发,造成集群内大量的调整,导致大量网络阻塞。),以及导致zookeeper负载过重(要维护大量副本的watch)
生产者
- send会放入发送生产者缓冲区(这部分非kafka服务器)中,但是不一定发送,如果不flush,按照一定周期也会发,flush是立刻清空缓冲区马上发送,flush函数会等待ack到达或者超时,如果超时抛出异常,但是不会进行重试,重试需要业务端自己执行
- #TODO 参考"深入探索kafka"书补充完
ACK
- 1(默认):leader收到数据就成功,可能丢数据,但可能重复数据
- 0:无需等待来自broker的确认而继续发送下一批消息。这种情况下数据传输效率最高,但是数据可靠性最低
- -1或all:producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高
定时/延时消息
原理
-
参考# Kafka中的方法
- 两者结合使用.Kafka 中的时间轮(TimingWheel)是一个存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表(TimerTaskList)。TimerTaskList是一个环形的双向链表,链表中的每一项表示的都是定时任务项(TimerTaskEntry),其中封装了真正的定时任务(TimerTask)。

- DelayQueue 中保存着所有的 ==TimerTaskList== (注意这里并不保存task只是相当于把那个时间点有task的信息时间点记录下,这样减少了堆元素的数量)对象,根据时间来排序,这样延时越小的任务排在越前面。
- 外部通过一个线程(叫做ExpiredOperationReaper)从 DelayQueue 中获取超时的任务列表 TimerTaskList,然后根据 TimerTaskList 的 过期时间来精确推进时间轮的时间,这样就不会存在空推进的问题啦。
- DelayQueue 只存放了 TimerTaskList,并不是所有的 TimerTask,数量并不多,相比空推进带来的影响是利大于弊的,DelayQueue才是真正对任务进行延时排序的地方,时间轮的用途是分级聚合任务,减少DelayQueue中的对象数。
- 两者结合使用.Kafka 中的时间轮(TimingWheel)是一个存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表(TimerTaskList)。TimerTaskList是一个环形的双向链表,链表中的每一项表示的都是定时任务项(TimerTaskEntry),其中封装了真正的定时任务(TimerTask)。
场景
- 事务场景下,为了保证可读性的控制,使用延迟发送的方式
消费者
AutoCommit
- true表示消费者只要接收到这个消息自动提交偏移
- false表示消费者需要手动提交偏移
__consumer_offsets
- 存储offset的特殊topic,key是上文的三元组<Group ID,主题名,分区号 >**,val是offset
- kafka会定时清理过期的信息
- kafka 默认为该 topic 创建了50个分区,并且对每个 group.id 做哈希求模运算,从而将负载分散到不同的 __consumer_offsets 分区上
[!tip] 为什么不存储在zookeeper或者hash hash不适合落盘保存,这个操作是写远远大于读的操作,因此写性能必须非常好,读时候找到最新的提交,然后后期进行日志压缩(相同key保存最新)
Rebalance机制
正常情况下,kafka会为每个topic分配几个partition,然后每个消费者组的成员负责不同的partition的消费,但是出现某些情况会导致重新分配.==在这里可能出现消息的重复问题==
触发时机
- 组成员发生变更,比如新consumer加入组,或已有consumer主动离开组,再或是已有consumer崩溃时则触发rebalance(==这里处理超时也会被认为是崩溃==)。
- 组订阅topic数发生变更,比如使用基于正则表达式的订阅,当匹配正则表达式的新topic被创建时则会触发rebalance。
- 组订阅topic的分区数发生变更,比如使用命令脚本增加了订阅topic的分区数。
分配策略
- range策略主要是基于范围的思想:它将单个topic的所有分区按照顺序排列,然后把这些分区划分成固定大小的分区段并依次分配给每个consumer
- round-robin策略则会把所有topic的所有分区顺序摆开,然后轮询式地分配给各个consumer
- sticky策略有效地避免了上述两种策略完全无视历史分配方案的缺陷,采用了“有黏性”的策略对所有consumer实例进行分配,可以规避极端情况下的数据倾斜并且在两次rebalance间最大限度地维持了之前的分配方案
拉取消息
- 通过主动pull而不是push机制拉取数据
- Push 模式最大缺点就是 Broker 不清楚 Consumer 的消费速度,且推送速率是 Broker 进行控制的, 这样很容易造成消息堆积,如果 Consumer 中执行的任务操作是比较耗时的,那么 Consumer 就会处理的很慢, 严重情况可能会导致系统 Crash。
- 如果 Kafka Broker 没有消息,这时每次 Consumer 拉取的都是空数据, 可能会一直循环返回空数据。 针对这个问题,Consumer 在每次调用 Poll() 消费数据的时候,顺带一个 timeout 参数,当返回空数据的时候,会在 Long Polling 中进行阻塞,等待 timeout 再去消费,直到数据到达。
状态机
消费控制

下文的commit是提交偏移(也就是消费者确认ack),消费是具体拿到消息的处理 Broker:一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个 topic。
at most once模式
- 基本思想是保证每一条消息commit成功之后,再进行消费处理;
- 设置自动提交为false,接收到消息之后,首先commit,然后再进行消费
- 特点:不会重复发送,可能消息丢失 ,acks = 0 可以实现。acks=0 保证producer往leader只发送一次,不管是否发送成功,因此可能丢数据,但不会重复发送
at least once模式
- 基本思想是保证每一条消息处理成功之后,再进行commit;
- 设置自动提交为false;消息处理成功之后,手动进行commit;
- 特点:会重复发送,消息不会丢失,ack = all 或-1可以实现。
exactly once模式
实际上并没有办法实现完全的exactly once,核心难点在于消费者端回commit和消费message,这两个不是原子操作,下面方法是保证生产者端不会重复发送
生产者幂等性
对于单个分区,幂等生产者不会因为生产者或 broker 故障而产生多条重复消息。
- 核心思想是发送端数据发送成功,并且成功的消息只发送一次(重复的数据被服务器拒绝掉);消费端再进行at most once模式消费。
- 特点:不会重复发送,消息不会丢失,at least once 加上消费者幂等性可以实现,还可以用kafka生产者的幂等性来实现
- 生产者端开启这个模式后会给每个消息编号,同一条消息发送两次不会二次写入。kafka每次发送消息会生成PID和Sequence Number,并将这两个属性一起发送给broker,broker会将PID和Sequence Number跟消息绑定一起存起来,下次如果生产者重发相同消息,broker会检查PID和Sequence Number,如果相同不会再接收
过程
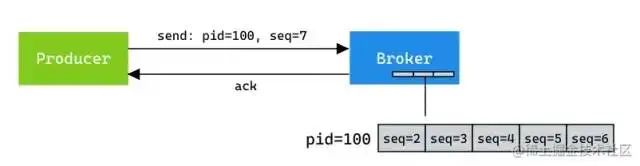
Producer每次启动后,会向Broker申请一个全局唯一的pid。- 重启后pid会变化,此时 <pid, seq num>中的pid不相同,因此kafka会认为是新的消费者,seq从0开始
- Broker端也会为每个
<PID, Topic, Partition>维护一个序号
Sequence Number:针对每个<Topic, Partition>都对应一个从0开始单调递增的Sequence(这意味着pid,partition,sequence三个部分可以唯一确定一条消息),同时Broker端会缓存这个seq num(==这里并不意味着所有的消息都需要放在同一个partition中 ==)- 判断是否重复: 拿 <pid, seq num> 去 Broker 里对应的队列 ProducerStateEntry.Queue(默认队列长度为 5)查询是否存在
- 如果 nextSeq == lastSeq + 1,即 服务端seq + 1 == 生产传入seq,则接收。
- 如果 nextSeq == 0 && lastSeq == Int.MaxValue,即刚初始化,也接收。
- 反之,要么重复,要么丢消息,均拒绝。
事务:跨分区原子写入
- 保证的是多个写操作的原子性,要么一起成功,要么一起不成功,通常用于写多个分区的消息时候(比如: 写下单topic-> 处理支付业务-> 写支付topic)或者需要 写 和commit相结合(保证写和commit原子性)
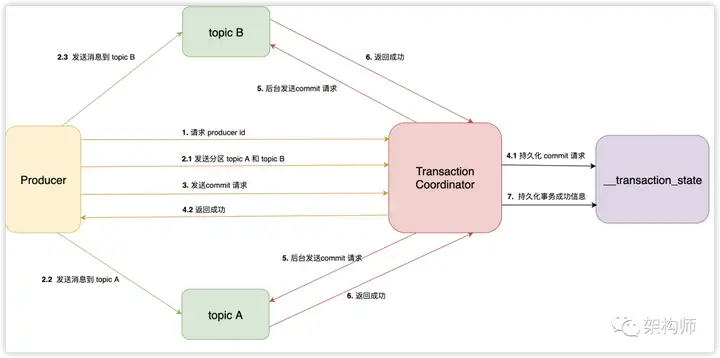
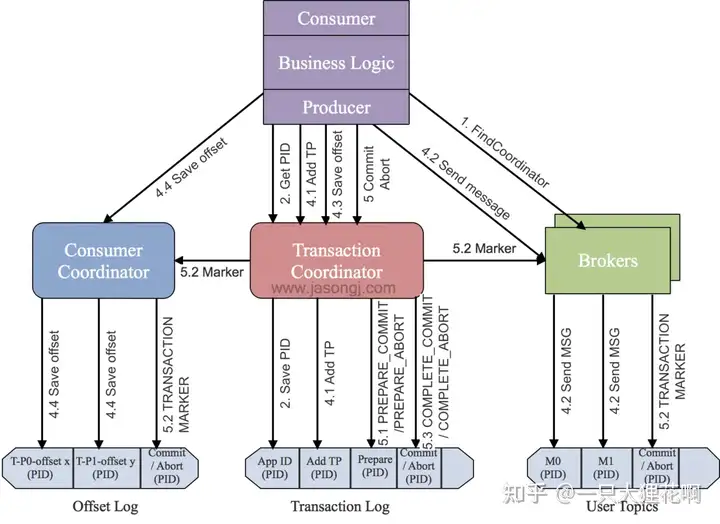
过程
- 查找 Transaction Coordinator:
Producer 通过向任意一个 Broker 发送 FindCoordinatorRequest 请求,获取 Transaction Coordinator 的地址,Transaction Coordinator 负责协调和管理事务的生命周期 - 初始化事务(initTransaction):
Producer 发送 InitPidRequest 给 Transaction Coordinator,获取 PID(Producer ID)。 Transaction Coordinator 记录 PID 和 Transaction ID 的映射关系,并执行一些额外的初始化工作,包括恢复之前未完成的事务和递增 PID 对应的 epoch.==(Transaction ID唯一确定机器,因为pid可能改变,但是Transaction ID是设置的不会变)== - 开始事务(beginTransaction):
Producer 执行 beginTransaction() 操作,本地记录该事务的状态为开始。此时,Transaction Coordinator 尚未被通知,只有在 Producer 发送第一条消息后,Transaction Coordinator 才认为事务已经开启 - Read-Process-Write 流程:
当Producer 开始发送消息,Transaction Coordinator 将消息存储于 Transaction Log 中,并将其状态标记为 BEGIN。如果该事务是第一个消息,Transaction Coordinator 还会启动事务的计时器(每个事务都有自己的超时时间)。注册到 Transaction Log 后,Producer 继续发送消息,即使事务未提交,消息已经保存在 Broker 上。即使后续执行了事务回滚,消息也不会删除,只是状态字段标记为 abort.这个时候的消息存在broker中但是不可见(RC情况下),==这里事务消息是存储在broker,不会直接发给消费者,而且不会乱序消费下一条消息,即使导致后面的消息阻塞== - 事务提交或终结(commitTransaction/abortTransaction):
在 Producer 执行 commitTransaction 或 abortTransaction 时,Transaction Coordinator 执行两阶段提交:- 第一阶段,将 Transaction Log 中该事务的状态设置为 PREPARE_COMMIT 或 PREPARE_ABORT。
- 第二阶段,将 Transaction Marker 写入事务涉及到的所有消息,即将消息标记为 committed 或 aborted。这一步 Transaction Coordinator 会发送给每个事务涉及到的 Leader(标记完消息后就可见了)。Broker 收到请求后,将对应的 Transaction Marker 控制信息写入日志。
- 一旦 Transaction Marker 写入完成,Transaction Coordinator 将最终的 COMPLETE_COMMIT 或 COMPLETE_ABORT 状态写入 Transaction Log,标明该事务结束。
- Consumer 在 read_committed 模式下只需做一些消息的过滤,即过滤掉回滚了的事务和处于 open 状态的事务的消息。过滤这些消息时,Consumer 利用消息中的元数据信息,不需要与 Transactional Coordinator 进行 RPC 交互。
[!tip] 参考 【Kafka】kafka消费者的三种模式(最多/最少/恰好消费一次)&生产者幂等性_kafka at least once 【Kafka】Kafka 实现 Exactly-once - 简书 (jianshu.com) 【Kafka系列】Kafka事务机制
Prometheus
特点
- 使用pull模型定时拉取数据,由Prom拉取而不是主动上报,减小程序负担,程序只需要负责埋点
- 使用PromQL进行查询更加高效
夜莺系统
- 使用prometheus作为时序库
- 支持grafana看图
- 支持丰富和复杂的告警规则
和grafana区别
- Grafana更擅长监控面板的管理,夜莺更擅长告警规则的管理。
[!tip] 常用形式 通常使用prom进行监控,grafana进行面板的展示,加上夜莺配置报警
核心解决问题
- 不信任任何微服务rpc的调用,即使是内部网络也是不可信任的
可能存在内部人员伪造rpc请求,可能存在黑客进入内网的情况,因此不可信任
- 用户的核心信息在网络中明文传递,非常不安全
核心思想
- 通过类似token的机制进行票据的颁发和验证,票据是层层传递的,意味着每次rpc请求都需要对票据进行校验,票据类似jwt token,本身携带信息
鉴权系统类型
方案1:单点登录
- 每个服务都访问鉴权服务
- 从性能和可用性角度来说,每个服务都要通过网络请求去鉴权速度是很慢的,而且会产生巨量的网络流量消耗,并且鉴权服务成为了系统的单点,一旦网络抖动或者鉴权服务故障,整个系统的可用性都要受到影响。
- 从架构设计的角度来说,这样不仅会造成对鉴权服务的依赖,也将鉴权和业务耦合在了一起。一旦鉴权方式有变更,系统中所有相关的服务都要改代码重编上线,管理非常困难。
方案2:分布式Session
- 业界常用的办法,但是存在较大缺点,鉴权后将身份信息存入Session,并返回SessionID,每个服务根据SessionID取出身份信息进行验证.这部分的方法就是常常使用的信息中心session存储,分配sessionID的机制
- session的存储是核心问题
- 中心存储:直接将所有Session数据存于专门的存储中,每个需要鉴权的服务都去读取.这种方法最为简单直接,但是这样做其实和单点登录的缺点类似:消耗大量网络资源,Session存储成为单点(中心化的架构都是危险的)
- 存储隔离+一致性哈希:不同身份映射到不同的存储区域,同一身份的请求总是路由到固定的存储区域。 这种方法对存储的压力较小(每个存储区域只存一部分数据),也具有一定的容灾能力(一个区域的存储故障不会影响其他区域)。但是由于不同身份的请求量差异很大(不同商户的交易量千差万别),存储会出现严重倾斜的情况(这部分是我完全没想到的)
- 分布式同步:将Session信息直接存储在业务服务机器上,并且使用分布式算法同步数据.这种方法可以避免中心存储带来的单点故障,存取Session也更快。但是分布式数据同步的实现是非常复杂的,尤其在微信的几万台机器之间同步,需要大量网络带宽消耗,并且最终一致的时延也可能对业务造成影响。
- 可行,但是麻烦而且消耗大量资源
方案3:客户端Token
- 客户端Token(Client Token)是指鉴权后将身份信息进行签名,生成Token返回给客户端,客户端带着Token发起请求,每个服务都可以验证Token的有效性,并通过Token中的信息来验证身份.不仅可以避免存储带来的可用性问题和成本问题,而且验证身份并不需要经过网络:只要把验证有效性的密钥下发到业务服务器上即可本地进行验证。
- 商户票据的实现方式
方案4:客户端Token+API网关
- 客户端Token+API网关(Client Token with API gateway)是指在方案3的基础上加入一层网关,把内部生成的Token转换为对外的Token交给客户端。客户端发起请求时通过网关再转换为内部的Token。这种方案将内外解耦,加强了对Token的控制能力。比如API网关可以随时独立控制某个Token的有效性,而外部毫无感知。并且由于只有API网关可以转换内外Token,无需担心外部服务拿着Token直接非法调用其他的服务。
- 凭证正是基于该方案实现。
- 感觉这种方式其实和session差不多,有中心化的问题,但是还是会出现中性化的问题

票据结构

- 已签名的部分就是加密的部分,内部再放一次票据类型是为了防止篡改,外部放一次为了包形式统一
- 使用RSA非对称加密的方式
- 票据通常放在请求头中
票据获取
- 核心就是即使是CGi也不能直接颁发票据,只能通过某个key区换取用户票据
客户端CGI
- 自带用户票据,唯一一个可以直接信任的设备
微信打开的网页CGI
- 用
export_key换取pass_ticket。XCGI可以使用内置拦截器。
小程序CGI
- 使用
session_key换取用户票据。
API商户票据
- 和飞书的类似,使用定时发送sessionid的形式,后台可以通过session ID拿到对应的票据
颁票方式
- agnet是一个机器ip一台的(方便管理),但是一个机器上可能存在一大堆的server
- 使用公钥验票,私钥颁票
方案一:本地agent颁票
- 部署本地Agent拉取密钥,密钥存放于Agent内存中,业务服务通过本地调用的方式(如Unix Socket)请求Agent颁票或验票
- 这个方式会出现一旦agent爆炸了,本地所有的的颁票和验票服务直接G了,好处是这样本地不储存密钥,安全性高

方案二:本地agent拉取密钥
- 部署 放在内存中,颁票和验票都是让agent进行,方案二则是agent拉取之后直接扔到本地,需要颁票验票自己读取
- 可用性比较好。Agent只负责拉取密钥,即使挂掉也不影响颁票或验票。需要依赖运维手段控制私钥:颁票模块不能与验票模块混布(避免恶意服务直接读取本地颁票)
- 在本地存储时使用本机IP作为密钥的一部分再做一次对称加密,避免私钥被拷贝到其他机器上使用,具体的流程为agent拉取密钥之后将将公私钥使用AES对称加密,密钥为本级ip,本地服务用的时候先根据ip解密才能用

方案三:票据中心服务
- 业务服务直接请求统一的颁票和验票服务
- 无需部署Agent,架构简单,逻辑简单,颁票和验票服务成为整个系统的单点,一旦出问题将导致全局不可用;鉴权和颁票无法一起完成,安全性无法保证。

最终方案
- 方案一,方案二和方案三混合使用,为了安全性,普通的服务不能颁票和验票,只能通过rpc调用特定的服务器才能使用,这种服务就是第二种方案的颁票和验票服务,除此以外,如果设计到票据转换,需要方案三
- 客户端:使用后台网络服务的各种类型终端。
- 客户端使用后台网络服务之前会先接入登录服务器进行身份验证。
- 登录服务器负责处理客户端用户的身份验证,将客户端提交的用户身份及验证信息进行基础的合法性校验后,将最核心的密码验证交由密码验证服务器来处理。
- 密码验证服务器:对用户密码进行验证,验证成功后会派发票据,票据加密时使用的密钥由密钥管理服务器定期更新。
- 密钥管理服务器:定期重新生成加密票据所使用的密钥,以减少外界破解密钥的风险,将密钥加密后推送到生成票据的密码验证服务器和验证票据的核心数据服务器。
- 核心数据服务器:存储用户的核心资料信息,包含用户的个人资料,好友列表,群资料等。逻辑服务器对外提供服务时需要获取用户对应的核心资料信息进行处理,核心数据服务器在提供数据给逻辑服务器时进行票据合法性验证,只有票据验证通过的请求才能拿到对应的用户核心资料信息。
- 逻辑服务器:对外提供网络服务,需要客户端将登录时派发的票据带上来,逻辑服务器将票据透传给核心数据服务器来验证并获取用户的核心资料信息,进行相应的业务逻辑处理,返回处理结果给客户端。
- 本地验票一般作为兜底的方案,出现大规模故障的时候才会使用,但是因为验票服务器比较多,所以一般使用验票服务器操作

密钥下发
Agent定时轮询中心服务
- 实现简单,Agent只管拉密钥,中心系统只管给密钥。中心系统可根据Agent轮询请求获取所有Agent的状况。
- 中心服务需要认证Agent,判断哪些Agent可以拿到私钥,哪些可以拿到公钥。
中心服务主动向Agent推
- 密钥更新时才触发全局推送,有新Agent加入时只需指定推送。
- Agent需要监听端口,中心系统需要定期查询机器变化情况,并主动对失败的Agent定期补发,实现较复杂。
最终方案
- 为了控制不同机器获得密钥的权限(能否拿到公钥或私钥),中心系统记录了一个白名单,里面是当前所有接入商户票据的模块对应的机器IP列表及这些机器具有的权限。Agent前来请求时,密钥存储服务会根据来源IP查找对应机器的权限,应答相应的密钥。
密钥更新
目标
- 最终所有Agent可以拿到新生成的密钥,并使用这个版本来进行颁票和验票。
- 在这个过程中,保证业务无感知,做到平滑过渡升级。
方法
- 对于Agent来说,只需定时上报本地密钥的最新版本号和生效版本号,并把取回的最新版本和生效版本的公私钥写到本地。(需要告诉中心服务自己最新的密钥版本,中心需要告诉agent应该用哪个版本),本地可能储存多个密钥版本
- 中心服务需要统计现在的agent密钥版本,如果都拿到最新版本,那么下次agent请求的时候可以让他们用新的版本颁票,验票的部分因为存在老版本的密钥,就算有延迟导致还是旧的票据也因此不影响验票,只是必须保证最新的密钥需要所有agent都收到才能用最新的颁票,都这无法验票,中心服务如果发现有个agent死活连不上,会强制过期旧的密钥(相当于放弃旧agent)
安全体系
- 使用RSA对称加密用于防止伪造
- 票据和请求唯一ID绑定,该ID在整条请求链中应保持不变(对于Svrkit来说是CallGraphID)
- 每个模块配置模块开关,全局配置全局开关。一旦使用全局开关,所有验票都将直接返回成功,这部分主要是考虑如果中心服务挂了,导致无法下发密钥,啊开这个开关,就会给所有的agent发送开关的请求,此时agent就会通过修改版本密钥的配置的手段使得所有的票据直接通过,这个部分是直接作用于颁票服务和验票服务的,使得验票的服务直接全部通过
凭证
- 凭证用于延期和延续票据,是票据的临时替身:
- 凭证由票据生成,可以落地存储。
- 凭证可以换回票据。
- 凭证可以比票据有更长的有效期。
- 通常用于请求转发给外部门,然后回调本部门
设计
- 加密解密,没有存储,依赖更少,速度更快,可用性更高,但是长度和票据一致,可能很长
- 落地存储,凭证只是一个ID,映射的内容在存储中,调整灵活|需要存储,要考虑存储容灾问题
- 最后使用第二种方法,业务需要落地存储,最好长度比较短且可控;另外方案2还预留了能力可以限制使用次数、续期凭证和撤销凭证。而且票据毕竟是通行证,传递到别的地方又安全风险
消息凭证
| 方案 | 优点 | 缺点 |
|---|---|---|
| 1. 业务自行进行票据凭证互换 | 现成方案,无需额外开发,也无需改事件中心 | 业务需要感知票据凭证(但并不关心),使用非常繁琐;成为请求关键路径,可用性要求极高;事件中心请求量很大,需要准备大量存储空间。 |
| 2. 改造事件中心,自动完成票据凭证互换 | 相比方案1,业务感知较小 | 除了方案1的缺点,还要改动事件中心:对事件中心来说依赖了外部系统,破坏了通用性(只有微信支付在用),可用性降低。 |
| 3. 事件中心透传,事件中心给商户票据加入延期标记,验票时特殊处理 | 业务无感知,不需要存储 | 对于事件中心仍然依赖了外部系统,和方案2一样,通用性和可用性都难以接受。 |
| 4. 事件中心透传,事件中心自己生成延期标记,放在请求包中,验票时特殊处理 | 业务无感知,不需要存储,而且是通用方案,与业务解耦 | 需要改造事件中心 |
- 核心问题是消息队列会进行重试,但是票据的有效期有限,容易过期,最后选择方案四,和方案一的凭证互换

引申
微信扫码授权登录过程
- app扫码(码的url通常是微信的域名,然后需要实际访问的链接通过query传入,然后app携带访问服务器,服务器授权申请,然后服务器将票据换取凭证,并且重定向到实际访问的链接,凭证通过query携带凭证通常是一个code)
- 实际访问的服务器只拥有凭证(这种凭证有效期一般设置为2分钟),可以通过凭证获取用户的信息(这里通过凭证code获取openid)
- 避免了外部地址拿到凭证,票据加密是一层(避免信息泄漏),签名是一层(避免篡改),换成凭证是一层(避免出现票据泄漏的问题,方便控制时间,本身不携带信息)
总结
- 创建理念是不信任任何一个服务,只认票据不认rpc
- 票据的生成和检验使用的是多种方式结合
- 外部调用使用凭证代替票据,增强安全性
TT登录态
参考
时间轮
- 低精度,因为格子大小是固定的
- 如果长时间没有到期任务,这种方案会带来空推进的问题,从而造成一定的性能损耗
- 操作和逻辑简单
单轮
- 可以使用倍数n来作为时间轮转动的数量
多轮
- 小轮一圈,大轮一格
- 添加时候先挂大轮,大轮到了再拿下来挂在小轮相对位置
时间堆
- 高精度
- 逻辑复杂
- 一般用四叉堆
- 插入和删除的复杂度是logn(因为涉及到排序二分搜索)
思路
- 类似二叉堆,最小先执行的时间放在上面
- 到了实现执行之后重新计算堆
cron
- 使用类似二叉堆的办法
for {
// Determine the next entry to run.
sort.Sort(byTime(c.entries))// 直接数组排序
var timer *time.Timer
if len(c.entries) == 0 || c.entries[0].Next.IsZero() {
timer = time.NewTimer(100000 * time.Hour)
} else {
timer = time.NewTimer(c.entries[0].Next.Sub(now))//计算最小到期时间并且计时
}
for {
select {
case now = <-timer.C://触发标识出现计时器到期
now = now.In(c.location)
// Run every entry whose next time was less than now
for _, e := range c.entries {
if e.Next.After(now) || e.Next.IsZero() {
break
}
c.startJob(e.WrappedJob)
e.Prev = e.Next
e.Next = e.Schedule.Next(now)//计算下一次触发时间
c.logger.Info("run", "now", now, "entry", e.ID, "next", e.Next)
}
case newEntry := <-c.add://添加之后会重新计算最小到期时间
timer.Stop()
now = c.now()
newEntry.Next = newEntry.Schedule.Next(now)
c.entries = append(c.entries, newEntry)
c.logger.Info("added", "now", now, "entry", newEntry.ID, "next", newEntry.Next)
//...略
case id := <-c.remove:
timer.Stop()
now = c.now()
c.removeEntry(id)//删除节点
c.logger.Info("removed", "entry", id)
}
break//无论结果到这里都会出来重新计算
}
}
Kafka中的方法
- 两者结合使用.Kafka 中的时间轮(TimingWheel)是一个存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表(TimerTaskList)。TimerTaskList是一个环形的双向链表,链表中的每一项表示的都是定时任务项(TimerTaskEntry),其中封装了真正的定时任务(TimerTask)。
- DelayQueue 中保存着所有的 ==TimerTaskList== (注意这里并不保存task只是相当于把那个时间点有task的信息时间点记录下,这样减少了堆元素的数量)对象,根据时间来排序,这样延时越小的任务排在越前面。
- 外部通过一个线程(叫做ExpiredOperationReaper)从 DelayQueue 中获取超时的任务列表 TimerTaskList,然后根据 TimerTaskList 的 过期时间来精确推进时间轮的时间,这样就不会存在空推进的问题啦。
- DelayQueue 只存放了 TimerTaskList,并不是所有的 TimerTask,数量并不多,相比空推进带来的影响是利大于弊的,DelayQueue才是真正对任务进行延时排序的地方,时间轮的用途是分级聚合任务,减少DelayQueue中的对象数。
Crony

- node和admin都是通过etcd进行交流和沟通
- node通过定时续租来保证任务运行,admin寻找最少任务数量的节点运行
- 任务类型支持http和cmd任务
- 触发通知支持Email
- 底层为时间堆算法
参考
- https://zhuanlan.zhihu.com/p/342285267
常用GC
- 经典的GC算法有三种:引用计数(reference counting)、标记-清扫(mark & sweep)、复制收集(Copy and Collection)
引用计数法
- 记录对象引用个数
- 当引用为0时候删除对象
优点
- 无需长时间暂停程序,STW非常短,立刻回收垃圾
- 逻辑简单
缺点
- 无法解决循环引用的问题(最大问题)
- 占用内存较大(保存引用个数)
- 更新频繁,浪费时间片
- 内存碎片化(释放的内存分布地方不同)
改进方法
- 延迟引用技术
引用为0不清除,加入空闲的table,分配内存时候可以用
- 减少引用变量位宽
- 溢出直接不管,不当作垃圾
- 运行标记清除
总结
- 简单,但是有时候不得不运行标记清除解决问题
标记清除
- 第一阶段:标记。从根结点出发遍历对象,对访问过的对象打上标记,表示该对象可达。
- 第二阶段:清除。对那些没有标记的对象进行回收,这样使得不能利用的空间能够重新被利用。
优点
- 运行时候才调用,平时不占用内存和cpu
- 没有引用计数问题
缺点
- 需要暂停程序进行GC,会使得程序停止
- 内存碎片化(释放的内存分布地方不同)
复制收集
- 将内存一分为二,GC时候相当于搬家到另外一边
- 访问对象,把可达的所有对象和他们子对象通通拷贝到另外一半
优点
- 没有碎片化问题(内存都是一大块释放)
- 内存分配更加高效(因为上一个的原因)
缺点
- 内存利用率低(不到50%)
分代垃圾回收
- 不是单独一种GC方法,而是作为一种缝合不同GC的方法
- 将对象分为新生代(更加容易被回收)和老生代(难以回收)
- 新生代通常使用复制收集算法,老的通常为标记清除
三色标记法
代码参考
- C++:https://gitee.com/chenxuan520/tricolor-notation/blob/master/gc.h
说明
- 本质也是标记清除算法,但是解决它的程序停止的缺点(核心还是读写冲突的问题,如果不暂停程序就会出现读写冲突,三色标记法使用的是类似锁的方法解决)
- 垃圾收集的根对象一般包括全局变量和栈对象,因为栈对象永远是黑色(会自动释放),只有堆对象需要回收
- Go 语言的垃圾收集可以分成清除终止、标记、标记终止和清除四个不同阶段
过程
- 先从根开始标记灰色,三个桶
- 把灰色引用到的全部变灰色,灰色变黑
- 删除白色对象
- 继续上面过程
完整流程
- GCMark 标记准备阶段,为并发标记做准备工作,启动写屏障
- STWGCMark 扫描标记阶段,与赋值器并发执行,写屏障开启并发
- GCMarkTermination 标记终止阶段,保证一个周期内标记任务完成,停止写屏障
- GCoff 内存清扫阶段,将需要回收的内存归还到堆中,写屏障关闭
- GCoff 内存归还阶段,将过多的内存归还给操作系统,写屏障关闭。
写屏障
- 强三色不变性 — 黑色对象不会指向白色对象,只会指向灰色对象或者黑色对象;
- 弱三色不变性 — 黑色对象指向的白色对象必须包含一条从灰色对象经由多个白色对象的可达路径
- 所有触发都是针对黑色和灰色对象,白色对象引用的改变不会触发
- 缺点: 需要给栈对象添加屏障,损耗指针性能
插入写屏障
writePointer(slot, ptr):
shade(ptr) //把要插入引用的对象先涂灰
*slot = ptr //改变指针到引用
- 把增加引用的对象变成灰色,添加引用时候触发,保证强三色不变性
删除写屏障
writePointer(slot, ptr)
shade(*slot) //把要删除的引用对象涂灰
*slot = ptr //改变指针到引用
- 删除引用之前,先把被删除引用对象涂灰
混合写屏障
writePointer(slot, ptr):
shade(*slot)
if current stack is grey://当前栈没有扫描,是白色
shade(ptr)
*slot = ptr
- 将创建的所有新对象都标记成黑色,防止新分配的栈内存和堆内存中的对象被错误地回收
各种语言使用GC
- GO: 三色标记法
- Python:引用计数器、标记-清除机制、分代垃圾收集
- Java: 标记-清除机制、分代垃圾收集
参考
- https://www.cnblogs.com/Delo/articles/12553593.html
- https://draveness.me/golang/docs/part3-runtime/ch07-memory/golang-garbage-collector/
- https://www.cnblogs.com/wuyanzu123/p/14813886.html
15. 三数之和
给你一个整数数组 `nums` ,判断是否存在三元组 `[nums[i], nums[j], nums[k]]` 满足 `i != j`、`i != k` 且 `j != k` ,同时还满足 `nums[i] + nums[j] + nums[k] == 0` 。请
你返回所有和为 `0` 且不重复的三元组。
**注意:**答案中不可以包含重复的三元组。
- 排序,先一层的for循环,然后第二层,使用两数之和的方式实现
238. 除自身以外数组的乘积
给你一个整数数组 `nums`,返回 _数组 `answer` ,其中 `answer[i]` 等于 `nums` 中除 `nums[i]` 之外其余各元素的乘积_ 。
题目数据 **保证** 数组 `nums`之中任意元素的全部前缀元素和后缀的乘积都在 **32 位** 整数范围内。
请**不要使用除法,**且在 `O(_n_)` 时间复杂度内完成此题。
- 前缀乘后缀
560. 和为 K 的子数组
给你一个整数数组 `nums` 和一个整数 `k` ,请你统计并返回 _该数组中和为 `k` 的连续子数组的个数_ 。
- 使用hash加前缀和,把每个数字前缀和加入hash表中
- 计算每一个数字时候,查询和目标和差值
- 这题和2488. 统计中位数为 K 的子数组 思路相似
class Solution {
public:
int subarraySum(vector<int>& nums, int k) {
unordered_map<int, int> mp;
mp[0] = 1;
int count = 0, pre = 0;
for (auto& x:nums) {
pre += x;
if (mp.find(pre - k) != mp.end()) {
count += mp[pre - k];
}
mp[pre]++;
}
return count;
}
};
525. 连续数组
给定一个二进制数组 `nums` , 找到含有相同数量的 `0` 和 `1` 的最长连续子数组,并返回该子数组的长度。
- 上一题的特殊模式,依旧是前缀加hash
523. 连续的子数组和
给你一个整数数组 `nums` 和一个整数 `k` ,编写一个函数来判断该数组是否含有同时满足下述条件的连续子数组:
- 子数组大小 **至少为 2** ,且
- 子数组元素总和为 `k` 的倍数。
如果存在,返回 `true` ;否则,返回 `false` 。
如果存在一个整数 `n` ,令整数 `x` 符合 `x = n * k` ,则称 `x` 是 `k` 的一个倍数。`0` 始终视为 `k` 的一个倍数。
- 也是前缀加hash的特殊模式,但是巧妙的地方在于当prefix[i]-prefix[j]是k的倍数的时候,prefix[i]和prefix[j]除以 k的余数相同
美团笔试:平均数为k的最长子数组
给定一个数组(10^5),求平均值为k的最长子数组的长度
- 本质还是前缀+hash,但是需要变通一下,首先将平均值转换为长度*和的形式,和可以用前缀求
// (i-j+1)*k=arr[i]+...+arr[j]
//=> i*k-j*k+k=prefix[i]-prefix[j]+arr[i]
//=> pre[j]-j*k+k=pre[i]-i*k+arr[i]
//前面的作为hash存储,后面的作为key遍历寻找值
vector<int> arr(size,0);
unordered_map<long long , long long> hashmap;
long long prefix=0,result=-1;
for (int i = 0; i < size; i++) {
if (hashmap.find(prefix-i*k+arr[i])!=hashmap.end()) {
auto temp=hashmap[prefix-i*k+arr[i]];
result=max(result,(long long)i-temp+1);
}
long long val=prefix-i*k+k;
if (hashmap.find(val)==hashmap.end()) {
hashmap[val]=i;
}
prefix+=arr[i];
}
304. 二维区域和检索 - 矩阵不可变
给定一个二维矩阵 `matrix`,以下类型的多个请求:
- 计算其子矩形范围内元素的总和,该子矩阵的 **左上角** 为 `(row1, col1)` ,**右下角** 为 `(row2, col2)` 。
实现 `NumMatrix` 类:
- `NumMatrix(int[][] matrix)` 给定整数矩阵 `matrix` 进行初始化
- `int sumRegion(int row1, int col1, int row2, int col2)` 返回 **左上角** `(row1, col1)` 、**右下角** `(row2, col2)` 所描述的子矩阵的元素 **总和** 。
- 特殊前缀和,这个前缀是矩阵的前缀即(0,0)->(n,n)前缀和
2448. 使数组相等的最小开销
给你两个下标从 **0** 开始的数组 `nums` 和 `cost` ,分别包含 `n` 个 **正** 整数。
你可以执行下面操作 **任意** 次:
- 将 `nums` 中 **任意** 元素增加或者减小 `1` 。
对第 `i` 个元素执行一次操作的开销是 `cost[i]` 。
请你返回使 `nums` 中所有元素 **相等** 的 **最少** 总开销。
- 很有意思的前缀和,最后成为的数字一定是其中的数组某个数字,只需要计算变成每个数字开销分别是多少就可以了,这个使用前缀前面一个很容易推出下一个
for (int i = 0; i < nums.size(); i++) {
arr[i].first=nums[i];
arr[i].second=cost[i];
}
sort(arr.begin(),arr.end());
vector<long long> pre(nums.size(),0),end(nums.size(),0);
long long now=arr[0].second;
for (int i = 1; i < nums.size(); i++) {
pre[i]=pre[i-1]+(arr[i].first-arr[i-1].first)*now;
now+=arr[i].second;
}
now=arr[nums.size()-1].second;
for (int i = nums.size()-2; i >=0; i--) {
end[i]=end[i+1]+(arr[i+1].first-arr[i].first)*now;
now+=arr[i].second;
}
for (int i = 0; i < nums.size(); i++) {
result=min(result,pre[i]+end[i]);
}
原理
- 本质就是穷举法+记忆化
- https://labuladong.gitee.io/algo/di-er-zhan-a01c6/dong-tai-g-a223e/dong-tai-g-1e688/
# 自顶向下递归的动态规划
def dp(状态1, 状态2, ...):
for 选择 in 所有可能的选择:
# 此时的状态已经因为做了选择而改变
result = 求最值(result, dp(状态1, 状态2, ...))
return result
# 自底向上迭代的动态规划
# 初始化 base case
dp[0][0][...] = base case
# 进行状态转移
for 状态1 in 状态1的所有取值:
for 状态2 in 状态2的所有取值:
for ...
dp[状态1][状态2][...] = 求最值(选择1,选择2...)
5. 最长回文子串
给你一个字符串 `s`,找到 `s` 中最长的回文子串。
如果字符串的反序与原始字符串相同,则该字符串称为回文字符串。
- 动态规划经典,用 P(i,j)P(i,j) 表示字符串 s的第 i到 j个字母组成的串(下文表示成 s[i:j])是否为回文串,P(i,j)=P(i+1,j−1)∧(Si==Sj)
53. 最大子数组和
给你一个整数数组 `nums` ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
**子数组** 是数组中的一个连续部分。
- 经典简单dp,选择自己或者上一个加上自己中大的那个
class Solution {
public:
int maxSubArray(vector<int>& nums) {
if(nums.size()==0){
return 0;
}
int result=nums[0];
for(unsigned i=1;i<nums.size();i++){
nums[i]=max(nums[i-1]+nums[i],nums[i]);
result=max(result,nums[i]);
}
return result;
}
};
升级版最大子数组和(小红书笔试)
给你一个整数数组 `nums` 和一个数字`change`,**你最多可以将数组中一个数修改成change**,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
**子数组** 是数组中的一个连续部分。
- 加了一个条件最多可以修改一个数字,变成了类似股票的问题,dp分为现在没用过这次机会和用过了这次机会,没用这次机会和最大子数组和类似,用了的是max(max(之前用过+原来数字,之前没用+change),change),实际上就是之前用还是当前用,当前用需要比较加上之前没用的最大值
vector<pair<long long,long long>> dp(size,{0,0});
long long result=0;
for (int j = 0; j < size; j++) {
if (j==0) {
dp[j].first=arr[j];
dp[j].second=change;
result=max(dp[j].first,dp[j].second);
continue;
}
dp[j].first=max(dp[j-1].first+arr[j],arr[j]);
dp[j].second=max(max(dp[j-1].first+change,dp[j-1].second+arr[j]),change);
result=max(result,max(dp[j].first,dp[j].second));
}
72. 编辑距离
给你两个单词 `word1` 和 `word2`, _请返回将 `word1` 转换成 `word2` 所使用的最少操作数_ 。
你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
- 超经典动态规划
- dp[i][j]表示 s1[0..i] 和 s2[0..j] 的最小编辑距离

class Solution {
public:
int minDistance(string word1, string word2) {
int n = word1.length();
int m = word2.length();
if (n * m == 0) return n + m;
vector<vector<int>> D(n + 1, vector<int>(m + 1));
for (int i = 0; i < n + 1; i++) {
D[i][0] = i;
}
for (int j = 0; j < m + 1; j++) {
D[0][j] = j;
}
// 计算所有 DP 值
for (int i = 1; i < n + 1; i++) {
for (int j = 1; j < m + 1; j++) {
int left = D[i - 1][j] + 1;
int down = D[i][j - 1] + 1;
int left_down = D[i - 1][j - 1];
if (word1[i - 1] != word2[j - 1]) left_down += 1;
D[i][j] = min(left, min(down, left_down));
}
}
return D[n][m];
}
};
198. 打家劫舍
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,**如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警**。
给定一个代表每个房屋存放金额的非负整数数组,计算你 **不触动警报装置的情况下** ,一夜之内能够偷窃到的最高金额。
- 简单动态规划
dp[i]=max(dp[i−2]+nums[i],dp[i−1])
322. 零钱兑换
给你一个整数数组 `coins` ,表示不同面额的硬币;以及一个整数 `amount` ,表示总金额。
计算并返回可以凑成总金额所需的 **最少的硬币个数** 。如果没有任何一种硬币组合能组成总金额,返回 `-1` 。
你可以认为每种硬币的数量是无限的。
- 经典动态规划
vector<int> dp(amount+1,-1);
for (int i=1; i<=amount; i++) {
for (auto& coin : coins) {
if (coin==i) {
dp[i]=1;
}else if (coin<i&&dp[i-coin]!=-1) {
if (dp[i]!=-1) {
dp[i]=min(dp[i],dp[i-coin]+1);
}else {
dp[i]=dp[i-coin]+1;
}
}
}
}
139. 单词拆分
给你一个字符串 `s` 和一个字符串列表 `wordDict` 作为字典。请你判断是否可以利用字典中出现的单词拼接出 `s` 。
**注意:**不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
dp[i]表示字符串s的[0,i)(当i==0时表示空串) 的字母组成的单词能否由字典中的单词拼接而成- 状态转移的时候,考虑枚举分割点
j (0 <= j <= i), 将字符串分成[0,j)和[j,i)两部分, 注意j==0时,第一部分是空串,j==i时,第二部分是空串 - 如果两部分都在字典中,则整个串可以由字典中的单词拼成
- 因为计算到
dp[i]的时候,已经计算出了dp[0]....dp[i-1]的值, 所以[0,j)直接由dp[j]即可得到 - 所以只需计算
[j,i)在不在字典中即可 - 所以如果
[j,i)在字典中且dp[j]为true, 则dp[i] = true, 否则dp[i] = false
func wordBreak(s string, wordDict []string) bool {
n := len(s)
dp := make([]bool, n+1)
// set 快速判断字符串在不在字典中
set := make(map[string]struct{})
for _, word := range wordDict {
set[word] = struct{}{}
}
dp[0] = true // 空串一定能被拼出来
for i := 1; i <= n; i++ {
// 枚举分割点 j
for j := 0; j <= i; j++ {
if _, ok := set[s[j:i]]; dp[j] && ok {
dp[i] = true
break
}
}
}
return dp[n]
}
152. 乘积最大子数组
给你一个整数数组 `nums` ,请你找出数组中乘积最大的非空连续子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积。
测试用例的答案是一个 **32-位** 整数。
**子数组** 是数组的连续子序列。
- 分为正数和负数分别进行dp
1035. 不相交的线
在两条独立的水平线上按给定的顺序写下 `nums1` 和 `nums2` 中的整数。
现在,可以绘制一些连接两个数字 `nums1[i]` 和 `nums2[j]` 的直线,这些直线需要同时满足满足:
- `nums1[i] == nums2[j]`
- 且绘制的直线不与任何其他连线(非水平线)相交。
请注意,连线即使在端点也不能相交:每个数字只能属于一条连线。
以这种方法绘制线条,并返回可以绘制的最大连线数。
- 底层是最长公共子序列
class Solution {
public:
int maxUncrossedLines(vector<int>& nums1, vector<int>& nums2) {
vector<vector<int>> dp(nums1.size(),vector<int>(nums2.size(),0));
for (int i = 0; i < nums1.size(); i++) {
for (int j = 0; j < nums2.size(); j++) {
if(nums1[i]==nums2[j]){
if(i>0&&j>0){
dp[i][j]=dp[i-1][j-1]+1;
}else{
dp[i][j]=1;
}
}else {
if (i>0&&j>0) {
dp[i][j]=max(dp[i][j-1],max(dp[i-1][j],dp[i-1][j-1]));
}else if(i==0&&j==0){
dp[i][j]=0;
}else if (i==0) {
dp[i][j]=dp[i][j-1];
}else if (j==0){
dp[i][j]=dp[i-1][j];
}
}
if(i==nums1.size()-1&&j==nums2.size()-1){
return dp[i][j];
}
}
}
return 0;
}
};
1049. 最后一块石头的重量 II
有一堆石头,用整数数组 `stones` 表示。其中 `stones[i]` 表示第 `i` 块石头的重量。
每一回合,从中选出**任意两块石头**,然后将它们一起粉碎。假设石头的重量分别为 `x` 和 `y`,且 `x <= y`。那么粉碎的可能结果如下:
- 如果 `x == y`,那么两块石头都会被完全粉碎;
- 如果 `x != y`,那么重量为 `x` 的石头将会完全粉碎,而重量为 `y` 的石头新重量为 `y-x`。
最后,**最多只会剩下一块** 石头。返回此石头 **最小的可能重量** 。如果没有石头剩下,就返回 `0`。
- #TODO 补全这部分
class Solution {
public:
int lastStoneWeightII(vector<int> &stones) {
int sum = accumulate(stones.begin(), stones.end(), 0);
int m = sum / 2;
vector<int> dp(m + 1);
dp[0] = true;
for (int weight : stones) {
for (int j = m; j >= weight; --j) {
dp[j] = dp[j] || dp[j - weight];
}
}
for (int j = m;; --j) {
if (dp[j]) {
return sum - 2 * j;
}
}
}
};
1043. 分隔数组以得到最大和
给你一个整数数组 `arr`,请你将该数组分隔为长度 **最多** 为 k 的一些(连续)子数组。分隔完成后,每个子数组的中的所有值都会变为该子数组中的最大值。
返回将数组分隔变换后能够得到的元素最大和。本题所用到的测试用例会确保答案是一个 32 位整数。
- 典型dp,向前查找k个内的值的最大值
class Solution {
public:
int maxSumAfterPartitioning(vector<int>& arr, int k) {
vector<int> dp(arr.size(),0);
for (int i = 0; i < arr.size(); i++) {
int now=arr[i],maxNow=arr[i];
if (i!=0) {
now+=dp[i-1];
}
for (int j=i-1; j>=0&&j>i-k; j--) {
maxNow=max(maxNow,arr[j]);
if (j!=0) {
now=max(now,maxNow*(i-j+1)+dp[j-1]);
}else {
now=max(now,maxNow*(i+1));
}
}
dp[i]=now;
}
return dp[dp.size()-1];
}
};
354. 俄罗斯套娃信封问题
给你一个二维整数数组 `envelopes` ,其中 `envelopes[i] = [wi, hi]` ,表示第 `i` 个信封的宽度和高度。
当另一个信封的宽度和高度都比这个信封大的时候,这个信封就可以放进另一个信封里,如同俄罗斯套娃一样。
请计算 **最多能有多少个** 信封能组成一组“俄罗斯套娃”信封(即可以把一个信封放到另一个信封里面)。
**注意**:不允许旋转信封。
- 首先经过一轮排序根据x的值正序,y的值逆序(逆序的原因是保证每一个相同的w只能选择一个),然后根据y的值寻找最长递增子序列
- 寻找最长递增子序列的方法也是动态规划
如排序成(1,3),(1,1),(2,6),(2,4),(3,7),(3,1)
class Solution {
public:
int maxEnvelopes(vector<vector<int>>& envelopes) {
if (envelopes.empty()) {
return 0;
}
int n = envelopes.size();
sort(envelopes.begin(), envelopes.end(), [](const auto& e1, const auto& e2) {
return e1[0] < e2[0] || (e1[0] == e2[0] && e1[1] > e2[1]);
});
vector<int> f(n, 1);
for (int i = 1; i < n; ++i) {
for (int j = 0; j < i; ++j) {
if (envelopes[j][1] < envelopes[i][1]) {
f[i] = max(f[i], f[j] + 1);
}
}
}
return *max_element(f.begin(), f.end());
}
};
264. 丑数 II
给你一个整数 `n` ,请你找出并返回第 `n` 个 **丑数** 。
**丑数** 就是只包含质因数 `2`、`3` 和/或 `5` 的正整数。
- 动态规划,因为下一个大的数字一定是有之前的数字乘于2,3,5得到,维护2,3,5三个指针,相当于使用2,3,5分别乘以之前出现的每一个数字,但是不是马上生成,而是每次比较下一个哪一个最小再移动,本质也是遍历,但是不需要提前计算很多数字,因为每次计算都是下一个最小的
class Solution {
public:
int nthUglyNumber(int n) {
vector<int> dp(n + 1);
dp[1] = 1;
int p2 = 1, p3 = 1, p5 = 1;
for (int i = 2; i <= n; i++) {
int num2 = dp[p2] * 2, num3 = dp[p3] * 3, num5 = dp[p5] * 5;
dp[i] = min(min(num2, num3), num5);
if (dp[i] == num2) {
p2++;
}
if (dp[i] == num3) {
p3++;
}
if (dp[i] == num5) {
p5++;
}
}
return dp[n];
}
};
174. 地下城游戏
恶魔们抓住了公主并将她关在了地下城 `dungeon` 的 **右下角** 。地下城是由 `m x n` 个房间组成的二维网格。我们英勇的骑士最初被安置在 **左上角** 的房间里,他必须穿过地下城并通过对抗恶魔来拯救公主。
骑士的初始健康点数为一个正整数。如果他的健康点数在某一时刻降至 0 或以下,他会立即死亡。
有些房间由恶魔守卫,因此骑士在进入这些房间时会失去健康点数(若房间里的值为_负整数_,则表示骑士将损失健康点数);其他房间要么是空的(房间里的值为 _0_),要么包含增加骑士健康点数的魔法球(若房间里的值为_正整数_,则表示骑士将增加健康点数)。
为了尽快解救公主,骑士决定每次只 **向右** 或 **向下** 移动一步。
返回确保骑士能够拯救到公主所需的最低初始健康点数。
**注意:**任何房间都可能对骑士的健康点数造成威胁,也可能增加骑士的健康点数,包括骑士进入的左上角房间以及公主被监禁的右下角房间
- 非常惊艳的题目,因为正向dp需要考虑剩余血量和走到当前位置的最少初始血量,导致无法dp,因此需要逆向dp,从终点向回走,因为从终点走,不需要考虑死亡的问题
class Solution {
public:
int calculateMinimumHP(vector<vector<int>>& dungeon) {
int n = dungeon.size(), m = dungeon[0].size();
vector<vector<int>> dp(n + 1, vector<int>(m + 1, INT_MAX));
dp[n][m - 1] = dp[n - 1][m] = 1;
for (int i = n - 1; i >= 0; --i) {
for (int j = m - 1; j >= 0; --j) {
int minn = min(dp[i + 1][j], dp[i][j + 1]);
dp[i][j] = max(minn - dungeon[i][j], 1);
}
}
return dp[0][0];
}
};
410. 分割数组的最大值
给定一个非负整数数组 `nums` 和一个整数 `m` ,你需要将这个数组分成 `m` 个非空的连续子数组。
设计一个算法使得这 `m` 个子数组各自和的最大值最小。
- 这个中分割类的题型的同一解法可以令 发[i][j]表示将数组的前 i 个数分割为 j 段所能得到的最大连续子数组和的最小值。在进行状态转移时,我们可以考虑第 j 段的具体范围,即我们可以枚举 k,其中前 k 个数被分割为 j-1 段,而第 k+1 到第 i 个数为第 j 段。此时,这 j 段子数组中和的最大值,就等于 f[k][j−1] 与 sub(k+1,i)的较大值,其中 sub(i,j)表示数组 nums中下标落在区间 [i,j] 内的数的和。由于我们要使得子数组中和的最大值最小,因此可以列出如下的状态转移方程:
f[i][j]=min(0<=k<=i){max(f[k][j-1],sub(k+1,j))}
class Solution {
public:
int splitArray(vector<int>& nums, int m) {
int n = nums.size();
vector<vector<long long>> f(n + 1, vector<long long>(m + 1, LLONG_MAX));
vector<long long> sub(n + 1, 0);
for (int i = 0; i < n; i++) {
sub[i + 1] = sub[i] + nums[i];
}
f[0][0] = 0;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= min(i, m); j++) {
for (int k = 0; k < i; k++) {
f[i][j] = min(f[i][j], max(f[k][j - 1], sub[i] - sub[k]));
}
}
}
return (int)f[n][m];
}
};
- 贪心+二分法, #TODO 整理
2209. 用地毯覆盖后的最少白色砖块
给你一个下标从 **0** 开始的 **二进制** 字符串 `floor` ,它表示地板上砖块的颜色。
- `floor[i] = '0'` 表示地板上第 `i` 块砖块的颜色是 **黑色** 。
- `floor[i] = '1'` 表示地板上第 `i` 块砖块的颜色是 **白色** 。
同时给你 `numCarpets` 和 `carpetLen` 。你有 `numCarpets` 条 **黑色** 的地毯,每一条 **黑色** 的地毯长度都为 `carpetLen` 块砖块。请你使用这些地毯去覆盖砖块,使得未被覆盖的剩余 **白色** 砖块的数目 **最小** 。地毯相互之间可以覆盖。
请你返回没被覆盖的白色砖块的 **最少** 数目。
- 一个非常典型的动态规划问题类似背包问题,dp[i][j]标识第i块砖上放j块毛毯最大的覆盖面积
for (int i = 0; i < floor.size(); i++) {
if (i-carpetLen>=0) {
if (floor[i-carpetLen]=='1') {
now--;
}
}
if (floor[i]=='1') {
now++;
}
arr[i]=now;
}
vector<vector<int>> dp(floor.size(),vector<int>(numCarpets,0));
int all=0,cover=0;
for (int i = 0; i < floor.size(); i++) {
if (i>0) {
dp[i]=dp[i-1];
}
if (floor[i]=='1') {
all++;
int pos=i-carpetLen;
for (int j = 0; j < numCarpets; j++) {
int temp=0;
if (pos>=0&&j>0) {
temp=dp[pos][j-1];
}
dp[i][j]=max(dp[i][j],temp+arr[i]);
cover=max(cover,dp[i][j]);
}
}
}
return all-cover;
}
2998. 使 X 和 Y 相等的最少操作次数
给你两个正整数 `x` 和 `y` 。
一次操作中,你可以执行以下四种操作之一:
1. 如果 `x` 是 `11` 的倍数,将 `x` 除以 `11` 。
2. 如果 `x` 是 `5` 的倍数,将 `x` 除以 `5` 。
3. 将 `x` 减 `1` 。
4. 将 `x` 加 `1` 。
请你返回让 `x` 和 `y` 相等的 **最少** 操作次数。
- 一个很有意思的dp题目,因为不是先往常的可以从前向后遍历(类似青蛙跳那种),这个状态从前和后面都出现了
- 因此这里需要引入bfs
queue<int> que;
que.push(x);
while (!que.empty()) {
auto pos=que.front();
auto num=dp[pos];
que.pop();
if (pos%11==0&&num+1<dp[pos/11]) {
dp[pos/11]=num+1;
que.push(pos/11);
}
if (pos%5==0&&num+1<dp[pos/5]) {
dp[pos/5]=num+1;
que.push(pos/5);
}
if (pos>0&&num+1<dp[pos-1]) {
dp[pos-1]=num+1;
que.push(pos-1);
}
if (pos+1<dp.size()&&num+1<dp[pos+1]) {
dp[pos+1]=num+1;
que.push(pos+1);
}
}
360笔试第二题
用1表示a,用2表示b...,26标识z,给定一个字符串(如1324929067),求这个字符串能对应多少种ab这种类型的标识
- 用的是dp优点难想到,这种一般想到的是递归
- 使用dp[i]表示前i个数字有多少种表示,根据dp[i-1]和dp[i-2]获取
int last=-1;
for (int i = 0; i < size; i++) {
int now=str[i]-'0';
int old=now;
if (now==0) {
if (last==-1||last==0) {
cout<<0;
return 0;
}else {
now=last*10+now;
if(now>26||i<1){
cout<<0;
return 0;
}
if (i>1) {
dp[i]+=dp[i-2]%mod;
}else {
dp[i]=1;
}
}
}else {
if (i!=0) {
dp[i]+=dp[i-1]%mod;
}else {
dp[i]+=1;
}
if (last>0) {
now=last*10+now;
if (now<=26) {
if (i>1) {
dp[i]+=dp[i-2]%mod;
}else {
dp[i]+=1;
}
}
}
}
dp[i]%=mod;
last=old;
}
区间dp
- 将数组分成若干份,求每份某个属性之和的最值就可以想到“I型区间DP”,套路很固定
1335. 工作计划的最低难度
你需要制定一份 `d` 天的工作计划表。工作之间存在依赖,要想执行第 `i` 项工作,你必须完成全部 `j` 项工作( `0 <= j < i`)。
你每天 **至少** 需要完成一项任务。工作计划的总难度是这 `d` 天每一天的难度之和,而一天的工作难度是当天应该完成工作的最大难度。
给你一个整数数组 `jobDifficulty` 和一个整数 `d`,分别代表工作难度和需要计划的天数。第 `i` 项工作的难度是 `jobDifficulty[i]`。
返回整个工作计划的 **最小难度** 。如果无法制定工作计划,则返回 **-1** 。
- 直接看这里
class Solution {
public:
int minDifficulty(vector<int>& jobDifficulty, int d) {
int n = jobDifficulty.size();
if (n < d) {
return -1;
}
vector<vector<int>> dp(d + 1, vector<int>(n, 0x3f3f3f3f));
int ma = 0;
for (int i = 0; i < n; ++i) {
ma = max(ma, jobDifficulty[i]);
dp[0][i] = ma;
}
for (int i = 1; i < d; ++i) {
for (int j = i; j < n; ++j) {
ma = 0;
for (int k = j; k >= i; --k) {
ma = max(ma, jobDifficulty[k]);
dp[i][j] = min(dp[i][j], ma + dp[i - 1][k - 1]);
}
}
}
return dp[d - 1][n - 1];
}
};
股票问题
121. 买卖股票的最佳时机
给定一个数组 `prices` ,它的第 `i` 个元素 `prices[i]` 表示一支给定股票第 `i` 天的价格。
你只能选择 **某一天** 买入这只股票,并选择在 **未来的某一个不同的日子** 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 `0` 。
- 作为easy,只需要记下目前最小值作为买入,遍历时候顺便计算利润最大值
122. 买卖股票的最佳时机 II
给你一个整数数组 `prices` ,其中 `prices[i]` 表示某支股票第 `i` 天的价格。
在每一天,你可以决定是否购买和/或出售股票。你在任何时候 **最多** 只能持有 **一股** 股票。你也可以先购买,然后在 **同一天** 出售。
返回 _你能获得的 **最大** 利润_
- 贪心:收集所有上坡的部分,结果一定最大化
class Solution {
public:
int maxProfit(vector<int>& prices) {
int ans = 0;
int n = prices.size();
for (int i = 1; i < n; ++i) {
ans += max(0, prices[i] - prices[i - 1]);
}
return ans;
}
};
- 动态规划
- 定义状态 dp[i][0]表示第 i 天交易完后手里没有股票的最大利润,dp[i][1]表示第 i天交易完后手里持有一支股票的最大利润(i 从 0 开始)
dp[i][0]=max{dp[i−1][0],dp[i−1][1]+prices[i]}
dp[i][1]=max{dp[i−1][1],dp[i−1][0]−prices[i]}
class Solution {
public:
int maxProfit(vector<int>& prices) {
int n = prices.size();
int dp0 = 0, dp1 = -prices[0];
for (int i = 1; i < n; ++i) {
int newDp0 = max(dp0, dp1 + prices[i]);
int newDp1 = max(dp1, dp0 - prices[i]);
dp0 = newDp0;
dp1 = newDp1;
}
return dp0;
}
};
714. 买卖股票的最佳时机含手续费
给定一个整数数组 `prices`,其中 `prices[i]`表示第 `i` 天的股票价格 ;整数 `fee` 代表了交易股票的手续费用。
你可以无限次地完成交易,但是你每笔交易都需要付手续费。如果你已经购买了一个股票,在卖出它之前你就不能再继续购买股票了。
返回获得利润的最大值。
**注意:**这里的一笔交易指买入持有并卖出股票的整个过程,每笔交易你只需要为支付一次手续费。
- 类似上一题,只不过购买的时候加上手续费
class Solution {
public:
int maxProfit(vector<int>& prices, int fee) {
int n = prices.size();
vector<vector<int>> dp(n, vector<int>(2));
dp[0][0] = 0, dp[0][1] = -prices[0];
for (int i = 1; i < n; ++i) {
dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] + prices[i] - fee);
dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] - prices[i]);
}
return dp[n - 1][0];
}
};
- 类似上一题的贪心算法,判断时候需要大于手续费
class Solution {
public:
int maxProfit(vector<int>& prices, int fee) {
int n = prices.size();
int buy = prices[0] + fee;
int profit = 0;
for (int i = 1; i < n; ++i) {
if (prices[i] + fee < buy) {
buy = prices[i] + fee;
}
else if (prices[i] > buy) {
profit += prices[i] - buy;
buy = prices[i];
}
}
return profit;
}
};
309. 最佳买卖股票时机含冷冻期
给定一个整数数组`prices`,其中第 `prices[i]` 表示第 `_i_` 天的股票价格 。
设计一个算法计算出最大利润。在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股票):
- 卖出股票后,你无法在第二天买入股票 (即冷冻期为 1 天)。
**注意:**你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
- 也是动态规划,不过dp[i][1]从上上个获取
class Solution {
public:
int maxProfit(vector<int>& prices) {
vector<vector<int>> value(prices.size(),vector<int>(2,0));
value[0][0]=0,value[0][1]=-prices[0];
for(unsigned i=1;i<prices.size();i++)
{
value[i][0]=max(value[i-1][0],value[i-1][1]+prices[i]);
if(i>1)
value[i][1]=max(value[i-1][1],value[i-2][0]-prices[i]);
else
value[i][1]=max(value[i-1][1],value[i-1][0]-prices[i]);
}
return value[value.size()-1][0];
}
};
123. 买卖股票的最佳时机 III IV
给定一个数组,它的第 `i` 个元素是一支给定的股票在第 `i` 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 **两笔** 交易。
**注意:**你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
- 由于我们最多可以完成两笔交易,因此在任意一天结束之后,我们会处于以下五个状态中的一种: 未进行过任何操作; 只进行过一次买操作; 进行了一次买操作和一次卖操作,即完成了一笔交易; 在完成了一笔交易的前提下,进行了第二次买操作; 完成了全部两笔交易。
for (int i = 0; i < prices.size(); i++) {
if (i==0) {
dp[i][0]=0;
dp[i][1]=-prices[0];
}else {
auto& last=dp[i-1];
dp[i][0]=last[0];
dp[i][1]=max(last[0]-prices[i],last[1]);
if (i>0) {
dp[i][2]=max(last[1]+prices[i],last[2]);
}
if (i>1) {
dp[i][3]=max(last[2]-prices[i],last[3]);
}
if (i>2) {
dp[i][4]=max(last[3]+prices[i],last[4]);
}
}
auto iter=max_element(dp[i].begin(),dp[i].end());
result=max(result,*iter);
}
打劫问题
198. 打家劫舍I and III
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,**如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警**。
给定一个代表每个房屋存放金额的非负整数数组,计算你 **不触动警报装置的情况下** ,一夜之内能够偷窃到的最高金额。
- 简单动态规划问题,核心在于两个状态的dp
dp[0]=nums[0]只有一间房屋,则偷窃该房屋
dp[1]=max(nums[0],nums[1])只有两间房屋,选择其中金额较高的房屋进行偷窃
213. 打家劫舍 II
你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金。这个地方所有的房屋都 **围成一圈** ,这意味着第一个房屋和最后一个房屋是紧挨着的。同时,相邻的房屋装有相互连通的防盗系统,**如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警** 。
给定一个代表每个房屋存放金额的非负整数数组,计算你 **在不触动警报装置的情况下** ,今晚能够偷窃到的最高金额。
- 上面类似,分两种情况,偷第一家,删除最后一家,不偷第一家,从1开始遍历
背包问题
01背包问题
有N件物品和一个最多能被重量为W 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。**每件物品只能用一次**,求解将哪些物品装入背包里物品价值总和最大。
- dp[i][j]的含义:从下标[0-i]的物品里任意取,放进容量为j的背包,价值总和最大是多少。
- 由dp[i - 1][j]推出,即背包容量为j,里面不放物品i的最大价值,此时dp[i][j]就是dp[i - 1][j]
- 由dp[i - 1][j - weight[i]]推出,dp[i - 1][j - weight[i]] 为背包容量为j - weight[i]的时候不放物品i的最大价值,那么dp[i - 1][j - weight[i]] + value[i] (物品i的价值),就是背包放物品i得到的最大价值
- 所以递归公式: dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]
// 初始化:第一列都是0,第一行表示只选取0号物品最大价值
for (int j = bagWeight; j >= weight[0]; j--)
dp[0][j] = dp[0][j - weight[0]] + value[0];
// weight数组的大小 就是物品个数
for (int i = 1; i < weight.size(); i++) // 遍历物品(第0个物品已经初始化)
{
for (int j = 0; j <= bagWeight; j++) // 遍历背包容量
{
if (j < weight[i]) //背包容量已经不足以拿第i个物品了
dp[i][j] = dp[i - 1][j]; //最大价值就是拿第i-1个物品的最大价值
//背包容量足够拿第i个物品,可拿可不拿:拿了最大价值是前i-1个物品扣除第i个物品的 重量的最大价值加上i个物品的价值
//不拿就是前i-1个物品的最大价值,两者进行比较取较大的
else
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}
- 二维代码可以进行优化,去除选取物品的那一层,简化为一维背包 // 一维 //状态定义:dp[j]表示容量为j的背包能放下东西的最大价值
// 初始化
vector<int> dp(bagWeight + 1, 0);
for (int i = 0; i < weight.size(); i++)
{ // 遍历物品
for (int j = bagWeight; j >= weight[i]; j--)
{ // 遍历背包容量(一定要逆序)
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]); //不取或者取第i个
}
}
1049. 最后一块石头的重量 II
有一堆石头,用整数数组 `stones` 表示。其中 `stones[i]` 表示第 `i` 块石头的重量。
每一回合,从中选出**任意两块石头**,然后将它们一起粉碎。假设石头的重量分别为 `x` 和 `y`,且 `x <= y`。那么粉碎的可能结果如下:
- 如果 `x == y`,那么两块石头都会被完全粉碎;
- 如果 `x != y`,那么重量为 `x` 的石头将会完全粉碎,而重量为 `y` 的石头新重量为 `y-x`。
最后,**最多只会剩下一块** 石头。返回此石头 **最小的可能重量** 。如果没有石头剩下,就返回 `0`。
- 从一堆石头中,每次拿两块重量分别为x,y的石头,若x=y,则两块石头均粉碎;若x<y,两块石头变为一块重量为y-x的石头求最后剩下石头的最小重量(若没有剩下返回0) 问题转化为:把一堆石头分成两堆,求两堆石头重量差最小值 进一步分析:要让差值小,两堆石头的重量都要接近sum/2;我们假设两堆分别为A,B,A<sum/2,B>sum/2,若A更接近sum/2,B也相应更接近sum/2 进一步转化:将一堆stone放进最大容量为sum/2的背包,求放进去的石头的最大重量MaxWeight,最终答案即为sum-2*MaxWeight
参考
- https://zhuanlan.zhihu.com/p/345364527
- https://leetcode.cn/problems/last-stone-weight-ii/solutions/805162/yi-pian-wen-zhang-chi-tou-bei-bao-wen-ti-5lfv/
146. LRU 缓存
请你设计并实现一个满足 [LRU (最近最少使用) 缓存](https://baike.baidu.com/item/LRU) 约束的数据结构。
实现 `LRUCache` 类:
`LRUCache(int capacity)` 以 **正整数** 作为容量 `capacity` 初始化 LRU 缓存
`int get(int key)` 如果关键字 `key` 存在于缓存中,则返回关键字的值,否则返回 `-1` 。
`void put(int key, int value)` 如果关键字 `key` 已经存在,则变更其数据值 `value` ;如果不存在,则向缓存中插入该组 `key-value` 。如果插入操作导致关键字数量超过 `capacity` ,则应该 **逐出** 最久未使用的关键字。
函数 `get` 和 `put` 必须以 `O(1)` 的平均时间复杂度运行。
- 通过双向链表,最新使用的插入链表头,删除链表内原来地址,淘汰链表尾部分
- 通过map建立key和node*之间联系.
[!question] 缺点 对突发流量表现差,突然的大量key很可能把一些重要的key踢下去
[!quote] 场景 如果数据的使用频率比较均匀,没有明显的热点数据,那么 LRU 算法比较适合。例如,一个在线书店的图书搜索页面,用户搜索图书的请求会比较频繁,但是对于每本书的访问并没有特别的频繁,这时 LRU 算法就能够很好地满足需求。
460. LFU 缓存
请你为 [最不经常使用(LFU)](https://baike.baidu.com/item/%E7%BC%93%E5%AD%98%E7%AE%97%E6%B3%95)缓存算法设计并实现数据结构。
实现 `LFUCache` 类:
- `LFUCache(int capacity)` - 用数据结构的容量 `capacity` 初始化对象
- `int get(int key)` - 如果键 `key` 存在于缓存中,则获取键的值,否则返回 `-1` 。
- `void put(int key, int value)` - 如果键 `key` 已存在,则变更其值;如果键不存在,请插入键值对。当缓存达到其容量 `capacity` 时,则应该在插入新项之前,移除最不经常使用的项。在此问题中,当存在平局(即两个或更多个键具有相同使用频率)时,应该去除 **最近最久未使用** 的键。
为了确定最不常使用的键,可以为缓存中的每个键维护一个 **使用计数器** 。使用计数最小的键是最久未使用的键。
当一个键首次插入到缓存中时,它的使用计数器被设置为 `1` (由于 put 操作)。对缓存中的键执行 `get` 或 `put` 操作,使用计数器的值将会递增。
函数 `get` 和 `put` 必须以 `O(1)` 的平均时间复杂度运行。
- 通过有序map记录每一条key的使用频率,自动排序,用hash记录key和val关系,时间复杂度log(n)
- 通过双hash机制,一个hash记录使用频率和一个链表,一个hash记录key和node*,当查询时候,增加使用频率,从hash中的链表拿出,换到下一个使用频率hash的链表,时间复杂度为O(1),重要
- 需要维护一个minFreq的变量,用来记录LFU缓存中频率最小的元素,在缓存满的时候,可以快速定位到最小频繁的链表,以达到 O(1) 时间复杂度删除一个元素。 具体做法是:
- 更新/查找的时候,将元素频率+1,之后如果minFreq不在频率哈希表中了,说明频率哈希表中已经没有元素了,那么minFreq需要+1,否则minFreq不变。
- 插入的时候将minFreq改为1即可。
[!question] 缺点 一个数字一旦积累了次数就很难被替换下来,但是很多时候有的数据遇有时效性 而且消耗大量空间,因为所有出现过的key都要记录频率
[!quote] 场景 如果数据有明显的热点,即某些数据被频繁访问,而其他数据则很少被访问,那么 LFU 算法比较适合。例如,一个视频网站的首页,某些热门视频会被很多用户频繁地访问,而其他视频则很少被访问,这时 LFU 算法就能够更好地满足需求。
2. 两数相加
给你两个 **非空** 的链表,表示两个非负的整数。它们每位数字都是按照 **逆序** 的方式存储的,并且每个节点只能存储 **一位** 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
- 通过递归或者栈实现,注意进位
11. 盛最多水的容器
给定一个长度为 `n` 的整数数组 `height` 。有 `n` 条垂线,第 `i` 条线的两个端点是 `(i, 0)` 和 `(i, height[i])` 。
找出其中的两条线,使得它们与 `x` 轴共同构成的容器可以容纳最多的水。
返回容器可以储存的最大水量。
**说明:**你不能倾斜容器。
- 典型双指针题目,每次移动短的边
class Solution {
public:
int maxArea(vector<int>& height) {
int begin=0,end=height.size()-1,result=0;
while (begin<end) {
result=max((end-begin)*min(height[end],height[begin]),result);
if (height[end]>height[begin]) {
begin++;
}else {
end--;
}
}
return result;
}
};
19. 删除链表的倒数第 N 个结点
给你一个链表,删除链表的倒数第 `n` 个结点,并且返回链表的头结点。
- 典型双指针问题,一个指针先领先一个指针N个身位,然后后面到尾巴把前面先面的指针节点删除
23. 合并K个升序链表
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
- 解法一
- 考虑两个链表的情况,典型的双指针
- 先1,2生成链表再依次和下一个合并
- 解法二
- 通过优先队列
32. 最长有效括号
给你一个只包含 `'('` 和 `')'` 的字符串,找出最长有效(格式正确且连续)括号子串的长度。
- 看到括号上栈
class Solution {
public:
int longestValidParentheses(string s) {
int result=0,now=0;
stack<int> sta;
for (auto ch : s) {
if (ch==')') {
if (sta.empty()) {
now=0;
}else {
auto temp=sta.top();
sta.pop();
now+=2+temp;
result=max(result,now);
}
}else {
sta.push(now);
now=0;
}
}
return result;
}
};
33. 搜索旋转排序数组
整数数组 `nums` 按升序排列,数组中的值 **互不相同** 。
在传递给函数之前,`nums` 在预先未知的某个下标 `k`(`0 <= k < nums.length`)上进行了 **旋转**,使数组变为 `[nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]]`(下标 **从 0 开始** 计数)。例如, `[0,1,2,4,5,6,7]` 在下标 `3` 处经旋转后可能变为 `[4,5,6,7,0,1,2]` 。
给你 **旋转后** 的数组 `nums` 和一个整数 `target` ,如果 `nums` 中存在这个目标值 `target` ,则返回它的下标,否则返回 `-1` 。
你必须设计一个时间复杂度为 `O(log n)` 的算法解决此问题。
- 典型二分搜索变形题,当mid最小右边有序,mid最大左边有序,如果从小到大说明有序,有序部分直接二分搜索
字节青训营考过
34. 在排序数组中查找元素的第一个和最后一个位置
给你一个按照非递减顺序排列的整数数组 `nums`,和一个目标值 `target`。请你找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 `target`,返回 `[-1, -1]`。
你必须设计并实现时间复杂度为 `O(log n)` 的算法解决此问题。
- 典型二分搜索
42. 接雨水
给定 `n` 个非负整数表示每个宽度为 `1` 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
- 单调栈
- 通过维持单调递减的栈,遇到大的就弹出并且计算储存的水数量
- 前缀数组
- 前缀和后缀,拿到交集

- 双指针
- 左右分别两个指针,小的指针移动,同时记录对应边的最高值计算雨水
56. 合并区间
以数组 `intervals` 表示若干个区间的集合,其中单个区间为 `intervals[i] = [starti, endi]` 。请你合并所有重叠的区间,并返回 _一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间_ 。
- 以左边界排序,排序之后,进行逐个比较右边界
84. 柱状图中最大的矩形
给定 _n_ 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。
- 典型单调栈
- 在一维数组中对每一个数找到第一个比自己小的元素。这类“在一维数组中找第一个满足某种条件的数”的场景就是典型的单调栈应用场景。
155. 最小栈
设计一个支持 `push` ,`pop` ,`top` 操作,并能在常数时间内检索到最小元素的栈。
实现 `MinStack` 类:
- `MinStack()` 初始化堆栈对象。
- `void push(int val)` 将元素val推入堆栈。
- `void pop()` 删除堆栈顶部的元素。
- `int top()` 获取堆栈顶部的元素。
- `int getMin()` 获取堆栈中的最小元素。
- 辅助栈经典题目
对于栈来说,如果一个元素 a 在入栈时,栈里有其它的元素 b, c, d,那么无论这个栈在之后经历了什么操作,只要 a 在栈中,b, c, d 就一定在栈中,因为在 a 被弹出之前,b, c, d 不会被弹出。
因此,在操作过程中的任意一个时刻,只要栈顶的元素是 a,那么我们就可以确定栈里面现在的元素一定是 a, b, c, d。
那么,我们可以在每个元素 a 入栈时把当前栈的最小值 m 存储起来。在这之后无论何时,如果栈顶元素是 a,我们就可以直接返回存储的最小值 m。
946. 验证栈序列
给定 `pushed` 和 `popped` 两个序列,每个序列中的 **值都不重复**,只有当它们可能是在最初空栈上进行的推入 push 和弹出 pop 操作序列的结果时,返回 `true`;否则,返回 `false` 。
- 纯粹的栈模拟,用一个栈模拟操作
class Solution {
public:
bool validateStackSequences(vector<int>& pushed, vector<int>& popped) {
stack<int> st;
int n = pushed.size();
for (int i = 0, j = 0; i < n; i++) {
st.emplace(pushed[i]);
while (!st.empty() && st.top() == popped[j]) {
st.pop();
j++;
}
}
return st.empty();
}
};
- 若一个数字被pop,那么他右边到之前最大的数字之间的距离都应该被pop了
bool validateStackSequences(vector<int>& pushed, vector<int>& popped) {
unordered_map<int, int> hashMap;
unordered_set<int> popnum;
for (int i = 0; i < pushed.size(); i++) {
hashMap.insert({pushed[i],i});
}
bool result=false;
int right=-1;
for (int i = 0; i < popped.size(); i++) {
auto temp=hashMap[popped[i]];
right=max(right,temp);
popnum.insert(temp);
if (right>temp) {
for (int i = temp+1; i < right; ++i) {
if (popnum.find(i)==popnum.end()) {
return false;
}
}
}
}
return true;
}
739. 每日温度
给定一个整数数组 `temperatures` ,表示每天的温度,返回一个数组 `answer` ,其中 `answer[i]` 是指对于第 `i` 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 `0` 来代替。
- 维护单调栈,经典题目
992. K 个不同整数的子数组
给定一个正整数数组 `nums`和一个整数 k ,返回 num 中 「**好子数组」** 的数目。
如果 `nums` 的某个子数组中不同整数的个数恰好为 `k`,则称 `nums` 的这个连续、不一定不同的子数组为 **「****好子数组 」**。
- 例如,`[1,2,3,1,2]` 中有 `3` 个不同的整数:`1`,`2`,以及 `3`。
**子数组** 是数组的 **连续** 部分。
- 三指针题目,恰好n个拆解为最多n个和最少n个的交集,成为三指针
- 左边为最长,中间为最短,右边负责移动
class Solution {
public:
int subarraysWithKDistinct(vector<int>& nums, int k) {
int left=0,mid=0,right=0,result=0;
unordered_map<int, int> hashMax,hashMin;
while (right!=nums.size()||left!=right) {
if (hashMax.size()==k) {
while (hashMin.size()!=k-1) {
hashMin[nums[mid]]--;
if (hashMin[nums[mid]]==0) {
hashMin.erase(nums[mid]);
}
mid++;
}
result+=mid-left;
if (right==nums.size()) {
break;
}
}
if (hashMax.size()<=k&&right!=nums.size()) {
hashMax[nums[right]]++;
hashMin[nums[right]]++;
right++;
}else if (hashMax.size()>=k&&left!=right) {
hashMax[nums[left]]--;
if (hashMax[nums[left]]==0) {
hashMax.erase(nums[left]);
}
left++;
}else {
break;
}
}
return result;
}
}
1944. 队列中可以看到的人数
有 `n` 个人排成一个队列,**从左到右** 编号为 `0` 到 `n - 1` 。给你以一个整数数组 `heights` ,每个整数 **互不相同**,`heights[i]` 表示第 `i` 个人的高度。
一个人能 **看到** 他右边另一个人的条件是这两人之间的所有人都比他们两人 **矮** 。更正式的,第 `i` 个人能看到第 `j` 个人的条件是 `i < j` 且 `min(heights[i], heights[j]) > max(heights[i+1], heights[i+2], ..., heights[j-1])` 。
请你返回一个长度为 `n` 的数组 `answer` ,其中 `answer[i]` 是第 `i` 个人在他右侧队列中能 **看到** 的 **人数** 。
- 单调栈,维护一个最大单调栈(反正右边小的会被忽略)
class Solution {
public:
vector<int> canSeePersonsCount(vector<int>& heights) {
reverse(heights.begin(),heights.end());
vector<int> result;
stack<int> sta;
for (int i = 0; i < heights.size(); i++) {
int now=heights[i];
int nowresult=0;
while (!sta.empty()&&heights[sta.top()]<now) {
sta.pop();
nowresult++;
}
if (!sta.empty()) {
nowresult++;
}
sta.push(i);
result.push_back(nowresult);
}
reverse(result.begin(), result.end());
return result;
}
};
402. 移掉 K 位数字
给你一个以字符串表示的非负整数 `num` 和一个整数 `k` ,移除这个数中的 `k` 位数字,使得剩下的数字最小。请你以字符串形式返回这个最小的数字。
- 使用单调栈,对于每个数字,如果该数字小于栈顶元素,我们就不断地弹出栈顶元素,直到
- 栈为空
- 或者新的栈顶元素不大于当前数字
- 或者我们已经删除了 k 位数字
- 如果做后k个数字还有剩余,就继续pop最后的数字
class Solution {
public:
string removeKdigits(string num, int k) {
vector<char> stk;
for (auto& digit: num) {
while (stk.size() > 0 && stk.back() > digit && k) {
stk.pop_back();
k -= 1;
}
stk.push_back(digit);
}
for (; k > 0; --k) {
stk.pop_back();
}
string ans = "";
bool isLeadingZero = true;
for (auto& digit: stk) {
if (isLeadingZero && digit == '0') {
continue;
}
isLeadingZero = false;
ans += digit;
}
return ans == "" ? "0" : ans;
}
}
2866. 美丽塔 II
给你一个长度为 `n` 下标从 **0** 开始的整数数组 `maxHeights` 。
你的任务是在坐标轴上建 `n` 座塔。第 `i` 座塔的下标为 `i` ,高度为 `heights[i]` 。
如果以下条件满足,我们称这些塔是 **美丽** 的:
1. `1 <= heights[i] <= maxHeights[i]`
2. `heights` 是一个 **山脉** 数组。
如果存在下标 `i` 满足以下条件,那么我们称数组 `heights` 是一个 **山脉** 数组:
- 对于所有 `0 < j <= i` ,都有 `heights[j - 1] <= heights[j]`
- 对于所有 `i <= k < n - 1` ,都有 `heights[k + 1] <= heights[k]`
请你返回满足 **美丽塔** 要求的方案中,**高度和的最大值** 。
- 有意思的单调栈题目,思路很难想,涉及到数组的区间替代的都是上单调栈,因为使用后面的替代前面的部分
class Solution {
public:
long long maximumSumOfHeights(vector<int> &maxHeights) {
stack<pair<long long, pair<long long, long long>>> sta;
vector<long long> prefix(maxHeights.size(), 0),
suffix(maxHeights.size(), 0);
for (int i = 0; i < maxHeights.size(); i++) {
while (!sta.empty() && sta.top().first > maxHeights[i]) {
sta.pop();
}
if (sta.empty()) {
sta.push({maxHeights[i], {(i + 1) * (long long)maxHeights[i], i}});
} else {
auto top = sta.top().second;
sta.push(
{maxHeights[i], {top.first + (long long)maxHeights[i] * (i - top.second), i}});
}
prefix[i] = sta.top().second.first;
}
while (!sta.empty()) {
sta.pop();
}
for (int i = maxHeights.size() - 1; i >= 0; i--) {
while (!sta.empty() && sta.top().first > maxHeights[i]) {
sta.pop();
}
if (sta.empty()) {
sta.push({maxHeights[i], {(maxHeights.size() - i) * (long long)maxHeights[i], i}});
} else {
auto top = sta.top().second;
sta.push(
{maxHeights[i], {top.first + (long long)maxHeights[i] * (top.second - i), i}});
}
suffix[i] = sta.top().second.first;
}
long long res = 0;
for (int i = 0; i < maxHeights.size(); i++) {
res = max(res, prefix[i] + suffix[i] - (long long)maxHeights[i]);
}
return res;
}
};
55. 跳跃游戏
给定一个非负整数数组 `nums` ,你最初位于数组的 **第一个下标** 。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标。
- DFS,深度优先,遍历所有可能的路径(太慢)
- 贪心,维护一个最远可到达地点,然后最后比较是否是终点就ok
class Solution {
public:
bool canJump(vector<int>& nums) {
int n = nums.size();
int rightmost = 0;
for (int i = 0; i < n; ++i) {
if (i <= rightmost) {
rightmost = max(rightmost, i + nums[i]);
if (rightmost >= n - 1) {
return true;
}
}
}
return false;
}
};
64. 最小路径和
给定一个包含非负整数的 `_m_ x _n_` 网格 `grid` ,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
**说明:**每次只能向下或者向右移动一步。
- 典型的BFS
200. 岛屿数量
给你一个由 `'1'`(陆地)和 `'0'`(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
- 经典BFS或者并查集
207. 课程表
你这个学期必须选修 `numCourses` 门课程,记为 `0` 到 `numCourses - 1` 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 `prerequisites` 给出,其中 `prerequisites[i] = [ai, bi]` ,表示如果要学习课程 `ai` 则 **必须** 先学习课程 `bi` 。
- 例如,先修课程对 `[0, 1]` 表示:想要学习课程 `0` ,你需要先完成课程 `1` 。
请你判断是否可能完成所有课程的学习?如果可以,返回 `true` ;否则,返回 `false` 。
- 有向图是否存在环的问题
- DFS或者BFS
215. 数组中的第K个最大元素
给定整数数组 `nums` 和整数 `k`,请返回数组中第 `**k**` 个最大的元素。
请注意,你需要找的是数组排序后的第 `k` 个最大的元素,而不是第 `k` 个不同的元素。
你必须设计并实现时间复杂度为 `O(n)` 的算法解决此问题。
2290. 到达角落需要移除障碍物的最小数目
给你一个下标从 **0** 开始的二维整数数组 `grid` ,数组大小为 `m x n` 。每个单元格都是两个值之一:
- `0` 表示一个 **空** 单元格,
- `1` 表示一个可以移除的 **障碍物** 。
你可以向上、下、左、右移动,从一个空单元格移动到另一个空单元格。
现在你需要从左上角 `(0, 0)` 移动到右下角 `(m - 1, n - 1)` ,返回需要移除的障碍物的 **最小** 数目。
- 本质上是BFS,遍历中加入下次可以走的点,如果通过这条路到达下一个点的代价小于之前遍历的这个点的代价,将这个点加入队列中继续遍历
- 巧妙地一点在于障碍物看作代价为1的点,然后找到代价最小的点
class Solution {
static constexpr int dirs[4][2] = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};
public:
int minimumObstacles(vector<vector<int>> &grid) {
int m = grid.size(), n = grid[0].size();
int dis[m][n];
memset(dis, 0x3f, sizeof(dis));
dis[0][0] = 0;
deque<pair<int, int>> q;
q.emplace_front(0, 0);
while (!q.empty()) {
auto [x, y] = q.front();
q.pop_front();
for (auto &[dx, dy] : dirs) {
int nx = x + dx, ny = y + dy;
if (0 <= nx && nx < m && 0 <= ny && ny < n) {
int g = grid[nx][ny];
if (dis[x][y] + g < dis[nx][ny]) {
dis[nx][ny] = dis[x][y] + g;
g == 0 ? q.emplace_front(nx, ny) : q.emplace_back(nx, ny);
}
}
}
}
return dis[m - 1][n - 1];
}
};
其他
- BFS和DFS邻接矩阵时候时间复杂度为O(n2)
寻路算法
BFS和DFS
- BFS主要用于最短路径,但是比较慢需要全图遍历
- DFS主要用于解决有没有路径的问题
Dijkstra 算法
- 计算每一个节点距离起点的总移动代价。同时,还需要一个优先队列结构。对于所有待遍历的节点,放入优先队列中会按照代价进行排序.这个代价通常是到这里需要消耗的距离或者步数,每次都从优先队列中选出代价最小的作为下一个遍历的节点。直到到达终点为止。
- 如果这个代价设置为 每个节点到达终点的距离作为优先级,每次始终选取到终点移动代价最小(离终点最近)的节点作为下一个遍历的节点。这种算法称之为最佳优先(Best First)算法。
A*算法
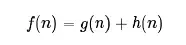
- 通过两个函数(g和h)结果得到优先级,然后放到优先队列中,每次找优先级最高的遍历
- f(n)是节点n的综合优先级。当我们选择下一个要遍历的节点时,我们总会选取综合优先级最高(值最小)的节点。
- g(n) 是节点n距离起点的代价。
- h(n)是节点n距离终点的预计代价,也就是A*算法的启发函数
* 初始化open_set和close_set;
* 将起点加入open_set中,并设置优先级为0(优先级最高);
* 如果open_set不为空,则从open_set中选取优先级最高的节点n:
* 如果节点n为终点,则:
* 从终点开始逐步追踪parent节点,一直达到起点;
* 返回找到的结果路径,算法结束;
* 如果节点n不是终点,则:
* 将节点n从open_set中删除,并加入close_set中;
* 遍历节点n所有的邻近节点:
* 如果邻近节点m在close_set中,则:
* 跳过,选取下一个邻近节点
* 如果邻近节点m也不在open_set中,则:
* 设置节点m的parent为节点n
* 计算节点m的优先级
* 将节点m加入open_set中
[!tip] h(n)启发函数
- 在极端情况下,当启发函数h(n)始终为0,则将由g(n)决定节点的优先级,此时算法就退化成了Dijkstra算法。
- 如果h(n)始终小于等于节点n到终点的代价,则A*算法保证一定能够找到最短路径。但是当h(n)的值越小,算法将遍历越多的节点,也就导致算法越慢。
- 如果h(n)完全等于节点n到终点的代价,则A*算法将找到最佳路径,并且速度很快。可惜的是,并非所有场景下都能做到这一点。因为在没有达到终点之前,我们很难确切算出距离终点还有多远。
- 如果h(n)的值比节点n到终点的代价要大,则A*算法不能保证找到最短路径,不过此时会很快。
- 在另外一个极端情况下,如果h(n)相较于g(n)大很多,则此时只有h(n)产生效果,这也就变成了最佳优先搜索。
- 如果图形中只允许朝上下左右四个方向移动,则可以使用曼哈顿距离(Manhattan distance)。
- 如果图形中允许朝八个方向移动,则可以使用对角距离。
- 如果图形中允许朝任何方向移动,则可以使用欧几里得距离(Euclidean distance)。
- 实际上来说 h(n)相当于深度优先,g(n)相当于广度优先,这两个权重的大小决定了结果和过程
[!tip] 参考 路径规划之 A* 算法 - 知乎
参考
- https://zhuanlan.zhihu.com/p/54510444
随机抽取
洗牌
洗牌算法
步骤
- 将数组分为以弄混和为弄混两部分
- 随机从未弄混(包含自己)拿出一个和未弄混的最后一个位置进行调换

- 标记最后一个为已弄混

- 重复步骤
137. 只出现一次的数字 II
- 这种题通常有要考虑只能用到O(1)的空间复杂度
- 两种思路:
- 使用位运算,类似异或的手法消除多余的数字(这个通常很难想到,需要用到状态机之类的)
- 创建一个32位的数组,直接遍历所有数字每个bit都加1,然后判断最后哪个bit不是倍数再组装出一个数字结果
水塘抽样
给你一个未知长度的单链表,请你设计一个算法,只能遍历一次,随机地返回链表中的一个节点
- 遇到第
i个元素时,应该有1/i的概率选择该元素,1 - 1/i的概率保持原有的选择
int getRandom(ListNode head) {
Random r = new Random();
int i = 0, res = 0;
ListNode p = head;
// while 循环遍历链表
while (p != null) {
i++;
// 生成一个 [0, i) 之间的整数
// 这个整数等于 0 的概率就是 1/i
if (0 == r.nextInt(i)) {
res = p.val;
}
p = p.next;
}
return res;
}
带权重的抽样
- 使用前缀和区间划分方法,将不同权重等效为区间长度
- 使用二分搜索快捷查找区间的映射关系
三路快排
// 三路快排
void qsort(int arr[],int l,int r)
{
if(l>=r) return;
int i=l,j=l,k=r;
int val=arr[l+rand()%(r-l+1)];
while(i<=k) {
if(arr[i]<val)
swap(arr[i++],arr[j++]); // 这里可,前面是安全的。
else if(val<arr[i])
swap(arr[i],arr[k--]); // 这里 i 不能 ++, 还要判断一下后面扔过来的东西。
else i++;
}
qsort(arr,l,j-1); qsort(arr,k+1,r);
}
堆排
- 按顺序建立二叉树
- 递归查找每个子树最大值,调整树

#include <iostream>
#include <algorithm>
using namespace std;
void max_heapify(int arr[], int start, int end) {
// 建立父節點指標和子節點指標
int dad = start;
int son = dad * 2 + 1;
while (son <= end) { // 若子節點指標在範圍內才做比較
if (son + 1 <= end && arr[son] < arr[son + 1]) // 先比較兩個子節點大小,選擇最大的
son++;
if (arr[dad] > arr[son]) // 如果父節點大於子節點代表調整完畢,直接跳出函數
return;
else { // 否則交換父子內容再繼續子節點和孫節點比較
swap(arr[dad], arr[son]);
dad = son;
son = dad * 2 + 1;
}
}
}
void heap_sort(int arr[], int len) {
// 初始化,i從最後一個父節點開始調整
for (int i = len / 2 - 1; i >= 0; i--)
max_heapify(arr, i, len - 1);
// 先將第一個元素和已经排好的元素前一位做交換,再從新調整(刚调整的元素之前的元素),直到排序完畢
for (int i = len - 1; i > 0; i--) {
swap(arr[0], arr[i]);
max_heapify(arr, 0, i - 1);
}
}
归并排序
- 将数组分割成为两个更加小的数组
- 然后让小的数组有序,再合并成大的数组
void merge(vector<int>& arr, int l, int m, int r) {
// 计算左右两个子数组的长度
int n1 = m - l + 1;
int n2 = r - m;
// 创建临时的左右两个子数组
vector<int> L(n1), R(n2);
// 将原数组的数据拷贝到临时的左右两个子数组中
for (int i = 0; i < n1; i++)
L[i] = arr[l + i];
for (int j = 0; j < n2; j++)
R[j] = arr[m + 1 + j];
// 合并左右两个子数组至原数组
int i = 0, j = 0, k = l;
while (i < n1 && j < n2) {
if (L[i] <= R[j]) {
arr[k] = L[i];
i++;
}
else {
arr[k] = R[j];
j++;
}
k++;
}
// 将剩余元素加入到已经排好序的结果中
while (i < n1) {
arr[k] = L[i];
i++;
k++;
}
while (j < n2) {
arr[k] = R[j];
j++;
k++;
}
}
void mergeSort(vector<int>& arr, int l, int r) {
if (l < r) {
// 计算中间位置
int m = l + (r - l) / 2;
// 递归排序左右两个子数组
mergeSort(arr, l, m);
mergeSort(arr, m + 1, r);
// 将已经排好序的子数组合并成为整体有序的数组
merge(arr, l, m, r);
}
}
基数排序-164.最大间距
给定一个无序的数组 `nums`,返回 _数组在排序之后,相邻元素之间最大的差值_ 。如果数组元素个数小于 2,则返回 `0` 。
您必须编写一个在「线性时间」内运行并使用「线性额外空间」的算法。
- 基数排序的时间复杂度为O(d * (n + k)),其中d是最大数字的位数,n是要排序的数字个数,k是桶的大小。因为需要进行d次排序,每次排序需要遍历一遍数组并将数字放到对应的桶中,再遍历一遍桶中数字的位置信息,因此总时间复杂度为O(d * (n + k))。
- 基数排序的空间复杂度也为O(n + k),即需要一个长度为n的原数组和一个长度为k的桶数组来存储数据。因为桶的大小取决于数字的范围,因此它通常比要排序的数字个数小得多,空间复杂度往往被认为是线性的。

// 获取数组中最大值
int getMax(int arr[], int n) {
int max = arr[0];
for (int i = 1; i < n; i++) {
if (arr[i] > max) {
max = arr[i];
}
}
return max;
}
// 基数排序实现
void radixSort(int arr[], int n) {
// 获取要排序数组中最大数字
int max = getMax(arr, n);
// 进行桶排序(按每个位数进行排序)
for (int exp = 1; max / exp > 0; exp *= 10) {
int bucket[10] = { 0 };
// 将数字放到对应的桶中
for (int i = 0; i < n; i++) {
bucket[(arr[i] / exp) % 10]++;
}
// 更新桶中数字的位置信息
for (int i = 1; i < 10; i++) {
bucket[i] += bucket[i - 1];
}
// 将数字按其在桶中的位置放回原数组
int output[n];
for (int i = n - 1; i >= 0; i--) {
output[bucket[(arr[i] / exp) % 10] - 1] = arr[i];
bucket[(arr[i] / exp) % 10]--;
}
// 更新原数组
for (int i = 0; i < n; i++) {
arr[i] = output[i];
}
}
}
计数排序
- 找出待排序的数组中最大和最小的元素,创建数组C
- 统计数组中每个值为i的元素出现的次数,存入数组C的第i项
- 对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)
- 反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1
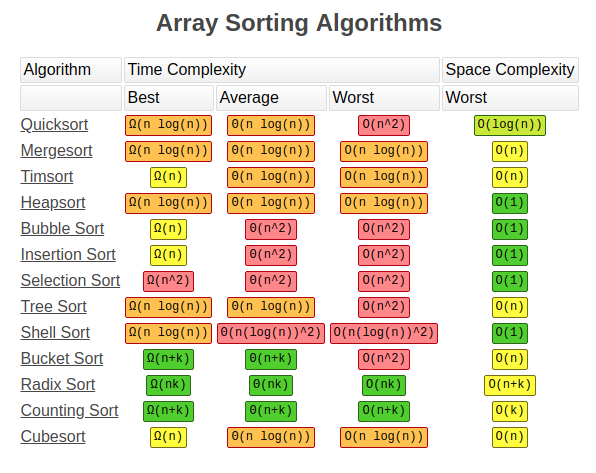
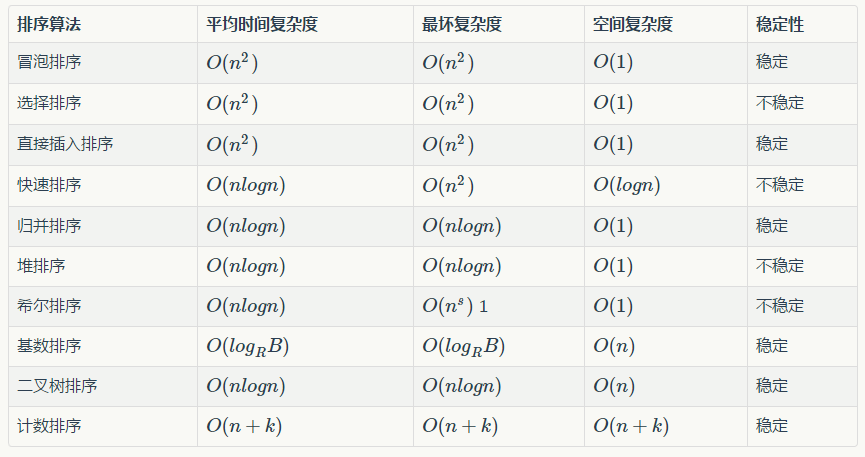
KMP字符串匹配
- 核心是生成next数组,主串指针永远不向后移动,之后自串指针根据数组的对应值进行移动
- 不匹配时候,子串指针根据数组数据移动到对应下标位置
- next数组的生成完全由子串自己决定和控制,和主串无关,生成最长公共前缀方法,思路使用动态规划的思想
- 遍历每一个数字,双指针方法,左边i是已经匹配的指针,右边j是目前的指针
- 当左右不相同时候开始移动,左边指针移动到next[j-1]位置,因为这个位置是公共前缀的下一个位置,循环直到成功
void getNext(int m){
int j = 0;
// 初始化next[0]的值
kmp_next[0] = 0;
for(int i=1; i<m; ++i){
// 当这一位不匹配时,将j指向此位之前最大公共前后缀的位置
while(j>0 && b[i]!=b[j]) j=kmp_next[j-1];
// 如果这一位匹配,那么将j+1,继续判断下一位
if(b[i]==b[j]) ++j;
// 更新next[i]的值
kmp_next[i] = j;
}
}
int kmp(int n,int m){
int i, j = 0;
// 初始化位置p = -1
int p = -1;
// 初始化next数组
getNext(m);
for(i=0; i<n; ++i){
// 当这一位不匹配时,将j指向此位之前最大公共前后缀的位置
while(j>0 && b[j]!=a[i]) j=kmp_next[j-1];
// 如果这一位匹配,那么将j+1,继续判断下一位
if(b[j]==a[i]) ++j;
// 如果是子串(m位完全匹配),则更新位置p的值,并中断程序
if(j==m){
p = i - m + 1;
break;
}
}
// 返回位置p的值
return p;
}

- 时间复杂度为O(m+n)(移动主串指针m加上生成数组的n),空间复杂度为O(n)(子串数组长度)
48. 旋转图像
给定一个 _n_ × _n_ 的二维矩阵 `matrix` 表示一个图像。请你将图像顺时针旋转 90 度。
你必须在 **[原地](https://baike.baidu.com/item/%E5%8E%9F%E5%9C%B0%E7%AE%97%E6%B3%95)** 旋转图像,这意味着你需要直接修改输入的二维矩阵。**请不要** 使用另一个矩阵来旋转图像。
- 找到每个点旋转后位置的规律
581. 最短无序连续子数组
给你一个整数数组 `nums` ,你需要找出一个 **连续子数组** ,如果对这个子数组进行升序排序,那么整个数组都会变为升序排序。
请你找出符合题意的 **最短** 子数组,并输出它的长度。
- 总结:从左往右,找到比左边最大值还小的最右下标,从右往左,找到比右边最小值还大的最左下标
class Solution {
public:
int findUnsortedSubarray(vector<int>& nums) {
int n = nums.size();
int maxn = INT_MIN, right = -1;
int minn = INT_MAX, left = -1;
for (int i = 0; i < n; i++) {
if (maxn > nums[i]) {
right = i;
} else {
maxn = nums[i];
}
if (minn < nums[n - i - 1]) {
left = n - i - 1;
} else {
minn = nums[n - i - 1];
}
}
return right == -1 ? 0 : right - left + 1;
}
};
41. 缺失的第一个正数
给你一个未排序的整数数组 `nums` ,请你找出其中没有出现的最小的正整数。
请你实现时间复杂度为 `O(n)` 并且只使用常数级别额外空间的解决方案。
- 这题目的巧妙之处就在于可以修改原来的数组,使得这个数字是多少就直接放到对应的位置就可以了(当然这部分需要循环放置)
class Solution {
public:
int firstMissingPositive(vector<int>& nums) {
int n = nums.size();
for (int i = 0; i < n; ++i) {
while (nums[i] > 0 && nums[i] <= n && nums[nums[i] - 1] != nums[i]) {
swap(nums[nums[i] - 1], nums[i]);
}
}
for (int i = 0; i < n; ++i) {
if (nums[i] != i + 1) {
return i + 1;
}
}
return n + 1;
}
};
米哈游笔试二题
两个字符串,只能向第一个字符串按顺序插入或者删除m,h,y三个字符,一定是按顺序且插满或者删满三个对应字符,是否最后可以变为第二个字符串
- 两个字符串删除所有mhy之后是否相等就是结果
- 删除mhy的方法是使用双栈(先m栈,到h栈)
142. 环形链表 II
给定一个链表的头节点 `head` ,返回链表开始入环的第一个节点。 _如果链表无环,则返回 `null`。_
如果链表中有某个节点,可以通过连续跟踪 `next` 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 `pos` 来表示链表尾连接到链表中的位置(**索引从 0 开始**)。如果 `pos` 是 `-1`,则在该链表中没有环。**注意:`pos` 不作为参数进行传递**,仅仅是为了标识链表的实际情况。
**不允许修改** 链表。
- 数学问题,龟兔赛跑,快慢指针,指针相遇的位置就是结果的位置
2982. 找出出现至少三次的最长特殊子字符串 II
给你一个仅由小写英文字母组成的字符串 `s` 。
如果一个字符串仅由单一字符组成,那么它被称为 **特殊** 字符串。例如,字符串 `"abc"` 不是特殊字符串,而字符串 `"ddd"`、`"zz"` 和 `"f"` 是特殊字符串。
返回在 `s` 中出现 **至少三次** 的 **最长特殊子字符串** 的长度,如果不存在出现至少三次的特殊子字符串,则返回 `-1` 。
**子字符串** 是字符串中的一个连续 **非空** 字符序列。
- 隐藏的有点深的差分数组,涉及到数组范围批量更改的都直接上差分数组
for (int i = 0; i < s.size(); i++) {
if (i!=0) {
if (s[i]==s[i-1]) {
arr[i]=arr[i-1]+1;
}else {
arr[i]=1;
}
}else {
arr[i]=1;
}
words[s[i]-'a'][1]++;
words[s[i]-'a'][arr[i]+1]--;
}
int result=-1;
for (auto& word : words) {
int now=0;
for (int i = 1; i < word.size(); i++) {
now+=word[i];
if (now>=3) {
result=max(i,result);
}
}
}
995. K 连续位的最小翻转次数
给定一个二进制数组 `nums` 和一个整数 `k` 。
**k位翻转** 就是从 `nums` 中选择一个长度为 `k` 的 **子数组** ,同时把子数组中的每一个 `0` 都改成 `1` ,把子数组中的每一个 `1` 都改成 `0` 。
返回数组中不存在 `0` 所需的最小 **k位翻转** 次数。如果不可能,则返回 `-1` 。
**子数组** 是数组的 **连续** 部分
- 这题是差分数组,不是很好想,实际上就是走到一个0就翻转,然后到最后康康还有没有剩下的,翻转用的是差分数组
class Solution {
public:
int minKBitFlips(vector<int>& nums, int k) {
vector<int> arr(nums.size()+1,0);
int now=0,result=0;
for (int i = 0; i< nums.size(); i++) {
now+=arr[i];
if (i+k>nums.size()) {
if ((nums[i]==0&&now%2==0)||(nums[i]==1&&now%2==1)) {
return -1;
}
continue;
}
if ((nums[i]==0&&now%2==0)||(nums[i]==1&&now%2==1)) {
result++;
now+=1;
arr[i+k]-=1;
}
}
return result;
}
};
质数欧拉筛
- 一种快速找质数的方法,核心方法是使用枚举,将所有质数的倍数都标记为合数,剩下的就是质数
vector<int> arr(right+1,1);
arr[1]=0;
for (long long i = 2; i < right+1; i++) {
if (arr[i]) {
for (long long j = i*i; j < right+1; j+=i) {
arr[j]=0;
}
}
}
牛顿迭代法
- 设函数f(x)在x0处可导,且f(x)在x0处的一阶导数f′(x0)存在,且f′(x0)≠0,则称x0是方程f(x)=0的一个牛顿迭代点,记作x0∈R,且称函数f(x)在x0处的切线方程为
f(x)=f(x0)+f′(x0)(x−x0)
- 若x1是方程f(x)=0的一个牛顿迭代点,且x1满足
x1=x0−f(x0)f′(x0),则称x1 是方程f(x)=0的一个牛顿迭代点,记作x1∈R,且称函数f(x)在x1 处的切线方程为f(x)=f(x1)+f′(x1)(x−x1) - 方程为
xn+1=xn−f(xn)f′(xn) - 底层是通过切线和x交点越来越接近零点的原理
位运算
136. 只出现一次的数字
给你一个 **非空** 整数数组 `nums` ,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
你必须设计并实现线性时间复杂度的算法来解决此问题,且该算法只使用常量额外空间。
- 通过两个相同的数字异或为0,0和任何数字异或原来数字不变
class Solution {
public:
int singleNumber(vector<int>& nums) {
int ret = 0;
for (auto e: nums) ret ^= e;
return ret;
}
};
面试
一共N个数,求最大的n个数
- 将N个数分割分布在每台机器上,使用堆的实现,求出每部分最大的最大n个数字,在进行整合得到最大的n个数
大规模数据去重问题
- 大部分是直接通过bitmap标识,每个数据占据一个bit,通过01判断是否存在
分布式大量数据下载处理
- 使用mapreduce,参考分布式架构 > MapReduce
赛马问题
25匹马,5条赛道,不计时,问至少要赛多少场才能保证找出前三?
- 7次确实是一定可行的,就25匹马5个一组,比5次,淘汰掉10匹,然后这5次的冠军比一次,获得第4第5的两组全部淘汰(淘汰6匹),第3的组里淘汰2匹,第2的组淘汰1匹,第1的那个确定是所有马里最快的。这样总共已经淘汰了10+6+2+1=19匹,还有1匹确定最快,还剩下5匹比一次就够了。
105. 从前序与中序遍历序列构造二叉树
239. 滑动窗口最大值
给你一个整数数组 `nums`,有一个大小为 `k` 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 `k` 个数字。滑动窗口每次只向右移动一位。
返回 _滑动窗口中的最大值_ 。
- 优先队列,堆,不着急删除,拿出来检查是否删除,删除继续拿
297. 二叉树的序列化与反序列化
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
**提示:** 输入输出格式与 LeetCode 目前使用的方式一致,详情请参阅 [LeetCode 序列化二叉树的格式](https://leetcode.cn/faq/#binary-tree)。你并非必须采取这种方式,你也可以采用其他的方法解决这个问题。
- 通过加上NULL,变成完全二叉树再进行遍历就OK
295. 数据流的中位数
**中位数**是有序整数列表中的中间值。如果列表的大小是偶数,则没有中间值,中位数是两个中间值的平均值。
- 例如 `arr = [2,3,4]` 的中位数是 `3` 。
- 例如 `arr = [2,3]` 的中位数是 `(2 + 3) / 2 = 2.5` 。
实现 MedianFinder 类:
- `MedianFinder()` 初始化 `MedianFinder` 对象。
- `void addNum(int num)` 将数据流中的整数 `num` 添加到数据结构中。
- `double findMedian()` 返回到目前为止所有元素的中位数。与实际答案相差 `10-5` 以内的答案将被接受。
- 思路非常惊奇,使用两个优先队列,每次加数字判断放到哪一边的优先队列,然后查询直接从头部查询就ok
class MedianFinder {
public:
priority_queue<int, vector<int>, less<int>> queMin;
priority_queue<int, vector<int>, greater<int>> queMax;
MedianFinder() {}
void addNum(int num) {
if (queMin.empty() || num <= queMin.top()) {
queMin.push(num);
if (queMax.size() + 1 < queMin.size()) {
queMax.push(queMin.top());
queMin.pop();
}
} else {
queMax.push(num);
if (queMax.size() > queMin.size()) {
queMin.push(queMax.top());
queMax.pop();
}
}
}
double findMedian() {
if (queMin.size() > queMax.size()) {
return queMin.top();
}
return (queMin.top() + queMax.top()) / 2.0;
}
};
哈夫曼编码
[!tip] 参考 https://zhuanlan.zhihu.com/p/144562146
- 本质是根据每个char出现的频率不同进行的优化压缩编码
- 如e的频率最高,z频率低,但是都是占用一个char大小,就会非常浪费
- 如果把e用0一个位表示,z用1111111标识,大小就会压缩
- 必须满足只用两个符号(即0和1)和前缀不重复这两个特征

生成过程
- 统计文本中字符出现的次数
- 将字符按照频数升序排序
- 将频数最小的两个叶子结点结合成树,看作一个整体,整体的频数是叶子结点频数和
- 把这个树看作整体和其他的一起也进行升序排序
- 重复上述过程知道生成整棵树
// 哈夫曼树节点定义
struct HuffmanNode {
char c;
int freq;
HuffmanNode* left;
HuffmanNode* right;
HuffmanNode(char cc = '\0', int f = 0, HuffmanNode* l = nullptr, HuffmanNode* r = nullptr) :
c(cc), freq(f), left(l), right(r) {}
};
// 哈夫曼树构建函数
HuffmanNode* buildHuffmanTree(unordered_map<char, int>& freqMap) {
auto cmp = [](HuffmanNode* a, HuffmanNode* b) {
return a->freq > b->freq;
};
priority_queue<HuffmanNode*, vector<HuffmanNode*>, decltype(cmp)> q(cmp); // 小根堆
for (auto& p : freqMap) {
q.push(new HuffmanNode(p.first, p.second));
}
while (q.size() > 1) {
auto leftNode = q.top(); q.pop();
auto rightNode = q.top(); q.pop();
auto parent = new HuffmanNode('\0', leftNode->freq + rightNode->freq, leftNode, rightNode);
q.push(parent);
}
return q.top();
}
// 递归构建 Huffman 编码表
void buildHuffmanCodeTable(HuffmanNode* node, string code, unordered_map<char, string>& codeTable) {
if (!node) return;
if (node->c != '\0') {
codeTable[node->c] = code;
}
buildHuffmanCodeTable(node->left, code + '0', codeTable);
buildHuffmanCodeTable(node->right, code + '1', codeTable);
}
Morris遍历
- Morris一种遍历二叉树的方式,并且时间复杂度为O(N),额外空间复杂度O(1)
- 实质就是利用叶节点具有大量空指针,通过这些空指针连成原本需要的栈达到目的
- 如果遍历要求不能改变树的结构,那么不能用这个Morris遍历
void morrisPreorder(TreeNode* root) {
TreeNode *cur = root, *pre = NULL;
while (cur != NULL) {
if (cur->left == NULL) {
cout << cur->val << " ";
cur = cur->right;
} else {
pre = cur->left;
while (pre->right != NULL && pre->right != cur)
pre = pre->right;
if (pre->right == NULL) {
cout << cur->val << " ";
pre->right = cur;
cur = cur->left;
} else {
pre->right = NULL;
cur = cur->right;
}
}
}
}
502. IPO
假设 力扣(LeetCode)即将开始 **IPO** 。为了以更高的价格将股票卖给风险投资公司,力扣 希望在 IPO 之前开展一些项目以增加其资本。 由于资源有限,它只能在 IPO 之前完成最多 `k` 个不同的项目。帮助 力扣 设计完成最多 `k` 个不同项目后得到最大总资本的方式。
给你 `n` 个项目。对于每个项目 `i` ,它都有一个纯利润 `profits[i]` ,和启动该项目需要的最小资本 `capital[i]` 。
最初,你的资本为 `w` 。当你完成一个项目时,你将获得纯利润,且利润将被添加到你的总资本中。
总而言之,从给定项目中选择 **最多** `k` 个不同项目的列表,以 **最大化最终资本** ,并输出最终可获得的最多资本。
答案保证在 32 位有符号整数范围内。
- 著名的银行家算法(用于避免死锁)
- 利用堆的贪心算法
- 项目按照所需资本的从小到大进行排序,每次进行选择时,假设当前手中持有的资本为 w,我们应该从所有投入资本小于等于 w 的项目中选择利润最大的项目 j,然后此时我们更新手中持有的资本为
w+profits[j],同时再从所有花费资本小于等于 w+profits[j]的项目中选择,我们按照上述规则不断选择 k 次即可 - 利用大根堆的特性,我们将所有能够投资的项目的利润全部压入到堆中,每次从堆中取出最大值,然后更新手中持有的资本,同时将待选的项目利润进入堆,不断重复上述操作。
- 项目按照所需资本的从小到大进行排序,每次进行选择时,假设当前手中持有的资本为 w,我们应该从所有投入资本小于等于 w 的项目中选择利润最大的项目 j,然后此时我们更新手中持有的资本为
typedef pair<int,int> pii;
class Solution {
public:
int findMaximizedCapital(int k, int w, vector<int>& profits, vector<int>& capital) {
int n = profits.size();
int curr = 0;
priority_queue<int, vector<int>, less<int>> pq;
vector<pii> arr;
for (int i = 0; i < n; ++i) {
arr.push_back({capital[i], profits[i]});
}
sort(arr.begin(), arr.end());
for (int i = 0; i < k; ++i) {
while (curr < n && arr[curr].first <= w) {
pq.push(arr[curr].second);
curr++;
}
if (!pq.empty()) {
w += pq.top();
pq.pop();
} else {
break;
}
}
return w;
}
};
632. 最小区间
你有 `k` 个 **非递减排列** 的整数列表。找到一个 **最小** 区间,使得 `k` 个列表中的每个列表至少有一个数包含在其中。
我们定义如果 `b-a < d-c` 或者在 `b-a == d-c` 时 `a < c`,则区间 `[a,b]` 比 `[c,d]` 小。
- 每个数组维护一个指针,标识现在是哪一个位置.通过堆维护所有指针中数据最小的
class Solution {
public:
vector<int> smallestRange(vector<vector<int>>& nums) {
vector<int> points(nums.size(),0);
pair<int, int> result={-1,-1},minNow=result;
auto cmp = [](pair<int, int>& a, pair<int, int>& b) {
return a.first > b.first;
};
priority_queue<pair<int, int>, vector<pair<int, int>>, decltype(cmp)> que(cmp);
for (int i = 0; i < nums.size(); i++) {
que.push({nums[i][points[i]],i});
minNow.second=max(minNow.second,nums[i][points[i]]);
}
while (!que.empty()) {
auto now=que.top();
que.pop();
minNow.first=now.first;
if (result.first==-1||minNow.second-minNow.first<result.second-result.first) {
result=minNow;
}
points[now.second]++;
auto pos=points[now.second];
if (pos==nums[now.second].size()) {
break;
}
minNow.second=max(minNow.second,nums[now.second][pos]);
que.push({nums[now.second][pos],now.second});
}
return vector<int>()={result.first,result.second};
}
}
树状数组
- 是线段树的一种
- 非常单纯,就是用来求
单点修改,区间查询的情况的 - #算法技巧
- 当出现区间修改,单点查询的时候,使用的是差分数组
- 不修改,只区间查询使用前缀和
- 只有单点修改,区间查询时候才使用树状数组
作用
- 可以用于求区间和,最简单的做法
- 用于于求逆序对
- 将数组离散化,即建立连续的对应关系,算出多少个不同的数字为n,将原来数组的元素一一映射到1-n
- 遍历数组,遇到数字求比他小的数组和(详细步骤可见1694题)
class Bit{//树状数组,作用是`单点改变,区间区和`
public:
Bit(int size){//设置bit数组长度,index需要小于这个
tree.resize(size+1,0);
}
private:
vector<int> tree;
int lowBit(int x) {
return x & (-x);
}
public:
void add(int index, int val) {//将某个index的val加上给定值
index+=1;
while (index < (int)tree.size()) {
tree[index] += val;
index += lowBit(index);
}
}
int prefixSum(int index) {//将数组的下标为0-index的数字求和,**包括自己**
index+=1;
int sum = 0;
while (index > 0) {
sum += tree[index];
index -= lowBit(index);
}
return sum;
}
};
找到数组中第一个比某个元素大的元素使用单调栈,统计比某个元素大的元素有多少个使用树状数组
完全二叉树的扁平化
- 完全二叉树除了最下面那一层,其他层都是满的,二叉堆都是完全二叉树
- 参考

2179. 统计数组中好三元组数目
给你两个下标从 **0** 开始且长度为 `n` 的整数数组 `nums1` 和 `nums2` ,两者都是 `[0, 1, ..., n - 1]` 的 **排列** 。
**好三元组** 指的是 `3` 个 **互不相同** 的值,且它们在数组 `nums1` 和 `nums2` 中出现顺序保持一致。换句话说,如果我们将 `pos1v` 记为值 `v` 在 `nums1` 中出现的位置,`pos2v` 为值 `v` 在 `nums2` 中的位置,那么一个好三元组定义为 `0 <= x, y, z <= n - 1` ,且 `pos1x < pos1y < pos1z` 和 `pos2x < pos2y < pos2z` 都成立的 `(x, y, z)` 。
请你返回好三元组的 **总数目** 。
- 典型的树状数组,惊艳的是三元组,使用中间的数为分界线,而不是左右两边,遇到3个的题可以参考
long long goodTriplets(vector<int>& nums1, vector<int>& nums2){
long long result=0;
unordered_map<int,int> hashmap;
int len=nums1.size();
for(unsigned i=0;i<nums2.size();i++)
hashmap.insert(pair<int,int>{nums2[i],i});
for(unsigned i=0;i<nums1.size();i++)
nums1[i]=hashmap[nums1[i]];
Bit pre(len),after(len);
vector<int> arrleft(len,0),arrright(len,0);
for (int i = 0; i < len; i++) {
arrleft[i]=pre.prefixSum(nums1[i]);
pre.add(nums1[i], 1);
}
for (int i = len-1; i>=0; i--) {
arrright[i]=after.prefixSum(len-1)-after.prefixSum(nums1[i]);
after.add(nums1[i], 1);
}
for (int i = 0; i < len; i++) {
result+=arrleft[i]*(long long)arrright[i];
}
return result;
}
金山wps笔试第二题
大概是两只队伍挑人,一个数组,依次选目前分数最高的人,和左右的各m个人,输出整个队伍最后的情况
数量级是10^5
- 首先使用构建堆,每次从堆那人出来,维护unorderset,记录是否有队伍,同时维护一个双向链表(vector pair)维护每个人的上一个和下一个人,每次动态更新,挺复杂的,用到了挺多数据结构的
各种树
满二叉树
- 只有最后一层的节点没有子节点,其他都是满的
二叉搜索树

- 左边比父节点小,右边比父节大,高度无限制
AVL树(平衡二叉树)
- 左右子树高度差不超过1,其他满足二叉搜索树的特点
红黑树

- 每个节点非红即黑.
- 根节点是黑的。
- 每个叶节点(叶节点即树尾端NUL指针或NULL节点)都是黑的.
- 如果一个节点是红的,那么它的两儿子都是黑的.
- 对于任意节点而言,其到叶子点树NIL指针的每条路径都包含相同数目的黑节点.
B-tree
没有B-树,只有B树
- 关键字集合分布在整颗树中;
- 任何一个关键字出现且只出现在一个结点中;
- 搜索有可能在非叶子结点结束(节点中存储真实数据);
- 其搜索性能等价于在关键字全集内做一次二分查找;
- 自动层次控制;
B+tree
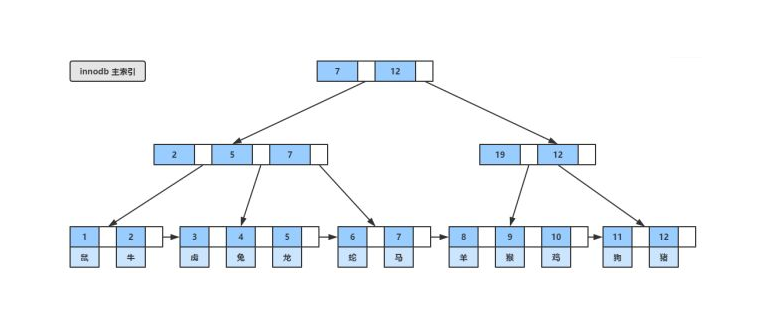
- 所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的
- 不可能在非叶子结点命中
- 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层
- 更适合文件索引系统
trie tree(前缀树)
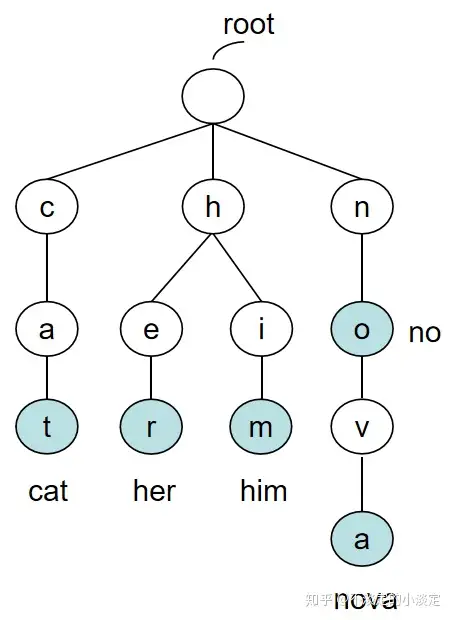
- 又称为前缀树,常用于根据前缀快速搜索匹配(比如ip域的匹配)
radix tree
[!tip] 参考 https://www.zhihu.com/question/41961814/answer/2685709494 https://zhuanlan.zhihu.com/p/644667990
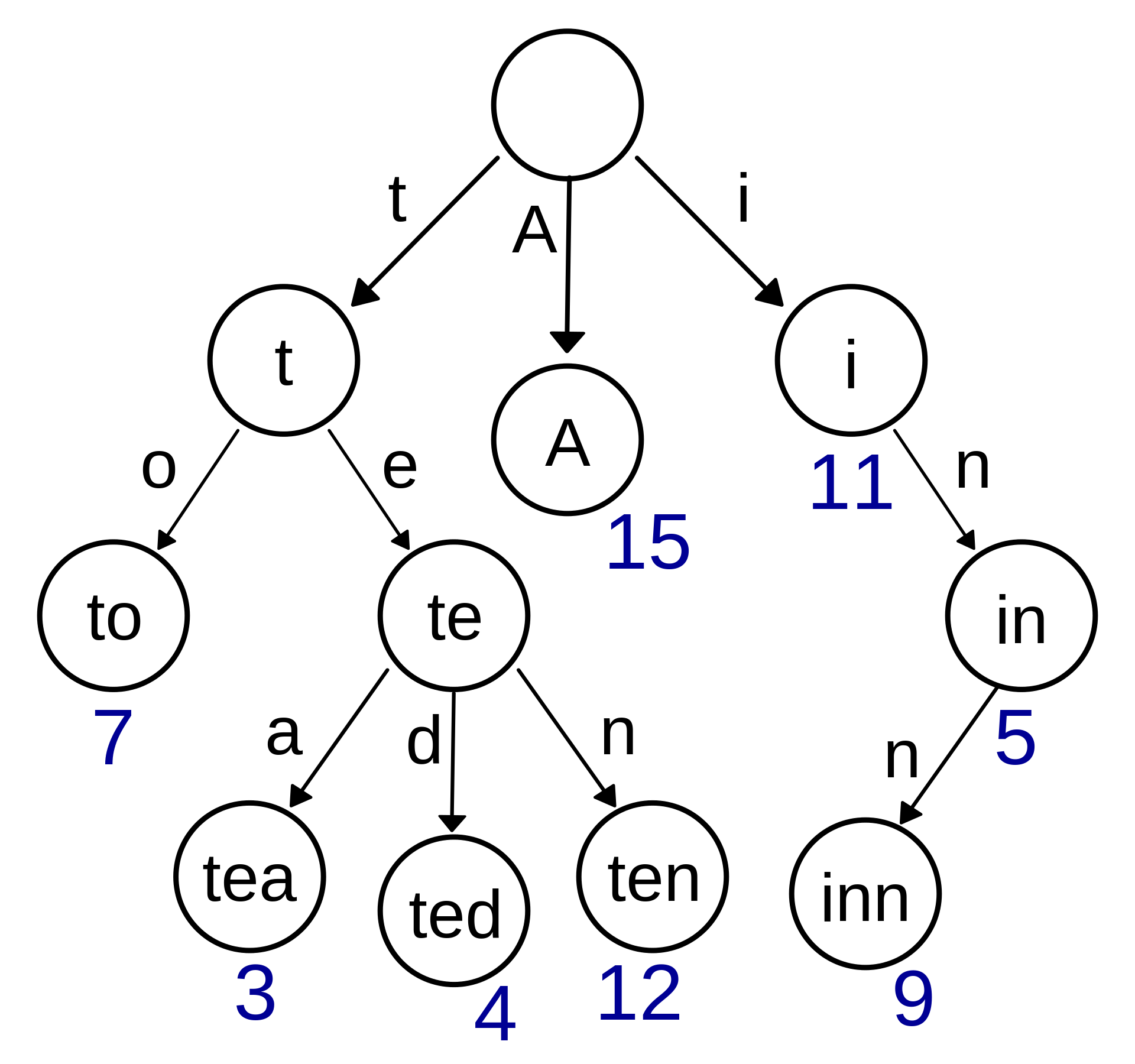
- 实际上就是一个节点的key不是单一的一个字符,可能存在多个字符的情况
- 实际上就是一种特殊的前缀树(Trie tree)
结构体
typedef struct raxNode {
uint32_t iskey:1; //节点是否包含key
uint32_t isnull:1; //节点的值是否为NULL
uint32_t iscompr:1; //节点是否被压缩
uint32_t size:29; //节点大小
unsigned char data[]; //节点的实际存储数据
} raxNode;
- #TODO 这部分后面根据参考补全一下
kdtree
[!tip] 参考 https://www.joinquant.com/view/community/detail/c2c41c79657cebf8cd871b44ce4f5d97
结构
struct kdtree{
Node-data // 数据矢量 数据集中某个数据点,是n维矢量(这里也就是k维)
Range // 空间矢量 该节点所代表的空间范围
split // 整数 垂直于分割超平面的方向轴序号
Left // kd树 由位于该节点分割超平面左子空间内所有数据点所构成的k-d树
Right // kd树 由位于该节点分割超平面右子空间内所有数据点所构成的k-d树
parent // kd树 父节点
}
- 实际上有点类似Mysql底层原理 > 联合索引,首先选取第一个坐标(这个点中位数最好,不是的话左右两边点数量会有影响),将所有数据大于这个的放在左边,小于这个的放置在右边,建立类似二叉树
- 然后选择第二个坐标,如法炮制,直到所有坐标都放进去
查找过程
- 设 L 为一个有 k 个空位的列表,用于保存已搜寻到的最近点
- 根据 p 的坐标值和每个节点的切分向下搜索,根据第一个属性比较
- 当达到一个底部节点(这里是必须是最底下的节点)时,将其标记为访问过。如果 L 里不足 k 个点,则将当前节点的特征坐标加入 L ;如果 L 不为空并且当前节点的特征与 p 的距离小于 L 里最长的距离,则用当前特征替换掉 L 中离 p 最远的点
- 如果当前节点是整棵树最顶端节点,算法完成,如果不是
- 向上爬一个节点。如果当前(向上爬之后的)节点未曾被访问过,将其标记为被访问过,然后执行 下面的1和2;如果当前节点被访问过,再次向上爬
- 如果此时 L 里不足 k 个点,则将节点特征加入 L;如L 中已满 k个点,且当前节点与 p 的距离小于 L 里最长的距离,则用节点特征替换掉 L 中离最远的点
- 计算 p 和当前节点切分线的距离。如果该距离大于等于 L 中距离 p 最远的距离并且 L 中已有 k 个点,则在切分线另一边不会有更近的点,执行(三);如果该距离小于 L 中最远的距离或者 L 中不足 k个点,则切分线另一边可能有更近的点,因此在当前节点的另一个枝从(1)开始执行.这一步是核心:如果比中线分割线的距离都比目前所有的远就不用找另外一边了,==注意不是中间的点,是中间的分割线,这才是最短距离==
- 向上爬一个节点。如果当前(向上爬之后的)节点未曾被访问过,将其标记为被访问过,然后执行 下面的1和2;如果当前节点被访问过,再次向上爬
- 滑动窗口的核心在于
- 不能回头,互动窗口只能向前滑动
- 题目一般要求是连续的,类似子串,不能是子序列
3. 无重复字符的最长子串
给定一个字符串 `s` ,请你找出其中不含有重复字符的 **最长子串** 的长度。
- 类dp方法,属于滑动窗口
class Solution {
public:
int lengthOfLongestSubstring(string s) {
unordered_map<int, int> hashMap;
int result=0,now=-1;
for (int i = 0; i < s.size(); i++) {
if (hashMap.find(s[i])!=hashMap.end()) {
now=max(now,hashMap[s[i]]);
}
hashMap[s[i]]=i;
result=max(i-now,result);
}
return result;
}
};
76. 最小覆盖子串
给你一个字符串 `s` 、一个字符串 `t` 。返回 `s` 中涵盖 `t` 所有字符的最小子串。如果 `s` 中不存在涵盖 `t` 所有字符的子串,则返回空字符串 `""` 。
**注意:**
- 对于 `t` 中重复字符,我们寻找的子字符串中该字符数量必须不少于 `t` 中该字符数量。
- 如果 `s` 中存在这样的子串,我们保证它是唯一的答案。
- 滑动窗口经典
438. 找到字符串中所有字母异位词
给定两个字符串 `s` 和 `p`,找到 `s` 中所有 `p` 的 **异位词** 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
**异位词** 指由相同字母重排列形成的字符串(包括相同的字符串)。
- 滑动窗口,每次遍历26个字母
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
int sLen = s.size(), pLen = p.size();
if (sLen < pLen) {
return vector<int>();
}
vector<int> ans;
vector<int> sCount(26);
vector<int> pCount(26);
for (int i = 0; i < pLen; ++i) {
++sCount[s[i] - 'a'];
++pCount[p[i] - 'a'];
}
if (sCount == pCount) {
ans.emplace_back(0);
}
for (int i = 0; i < sLen - pLen; ++i) {
--sCount[s[i] - 'a'];
++sCount[s[i + pLen] - 'a'];
if (sCount == pCount) {
ans.emplace_back(i + 1);
}
}
return ans;
}
};
713. 乘积小于 K 的子数组
给你一个整数数组 `nums` 和一个整数 `k` ,请你返回子数组内所有元素的乘积严格小于 `k` 的连续子数组的数目。
- 一个简单的思路是二分搜索O(nlog(n))
- 滑动窗口O(n)
class Solution {
public:
int numSubarrayProductLessThanK(vector<int>& nums, int k) {
int n = nums.size(), ret = 0;
int prod = 1, i = 0;
for (int j = 0; j < n; j++) {
prod *= nums[j];
while (i <= j && prod >= k) {
prod /= nums[i];
i++;
}
ret += j - i + 1;
}
return ret;
}
};
438. 找到字符串中所有字母异位词
给定两个字符串 `s` 和 `p`,找到 `s` 中所有 `p` 的 **异位词** 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
**异位词** 指由相同字母重排列形成的字符串(包括相同的字符串)。
- 构造长度为len(p)的滑动窗口,遍历时候循环检查一下26个字母是否每个都匹配
30. 串联所有单词的子串
定一个字符串 `s` 和一个字符串数组 `words`**。** `words` 中所有字符串 **长度相同**。
`s` 中的 **串联子串** 是指一个包含 `words` 中所有字符串以任意顺序排列连接起来的子串。
- 例如,如果 `words = ["ab","cd","ef"]`, 那么 `"abcdef"`, `"abefcd"`,`"cdabef"`, `"cdefab"`,`"efabcd"`, 和 `"efcdab"` 都是串联子串。 `"acdbef"` 不是串联子串,因为他不是任何 `words` 排列的连接。
返回所有串联字串在 `s` 中的开始索引。你可以以 **任意顺序** 返回答案。
- 核心就是滑动窗口,惊艳的点在于使用unordered_map作为统计数量,如果向右滑动就key的val++.左边的key的val--,如果key的val为0就erase,最后如果map为empty说明位置是ok的记录下来
招联笔试第二题:和最接近k的子数组
- 如果是和为k,直接前缀和+hash带走,但是这个是最接近,比较有意思
- 最接近分为联合,分别为正向最接近和反向最接近,分辨使用滑动窗口,维护左边能选到的边界
int left=-1;
long long likely=INT32_MAX;
for (int i = 0; i < len; i++) {
now+=arr[i];
if (now<sum) {
continue;
}
while (left<=i&&now-arr[left+1]>=sum) {// 移动左边界保证大于等于目标值的最右边
left++;
now-=arr[left];
}
if (abs(sum-now)<likely) {
likely=abs(sum-now);
}
}
left=-1;
now=0;
for (int i = 0; i < len; i++) {
now+=arr[i];
while (left<=i&&now>sum) {// 移动左边界,保证小于等于的最小左边界
left++;
now-=arr[left];
}
if (abs(sum-now)<likely) {
likely=abs(sum-now);
}
}
1423. 可获得的最大点数
几张卡牌 **排成一行**,每张卡牌都有一个对应的点数。点数由整数数组 `cardPoints` 给出。
每次行动,你可以从行的开头或者末尾拿一张卡牌,最终你必须正好拿 `k` 张卡牌。
你的点数就是你拿到手中的所有卡牌的点数之和。
给你一个整数数组 `cardPoints` 和整数 `k`,请你返回可以获得的最大点数。
- 挺有意思的题目,难点在于将左右两边转换为中间的滑动窗口
前缀hash和滑动窗口题目的不同特点
- 滑动窗口通常要求连续
- 前缀hash通常只是要求是某个序列
- 滑动窗口不支持向前滑动,只能向后,出现就不能使用滑动窗口
22. 括号生成
数字 `n` 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 **有效的** 括号组合。
**输入:**n = 3
**输出:**["((()))","(()())","(())()","()(())","()()()"]
- 遇到类似生成所有情况的,一般都是直接使用递归(栈和DFS类似)
- 遇到括号匹配的,一般都是用栈
class Solution {
public:
vector<string> generateParenthesis(int n) {
dfs("", n, n);
return res;
}
private:
vector<string> res;
void dfs(const string& str, int left, int right) {
if (left < 0 || left > right) // 出现类似 ()) )) 这种格式都是错误的不用再继续了
return;
if (left == 0 && right == 0) {
res.push_back(str);
return;
}
dfs(str + '(', left - 1, right);
dfs(str + ')', left, right - 1);
}
};
46. 全排列
给定一个不含重复数字的数组 `nums` ,返回其 _所有可能的全排列_ 。你可以 **按任意顺序** 返回答案。
- 暴力递归不解释
class Solution {
public:
vector<vector<int>> permute(vector<int>& nums) {
vector<vector<int>> result;
vector<int> now;
travelArray(result,now,nums);
return result;
}
void travelArray(vector<vector<int>>& result,vector<int>& now,vector<int>& left)
{
int flag=1000;
for(unsigned i=0;i<left.size();i++)
{
if(left[i]!=100)
{
flag=left[i];
now.push_back(left[i]);
left[i]=100;
travelArray(result,now,left);
left[i]=flag;
now.erase(now.end()-1);
}
}
if(flag==1000)
result.push_back(now);
}
};
236. 二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
[百度百科](https://baike.baidu.com/item/%E6%9C%80%E8%BF%91%E5%85%AC%E5%85%B1%E7%A5%96%E5%85%88/8918834?fr=aladdin)中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(**一个节点也可以是它自己的祖先**)。”
- 递归,找到第一个两个节点都为true的节点
1326. 灌溉花园的最少水龙头数目
在 x 轴上有一个一维的花园。花园长度为 `n`,从点 `0` 开始,到点 `n` 结束。
花园里总共有 `n + 1` 个水龙头,分别位于 `[0, 1, ..., n]` 。
给你一个整数 `n` 和一个长度为 `n + 1` 的整数数组 `ranges` ,其中 `ranges[i]` (下标从 0 开始)表示:如果打开点 `i` 处的水龙头,可以灌溉的区域为 `[i - ranges[i], i + ranges[i]]` 。
请你返回可以灌溉整个花园的 **最少水龙头数目** 。如果花园始终存在无法灌溉到的地方,请你返回 **-1** 。
- 贪心:同一个x,选择最远的y,在这个比y小的所有x1,选取最远的y1,迭代进行
- 动态规划:从前向后
class Solution {
public:
int minTaps(int n, vector<int>& ranges) {
int mindiff=0;
unordered_map<int, int> hashmap;
for (int i=0;i<ranges.size();i++) {
mindiff=min(i-ranges[i],mindiff);
if (hashmap.find(i-ranges[i])!=hashmap.end()) {
hashmap[i-ranges[i]]=max(hashmap[i-ranges[i]],2*ranges[i]);
}else {
hashmap[i-ranges[i]]=2*ranges[i];
}
}
mindiff=-mindiff;
vector<int> dp(ranges.size()+mindiff,INT32_MAX);
for (int i = 0; i < mindiff; i++) {
dp[i]=0;
}
for (int i = 0; i < dp.size(); i++) {
auto self=dp[i];
if (self==INT32_MAX) {
return -1;
}
int val=0;
if (hashmap.find(i-mindiff)!=hashmap.end()) {
val=hashmap[i-mindiff];
}
for (int j = 1; j <= val&&i+j<dp.size(); j++) {
dp[i+j]=min(dp[i+j],self+1);
}
}
return dp[dp.size()-1];
}
}
小于n的最大数字
给一个数n,一个数组A,返回由A中元素组成的小于n的最大数
如n=23121,A={2,4,9| 返回22999
n=23121 A={9} 返回9999
n=23333 A={2,3} 返回23332
n=2222 A={2} 返回222
n=2 A={2} 无解
- 使用贪心加dfs的方法,实际上因为数据量太小,每个位置都尽可能选择最大的一个数字,最后弄不了就回到上一层选择上一层小一点的数字
前提
- 至少一半的机器运行正常
- 广播时间需要<<选举超时时间<<平均故障时间
- 非拜占庭情况下
状态机复制
- 底层是状态机的复制,同一个系统,相同的输入之后得到的状态是相同的
状态转换
- 所有的机器只会是leader(领导者),candidate(候选人),follower(跟随者)
- Raft算法将时间分为一个个的任期(term),每一个term的开始都是Leader选举。在成功选举Leader之后,Leader会在整个term内管理整个集群。如果Leader选举失败,该term就会因为没有Leader而结束。
- 只存在两种RPC
- RequestVote RPC : candidate发起,请求投票
- AppendEntries RPC : leader复制日志和心跳保活
- 通讯会交换任期号,如果是follwer发现自己的任期比较小,那么会切换到大的任期号,如果是其他两种发现,会切换为follower
- 节点忽略过期任期号的请求(比如刚复活的进行选举,会选举失败)
领导者选举
- 心跳机制,leader向follower发送心跳包(携带任期号),超过最大时间follower发现没收到心跳之后
- 增大自己的任期号
- 切换为candidate状态,投票给自己,发送RequestVote给其他机器
- 结果三种可能
- 超过半数选票成为leader
- 其他赢了,标志为收到其他leader的心跳包,新leader任期不小于自己的任期号
- 没人获胜,重新选举
- 为了公平和防止进入死循环,选举超时时间会进行随机化(从发现leader没发心跳包,到成为candidate发送rpc的时间随机化)
RequestVote RPC内容
被候选者用来收集选票:
Arguments:
term 候选者的任期
candidateId 候选者编号
lastLogIndex 候选者最后一条日志记录的索引
lastLogItem 候选者最后一条日志记录的索引的任期
Results:
term 当前任期,候选者用来更新自己
voteGranted 如果自己将票投给候选人则为 true。
接受者的实现:
1. 如果 leader 的任期小于自己的任期返回 false。(5.1)
2. 如果本地 voteFor 为空,候选者
日志复制
- 只有leader具有写的权限(即向日志中附加条目),follower的写请求都会重定向到leader
AppendEntries RPC 内容
被 leader 用来复制日志,同时也被用作心跳
Arguments:
term leader 任期
leaderId 用来 follower 重定向到 leader
prevLogIndex 前继日志记录的索引
prevLogItem 前继日志的任期
entries[] 存储日志记录
leaderCommit leader 的 commitIndex
Results:
term 当前任期,leader 用来更新自己
success 如果 follower 包含索引为 prevLogIndex 和任期为
prevLogItem 的日志
接受者的实现:
1. 如果 leader 的任期小于自己的任期返回 false。(5.1)
2. 如果自己不存在索引、任期和 prevLogIndex、prevLogItem
匹配的日志返回 false。(5.3)
3. 如果存在一条日志索引和 prevLogIndex 相等,
但是任期和 prevLogItem 不相同的日志,
需要删除这条日志及所有后继日志。(5.3)
4. 如果 leader 复制的日志本地没有,则直接追加存储。
5. 如果 leaderCommit>commitIndex,
设置本地 commitIndex 为 leaderCommit 和最新日志索引中
较小的一个。
- 只有日志号和任期号才能唯一确定一个日志
日志有两种状态,生成和提交,提交之后不可撤回,只有半数以上节点ack,日志才会变为提交,只有leader同意,follower才能提交,没有生成的日志有可能被替代
- 具体流程
- leader接受到写请求,将日志通过rpc复制到所有的follower中
- 等待超过半数的follower复制成功并且返回ack(就是下一个心跳包)之后,leader会提交日志到版本库,并且返回应用层成功的消息
- leader告诉所有的follower让他们提交
- follower提交
follower宕机
- 如果follower没有响应,leader会不断进行重发到该follower尝试
- follower回复之后会进行一致性检查恢复缺失的日志
当发送一个 AppendEntries RPC 时,Leader会把新日志条目紧接着之前的条目的log index和term都包含在里面。如果Follower没有在它的日志中找到log index和term都相同的日志,它就会拒绝新的日志条目。
leader宕机
- 如果宕机的leader还有日志未提交,那么可能出现其他leader强制性覆盖旧leader未提交的数据
安全性
投票
- 如果投票者手上的日志信息比candidate还新,就会拒绝该请求
相同任期比日志号,不同任期比任期号,日志号不是提交了的日志号,而是存在的日志号码(没有提交的也算)
日志
- leader只会对自己的任期内的日志计算副本数目的提交,上一个任期内的日志不会被马上提交,只有自己产生了新日志才会进行统一提交
成员变更
联合一致
- 采用两阶段的方法避免脑裂问题
- leader发起rpc请求,使整个集群进入联合一致的状态,此时rpc在新旧两个配置都要达到大多数才算成功
- leader发起rpc,整个集群进入新配置状态,能达到大多数就算成功,在新增节点时,需要等待新增的节点完成日志同步才开始成员变更
- 复杂,使用较少
单节点变更
- 完成增加节点的日志同步
- leader发送rpc请求,等待大多数之后就可以提交标识成功
数据读写
- 写请求统一发送到leader
- 读请求到了 follower 后,follower会去向 leader 请求 readindex(也就是当时 leader 的 commitindex), leader 在确认自己还是 leader 之后,就会吧 readindex 发给 follower,follower 会对比自己的 commitindex 和 readindex,只有commitindex 大于等于 readindex 之后,才能读取数据返回.
ETCD
- etcd 就是底层使用raft实现的一个kv类型的数据库,可以保证强一致性,属于CP类型的数据库
参考
- https://raft.github.io/
- https://zhuanlan.zhihu.com/p/32052223
跳表
- 就是一个二维链表,从有序链表构建
- 最上层开始查,下一个比他小就向右,否则向下
- 插入数据后random,50%的概率向上插入,递归向上遍历
优缺点
- 实现简单,比平衡树简单多了
- 比B树占用内存更少
- 缓存局部性
确定层数
- level=log2(n) - 1,每一层是下一层的一半
洗牌算法
步骤
- 将数组分为以弄混和为弄混两部分
- 随机从未弄混(包含自己)拿出一个和未弄混的最后一个位置进行调换
- 标记最后一个为已弄混
- 重复步骤
Top K算法
步骤
- 底层是快排,时间复杂度是O(n)
- 使用快排方法,拿到pos,判断pos和k关系
- 在len比k大的区间进行递归,直到找到pos正好为k时候
如果使用堆的方法,插入n个元素的时间复杂度为O(n log n),取出前K个元素的时间复杂度为O(K log n),因此,总的时间复杂度为O(n log n + K log n),即O((n + K) log n) 快速选择算法实现取出最大K个元素的时间复杂度为O(n),其中n为优先队列中的元素个数。快速选择算法的时间复杂度与快速排序类似,平均情况下为O(n),最坏情况下为O(n^2)
P和NP问题
P类问题
- 多项式时间(Polynomial time)
- 能用经典计算机轻易解决的所有问题
- P类中的算法必须在n^c的时间内停止并给出正确答案,其中n是输入的规模,c是常数
如某个数是否为质数
NP类问题
- 不确定多项式时间 (Non-deterministic Polynomial time)
- 能用经典计算机快速验证答案的所有问题
- 如果给出某问题一个答案,存在对答案正确性的简短的证明,那么该问题就是一个NP问题
有没有一个公式能推出下一个质数是多少呢?这种问题的答案,是无法直接计算得到的,只能通过间接的“猜算”来得到结果。这也就是非确定性问题。而这些问题的通常有个算法,它不能直接告诉你答案是什么,但可以告诉你,某个可能的结果是正确的答案还是错误的。这个可以告诉你“猜算”的答案正确与否的算法,假如可以在多项式(polynomial)时间内算出来,就叫做多项式非确定性问题。 生成问题的一个解通常比验证一个给定的解时间花费要多得多,如果某人告诉你,数13,717,421可以写成两个较小的数的乘积,你可能不知道是否应该相信他,但是如果他告诉你他可以因式分解为3607乘上3803,那么你就可以用一个袖珍计算器容易验证这是对的
P=NP?
- P 问题和 NP 问题是否等价。如果 P = NP 就意味着任何能够在多项式的复杂度验证的问题也能够在多项式的复杂度解决它
- 如果p=np,RSA加密将会在多项式时间内攻破,意味着加密算法是不安全的,O(x^k),k为一个常数(目前最先进也是指数级).同时意味着所有问题都可以用计算机解决了
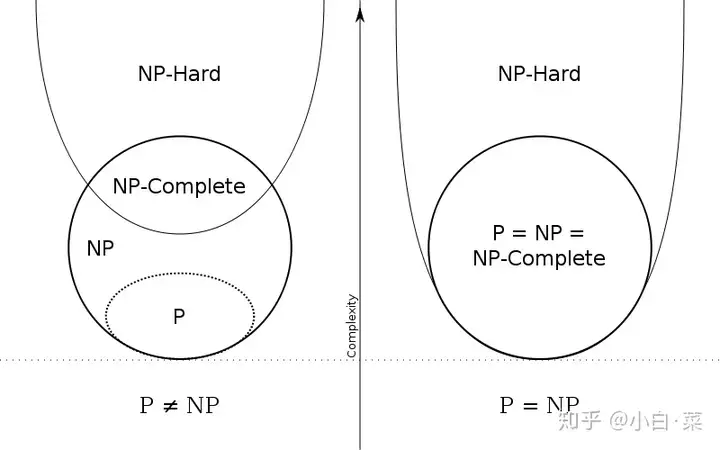
线段树

- 通过一个数组管辖的区域不同,每个数组元素代表一个区域的和
参考
- https://zhuanlan.zhihu.com/p/144002143
- https://zhuanlan.zhihu.com/p/141884913
- https://baike.baidu.com/item/NP%E5%AE%8C%E5%85%A8%E9%97%AE%E9%A2%98/4934286
- https://zhuanlan.zhihu.com/p/260083265
先来先服务(First Come First Seved, FCFS)
- 每次从就绪队列选择最先进入队列的进程,然后一直运行,直到进程 退出或被阻塞,才会继续从队列中选择第一个进程接着运行
- 当一个⻓作业先运行了,那么后面的短作业等待的时间就会很⻓,不利 于短作业
最短作业优先(Shortest Job First, SJF)
- 优先选择运行时 间最短的进程来运行,这有助于提高系统的吞吐量
- 对⻓作业不利
高响应比优先 (Highest Response Ratio Next, HRRN)

时间片轮转(Round Robin, RR)
- 每个进程被分配一个时间段,称为时间片(Quantum),即允许该进程在该时间段中运行。 如果时间片用完,进程还在运行,那么将会把此进程从 CPU 释放出来,并把 CPU 分配 给另外一个进程; 如果该进程在时间片结束前阻塞或结束,则 CPU 立即进行切换;
多级反馈队列(Multilevel Feedback Queue)
- 「多级」表示有多个队列,每个队列优先级从高到低,同时优先级越高时间片越短。
- 「反馈」表示如果有新的进程加入优先级高的队列时,立刻停止当前正在运行的进程,转而去运行优先级高的队列;
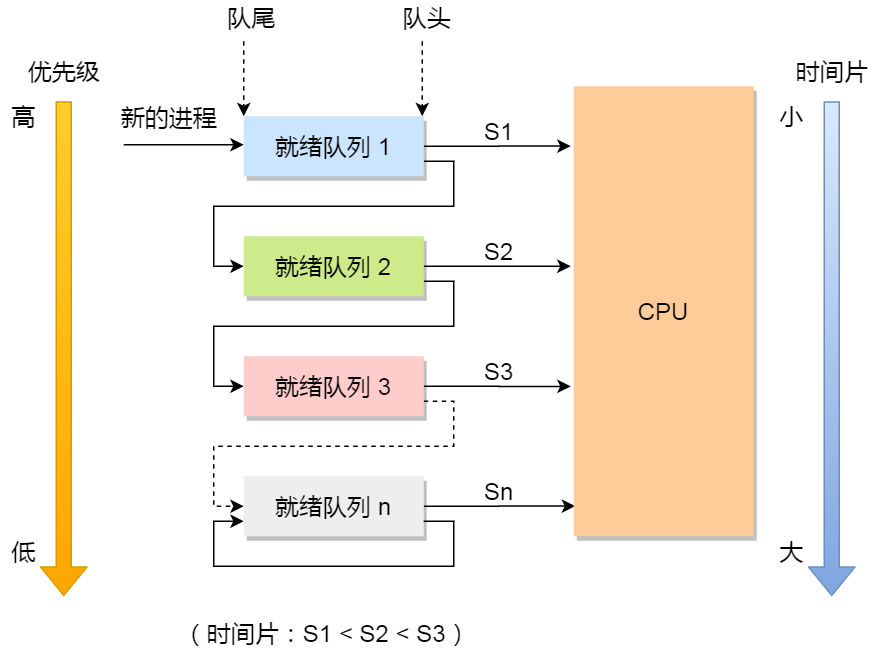
- 设置了多个队列,赋予每个队列不同的优先级,每个队列优先级从高到低,同时优先级越高时间片越短;
- 新的进程会被放入到第一级队列的末尾,按先来先服务的原则排队等待被调度,如果在第一级队列规定的时间片没运行完成,则将其转入到第二级队列的末尾,以此类推,直至完成;
- 当较高优先级的队列为空,才调度较低优先级的队列中的进程运行。如果进程运行时,有新进程进入较高优先级的队列,则停止当前运行的进程并将其移入到原队列末尾,接着让较高优先级的进程运行;
linux进程调度算法
演化过程
- 早期的进程调度器:早期的Linux内核使用的进程调度器是一个非常简单的轮询调度器。当进程被唤醒时,它被添加到调度队列的末尾。当进程的时间片用完后,它被移动到队列的头部。
- 2.2内核进程调度器:在2.2内核中,进程调度器被重写,引入了优先级调度算法。每个进程都被赋予一个优先级,优先级越高的进程获得更多的CPU时间。在这个版本的内核中,进程的优先级是根据进程的进程状态、时间片和其他因素动态计算的。通过轮询执行复杂度为O(n)
- O(1)进程调度器:O(1)进程调度器是在2.4内核中引入的。它使用了一个基于时间戳的调度算法,使得调度器能够快速地选择下一个要执行的进程。O(1)调度器还引入了一个“反馈优先级”机制,以确保长时间运行的进程不会占用CPU时间过多。
- CFS进程调度器:CFS(Completely Fair Scheduler)进程调度器是在2.6.23内核中引入的。CFS调度器使用了红黑树来维护进程的调度队列,使得进程的查找和调度变得更加高效。CFS调度器还引入了一个权重机制,以确保进程能够按照它们的优先级获得适当的CPU时间。
O(n)进程调度器
- 调度器定义了一个 runqueue 的运行队列,将进程的状态变为 Running 的都会添加到此运行队列中,但是不管是实时进程,还是普通进程都会添加到这个运行队列中。当需要从运行队列中选择一个合适的任务(通过优先级确定执行顺序)时,就需要从队列的头遍历到尾部,这个时间复杂度是O(n)
O(1)进程调度器
- 因为时间复杂度为O(1)而得名
具体流程
-
存在两个bitmap(长度都是140,对应140个优先级,越低优先级越高),如果对应bit是1表示相应优先级队列有任务,还有一个数组,长度为140,元素为不同优先级的运行队列头
优先级通过静态优先级(创建时候指定)和动态优先级确定,动态优先级由其是IO密集型(优先级高)还是计算密集型综合得到
-
优先从高优先级队列执行,当时间片消耗完,加入expired 数组中
-
睡眠加入等待队列,睡醒再加入运行队列
-
当所有进程的时间片消耗完了,所有进程都在expired 数组了,只需要交换expired数组和active数组就OK
CFS
- CFS的思想就是让每个调度实体(没有组调度的情形下就是进程,以后就说进程了)的vruntime互相追赶,而每个调度实体的vruntime增加速度不同,权重越大的增加的越慢,这样就能获得更多的cpu执行时间。
具体调度流程
-
首先进程调度器先给
TASK_RUNNING状态的进程分配时间片 -
时间片大小的计算通过
分配给进程的运行时间 = 调度周期 * 进程权重 / 所有进程权重之和,权重和nice值相关调度周期就是将所有处于TASK_RUNNING态进程都调度一遍的时间,差不多相当于O(1)调度算法中运行队列和过期队列切换一次的时间
-
将进程插入红黑树中,插入的key为vruntime,val为进程的信息
-
vruntime的计算方法为
vruntime = 实际运行时间 * 1024 / 进程权重 -
调度时候选择vruntime最小(即红黑树最左边)运行
-
当进程被唤醒或者通过fork()创建进程时,加入红黑树,
-
当进程进入休眠状态,会放到等待队列中,满足条件后会重新加入红黑树中
滑动窗口
维护一个计数器,将单位时间段(比如1s)当做一个窗口,计数器记录这个窗口接收请求的次数。
- 当次数少于限流阀值,就允许访问,并且计数器+1
- 当次数大于限流阀值,就拒绝访问。
- 当前的时间窗口过去之后,计数器清零。
缺点
- 但是一旦到达限流后,请求都会直接暴力被拒绝
- 边缘效应,还是可能出现一段时间请求超过限制的问题
滑动队列
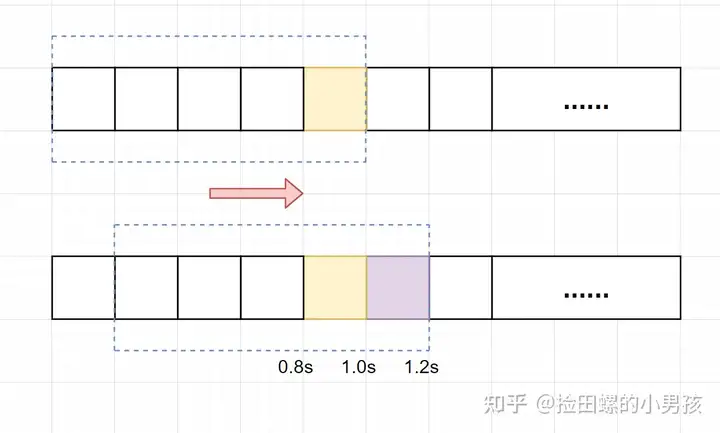
- 使用队列作为请求的标识,每次请求之前将1分钟(假设以1分钟作为单位)前的请求全部pop出去,然后检查队列长度是否依旧大于最大值
缺点
- 简单但是占空间大,因为有实体,有些过期的依旧会被保存
漏桶
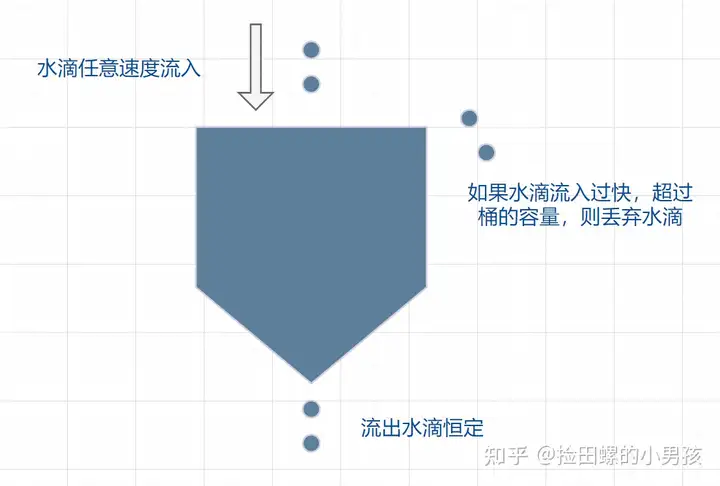
- 流入的水滴,可以看作是访问系统的请求,这个流入速率是不确定的。
- 桶的容量一般表示系统所能处理的请求数。
- 如果桶的容量满了,就达到限流的阀值,就会丢弃水滴(拒绝请求)
- 流出的水滴,是恒定过滤的,对应服务按照固定的速率处理请求。
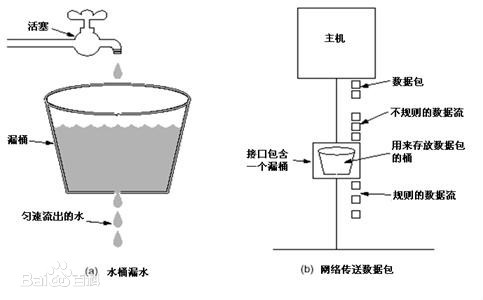
- 存下请求
- 匀速处理
- 多余丢弃
缺点
- 面对突发流量的时候,漏桶算法还是循规蹈矩地处理请求,这就不是我们想看到的啦。流量变突发时,我们肯定希望系统尽量快点处理请求,提升用户体验
令牌桶
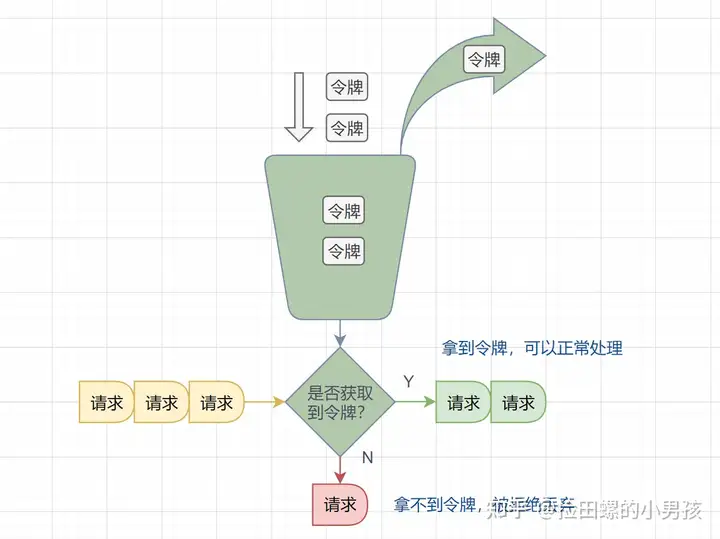
- 有一个令牌管理员,根据限流大小,定速往令牌桶里放令牌。
- 如果令牌数量满了,超过令牌桶容量的限制,那就丢弃。
- 系统在接受到一个用户请求时,都会先去令牌桶要一个令牌。如果拿到令牌,那么就处理这个请求的业务逻辑;
- 如果拿不到令牌,就直接拒绝这个请求
- 用的最多,如果放令牌速度不变退化成漏桶
- 优点是满足突然的高峰需求
缺点
- 放置令牌的速率难以控制
滑动窗口计数法

- 结合了计数法和队列法的特点
- 当前的请求数量=当前窗口的请求+上个窗口的请求*((窗口长度-当前窗口长度)/窗口长度)
[!example] 上图中的计算 3+5*0.7%=6.5 舍和入都可以
- 优点是滑了流量峰值,因为速率是基于前一个窗口的平均速率和内存效率高
缺点
- 它假设前面窗口请求是均匀分配的,如果出现不均匀分配,可能出现错误放通或禁止,只适用于不那么严格的向后看窗口
并发限流
- 对于每个请求,并发度限流分三个步骤:
- 资源申请:请求开始时,业务服务申请资源,并发度+1。当并发度达到阈值,拒绝请求,在这之前设置了最大并发度。
- 业务逻辑:请求进行中,业务执行访问数据库、下游服务等操作。
- 资源释放:请求结束后,业务服务释放资源,并发度-1。
- 这个其实可以和别的限流方法一起使用
- 相当于通过并发的维度而不是通过QPS的维度,在大规模秒杀场景很管用
微信
过载保护
- 依赖微服务框架的快速拒绝

- client端漏桶策略:每15秒为一个统计周期,统计请求所有ip:port的连接和超时(-202)次数,当某个ip:port的fail次数超过4次,则本周期内不在请求这个ip:port,client端会尝试请求其他ip:port。这部分类似熔断策略
- INQUEUE TIMEOUT: hikit woker从INQUEUE里取到一个任务时,发现任务在队列里面等待超过了500ms,那么直接不处理,给client返回-1235,client端直接失败,默认没有重试策略。
- FastReject策略: 一个请求在入队前,判断上一周期(默认是上1秒)的所有请求入队/出队平均耗时,如果耗时大于20ms,那么直接不入队,给client返回-1233,client端重试下一台,如果两台机都返回-1233,那么不再重试,client返回-1234失败
频率拦截服务

- 本地Agent通过RPC代理上报访问信息到后台,同时拉取拦截策略并更新至拦截策略共享内存
- 频率拦截后台负责统计访问频率,达到阈值时触发新的拦截策略。
- 拦截Api将访问信息push到队列中,同时通过拦截策略共享内存获知当次访问是否需要拦截。
熔断
- 两种熔断机制,一种是本地熔断,快速拒绝,计算平均响应时间
- #TODO 完成熔断部分的学习
参考
- https://zhuanlan.zhihu.com/p/376564740
常见操作系统
CPU
All problems in computer science can be solved by another level of indirection
- 计算机科学中的所有问题都可以通过增加一个间接层来解决
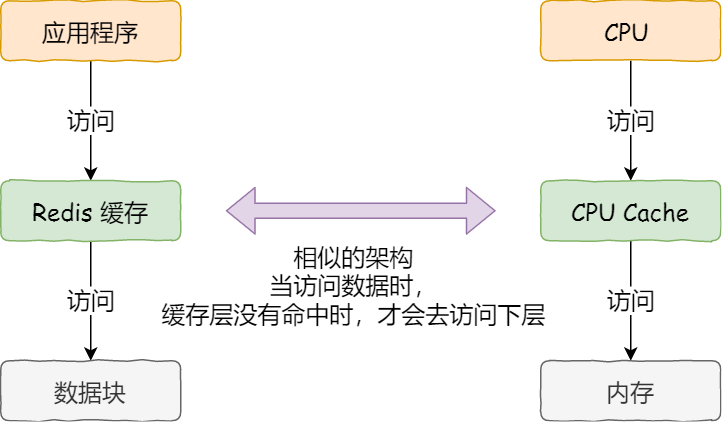
cache分布
- 每个CPU有自己的cache1和cache2,但是cache3是共享的
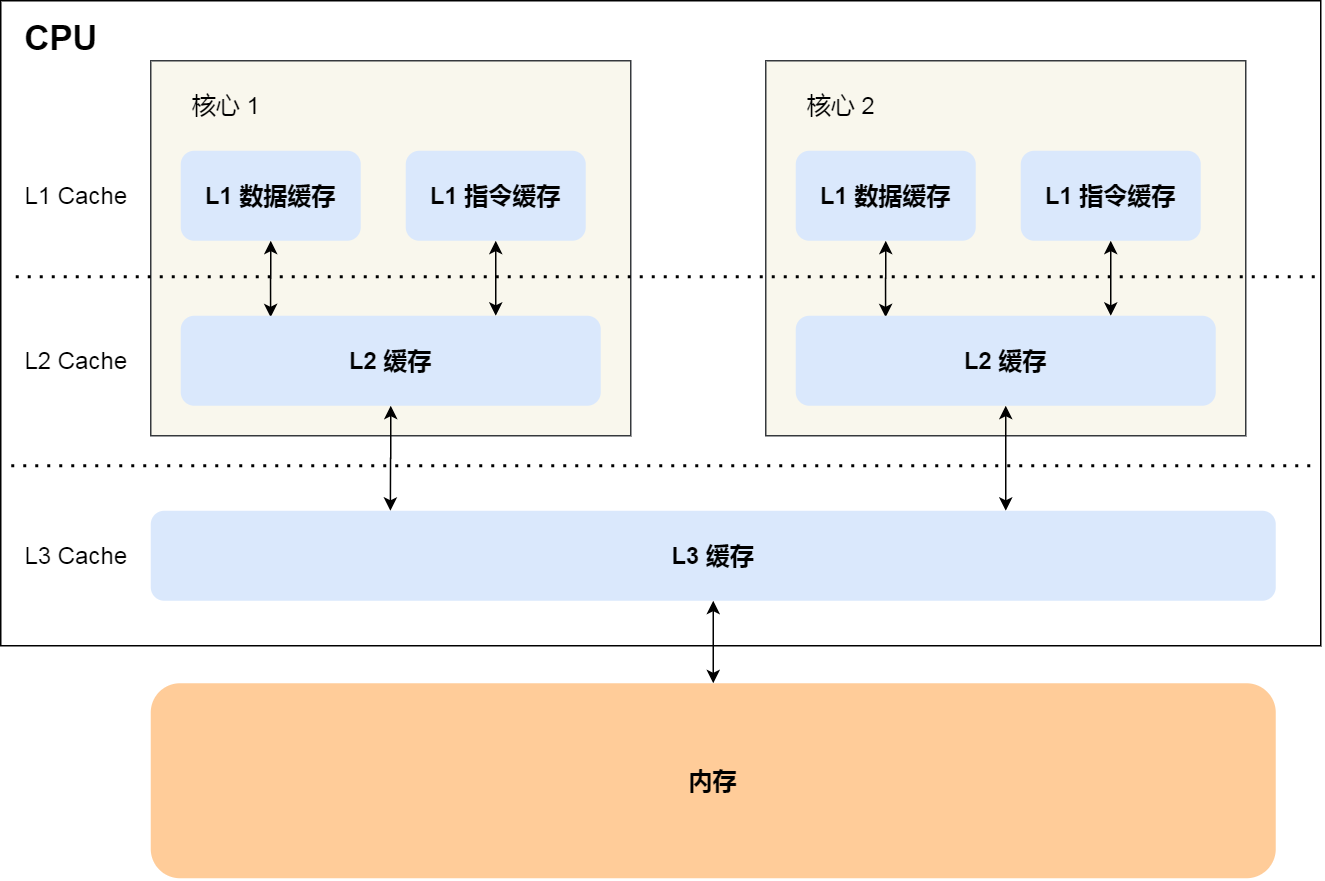
写入cache流程
缓存一致性问题
出现原因
- 多个CPU同时更新同一个数据,出现不一致现象,类似缓存一致性
解决办法
- 需要同时满足写同步和串行化
写同步
- 某个 CPU 核心里的 Cache 数据更新时,必须要传播到其他核心的 Cache
- 通过总线嗅探(Bus Snooping)实现
串行化
- 所有核心都能看到相同顺序的数据变化
- 通过MESI 协议实现
cpu选择线程
- CFS公平算法
- CPU优先选择vruntime时间小的

- cpu维护一个运行队列(底层是按照vruntime排序的红黑树)
nice值
- priority(new) = priority(old) + nice
- 时间片的分配由nice值决定
启动过程
- BISO 开机自检
- MBR 查找启动分区的代码执行(现在可能没有了) >MBR存在于可启动磁盘的0磁道0扇区,占用512字节,它主要用来告诉计算机从选定的可启动设备的哪个分区来加载引导加载程序(Boot loader),MBR中存在如下内容: (1) Boot Loader 占用446字节,存储有操作系统(OS)相关信息,如操作系统名称,操作系统内核位置等,它的主要功能是加载内核到内存中运行。 (2) Partition Table 分区表,占用64字节,每个主分区占用16字节(这就是为啥一块硬盘只能有4个主分区啦 (3)分区表有效性标记占用2字节 CPU将MBR读取至内存,运行GRUB(Boot Loader常用的有GRUB和LILO两种,现在常用的是GRUB),GRUB会把内核加载到内存去执行。
- Loader唤醒操作系统,唤醒下一层,把kernal读入内存,将initrd.img(一个虚拟的临时的根文件系统,每台机器都不一样)读到内存
- Kernel,init 长期执行,使用只带驱动,替代biso提供的服务,然后后台运行
- Application Manager,接管和用户打交道的部分
- Applications,各种各样的应用运行

运行等级
runlevel命令查看,Linux系统有7个运行级别(runlevel):- 0:系统停机状态,系统默认运行级别不能设为0,否则不能正常启动
- 1:单用户工作状态,root权限,用于系统维护,禁止远程登录
- 2:多用户状态(没有NFS)
- 3:完全的多用户状态(有NFS),登录后进入控制台命令行模式
- 4:系统未使用,保留
- 5:X11控制台,登录后进入图形GUI模式
- 6:系统正常关闭并重启,默认运行级别不能设为6,否则不能正常启动
并发和并行的区别
并发
并行
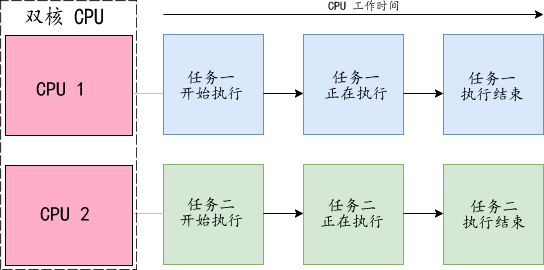
相较于顺序执行的优缺点
优点
- 提高程序执行效率:多线程可以利用多个CPU核心同时执行任务,从而提高程序的执行效率。在单核CPU上,多线程也可以使程序更加响应,因为线程可以在等待I/O操作(如读写文件、网络通信等)时让出CPU资源,从而避免了阻塞等待。
- 提高程序的并发性:多线程可以让程序同时执行多个任务,从而提高程序的并发性。这对于需要同时处理多个请求的Web服务器和数据库等应用程序来说尤其重要。
- 提高用户体验:多线程可以让程序更加快速地响应用户操作,从而提高用户体验。例如,在GUI程序中,一个线程可以负责处理用户界面的更新和事件响应,另一个线程可以负责执行耗时的计算任务,这样用户就不会感觉到界面的卡顿。
缺点
- 线程之间的通讯和同步麻烦
- 竞争现象,容易产生死锁
- 当python这种全局只有一个解释器,在单核的场景下,多线程比单线程还慢
僵尸进程和孤儿进程
- 启动了一个A进程,然后通过A进程再启动B进程,此时如果杀死A进程,B可能有两种情况,B被杀死或者B被作为孤儿进程被1号进程收养,如果是使用kill发出信号的形式,那么操作系统会将所有的子进程一起kill,但是如果是父进程自然结束,没有收到信号,那么子进程将会被挂到1号进程的进程树中
- 子比父先死,但是父没有回收讲座僵尸进程,损耗系统资源,父比子先死,值会成为孤儿进程被1号给接管
进程之间通讯方式
-
管道pipe:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
-
命名管道FIFO:有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
-
消息队列MessageQueue:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
-
共享存储SharedMemory:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
-
信号量Semaphore:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
互斥量是信号量的一种特例,互斥量的本质是一把锁 信号量一般用于进程同步,本质上只是一个atomic
-
套接字Socket:套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
-
信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
优缺点
- 管道:速度慢,容量有限;
- Socket:任何进程间都能通讯,但速度慢
- 消息队列:容量受到系统限制,且要注意第一次读的时候,要考虑上一次没有读完数据的问题
- 信号量:不能传递复杂消息,只能用来同步
- 共享内存区:能够很容易控制容量,速度快,但要保持同步,比如一个进 程在写的时候,另一个进程要注意读写的问题,相当于线程中的线程安全,当然,共享内存区同样可以用作线程间通讯,不过没这个必要,线程间本来就已经共享了同一进程内的一块内存。
进程状态
| 运行状态 | 等级表示 | 描述 |
|---|---|---|
| r | running | 进程正在运行或正在运行队列中等待 |
| s | sleeping | 进程被挂起,并正在等待某个事件的发生 |
| d | waiting | 进程正在等待 i/o 操作完成,例如等待磁盘输入/输出 |
| z | zombie | 进程已经结束,但其父进程还没有将其完全释放 |
| t | stopped | 进程被暂停或停止 |
408状态
- 运行态,占有CPU
- 就绪态,等待CPU,准备好其他的
- 阻塞态,因为等待事件发生
- 创建态,初始化PCB
- 终止态,回收PCB
进程的组成
- PCB,操作系统为进程分配的数据结构,描述进程信息,创建进程实质就是创建进程PCB
- 程序段,数据段
- 操作系统维护一个PCB链表统一管理进程
锁
自旋锁
- 只旋锁不能在单cpu下使用(会出现A拿到锁,被换下去,B等待锁,就会陷入漫长的等待)
死锁
- 解决死锁的办法就是获取资源的顺序保持相同
//死锁demo
go func() {
mu1.Lock()
// 在请求锁1后休眠一段时间,模拟复杂的执行过程
time.Sleep(1 * time.Second)
mu2.Lock()
mu2.Unlock()
mu1.Unlock()
wg.Done()
}()
go func() {
mu2.Lock()
// 在请求锁2后休眠一段时间,模拟复杂的执行过程
time.Sleep(1 * time.Second)
mu1.Lock()
mu1.Unlock()
mu2.Unlock()
wg.Done()
}()
//解决demo 核心在于获取临界资源的顺序一致性
go func() {
defer wg.Done()
mu1.Lock()
defer mu1.Unlock()
mu2.Lock()
defer mu2.Unlock()
// 真正的临界区代码
}()
go func() {
defer wg.Done()
mu1.Lock()
defer mu1.Unlock()
mu2.Lock()
defer mu2.Unlock()
// 真正的临界区代码
}()
中断
- 上半部,对应硬中断,由硬件触发中断,用来快速处理中断;
- 下半部,对应软中断,由内核触发中断,用来异步处理上半部未完成的工作;
- 当中断发生时候,CPU立刻进入核心态
- 中断发生后,进程停止运行,操作系统堆中断进行处理
- 用户态到核心态的切换是通过中断实现的,而且中断是唯一途径
- 只有下半部中断可以被打断,上半部执行完成后会加入下半部的队列中执行
数据存储
浮点数的表示
所以通常将
1000.101这种二进制数,规格化表示成1.000101 x 2^3,其中,最为关键的是 000101 和 3 这两个东西,它就可以包含了这个二进制小数的所有信息:
000101称为尾数,即小数点后面的数字;3称为指数,指定了小数点在数据中的位置;

内核类型
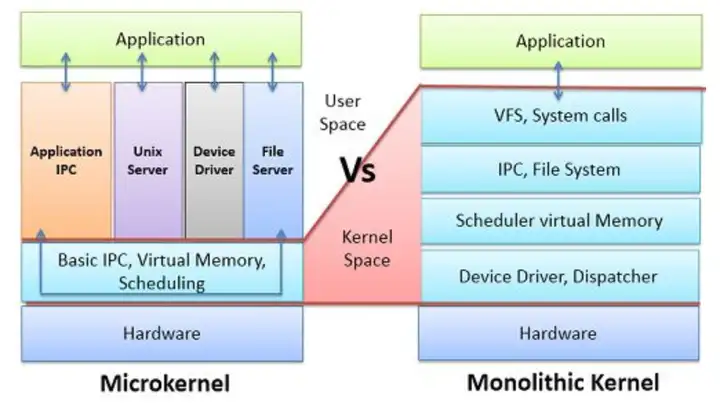
宏内核
- 宏内核的特征是系统内核的所有模块,比如进程调度、内存管理、文件系统、设备驱动等, 都运行在内核态。
优缺点
- 内核管理着CPU调度,内存管理,文件管理和系统调用等各模块的的工作,由于用户服务和内核服务被实现在同一空间中,这样在执行速度上要比微内核快
- 当内核中的某个服务崩溃了,整个内核也会崩溃。另一点,想要在内核中添加新的功能就意味着内核中的各个模块需要做相应的修改,因此其扩展性很弱。
微内核
- 微内核架构的内核只保留最基本的能力,比如进程调度、虚拟机 内存、中断等,把一些应用放到了用户空间,比如驱动程序、文件系统等
优缺点
- 用户服务是独立于内核服务的,因此任何用户服务崩溃都不会影响到内核服务,这就加强了操作系统的健壮性,这是微内核的优势所在。另一点,微内核的扩展性强,添加一个功能,只需要建立一个新的服务到用户空间当中,而内核空间不需要任何的修改。因此,微内核可移植性强、安全并且易于扩展。
- 内核中的某个服务负责管理缺页异常并保存新分配的页,只要有缺页异常发生,请求就经过内核通知页管理器。页管理器必须进入特权模式下来获取内存的访问,然后回到用户模式下。然后发送一个返回结果来触发进程,当然这个过程也是需要经过内核的。处理缺页异常或者保存新分配页的整个过程是繁复而耗时的。
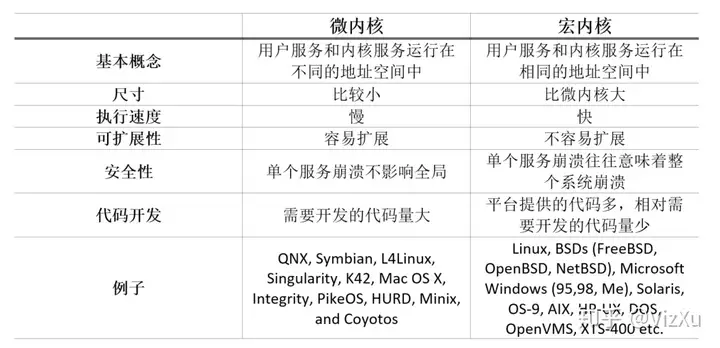
混合类型内核
- 内核里面会有一个最小版本的内 核,然后其他模块会在这个基础上搭建,然后实现的时候会跟宏内核类似,也就是把整个内 核做成一个完整的程序,大部分服务都在内核中,这就像是宏内核的方式包裹着一个微内核。(windows使用)
用户态内核态
切换
- 当用户程序需要访问系统资源时,会触发一个系统调用(system call),该系统调用会在用户态产生一个异常(exception)请求。
- 操作系统捕获到异常请求后,会检查该请求是否合法。如果合法,操作系统会切换到内核态,并将程序执行的现场(如程序计数器、寄存器状态等)保存在内核态的堆栈中。
- 在内核态中,操作系统会根据请求类型,调用相应的内核服务例程(只是执行待代码片段,而不是一个进程),对系统资源执行所需操作并返回结果。
- 操作系统在完成了对系统资源的操作之后,会将结果返回给用户程序,并将现场(程序计数器、寄存器状态等)恢复为切换前的状态。
- 操作系统再次切换回用户态,用户程序可以继续执行。
区别
- 内核态是操作系统内核在运行,而用户态是普通应用程序在运行。
- 处于内核态执行时,则能访问所有的内存空间和对象,且所占有的处理器是不允许被抢占的。
- 执行指令的不同,特权指令必须在内核态执行
- 判断是通过程序中的PSW标识位判断当前的状态的
切换时机
- 系统调用:这是用户态进程主动要求切换到内核态的一种方式,用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作,类似print,fork
- 中断:当外围设备完成用户请求的操作后,会向 CPU 发出相应的中断信号,这时 CPU 会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
- 异常:当 CPU 在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常,比如除0异常
内存
OOM
- (Out Of Memory Killer),如果发现内存不够了,而且没开启swapfile,那么杀死占用内存最高的进程,以维护系统不崩溃
碎片
内部碎片
- 一个分区(某个进程中)内部出现的碎片(即被浪费的空间),不能被利用。如一个进程申请43KB的内存空间,某些处理器因为限制(比如其体系结构规定只能整除4、8、16),该进程被分配了44KB,就有1KB的内部碎片。
解决办法
- 内存交换,内存分页方法.⻚表是存储在内存里的,内存管理单元 (MMU)就做将虚拟内存地址转换成物理地址的工作。
外部碎片
- 动态分区法中,频繁进行分配回收后,会出现越来越多的小空闲块,由于太小了,无法装进小进程,就是外部碎片
解决办法
- 紧缩(利用动态重定位技术):移动某些已分配区的内容,是所有进程的分区紧挨在一起,把空闲区留在另一端
虚拟内存
- 使用页表使得虚拟内存的地址和实际内存的地址联系起来
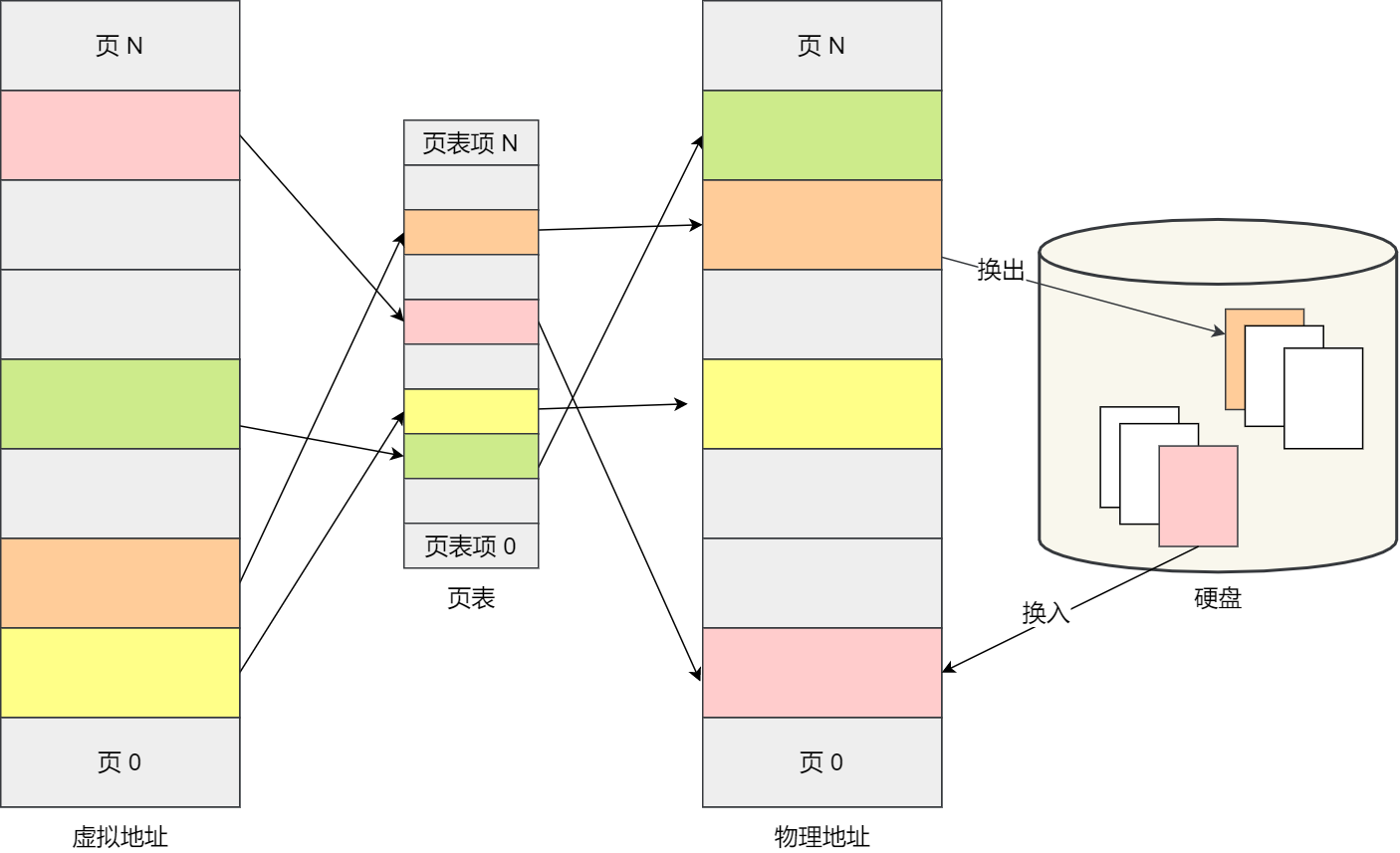
意义
- 因为内存分页,如果不使用虚拟内存,那么应用的地址是不连续的,那么应用的开发体验会不好(无法确定地址的位置),虚拟地址是连续的
- 虚拟内存允许进程使用比物理内存更大的内存空间,这样可以扩展可用内存的大小。即使物理内存有限,虚拟内存可以为进程提供更大的地址空间。
- 内存隔离和保护:虚拟内存将进程的地址空间划分为多个页面,每个页面可以独立进行访问和管理。这样可以实现内存隔离,使得每个进程的内存空间相互隔离,互不影响。同时,虚拟内存还可以通过页面级别的权限设置,提供内存保护机制,防止进程之间相互干扰或访问非法内存
- 更好的支持内存交换机制
swap机制
- 系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前运行的程序使用。那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间会被临时保存到磁盘,等到那些程序要运行时,再从磁盘中恢复保存的数据到内存中。当内存使用存在压力的时候,会开始触发内存回收行为,会把这些不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了
- 优点是应用程序实际可以使用的内存空间将远远超过系统的物理内存。由于硬盘空间的价格远比内存要低,因此这种是经济实惠的。当然,频繁地读写硬盘,会显著降低操作系统的运行速率,这也是 Swap 的弊端。
[!info] linux下swapfile的调整参考 如何在 Ubuntu 中创建、删除和调整 SWAP 空间 - 系统极客
内存空间
- 32 位系统的内核空间占用 1G ,位于最高处,剩下的 3G 是用户空间
- 64 位系统的内核空间和用户空间都是 128T ,分别占据整个内存空间的最高和最低处, 剩下的中间部分是未定义的。


程序内存布局
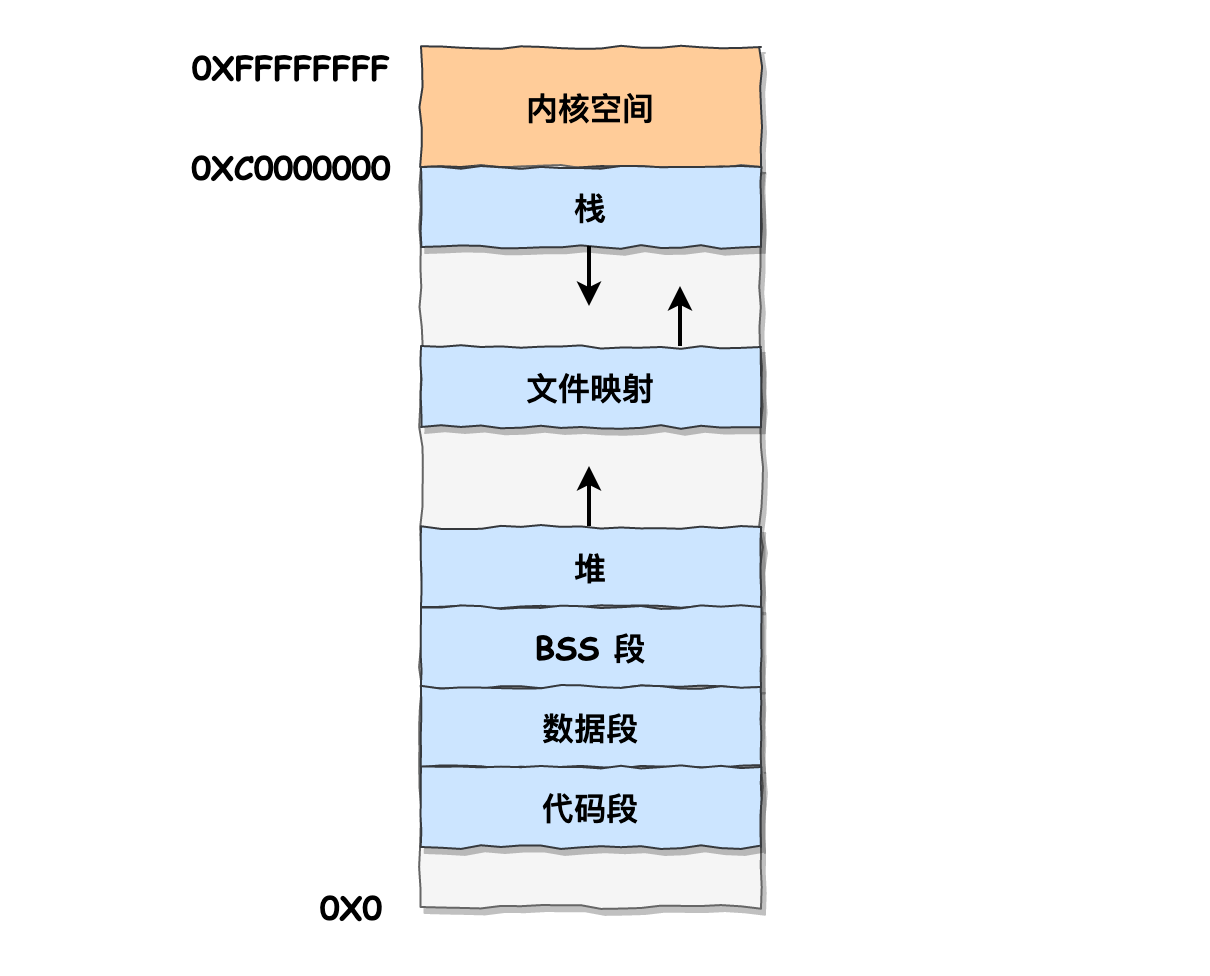
- 程序文件段,包括二进制可执行代码
- 已初始化数据段,包括静态常量
- 未初始化数据段,包括未初始化的静态变量
- 堆段,包括动态分配的内存,从低地址开始向上增⻓
- 文件映射段,包括动态库、共享内存等,从低地址开始向上增⻓部变量和函
- 调用的上下文等。栈的大小是固定的,一般是 8 MB
栈:由编译器管理分配和回收,存放局部变量和函数参数。 堆:由程序员管理,需要手动 new malloc delete free 进行分配和回收,空间较大,但可能会 出现内存泄漏和空闲碎片的情况。 全局/静态存储区:分为初始化和未初始化两个相邻区域,存储初始化和未初始化的全局变量 和静态变量。 常量存储区:存储常量,一般不允许修改。 代码区:存放程序的二进制代码。
静态库和动态库加载
- 动态库:动态库的加载是在程序运行时由操作系统进行的,通常是将动态库的代码和数据加载到进程的虚拟内存空间的共享库区域。这个共享库区域通常是由操作系统维护的,多个进程可以共享同一个动态库的实例,从而实现了动态库的代码重用和共享
- 静态库:静态库的加载则是在编译链接时进行的,在编译链接过程中,静态库的代码和数据会被直接嵌入到可执行文件中的相应区域。在程序运行时,这些静态库的代码和数据会随着可执行文件一起加载到进程的虚拟内存空间的代码段和数据段中。
如何malloc很大的内存如何分配
- malloc时候分配的是虚拟内存,并不是实际内存,当程序下如这部分内存的地址时候CPU访问这个内存,这时会发现这个虚拟内存没有映射到物理内存, CPU 就会产生缺页中断,进程会从用户态切换到内核态,并将缺页中断交给内核的 Page Fault Handler (缺页中断函数)处理
- 如果内存足够,直接进行映射,如果不够系统启动内存回收流程
- 如果申请物理内存大小超过了空闲物理内存大小,就要看操作系统有没有开启 Swap 机制:
- 如果没有开启 Swap 机制,程序就会直接 OOM;
- 如果有开启 Swap 机制,程序可以正常运行。
进程和线程协程
- 线程与进程最大的区别在于:线程是调度的基本单位,而进程则是资源拥有的基本单位。 线程是程序执行流的最小单位
- 线程的调度是系统级的,资源消耗大,协程是用户级的,资源消耗少,最大区别就是管理调度这些实现一个在系统,一个在用户,协程适合大量IO操作(阻塞代价小),协程主打并发,线程主打并行,操作系统 > 并发和并行的区别
- 进程调度参考调度算法
- 协程适合大量的并发任务,因为创建代价小,适合大量IO操作(切换代价小)
进程切换步骤
- 保存进程上下文环境(程序计数器,寄存器内容,堆栈指针等),一个叫做PCB的结构,使用数组或者链表实现,系统层面的
- 切换到进程的上下文环境,将状态信息加载待CPU寄存器中
- 移动控制权
线程的实现方式
- 根据操作系统内核是否对线程可感知,可以把线程分为内核线程和用户线程
用户型线程
- 内核无法感知用户的进程,进程的创建销毁都是通过线程库实现
- 库调度器从进程的多个线程中选择一个线程,然后该线程和该进程允许的一个内核线程关联起来。内核线程将被操作系统调度器指派到处理器内核。用户级线程是一种”多对一”的线程映射。
- 实现简单,无需用户态内核态的切换,因此更加快速
- 缺点是无法发挥多核心优势
内核型线程
- 内核线程驻留在内核空间,它们是内核对象。有了内核线程,每个用户线程被映射或绑定到一个内核线程。用户线程在其生命期内都会绑定到该内核线程。一旦用户线程终止,两个线程都将离开系统。这被称作”一对一”线程映射,
- 优点是可靠性和安全性,可以利用多核的优势
- 缺点是需要用户态的频繁切换,性能较低
组合方式
- linux操所系统使用的方式
- 使用组合方式的多线程实现, 线程创建完全在用户空间中完成,线程的调度和同步也在应用程序中进行. 一个应用程序中的多个用户级线程被映射到一些(小于或等于用户级线程的数目)内核级线程上
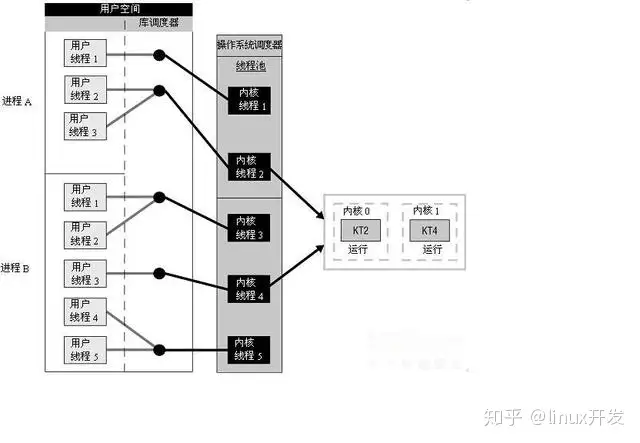
内存置换算法
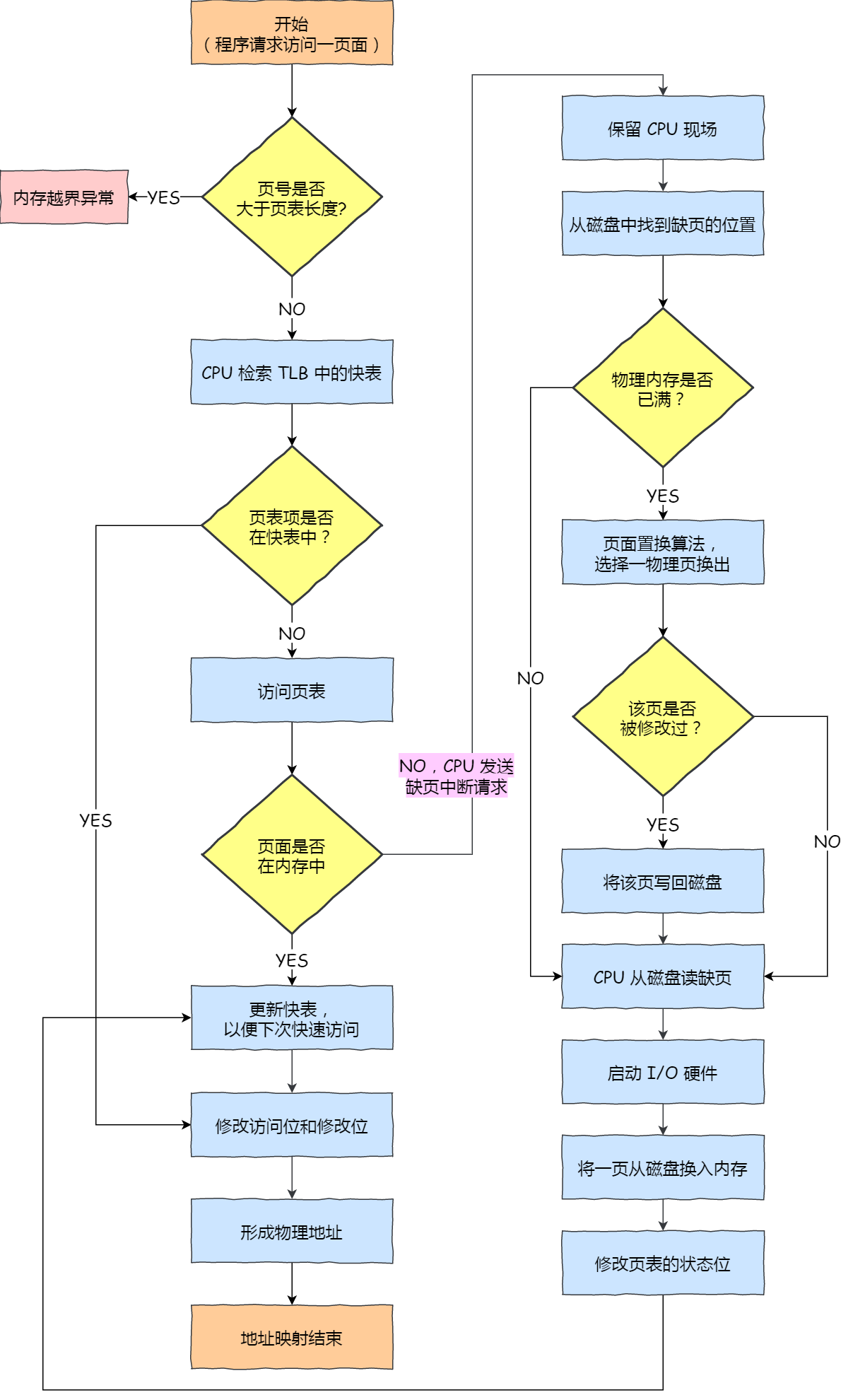
LRU算法
- 详情参考[[单调栈和链表双指针#146. LRU 缓存]|LRU]]
- 因为需要维护更新链表,使用较少
时钟⻚面置换算法
该算法的思路是,把所有的⻚面都保存在一个类似钟面的「环形链表」中,一个表针指向最 老的⻚面。 当发生缺⻚中断时,算法首先检查表针指向的⻚面: 如果它的访问位位是 0 就淘汰该⻚面,并把新的⻚面插入这个位置,然后把表针前移一 个位置; 如果访问位是 1 就清除访问位,并把表针前移一个位置,重复这个过程直到找到了一个 访问位为 0 的⻚面为止;
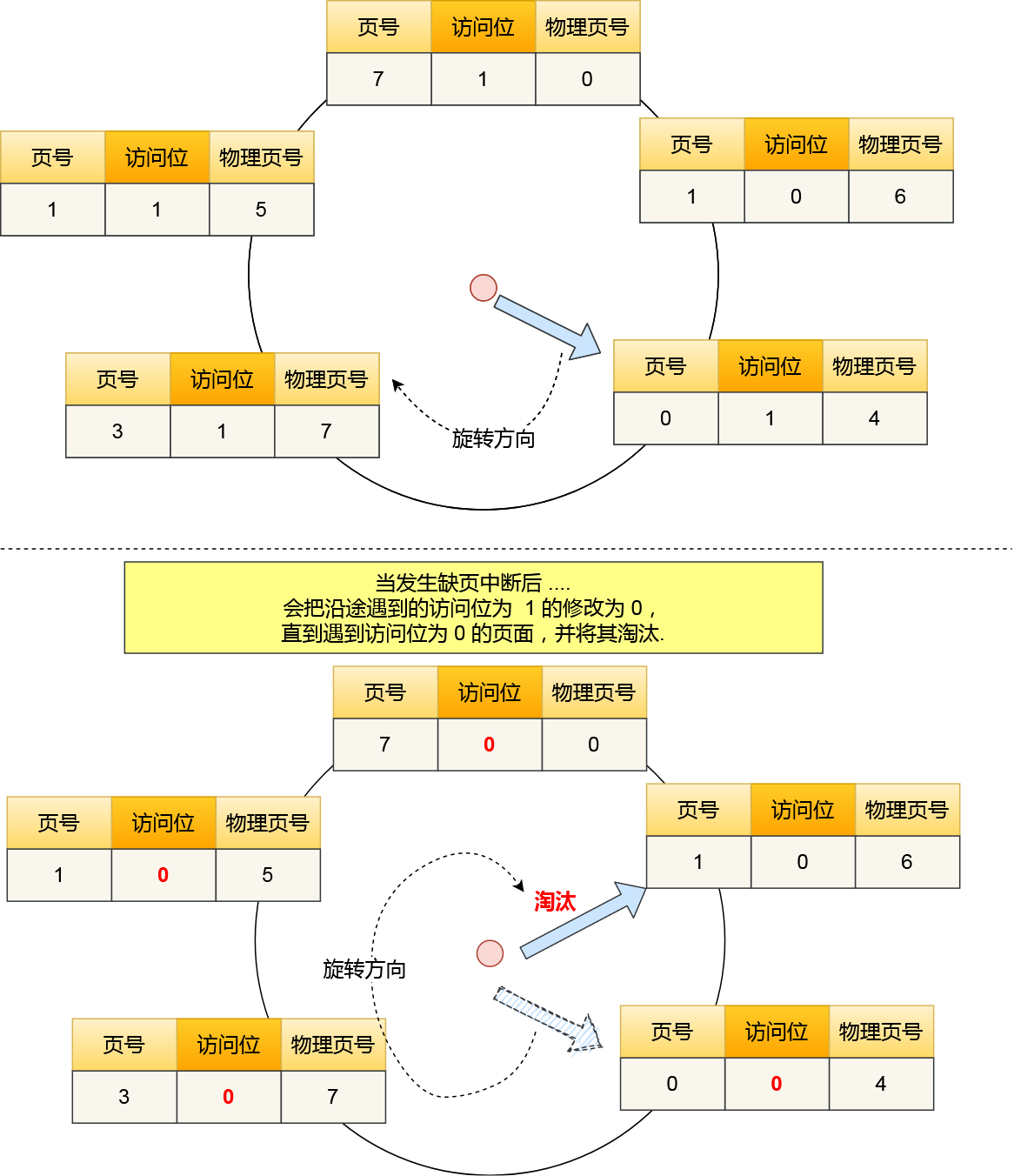
{kind=link}
文件系统

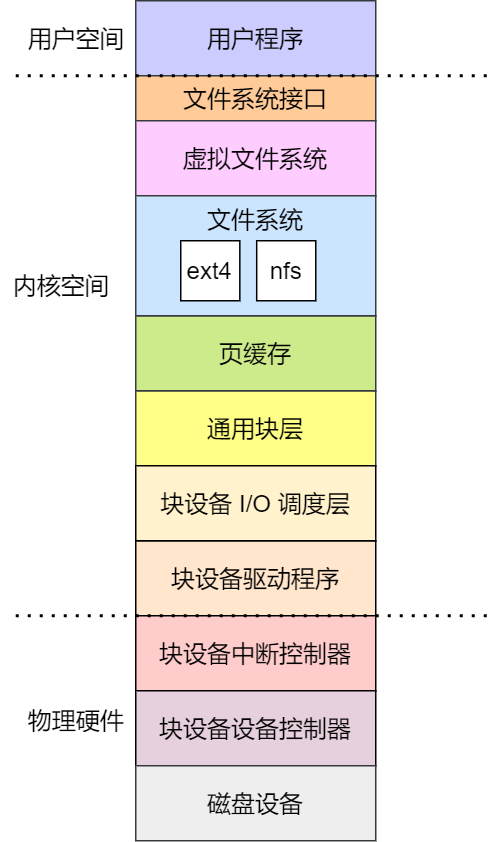
DMA技术
- 通过磁盘只带的DMA,避免了CPU长期处于用于拷贝数据状态
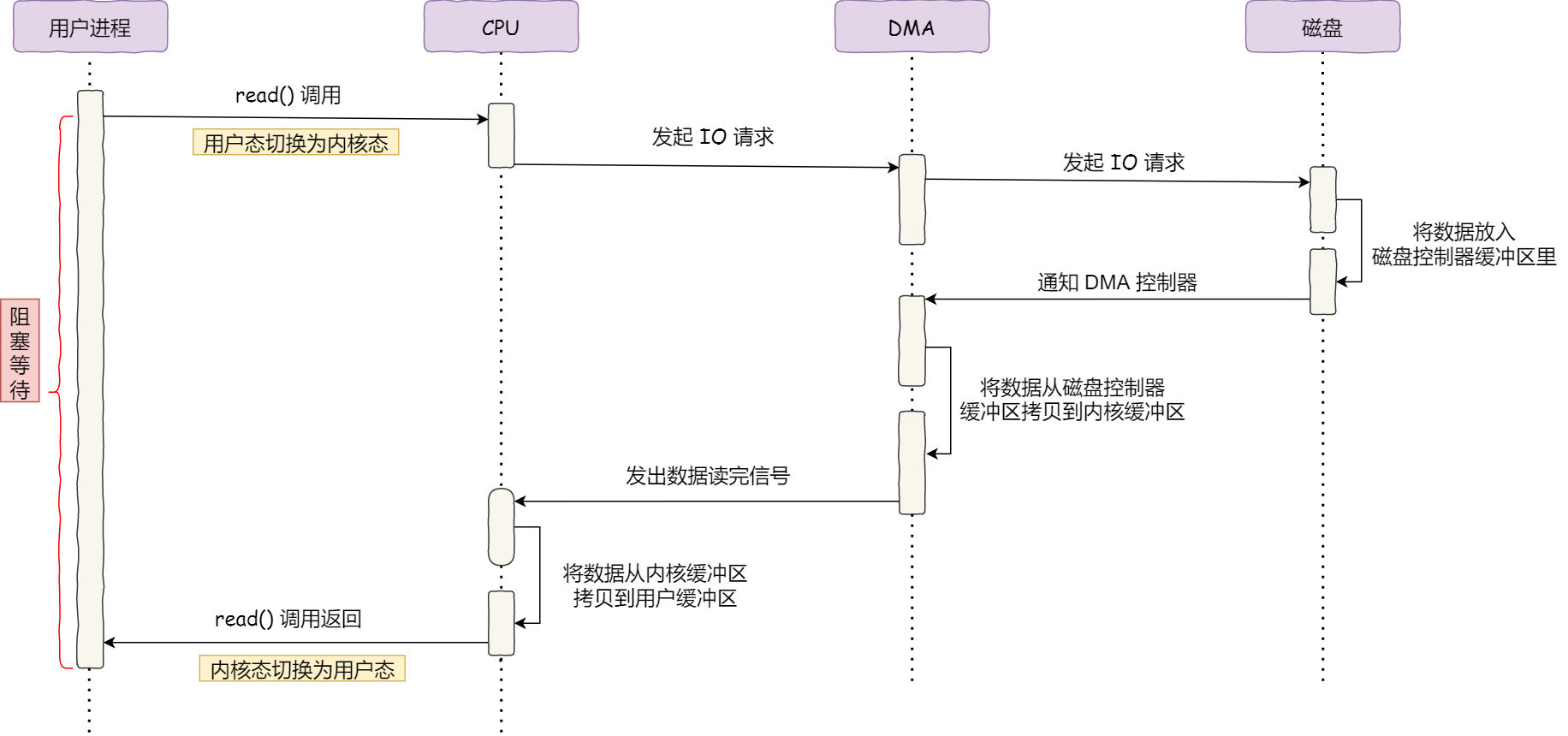
零拷贝
传统文件传输(发送文件)
- 用户态到内核态
- DMA拷贝到内核缓冲区,CPU拷贝到用户缓冲区
- 内核态到用户态
- 用户态到内核态
- CPU拷贝到socket内核缓冲区,DMA拷贝到网卡
- 内核态到用户态
缺点
- 内核态和用户态切换频繁
- 拷贝太多且没有意义
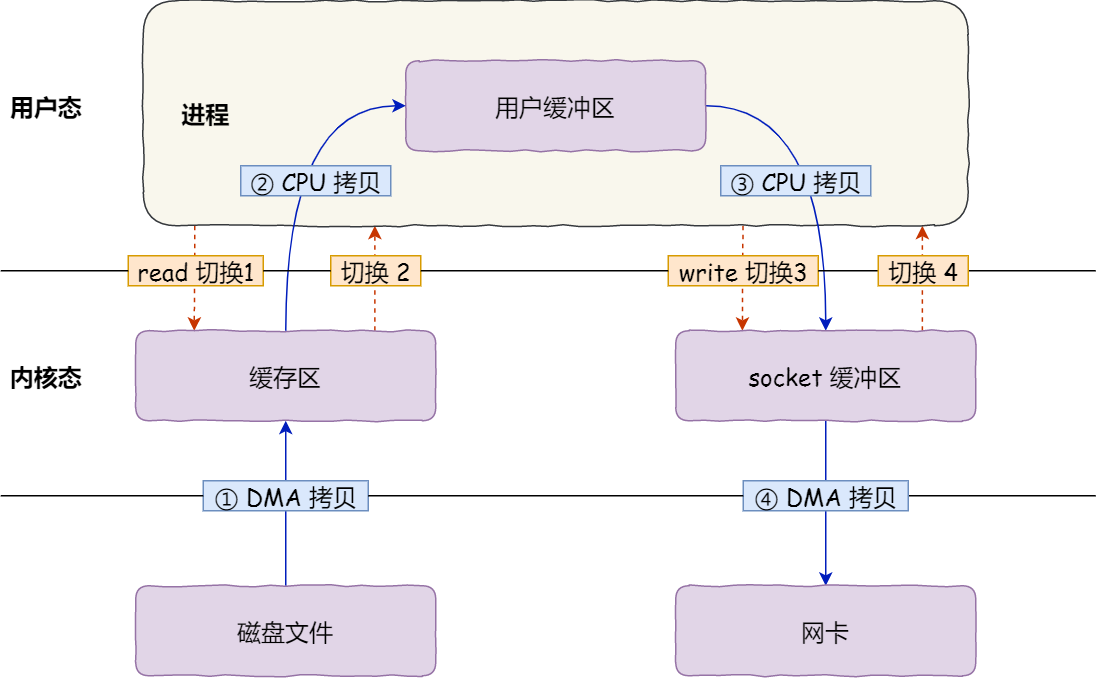
零拷贝文件传输
- 用户态到内核态
- DMA拷贝到内存,CPU发送描述符和数据长度给socket(并非拷贝)
- socket通过DMA拷贝数据到网卡
- 内核态到用户态
优点
- 减少切换次数
- 在内核区域没有对数据进行拷贝,零拷贝,kafka和nginx都使用了
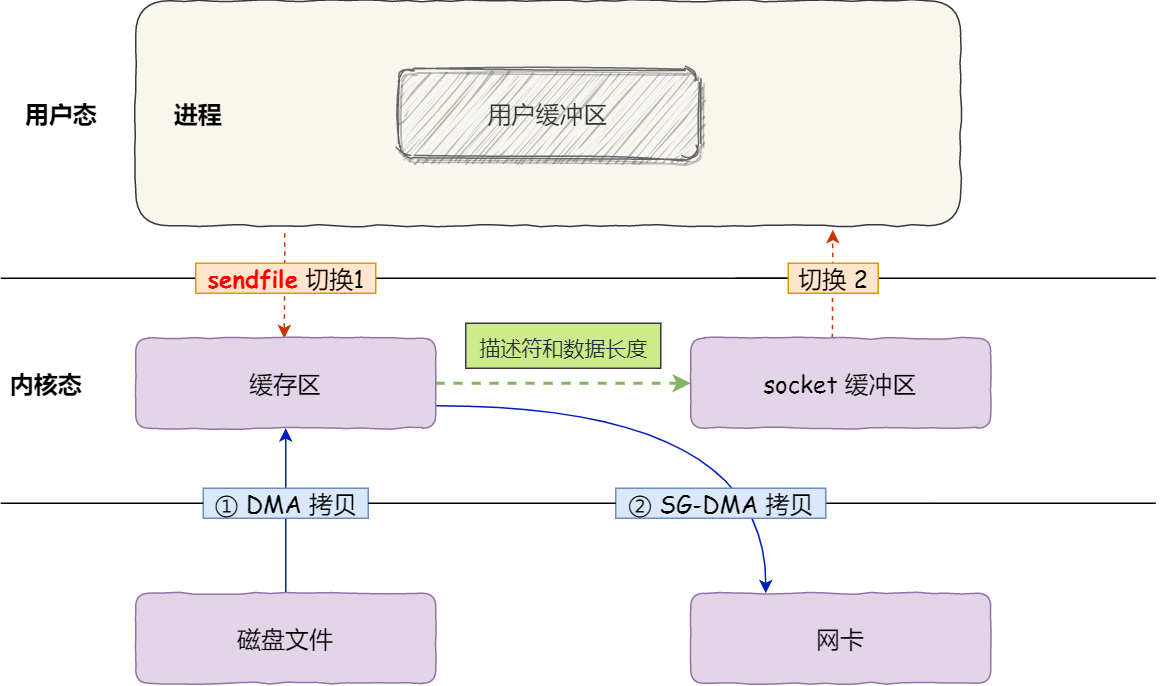
IO多路复用
单路socket
- 单线程阻塞
- 只能处理一个socket连接
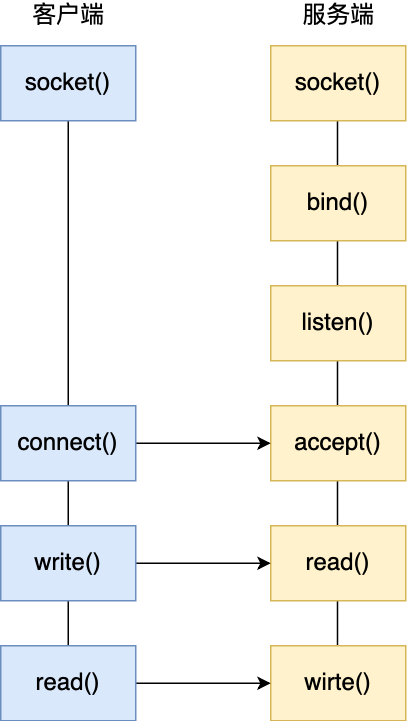
socket+多进程
- 每个请求一个进程连接一旦太大扛不住
- 上下文切换和内存拷贝频繁,效率低下
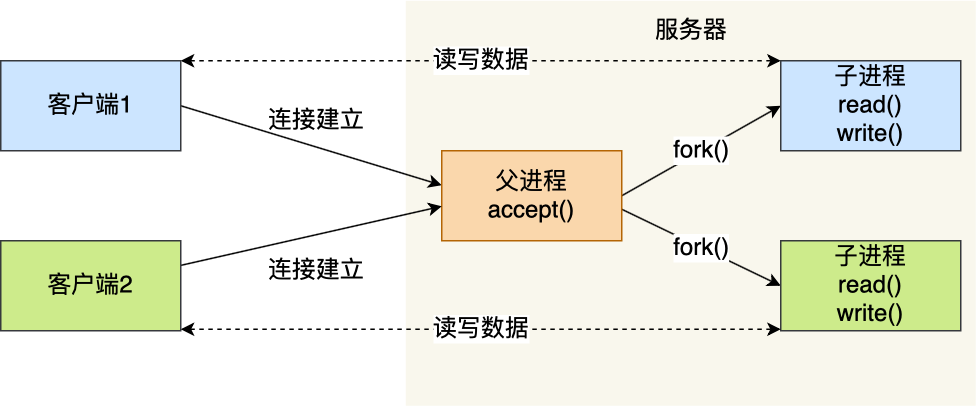
socket+线程池
- 线程池因为共享内存,加锁频繁,但是减少了内存拷贝
- 但是还是出现了上下文拷贝频繁,还是扛不住大流量
- 可以充分发挥多核优势
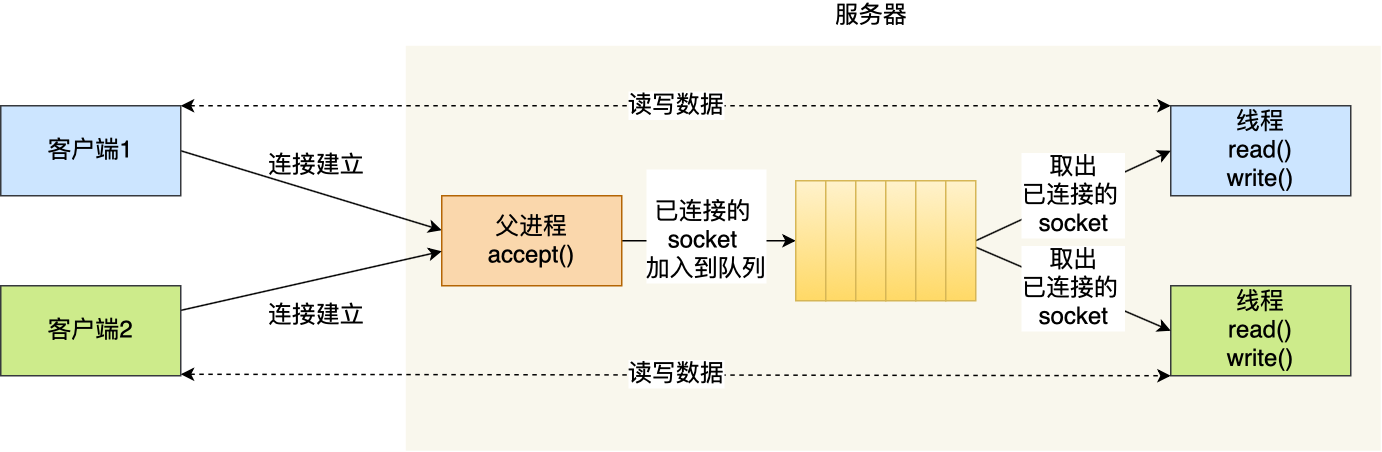
Select和Poll多路复用
- select底层使用bitmap代表每个socket,如果有消息就置为1,没有就为0,bitmap限制了监听的最大socket值(默认为1024),遍历bitmap查询
- poll底层使用链表,因此没有最大描述符的限制,但是仍然需要遍历查找每个监听socket,查询
- poll 和 select 并没有太大的本质区别,都是使用「线性结构」存储进程关注的 Socket 集合,因此都需要遍历文件描述符集合来找到可读或可写的 Socket,时间复杂度为 O(n),而且也需要在用户态与内核态之间拷贝文件描述符集合,这种方式随着并发数上来,性能的损耗会呈指数级增长。
Epoll多路复用
- epoll 在内核里使用红黑树来跟踪进程所有待检测的文件描述字,把需要监控的 socket 通过
epoll_ctl()函数加入内核中的红黑树里,红黑树是个高效的数据结构,增删改一般时间复杂度是O(logn)。而 select/poll 内核里没有类似 epoll 红黑树这种保存所有待检测的 socket 的数据结构,所以 select/poll 每次操作时都传入整个 socket 集合给内核,而 epoll 因为在内核维护了红黑树,可以保存所有待检测的 socket ,所以只需要传入一个待检测的 socket,减少了内核和用户空间大量的数据拷贝和内存分配。 - epoll 使用事件驱动的机制,内核里维护了一个链表来记录就绪事件,当某个 socket 有事件发生时,通过回调函数内核会将其加入到这个就绪事件列表中,当用户调用
epoll_wait()函数时,只会返回有事件发生的文件描述符的个数,不需要像 select/poll 那样轮询扫描整个 socket 集合,大大提高了检测的效率。 - epoll 的方式即使监听的 Socket 数量越多的时候,效率不会大幅度降低,能够同时监听的 Socket 的数目也非常的多了,上限就为系统定义的进程打开的最大文件描述符个数。因而,epoll 被称为解决 C10K 问题的利器。
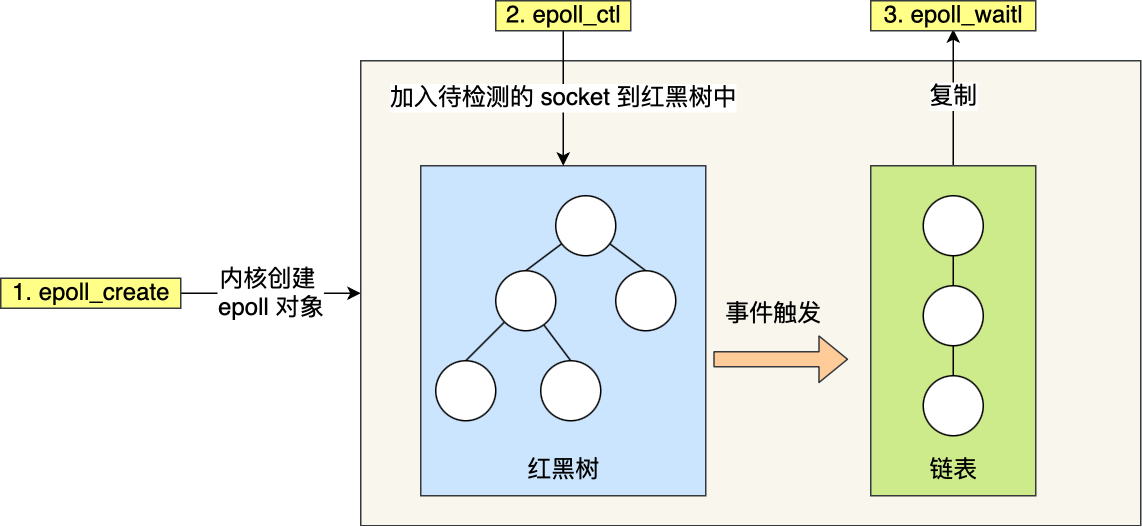
水平触发和边缘触发
- 类似于电平,水平触发时候电平处于高电位就会触发(有消息就会触发)
- 边缘触发只有电平突变才会触发(有消息触发之后即使高电位也不会继续触发)
- 水平触发简单但是效率低下
reactor模型
- 通过epoll IO复用,再从线程池拿出线程处理
- 综合两者的优点,大部分使用
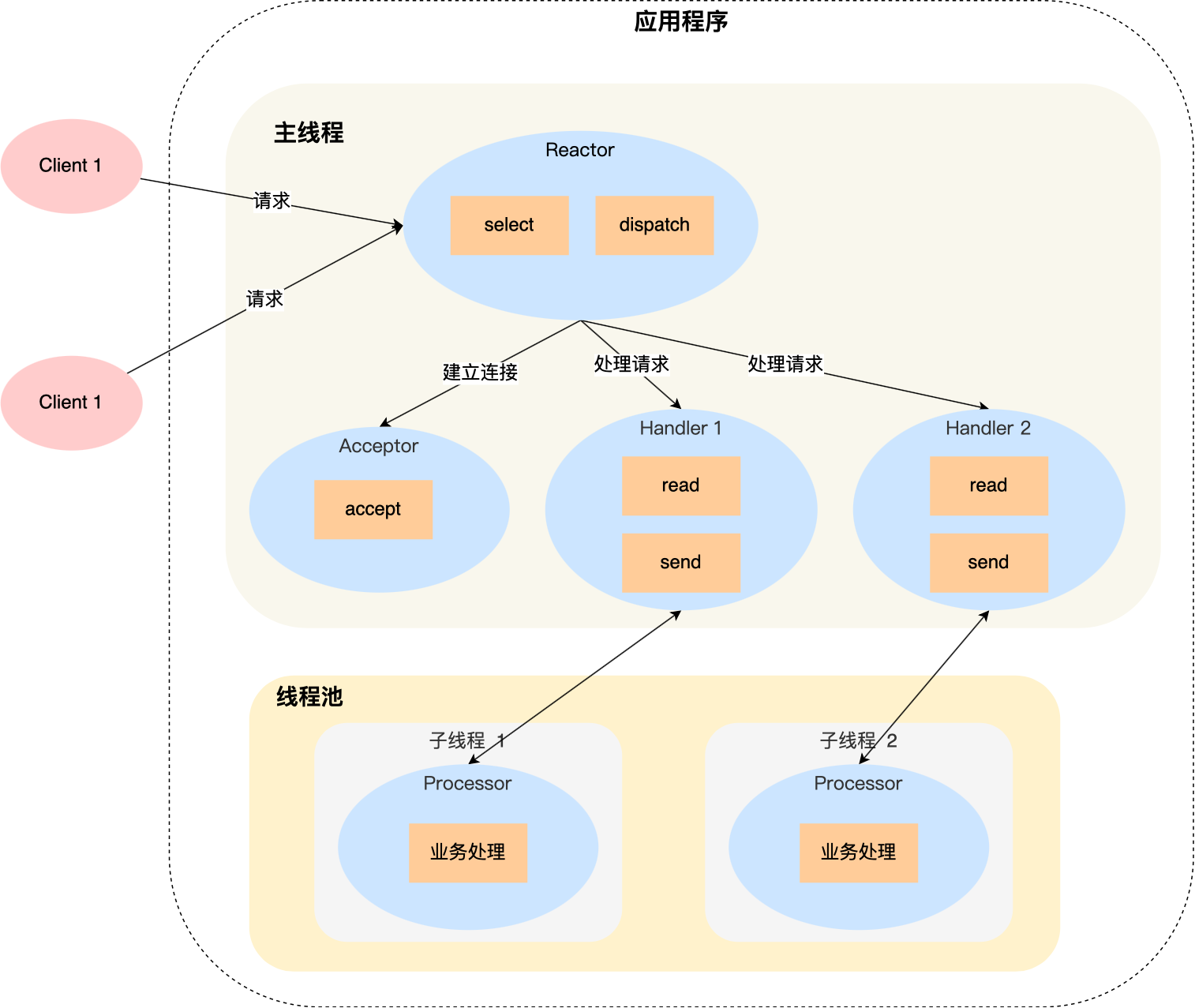
proactor模型
- 通知程序的内容从socket事件变成了,从socket读到了
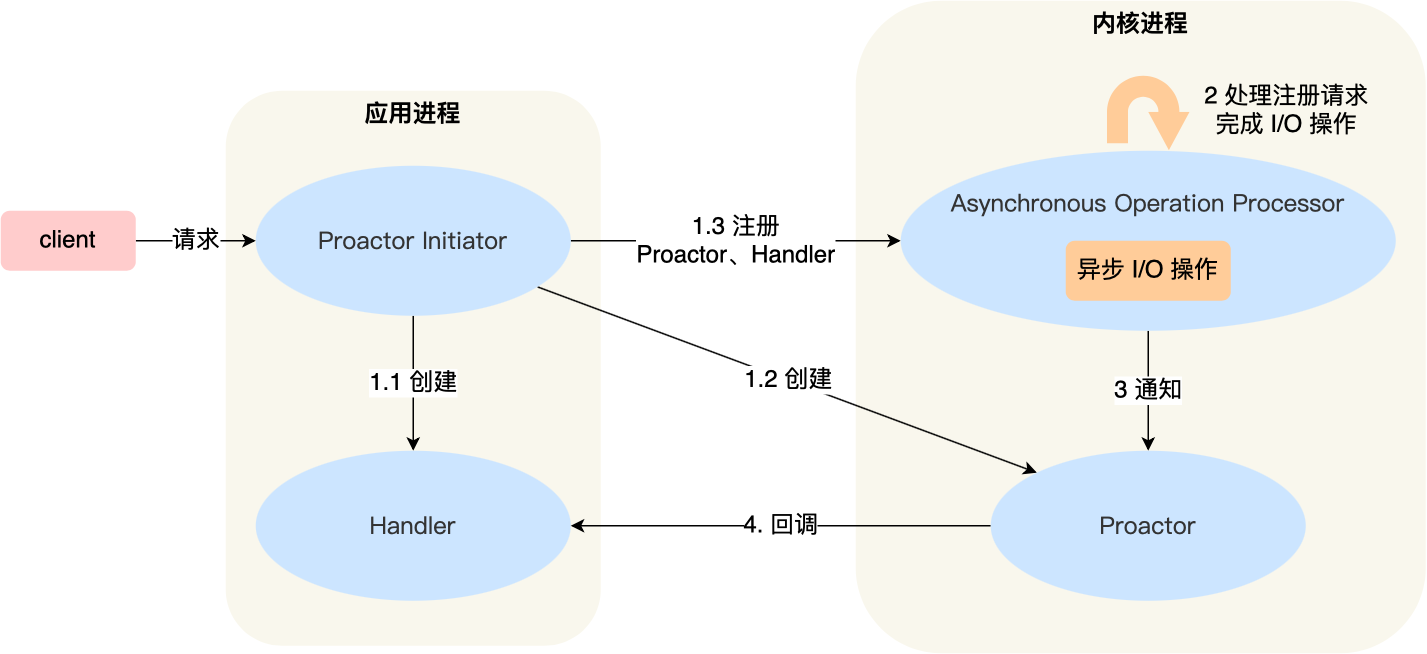
- Reactor 可以理解为「来了事件操作系统通知应用进程,让应用进程来处理」,而 Proactor 可以理解为「来了事件操作系统来处理,处理完再通知应用进程」
- 它是采用异步 I/O 实现的异步网络模型,感知的是已完成的读写事件,而不需要像 Reactor 感知到事件后,还需要调用 read 来从内核中获取数据。
eventfd
- #TODO 补全eventfd
linux文件描述符
- Linux中一个进程访问文件的唯一标识。
设计
- 进程级的文件描述符表:文件描述符表示进程级别的,即每一个进程都会有一张维护其占用FD的表。在进程内部,FD标识即第一列是唯一的。第二列是保存了指向系统级的打开文件描述符表的指针
- 系统级的打开文件描述符表:打开文件描述符表是系统级别的,即整个系统只会保留一份。每一个进程在创建FD之后,都会在这个表里面注册一下。所有的进程FD都可以在这里找到一条对应的记录。分为三列,第一列是FD的状态,即可读,可写还是读写。第二列是当前FD操作的文件索引到哪里了。第三列是一个指向node的指针。
- 文件系统的i-node表:i-node表是文件系统级别的。我们都知道,i-node是存储文件实际元数据的地方,即文件长度等属性。
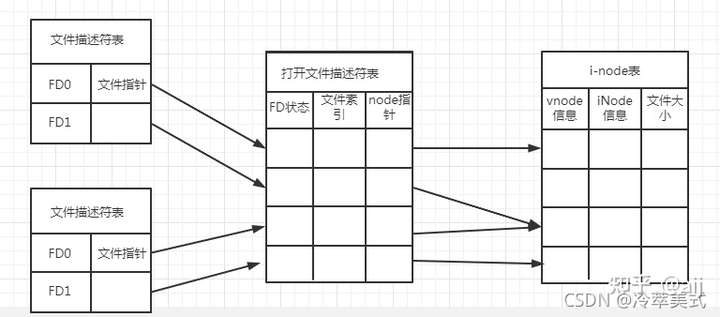
常识性问题
- ==绝对不要带空格文件名,绝对不要用中文作为用户名,绝对不要在目录中出现中文文件夹,最好不要在文件名出现中文==,则只最基本的常识,否则任何软件都可能因为这些报错,记住,英文才是世界通用语言!
参考
- https://cloud.tencent.com/developer/article/1114481
- https://www.cnblogs.com/LUO77/p/5816326.html
网络模型
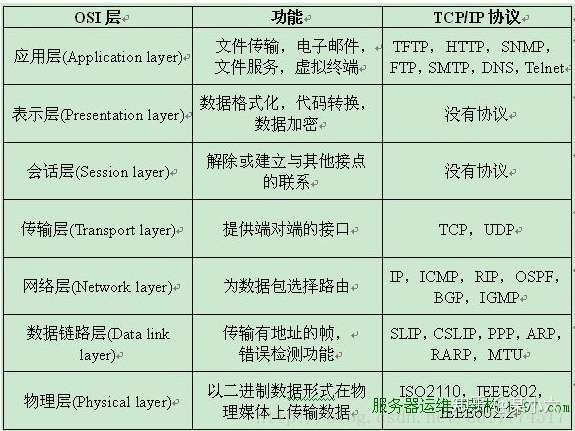
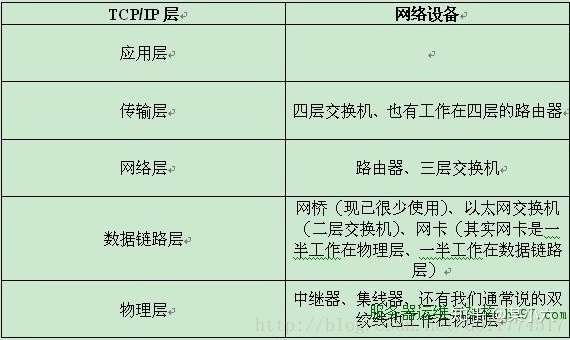

七层模型
- 应用层——–电脑的各种数据
- 表示层 ——– 处理用户信息的表示问题,如编码、数据格式转换和加密解密
- 会话层——–会话管理、会话流量控制、寻址、寻址
- 传输层——–各种协议(TCP/IP中的TCP协议、Novell网络中的SPX协议和微软的NetBIOS/NetBEUI协议。 )
- 网络层——–路由器(通过路由选择算法,为报文或分组通过通信子网选择最适当的路径)
- 数据链路层—-交换机/网桥(负责建立和管理节点间的链路,通过各种控制协议,将有差错的物理信道变为无差错的、能可靠传输数据帧的数据链路)
- 物理层
五层模型
- 应用层
- 传输层
- 网络层
- 数据链路层
- 物理层
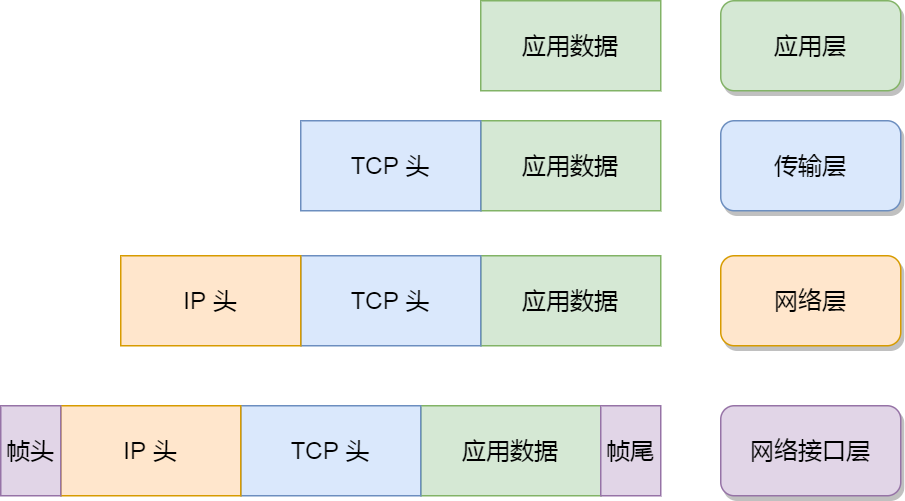
数据格式
- 数据二进制字节流 (Byte) : 物理层传输
- 数据帧(Frame):是一种信息单位,它的起始点和目的点都是数据链路层
- 数据包(Packet):也是一种信息单位,它的起始和目的地是网络层。
- 数据报(Datagram):通常是指起始点和目的地都使用无连接网络服务的的网络层的信息单元。
- 数据段(Segment):通常是指起始点和目的地都是传输层的信息单元。
- 报文 (message) :报文包含了应用层的完整的数据信息。
HTTP
超文本含义
- 超越了普通文本的文本,它是文字、图片、视频等的混合体,最关键有超链接,能从 一个超文本跳转到另外一个超文本
http5新特性
EventStream
- 本质上就是hold住http连接
- 只能服务端给客户端发,不是双向的
- 文本协议
- 参考
HTTPS
- 解决安全性问题
- 参考TLS
状态码分类

http2.0/3.0
1. 头部压缩
- 静态编码成为哈夫曼编码,压缩请求头
2. 二进制格式
- 一条 HTTP 响应,划分成了两类帧(头部和消息体)来传输,并且采用二进制来编码。
3. 数据流并发传输
- 通过一个TCP发送多个请求
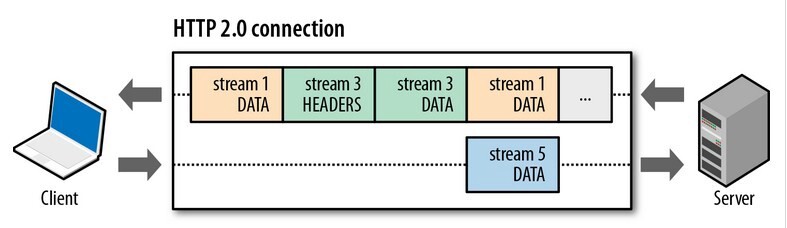
- 一个TCP包含多个stream(这里是类似http1.1的多个tcp请求),每个stream自身保持有序
4. 服务器推送(主动推送css等文件)
- 3.0改成udp连接了,太离谱了
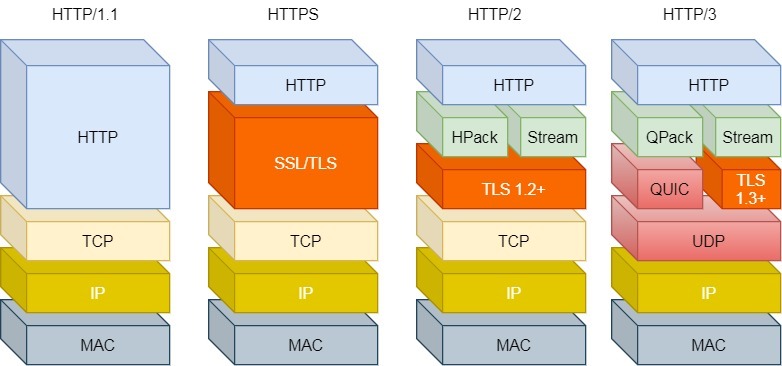
优化方法
- 缓存减少请求
- 合并请求
- 按需访问
- 压缩算法
TCP
- TCP 连接是由四元组唯一确认的,这个四元组就是:本机IP, 本机端口, 对端IP, 对端端口。
定义
- TCP是一种“可靠的、基于连接的流协议”,其中,“可靠”的意思是:(物理网络 正常的前提下)TCP保证用户数据的完整性。完整性本身就包含了顺序等方面的要求。而“流”的意思则是:数据是以字节为单位的,不存在分包概念。
- 会出现丢包现象,但是会自己进行重试,不让用户进行感知
报文格式
三次握手
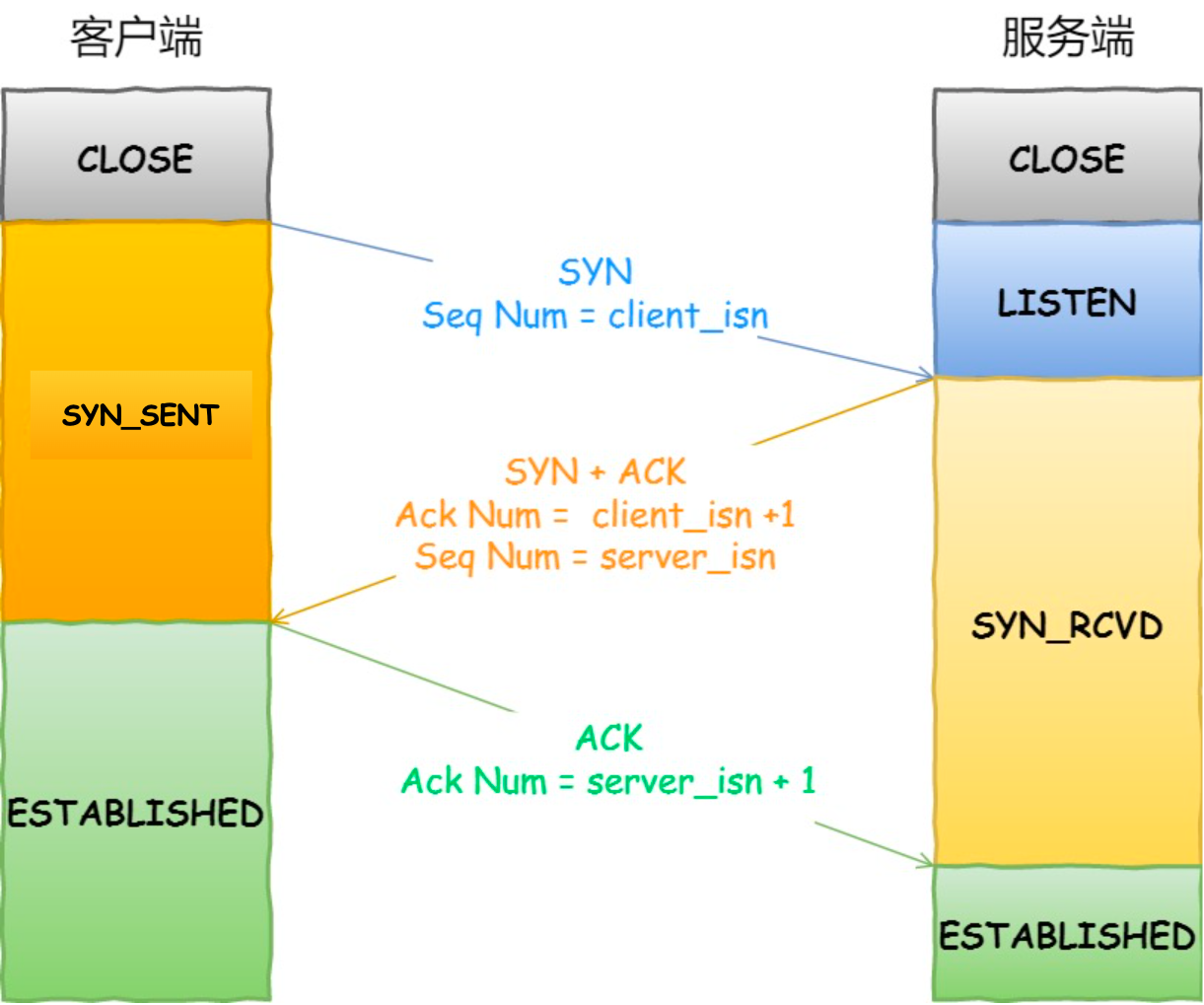
- 第三次握手是可以携带数据的,前两次握手是不可以携带数据的
QA
- 为什么三次握手才可以初始化 Socket、序列号和窗口大小并建立 TCP 连接
- 三次握手才可以阻止重复历史连接的初始化(主要原因),如果只有两次的话,可能网络中存在历史的syn包,然后服务端接受之后发ack成功,实际上并没有成功(使用RES保文方法)
- 三次握手才可以同步双方的初始序列号
- 三次握手才可以避免资源浪费
- 什么是 SYN 攻击?如何避免 SYN 攻击?
- SYN 攻击方式最直接的表现就会把 TCP 半连接队列打满,这样当 TCP 半连接队列满了,后续再在收到 SYN 报文就会丢弃,导致客户端无法和服务端建立连接。
- 解决办法
- 调大 netdev_max_backlog;
- 增大 TCP 半连接队列;
- 开启 tcp_syncookies;
- 减少 SYN+ACK 重传次数
四次挥手
QA
- 为什么挥手需要四次?
- 关闭连接时,客户端向服务端发送
FIN时,仅仅表示客户端不再发送数据了但是还能接收数据。 - 服务端收到客户端的
FIN报文时,先回一个ACK应答报文,而服务端可能还有数据需要处理和发送,等服务端不再发送数据时,才发送FIN报文给客户端来表示同意现在关闭连接。
- 什么时候可以使用三次连接
- 「没有数据要发送」并且「开启了 TCP 延迟确认机制」,那么第二和第三次挥手就会合并传输,这样就出现了三次挥手。
- 为什么需要 TIME_WAIT 状态?
- 保证「被动关闭连接」的一方,能被正确的关闭 >如果客户端(主动关闭方)最后一次 ACK 报文(第四次挥手)在网络中丢失了,那么按照 TCP 可靠性原则,服务端(被动关闭方)会重发 FIN 报文。 >假设客户端没有 TIME_WAIT 状态,而是在发完最后一次回 ACK 报文就直接进入 CLOSE 状态,如果该 ACK 报文丢失了,服务端则重传的 FIN 报文,而这时客户端已经进入到关闭状态了,在收到服务端重传的 FIN 报文后,就会回 RST 报文。
- 为什么 TIME_WAIT 等待的时间是 2MSL?
**TTL 的值一般是 64,Linux 将 MSL 设置为 30 秒,意味着 Linux 认为数据报文经过 64 个路由器的时间不会超过 30 秒,如果超过了,就认为报文已经消失在网络中了**。
TIME_WAIT 等待 2 倍的 MSL,比较合理的解释是: 网络中可能存在来自发送方的数据包,当这些发送方的数据包被接收方处理后又会向对方发送响应,所以**一来一回需要等待 2 倍的时间**。
比如,如果被动关闭方没有收到断开连接的最后的 ACK 报文,就会触发超时重发 `FIN` 报文,另一方接收到 FIN 后,会重发 ACK 给被动关闭方, 一来一去正好 2 个 MSL。
可以看到 **2MSL时长** 这其实是相当于**至少允许报文丢失一次**。比如,若 ACK 在一个 MSL 内丢失,这样被动方重发的 FIN 会在第 2 个 MSL 内到达,TIME_WAIT 状态的连接可以应对。
- 出现大量 TIME_WAIT 状态的原因
- 第一个场景:HTTP 没有使用长连接
- 第二个场景:HTTP 长连接超时
- 第三个场景:HTTP 长连接的请求数量达到上限
保活
- 定义一个时间段,在这个时间段内,如果没有任何连接相关的活动,TCP 保活机制会开始作用,每隔一个时间间隔,发送一个探测报文,该探测报文包含的数据非常少,如果连续几个探测报文都没有得到响应,则认为当前的 TCP 连接已经死亡,系统内核将错误信息通知给上层应用程序。在 Linux 系统中,最少需要经过 2 小时 11 分 15 秒才可以发现一个「死亡」连接
全连接队列和半连接队列
- 半连接队列,也称 SYN 队列;
- 全连接队列,也称 accept 队列;
- 可以存在多个进程accept同一个端口,然后内核会类似生产者消费者唤醒accept函数(这个accept函数实际上是从全连接队列中获取连接的),三次握手发生在内核,和accept解耦且没有关系
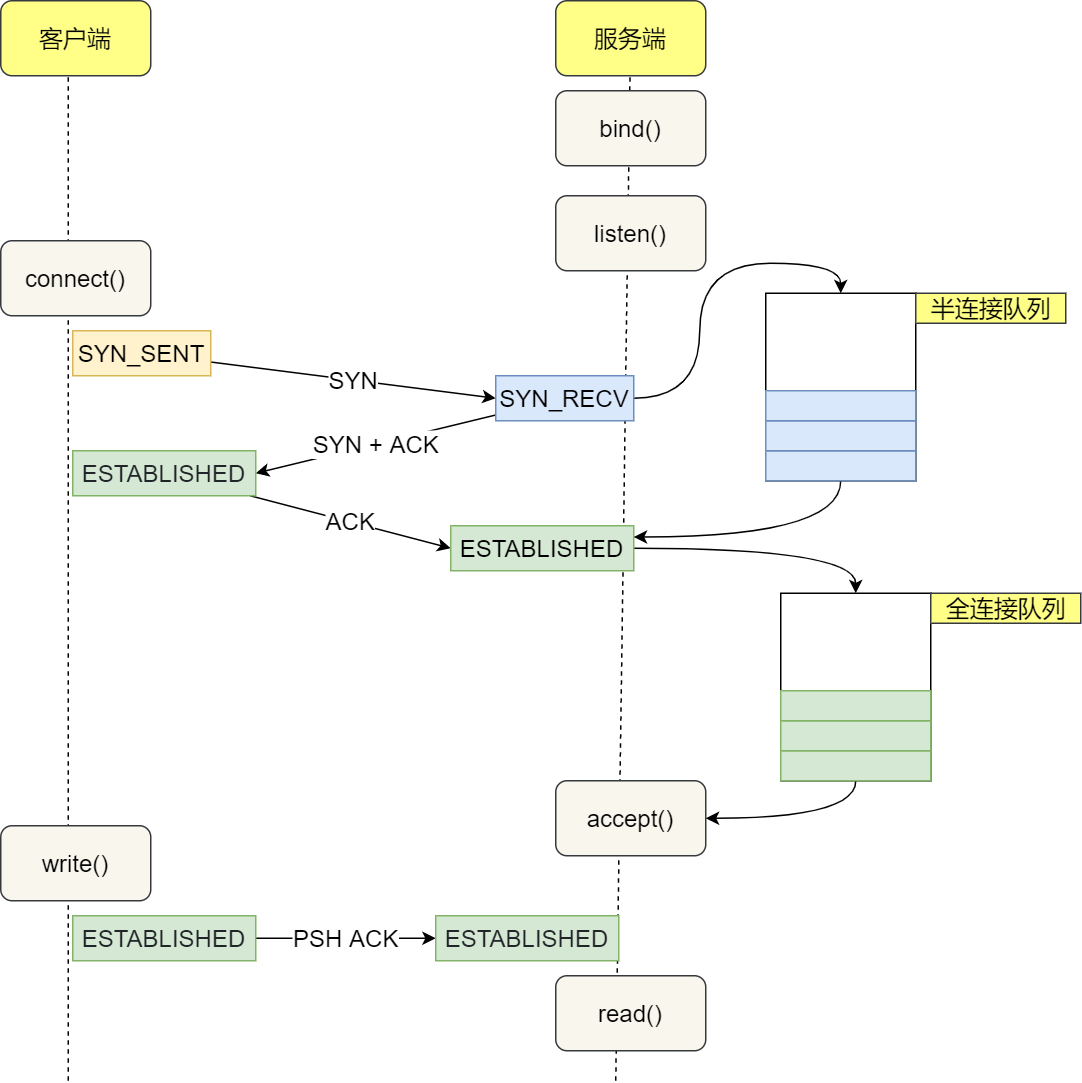
重传机制
RTT和RTO
- RTT(Round Trip Time):一个连接的往返时间,即数据发送时刻到接收到确认的时刻的差值;
- RTO(Retransmission Time Out):重传超时时间,即从数据发送时刻算起,超过这个时间便执行重传。
超时重传
TCP 会在以下两种情况发生超时重传:
- 数据包丢失
- 确认应答丢失
快速重传(FACK算法)
- 快速重传的工作方式是当收到三个相同的 ACK 报文时,会在定时器过期之前,重传丢失的报文段
- 因为可能存在乱序情况(不需要重发),因此三次是比较合适的次数
- 出现不知道缺失了多少的问题
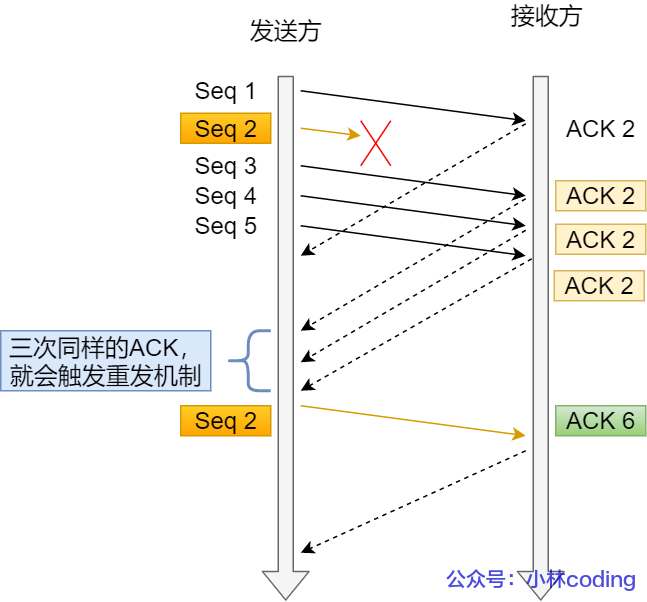
SACK
- 解决快速重传的问题
- 通过ack中携带已经收到的序号
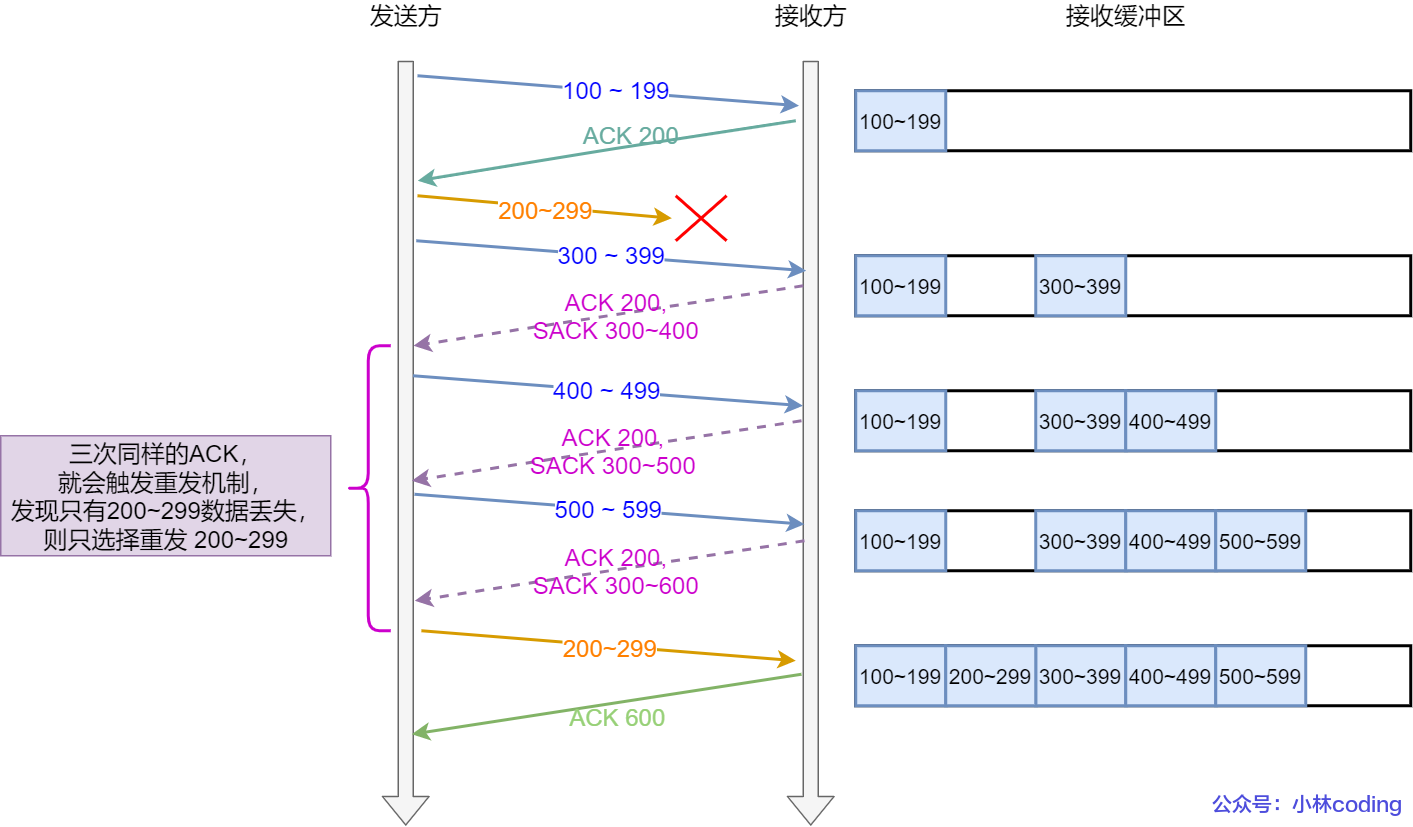
ACK延迟确认机制
- 接收方在收到数据后,并不会立即回复ACK,而是延迟一定时间。一般ACK延迟发送的时间为200ms,但这个200ms并非收到数据后需要延迟的时间。
意义
- 合并ack,减少网络占用
- 接受放有数据的话顺手发送数据带上ACK
滑动窗口
意义
- 进行流量控制,通过控制发送方的发送速率达到流量控制的效果,发送方的发送窗口和接受窗口大小不是严格相等,而是大约相等,而且会动态变化
- 提高丢包容错率,ack某个丢包不影响接受,这个模式就叫累计确认或者累计应答。
- 可以指定窗口大小,窗口大小为无需等待确认应答,而可以继续发送数据的最大值,使得不用漫长等待,提高发送的效率
发送方
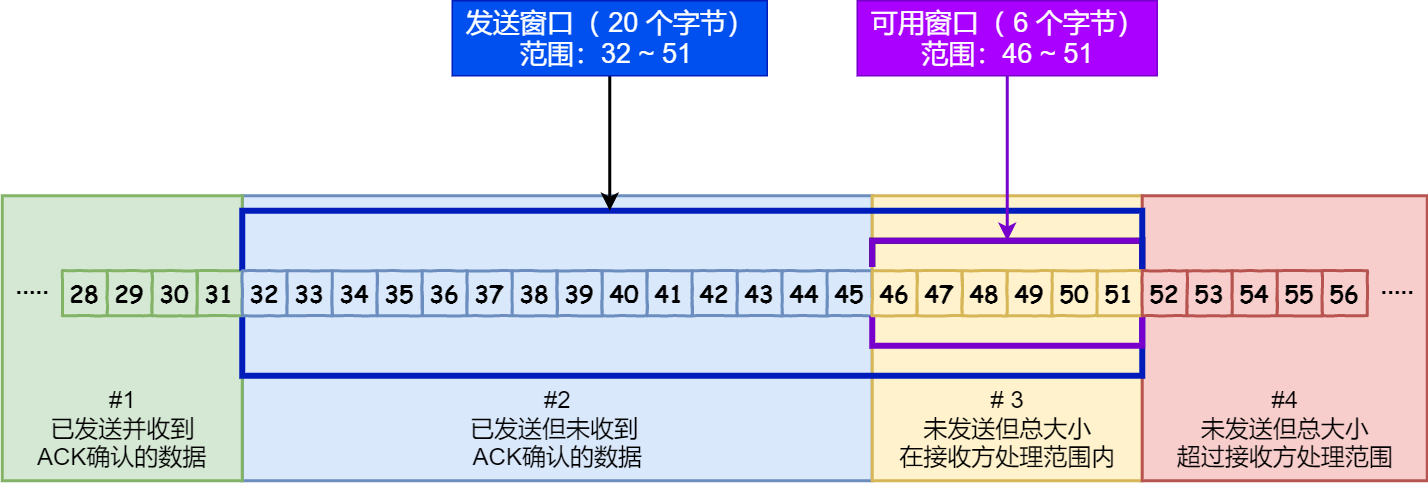
接收方
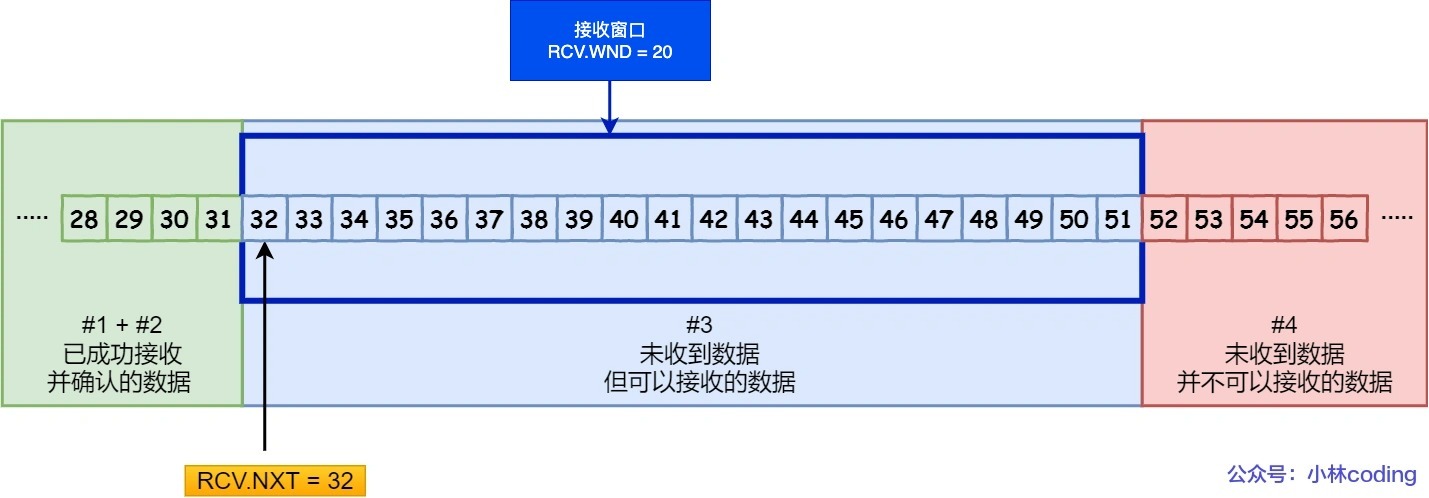
- 如果在红色区域的数据包会直接丢弃,用于流量控制
问题
- 会出现死锁问题,当接受窗口大小为0时候,发送方等待接收方ack才能发,接收方如果此时ack丢失,接受方也在等待发送发继续发送(死锁,相互等待)
解决办法
- 为了解决这个问题,TCP 为每个连接设有一个持续定时器,只要 TCP 连接一方收到对方的零窗口通知,就启动持续计时器。
- 如果持续计时器超时,就会发送窗口探测 ( Window probe ) 报文,而对方在确认这个探测报文时,给出自己现在的接收窗口大小。
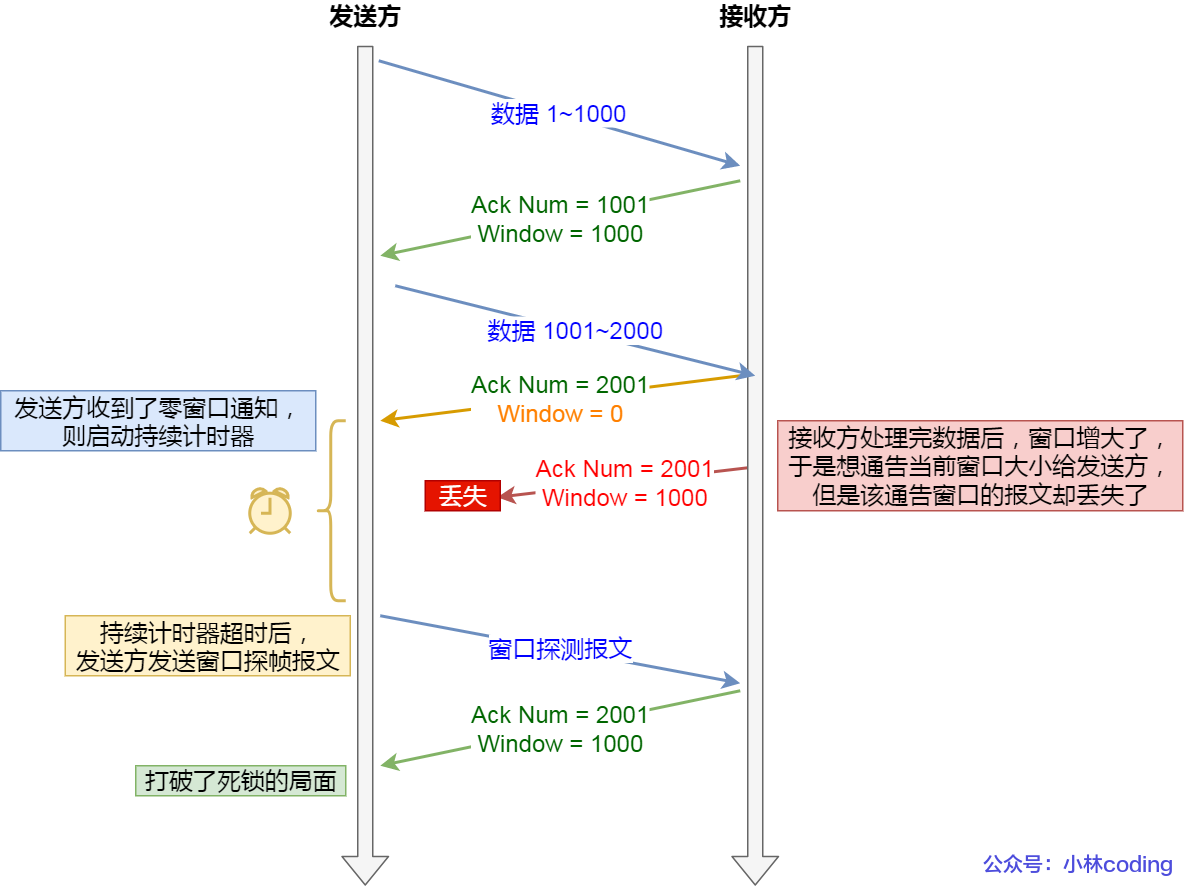
流量控制
- 通过滑动窗口大小的变化达到动态控制流量
- 发送方接受到的ack包含接收端窗口的大小(这部分的大小是不去要确认也可以发送的大小)
- 如果接收端发现自己的缓冲区快满了,就可以通过ack包头中设置减少发送窗口的大小
拥塞控制
- 通过拥塞窗口大小达到控制,只在发送端存在,控制发送端的发送窗口大小,拥塞窗口 cwnd是发送方维护的一个的状态变量,它会根据网络的拥塞程度动态变化的
- 此时发送窗口的值是swnd = min(cwnd, rwnd),也就是拥塞窗口和接收窗口中的最小值。
慢启动
- 一开始窗口大小设置为1,当ack则加倍,直到到达慢启动门限
拥塞避免算法
- 到慢启动门限之后,每个ack加一,如果出现丢包拥塞,慢启动门限减半
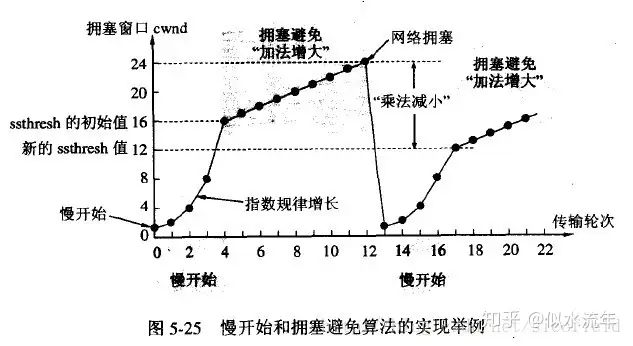
快速重传
- 对某个报文发出3个ack代表需要,发送端对该报文重发
流量控制和拥塞控制的区别
- 拥塞控制是作用于网络的,它是防止过多的数据注入到网络中,避免出现网络负载过大的情况;常用的方法就是:(1)慢开始、拥塞避免(2)快重传、快恢复.
- 流量控制:流量控制是作用于接收者的,它是控制发送者的发送速度从而使接收者来得及接收,防止分组丢失的。
- 目的不同:流量控制主要关注发送方和接收方之间的数据传输速率,确保接收方能够处理接收到的数据;而拥塞控制主要关注网络中的拥塞程度,避免网络拥塞和保持网络的稳定性。
- 控制对象不同:流量控制是在发送方和接收方之间进行控制,通过滑动窗口机制实现;拥塞控制是在网络中进行控制,通过监测网络拥塞程度和调整发送方的数据传输速率实现。
- 两者都可以控制发送端的发送窗口大小
UDP
报文格式
socket编程
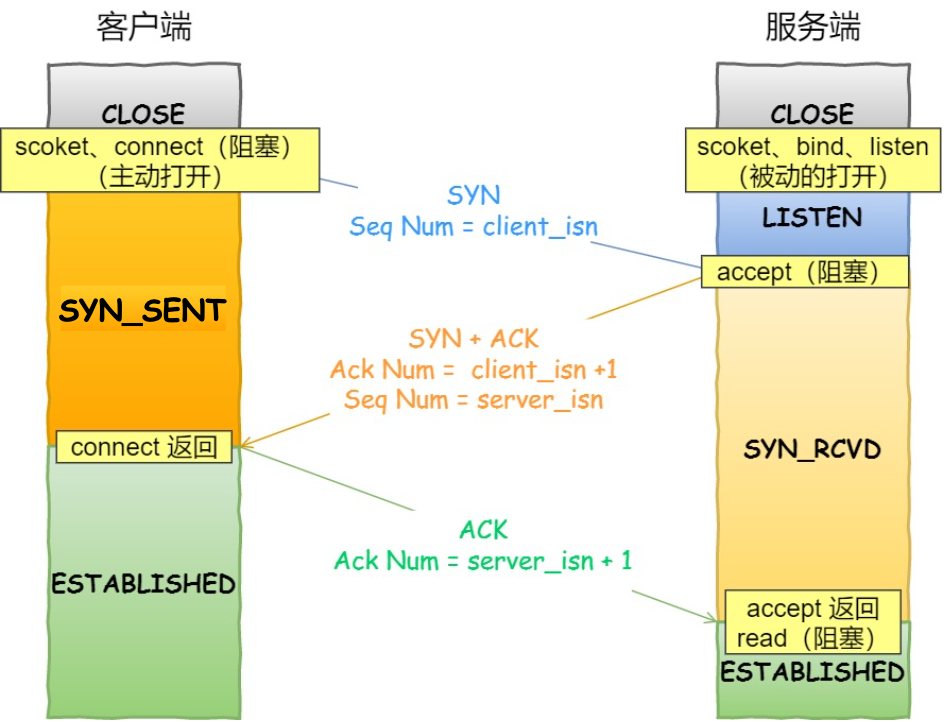
backlog作用
- TCP 和 UDP 是可以同时绑定同一个端口号的
IP
头部信息
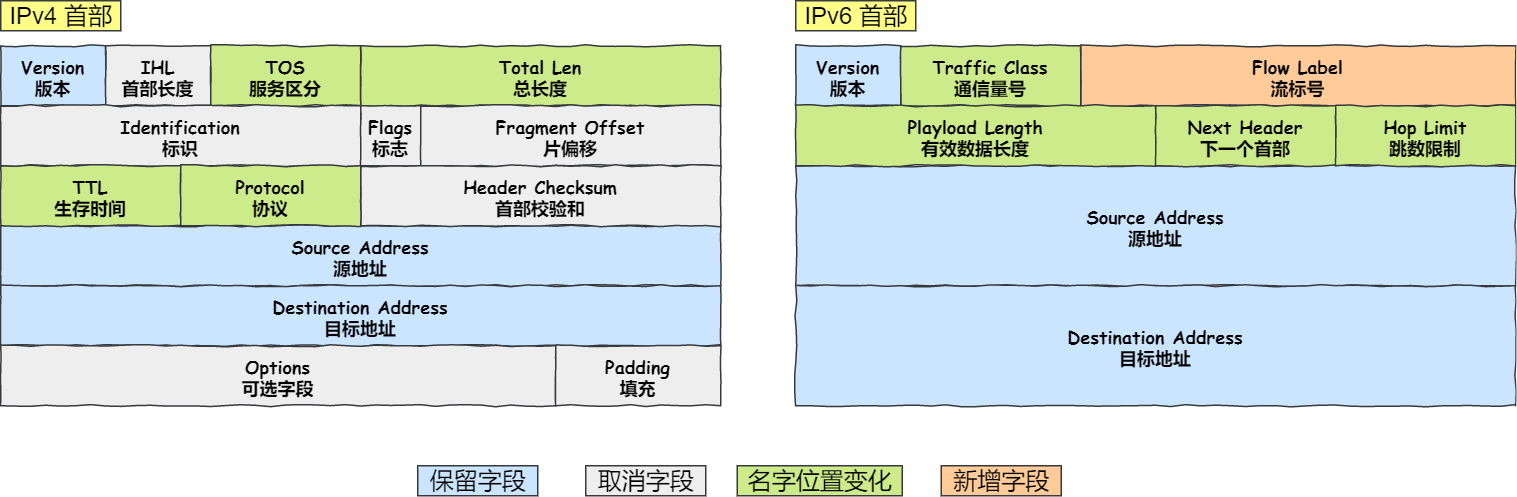
- 每次传播,TTL和checksums都会改变
ip地址分类
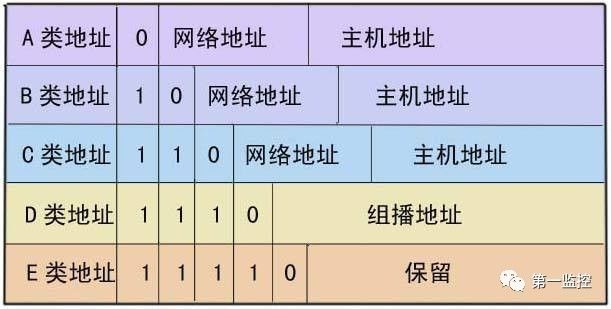
[!important] 127.0.0.1 和 0.0.0.0 区别 通常网络程序bind host的时候 127表示只能通过本地访问(127或者localhost),不接受其他ip访问,0.0.0.0代表接受所有的ip访问
ARP
- 在传输一个 IP 数据报的时候,确定了源 IP 地址和目标 IP 地址后,就会通过主机「路由表」确定 IP 数据包下一跳。然而,网络层的下一层是数据链路层,所以我们还要知道「下一跳」的 MAC 地址。
- 由于主机的路由表中可以找到下一跳的 IP 地址,所以可以通过 ARP 协议,求得下一跳的 MAC 地址。
- 网络层协议
DHCP
- 通过 DHCP 动态获取 IP 地址
- 全程都是使用 UDP 广播通信,应用层协议
ICMP
ICMP主要的功能包括:确认 IP 包是否成功送达目标地址、报告发送过程中 IP 包被废弃的原因和改善网络设置等。- 网络层协议,一般认为属于IP层协议
- ping命令使用的协议
ping流程
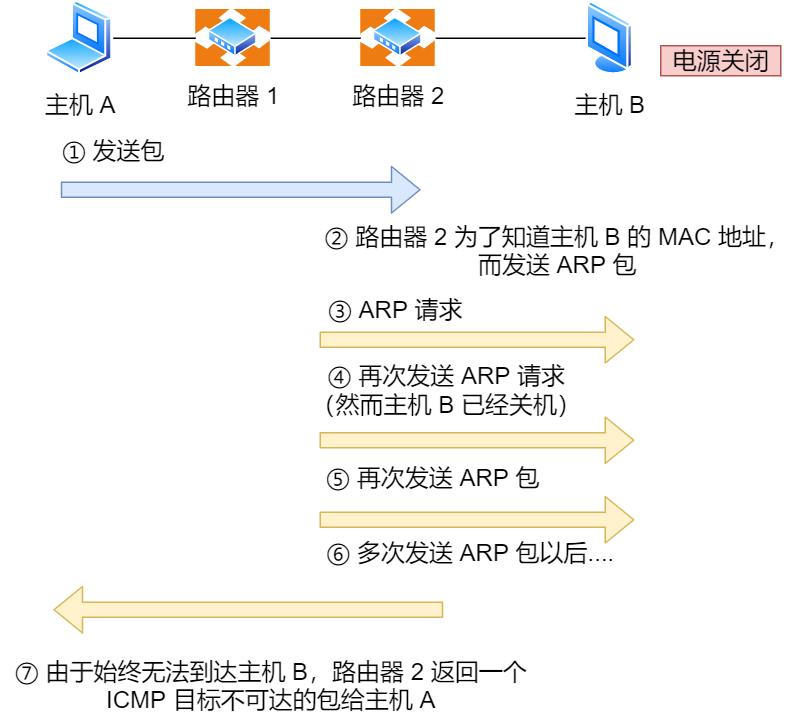
网卡
- 网卡是电脑的一个接收信息,转换信息,暂储信息的一个硬件,通常虚拟化,如docker0
- 同一个网卡下程序可以直接通讯
八股
get和post的区别
- post更安全(不会作为url的一部分,不会被缓存、保存在服务器日志、以及浏览器浏览记录中)
- post发送的数据更大(get有url长度限制)
- post能发送更多的数据类型(get只能发送ASCII字符)
- post比get慢
- post用于修改和写入数据,get一般用于搜索排序和筛选之类的操作
session,cookie和token区别
- Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;
- Cookie是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
- Token类似一个令牌,无状态,用户信息都被加密到token中,服务器收到token后解密就可知道是哪个用户。需要开发者手动添加。
有了http为什么还需要rpc
- http的报文是明文状态,导致很长,传输效率不够高,相当于不够专业,因此大部分使用类似protobuf压缩,性能更加好
- http是一种应用层的协议,而rpc是一种调用方式,有的rpc底层分装的也是http
参考
计算机结构
冯诺依曼结构
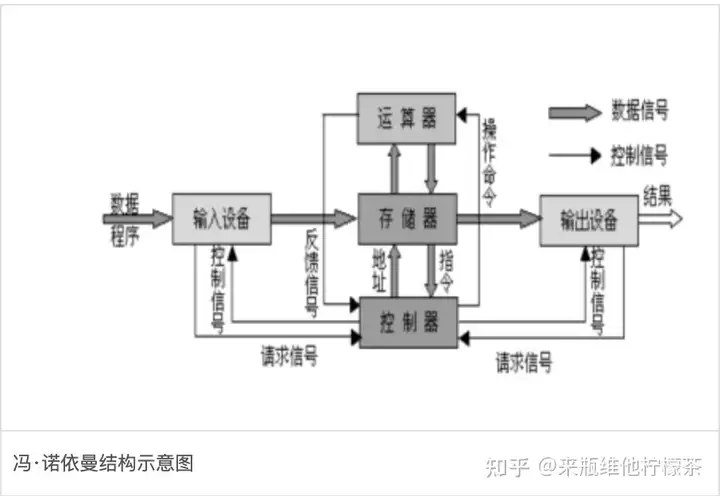

- ==一种将程序指令存和数据一起存储的计算机结构。 该结构隐约指导了将储存装置与中央处理器分开的概念==
设计
- CA(Central Arithmetical)
- 算数单元,当时的计算机主要面向复杂的数值计算,ENIAC/EDVAC的设计初衷都是是为了计算弹道,早期计算机大部分都是为了完成复杂计算而设计制造。
- CC(Central Control)
- 逻辑控制单元,指令的执行,异常的处理,I/O处理等,除了计算以外的所有事情都需要处理,这些都交给了逻辑控制单元。
- M(Memory)
- 比如多级计算需要存储中间数据,执行计算用到的程序,算数单元获取的计算数据等等都需要一个设备来存储,一个内存设备是必要的。
- 为了完成计算,必须将外部数据输入到计算机内部,以及计算完成后将结果输出,因此还需要两个设备,即输入设备和输出设备,以及记录这些输入/输出数据的存储设备。
[!important] 因为冯诺依曼架构数据和程序放置在一起,使得可能出现缓冲区溢出的攻击行为,通过溢出的缓冲区更改程序的执行
哈弗结构

- ==将程序指令和数据分开存储==,减轻程序运行时的访存瓶颈。
混合结构
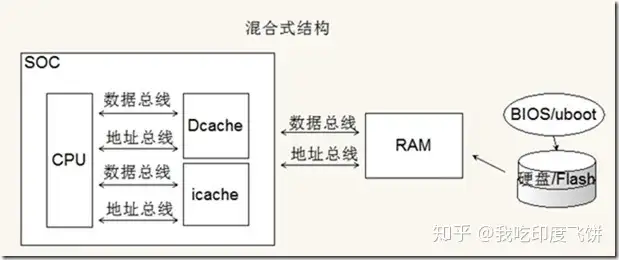
- 程序和数据地址空间隔离,但可以从程序地址空间读取数据
- 程序和数据地址共享,将程序和数据的缓存分开
当代处理器中将存储单元分为两层,第一层接近CC(控制单元)的存储单元中,将指令和数据存储分开,但是地址空间并不隔离(即程序/数据缓存),与哈佛结构的最大不同就是程序和数据地址空间共用,第二层存储单元为程序和数据共用,采用冯诺伊曼结构,只有在缓存失效时才会访问第二层,不能并行。在一定程度上解决了冯诺伊曼瓶颈,同时兼顾了存储利用率的最大化。
区别
- 冯诺依曼结构有一个存储器,指令和数据存储在该存储器,且只有一条总线用于存取数据。
- 哈佛结构有两个存储器,指令和数据分别存储在指令存储器和数据存储器,有两条总线用于存取数据。可以同时访问指令和数据,效率更高,但是成本更高,开发成本更高
目前
- 大部分单片机使用哈弗结构
- 大部分嵌入式/商用处理器如arm/x86等在L2/L3缓存、内存这一段使用冯诺依曼
你不会为一台电脑购买2倍内存条,一个分给指令存储,一个分给数据存储 操作系统要设计2套内存管理,一套管理指令内存,一套管理数据存储 程序员不用为某个数据到底应该存储在指令内存还是数据内存中而争论
[!quote] 实际上在内存里,指令和数据是在一起的。而在CPU内的缓存中,还是会区分指令缓存和数据缓存,最终执行的时候,指令和数据是从两个不同的地方出来的。你可以理解为在CPU外部,采用的是冯诺依曼模型,而在CPU内部用的是哈佛结构。
大部分的DSP都没有缓存,因而直接就是哈佛结构。
哈佛结构设计复杂,但效率高。冯诺依曼结构则比较简单,但也比较慢。CPU厂商为了提高处理速度,在CPU内增加了高速缓存。也基于同样的目的,区分了指令缓存和数据缓存。
从沙子到cpu
沙子
- 主要成分是SiO2(二氧化硅)
半导体
- 是常温下导电性能介于导体与绝缘体之间的材料。硅是种常见的半导体,硅本身不带电荷(因为正好4个平衡)
- 半导体的关键,是可变性,能在绝缘体与导体之间转化。抽象一点,就是具备对立转化的潜质,得益于电压电场的加持,半导体完成了第二轮对立转化
二极管
- 正向导通,反向阻断
- 向硅中掺杂如N和P,分为两边,使得带不同电荷,如果电流方向和内建电场相同,嘛呢就是导体,不同就变成绝缘体,依赖了硅本身是报到题不带电荷,掺杂电荷形成内部电场的特性
- P是提供电子的,N是接受电子的
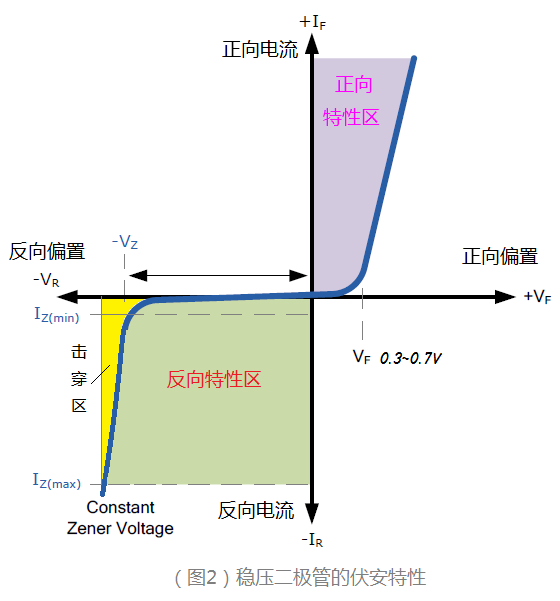
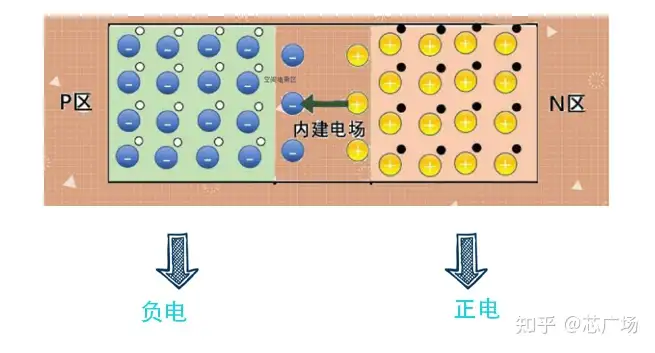
三极管
- 使用P结和N结构成
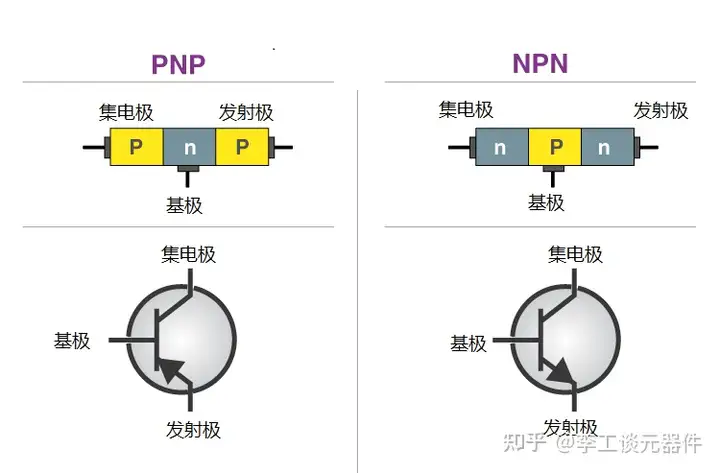
状态
截止状态
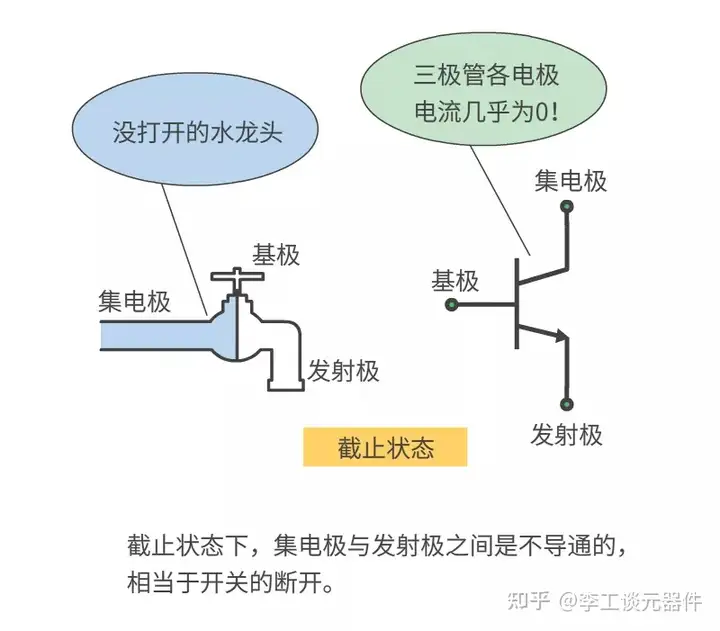
放大状态
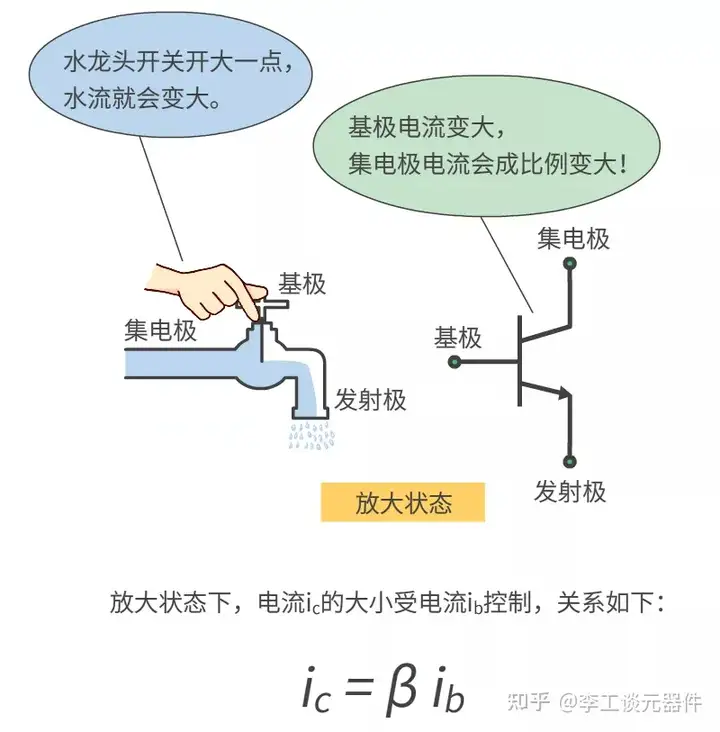
饱和状态
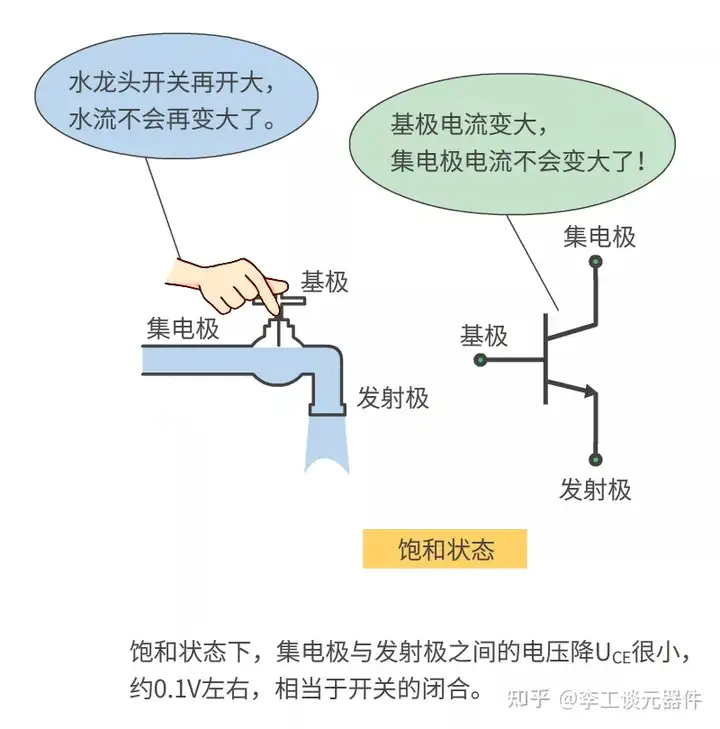
功能特性
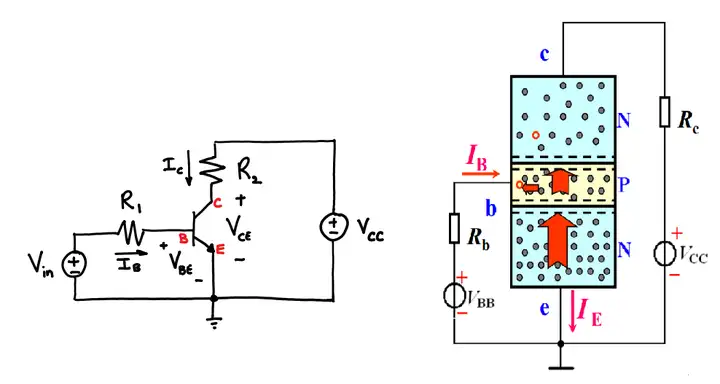
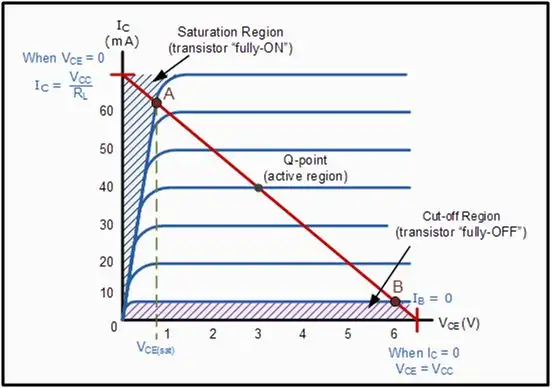

作用
- 三极管在电路中最常用作开关。用作开关时的工作原理:
- 基极是控制端,根据三极管种类是NPN还是PNP,来给基极高电平或者低电平,那么三极管的CE两极就会导通。三极管的工作原理类似于水龙头控制水管通断。
- 相当于使用Ib控制开关,开了之后,电流就是根据Ib决定Ic电流,饱和之后Ib就不变了
- 晶体三极管具有电流放大作用,其实质是三极管能以基极电流微小的变化量来控制集电极电流较大的变化量
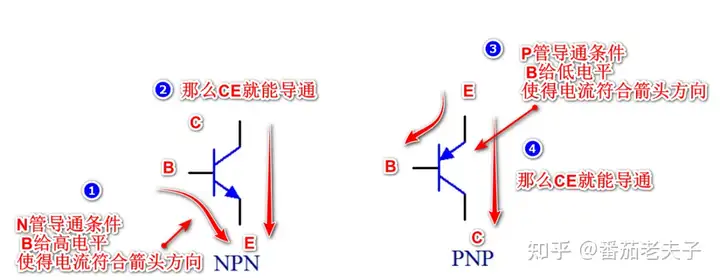
门电路
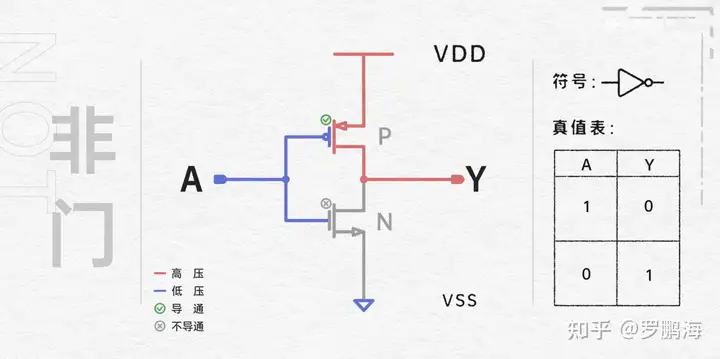
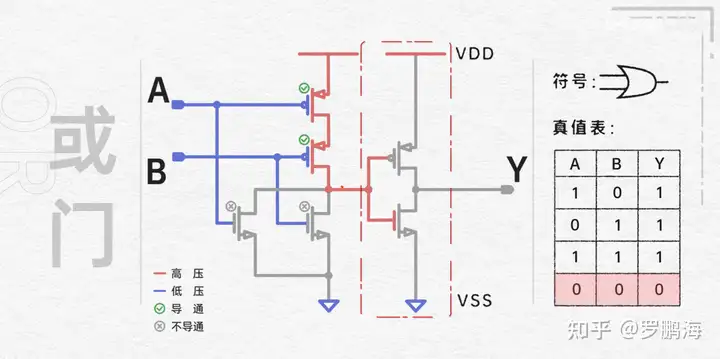
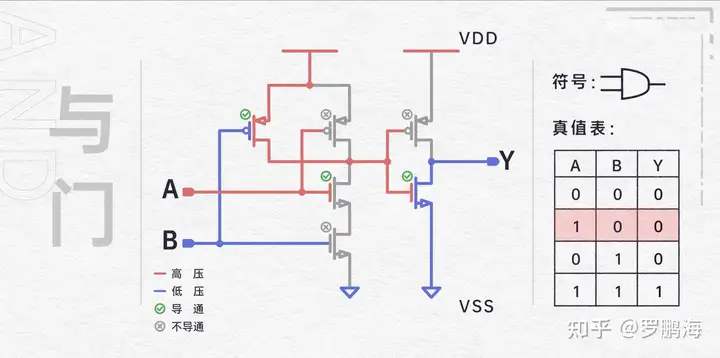
- 使用三极管构成简单的门电路,使用门电路就可以构成加法器
触发器

- 根据输入决定下一阶段的输出,下一阶段是指脉冲的时间,在状态机中经常使用,底层使用门电路.触发器的转移特性决定了它可以很好作为cpu流水线的底层,也是异步电路的基础
- 实际上就是多个锁存器的组装

CPU
- 计算机执行指令的过程可以分为以下三个步骤:
- Fetch(取指),也就是从 PC 寄存器里找到对应的指令地址,根据指令地址从内存里把具体的指令,加载到指令寄存器中,然后把 PC 寄存器自增,好在未来执行下一条指令。
- Decode(译码),也就是根据指令寄存器里面的指令,解析成要进行什么样的操作,是 R、I、J 中的哪一种指令,具体要操作哪些寄存器、数据或者内存地址。
- Execute(执行指令),也就是实际运行对应的 R、I、J 这些特定的指令,进行算术逻辑操作、数据传输或者直接的地址跳转。
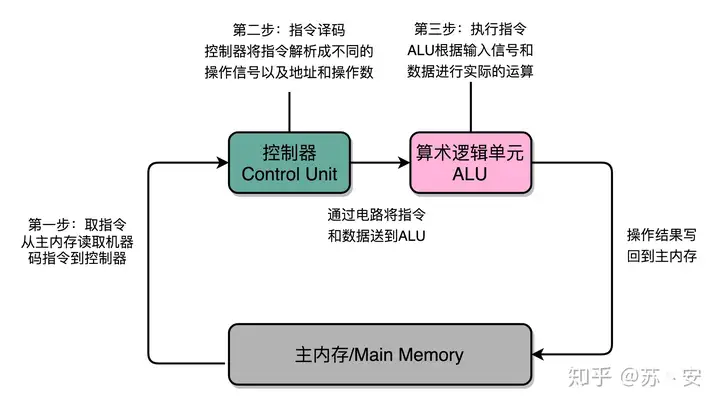
周期
时钟周期
- 又称振荡周期,是处理操作的最基本单位。
- 这个是晶振的周期经过放大之后得到的时钟发生器的频率
- 这个周期是流水线的周期,嘀嗒一下状态机向前推进一个,因此周期越短,执行越快,但是发热也越厉害
指令周期
- 取出并执行一条指令的时间。
CPU周期
- 一条指令执行过程被划分为若干阶段,每一阶段完成所需时间。
流水线
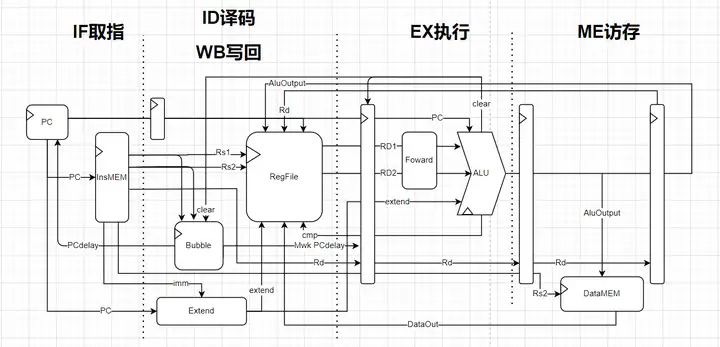
- 取指:将指令从存储器中读取出来的过程。
- 译码:从存储器中取出的指令进行翻译的过程.经过译码之后得到指令需要的操作数寄存器索引,可以使用此索引从通用寄存器组(Register File, Regfile )中将操作数读出。
- 执行:指令执行是指对指令进行真正运算的过程
- 访存:存储器访问指令将数据从存储器中读出,或者写入存储器的过程。
- 写回:将指令执行的结果写回通用寄存器组的过程
- 因为一条指令的多个阶段,因此为了提高计算速率,将每个组件和步骤都组装成时序异步电路,这部分的状态转移用的就是触发器,类似
总结
- 通过沙子提炼Si得到半导体
- 半导体加上PN得到二极管和三极管
- 二极管和三极管组合得到基础的门电路(与或非门)
- 门电路构成了锁存器,锁存器有构成了触发器
- 触发器构成了流水线,流水线周期是时钟周期
[!tip] 参考 https://zhuanlan.zhihu.com/p/144345863 https://zhuanlan.zhihu.com/p/519072786 深入了解计算机系统
设计模式
- 核心目的是高内聚,低耦合,增强代码的扩展性和结构性
UML
UML关系图
demo

- 箭头上的数字代表 1 个学生可以不参加课程,也可以无限制参加各种课程
- 1 代表一个,0..* 代表 0 个到无限个
[!important] 多重性 多重性应用于关联的目标端,说明源类的每个实例与目标类实例的连接个数。 0..*:0个或多个 3..7:指定范围(3~7个,包含3和7)
依赖
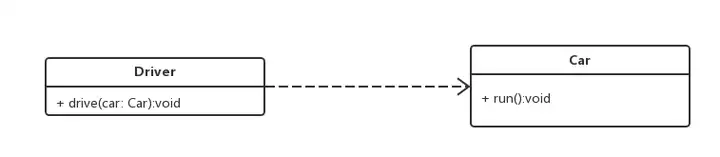
- 对于两个相对独立的对象,当一个对象负责构造另一个对象的实例,或者依赖另一个对象的服务时,这两个对象之间主要体现为依赖关系。
- 类 A 使用到了类 B,而这种使用关系具有偶然性,临时性,非常弱的,但是 B 类中的变化会影响到类 A
[!example] 你是一名出租车司机,每天开着公司给你分配的车去载客,而每天出租车可能不同,我只是个司机,公司给我什么车我就开什么车,我使用这个车。
关联

- 对于两个相对独立的对象,当一个对象的实例与另一个对象的一些特定实例存在固定的对应关系时,这两个对象之间为关联关系。双向关联的话箭头可以省略。
- 两个类中一种强依赖关系,比如我和我的朋友,这种关系比依赖更强,不存在依赖关系中的偶然性,关系也不是临时的,一般是长期性的。
[!example] 我是一名老司机,车是我自己的,我拥有这辆车,平时也会用着辆车去载客人。
聚合
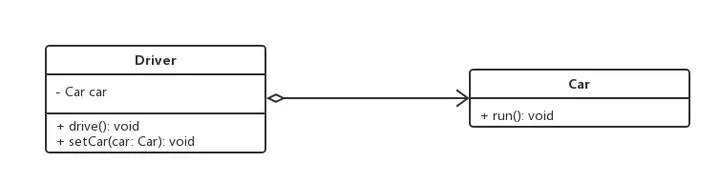
- 聚合关系是关联关系的一种,耦合度强于关联,他们的代码表现是相同的,仅仅是在语义上有所区别:关联关系的对象间是相互独立的,而聚合关系的对象之间存在着包容关系,他们之间是“整体-个体”的相互关系。
- 聚合关系中作为成员变量的类一般使用 set 方法赋值
[!quote] 依赖:用完就扔。
关联,聚合:不属于我,但是用完先放着。
组合:是我的一部分,用完保存好。
组合
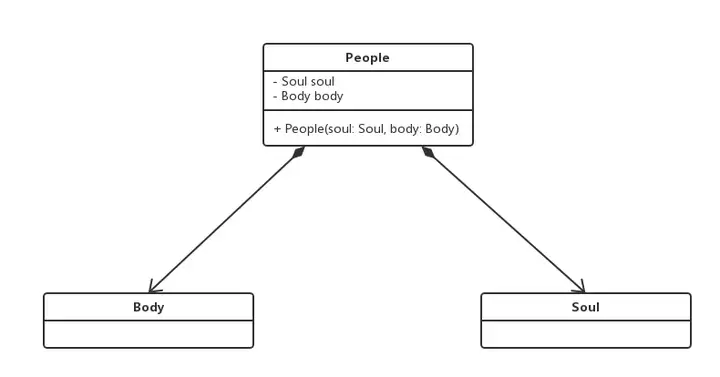
- 相比于聚合,组合是一种耦合度更强的关联关系。存在组合关系的类表示“整体-部分”的关联关系,“整体”负责“部分”的生命周期,他们之间是共生共死的;并且“部分”单独存在时没有任何意义。
[!example] 人和灵魂,身体之间是组合关系,当人的生命周期开始时,必须同时拥有灵魂和肉体,当人的生命周期结束时,灵魂肉体随之消亡;无论是灵魂还是肉体,都不能单独存在,他们必须作为人的组成部分存在。
继承
实现
[!tip] 参考 https://zhuanlan.zhihu.com/p/24576502
六大原则
开闭原则
- 总原则
- 对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有的代码,而是要扩展原有代码,实现一个热插拔的效果
单一职责原则
- 不要存在多于一个导致类变更的原因,也就是说每个类应该实现单一的职责,如若不然,就应该把类拆分。
里氏替换原则
- 最基础的原则,是实现的底层基础
- 父类出现的地方,子类一定可以出现.任何基类可以出现的地方,子类一定可以出现
依赖倒转原则
- 这个是开闭原则的基础,具体内容:面向接口编程,依赖于抽象而不依赖于具体。写代码时用到具体类时,不与具体类交互,而与具体类的上层接口交互。相当于行为准则
合成复用原则
- 原则是尽量首先使用合成/聚合的方式,而不是使用继承。
最少知道原则
- 类出现就应该遵守的基本原则
- 一个类对自己依赖的类知道的越少越好。也就是说无论被依赖的类多么复杂,都应该将逻辑封装在方法的内部,通过public方法提供给外部。这样当被依赖的类变化时,才能最小的影响该类。
创建型模式
这部分模式用于创建对象
单例模式
- 底层的实质是需要规定某个对象全局只能初始化一次
懒汉模式
- 存在内存泄漏问题(使用智能指针或者嵌套类)
- 多线程下多个线程可能同时拿到(加锁)
// version 1.0
class Singleton
{
private:
static Singleton* instance;
private:
Singleton() {};
~Singleton() {};
Singleton(const Singleton&);
Singleton& operator=(const Singleton&);
public:
static Singleton* getInstance() {
if(instance == NULL)
instance = new Singleton();
return instance;
}
};
// init static member
Singleton* Singleton::instance = NULL;
饿汉模式
// version 1.3
class Singleton
{
private:
static Singleton instance;
private:
Singleton();
~Singleton();
Singleton(const Singleton&);
Singleton& operator=(const Singleton&);
public:
static Singleton& getInstance() {
return instance;
}
}
// initialize defaultly
Singleton Singleton::instance;
Best
- 通过static的形式
// version 1.2
class Singleton
{
private:
Singleton() { };
~Singleton() { };
Singleton(const Singleton&);
Singleton& operator=(const Singleton&);
public:
static Singleton& getInstance(){
static Singleton instance;
return instance;
}
};
工厂模式
简单工厂
[!question] 工厂模式问题 会遇到比如某些工厂余姚设置某些特别的属性时候不能够通用的问题,虽然可以通过static 设置但是不够优雅
- 本质是调用时候不需要使用调用类的名字,而是使用一个枚举变量就创建类,返回值是一个抽象的父类指针
- 优点是这样只需要一个枚举就能创建不同的对象,创建的函数中可以进行具体的操作,将实际的功能的类和创建的类彻底分开
enum CTYPE {COREA, COREB};
class SingleCore{
public:
virtual void Show() = 0;
};
//单核A
class SingleCoreA: public SingleCore{
public:
void Show() { cout<<"SingleCore A"<<endl; }
};
//单核B
class SingleCoreB: public SingleCore{
public:
void Show() { cout<<"SingleCore B"<<endl; }
};
//唯一的工厂,可以生产两种型号的处理器核,在内部判断
class Factory{
public:
SingleCore* CreateSingleCore(enum CTYPE ctype){
if(ctype == COREA) //工厂内部判断
return new SingleCoreA(); //生产核A
else if(ctype == COREB)
return new SingleCoreB(); //生产核B
else
return NULL;
}
};
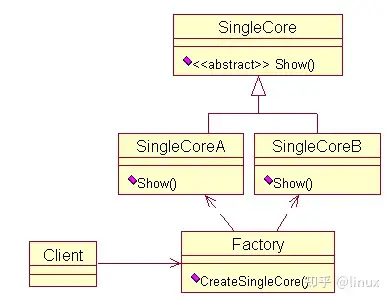
抽象工厂和工厂方法
- 工厂方法是简单工厂的升级模式,用于在多个成系列的产品需要一起创造的时候,使用一个工厂生产==一个系列的产品==
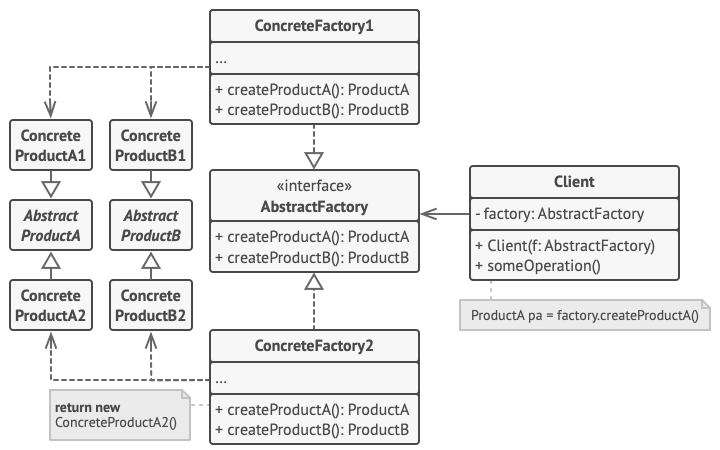
# 程序会根据当前配置或环境设定选择工厂类型,并在运行时创建工厂(通常在初
# 始化阶段)。
class ApplicationConfigurator is
method main() is
config = readApplicationConfigFile()
if (config.OS == "Windows") then
factory = new WinFactory()
else if (config.OS == "Mac") then
factory = new MacFactory()
else
throw new Exception("错误!未知的操作系统。")
Application app = new Application(factory)
建造者模式
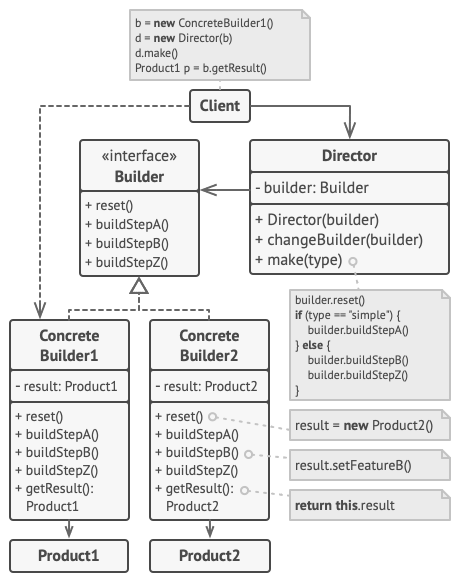
- 用于与解决复杂对象的构建,实质上就是分开不同的步骤,在加上一个指挥类负责调用函数构建
class Builder
{
public:
virtual void BuildHead() {}
virtual void BuildBody() {}
virtual void BuildLeftArm(){}
virtual void BuildRightArm() {}
virtual void BuildLeftLeg() {}
virtual void BuildRightLeg() {}
};
//构造瘦人
class ThinBuilder : public Builder
{
public:
void BuildHead() { cout<<"build thin body"<<endl; }
void BuildBody() { cout<<"build thin head"<<endl; }
void BuildLeftArm() { cout<<"build thin leftarm"<<endl; }
void BuildRightArm() { cout<<"build thin rightarm"<<endl; }
void BuildLeftLeg() { cout<<"build thin leftleg"<<endl; }
void BuildRightLeg() { cout<<"build thin rightleg"<<endl; }
};
//构造胖人
class FatBuilder : public Builder
{
public:
void BuildHead() { cout<<"build fat body"<<endl; }
void BuildBody() { cout<<"build fat head"<<endl; }
void BuildLeftArm() { cout<<"build fat leftarm"<<endl; }
void BuildRightArm() { cout<<"build fat rightarm"<<endl; }
void BuildLeftLeg() { cout<<"build fat leftleg"<<endl; }
void BuildRightLeg() { cout<<"build fat rightleg"<<endl; }
};
//构造的指挥官
class Director
{
private:
Builder *m_pBuilder;
public:
Director(Builder *builder) { m_pBuilder = builder; }
void Create(){
m_pBuilder->BuildHead();
m_pBuilder->BuildBody();
m_pBuilder->BuildLeftArm();
m_pBuilder->BuildRightArm();
m_pBuilder->BuildLeftLeg();
m_pBuilder->BuildRightLeg();
}
};
结构型模式
这部分模式侧重于类和类之间的组合桥梁成为更大的结构
装饰模式
- 实现和继承类似的功能,但是因为继承耦合度增加,因此用这个模式是替代,==使用组合代替继承==,组合之后再加上额外的功能在新的类中
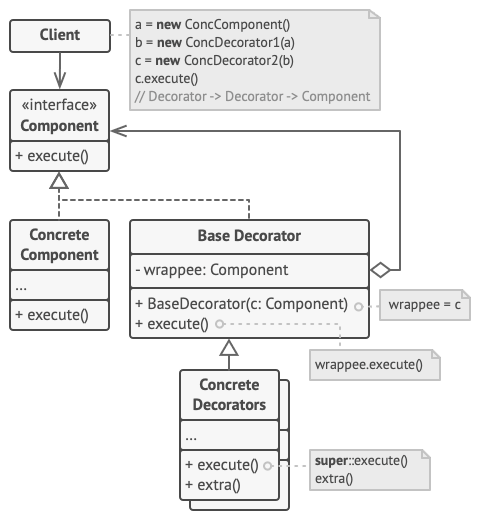
适配器模式
- 用于构建一个类将两个本来不能兼容的类适配,方法是创建一个适配器类,继承已经存在的类和需要实现的interface,在需要实现的interface中操作
- 需要使用的时候直接用适配器类代替已经存在的类,不需要使用以前的类
func main{
client := &Client{}
mac := &Mac{}
client.InsertLightningConnectorIntoComputer(mac)
windowsMachine := &Windows{}
windowsMachineAdapter := &WindowsAdapter{
windowMachine: windowsMachine,
}
client.InsertLightningConnectorIntoComputer(windowsMachineAdapter)
}
代理模式
- 实际上就是套娃,在外层再封装一个模式作为代理层,用于间接调用(因为可能直接的部分是库无法更改)
- MCV中的m实际上就是代理层,还有限流缓存等功能
行为型模式
这部分模式侧重点在类和类之间的关系,相互调用和依赖
观察者模式
- 就是发布订阅模型,具体实现可以参考redis实现 > 订阅频道
- 普通情况下我们通常采用传递函数,然后回调的方法使用,这样的局限性在于函数不能携带状态和数据,因此观察者模式抽象出一个订阅者的interface,实现了这个interface内函数的类都可以直接传入
type Observer interface {
update(string)
}
type Customer struct {
id string
}
func (c *Customer) update(itemName string) {
fmt.Printf("Sending email to customer %s for item %s\n", c.id, itemName)
}
func main() {
shirtItem := newItem("Nike Shirt")
observerFirst := &Customer{id: "abc@gmail.com"}
observerSecond := &Customer{id: "xyz@gmail.com"}
shirtItem.register(observerFirst)
shirtItem.register(observerSecond)
shirtItem.updateAvailability()
}
策略模式

- 和工厂模式类似,但是核心区别是工厂模式生产的是不同的对象,然后通过基类对象指针接收着整个新对象,但是策略模式是先生成对象,然后通过策略模式更改这个对象的行为
- 工厂模式中只管生产实例,具体怎么使用工厂实例由调用方决定,策略模式是将生成实例的使用策略放在策略类中配置后才提供调用方使用,进一步封装了实例的使用,实际上是封装了使用的场景,工厂只封装了生产的场景
PeopleFactory peopleFactory = new PeopleFactory();
People people = peopleFactory.getPeople("Xiaohong"); System.out.print("工厂模式-------------"); people.run(); StrategySign strategySign = new StrategySign("Xiaohong"); System.out.print("策略模式-------------");strategySign.run();
[!tip] 参考 https://cloud.tencent.com/developer/article/1873154
迭代器模式
- 就是C++的迭代器模式: 声明所有迭代器的父类interface,特定的对象实现一个特定的迭代器,然后将这个特定的迭代器作为自己的成员暴露出去,外部调用的是第五代其interface的实现方法
type Iterator interface {
hasNext() bool
getNext() *User
}
中介者模式
- 大家都依赖一个中心化的类,避免相互依赖提高耦合度,这个平时也经常用
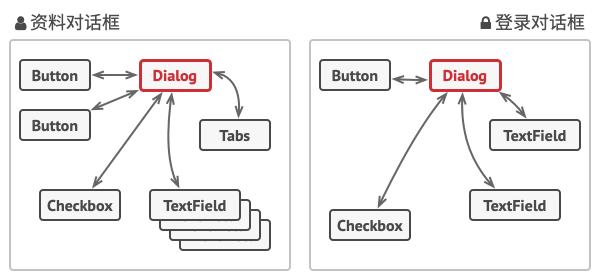
重构
重构时机
[!important] 需求的变化导致重构,如果一段代码能正常工作,并且不会再被修改,那么完全可以不去重构它
- ==三次法则==:如果三次做类似的事情(写相似的代码),那么就应该对代码进行重构
[!important] 重构前,保证有一套可靠的测试集,这些测试必须具有自我检验的能力,测试参考测试系统
代码坏味道
过长函数
- 保证代码的圈复杂度尽量在10以内,最多不能超过20
- 将逻辑提取到小函数进行封装
- 共同的逻辑也提取到小函数封装
- 如果是class中的共同代码考虑提取到父类中进行
过长参数列表
- 查询代替参数,如果参数可以通过其他参数计算得到,那么封装成为一个独立的函数使用查询获得
- 引用参数对象,合并参数为对象直接传递对象
- 去除参数标记,将标记拆分成为多个函数,使用函数名区分开,多个函数中公共部分拆分提取公共函数
参考
- https://zhuanlan.zhihu.com/p/37469260
- https://zhuanlan.zhihu.com/p/431714886
- https://refactoringguru.cn/design-patterns/cpp
[!success] 软件开发没有银弹
前置知识
序列图/时序图
- 时序图更加适合设计多个微服务多方调用,活动图更加适合一个部分逻辑复杂使用
- 异步调用用空心箭头,同步用实心箭头
- 返回值统一用虚线表示

- 交互框:实际上就opt,alt,loop,par常用
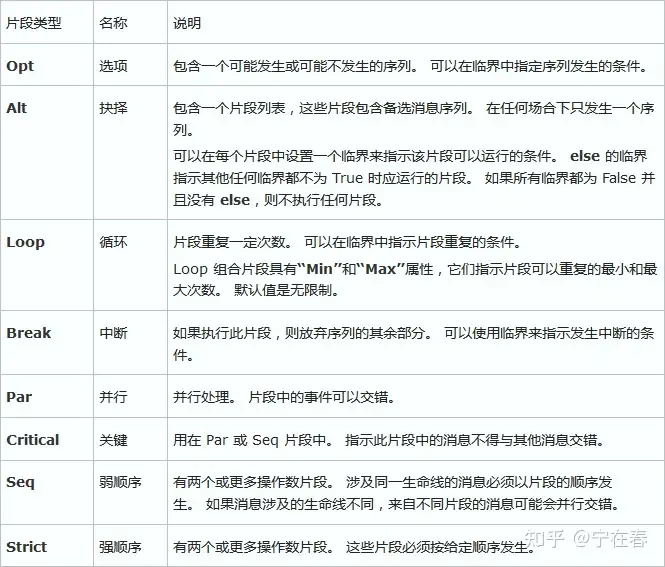
- 序列图场景
| 应用场景 | 名称 | 抽象级别 | 示例 | 作用 |
|---|---|---|---|---|
| 业务建模 | 业务序列图 | 组织-组织 系统-系统 | 业务执行者、业务工人、业务实体 | 业务用例的实现,描述组织内业务流程 |
| 设计 | 设计序列图 | 系统-系统 组件-组件 | 组件 | 组织的各种系统如何协作以完成组织的用例 |
[!tip] 参考 https://diangroup.feishu.cn/file/TfE7bFToQo2tDOxEPmSc07UhnTe https://zhuanlan.zhihu.com/p/422509874
活动图
活动图的前身流程图,应该是在建模人员中使用频率最高的图形了。流程图最早出现于1921年Gilbreth的文章中,用于机械工程领域。在Goldstine和von Neumann将其引入计算机领域之后,流程图变得流行起来,主要用于在编写文本源代码之前表达跳转逻辑。不过,随着编程语言表达能力越来越强,针对简单的分支或循环逻辑画图在很多情况下已经变得没有必要
- 之前画得基本上都是活动图,着重于数据在各个组件之间的传递,这个有点相当于业务序列图和设计序列图的结合版本,核心在于数据的传递,以及传递过程的组件
- 这种理解性最好,推荐系统需要画一个
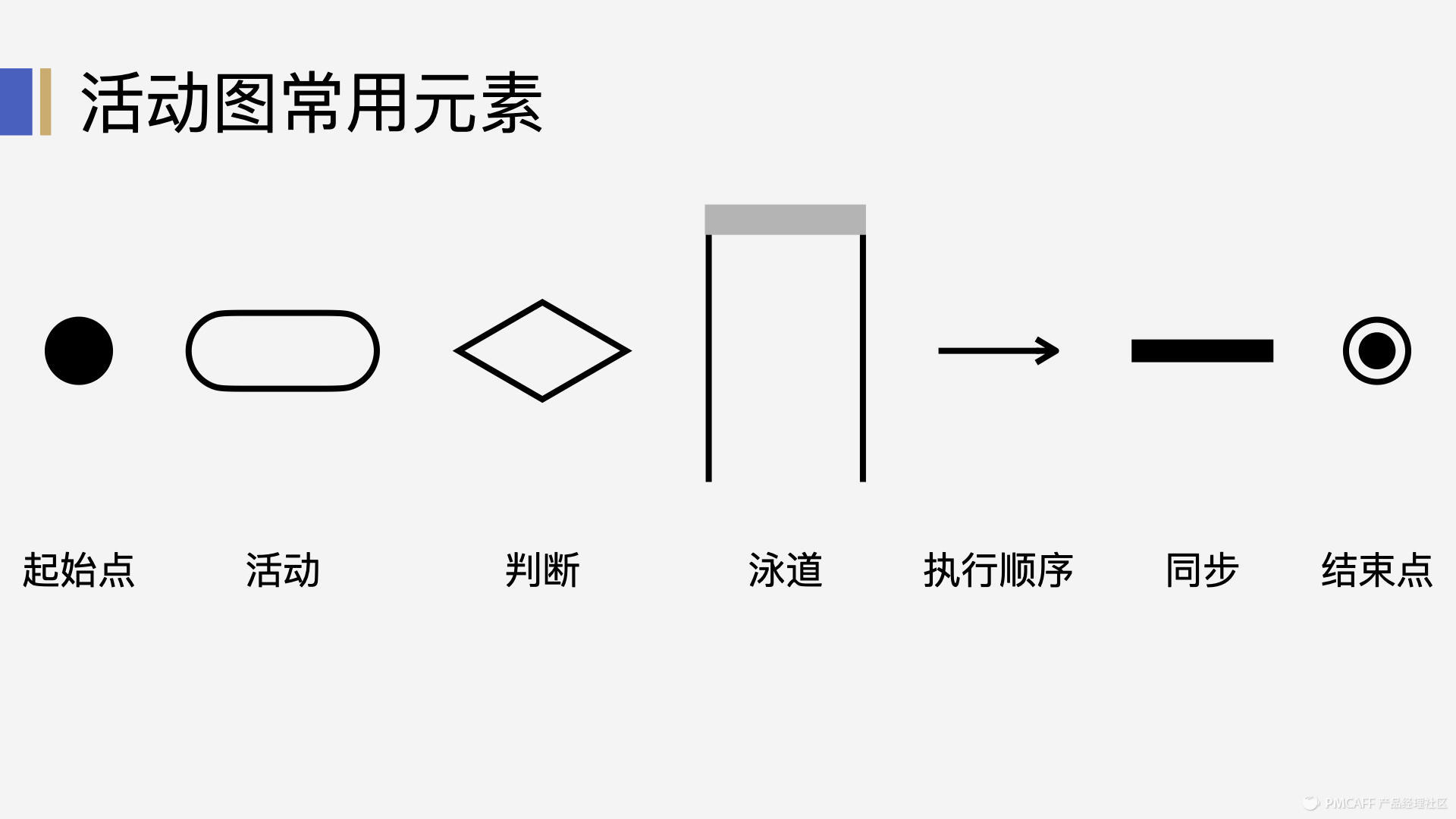
[!tip] 参考 UML活动图大白话入门教程 - 知乎
软件工作流
- 业务建模:描述的是整个领域内的系统如何协作不只是要开发的部分
- 需求:想要的功能特性
- 分析: 分析该什么做
- 设计:具体的逻辑实现等等
业务建模
[!important] 作用 描述组织内部各系统(人脑系统、电脑系统……)如何协作,使得组织可以为其他组织提供有价值的服务。新系统只不过是组织为了对外提供更好的服务,对自己的内部重新设计而购买的一个零件
愿景
业务序列图
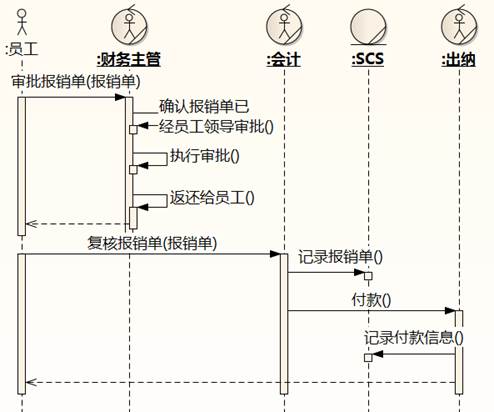
- 序列图描绘的是业务,因此每个对象是一个系统而不是模块,消息代表的是责任而不是数据和逻辑
- ==消息代表责任分配而不是数据流动==:序列图最重要的要点是消息的含义。A 指向 B 的消息,代表“A 请求 B 做某事”,或者“A 调用 B 做某事的服务”,做某事是 B 的一个责任。比如上图中不能写为'把审批单提交'而是应该写成"审批报销单",审批是B的责任,具体的数据流通过参数传递
- 每个对象是系统,而不是细化的某个逻辑,过细的自反消息会把需求和分析的工作流的工作带入了业务建模
- 序列图的返回通常使用虚线,业务序列图很少有返回消息,除非是一整个流程结束才会返回
需求
系统用例图
- 重点是==对外部的什么个体,提供了业务流程中的什么价值==,系统能够为执行者提供的、涉众可以接受的价值
- 用例的命名是动宾结构,用例的命名是动宾结构,例如“取现金”。 动词前面可以加状语,宾语前面可以加定语,把一句话 的主语砍掉,剩下的可以作为用例的名字。
- ==命名是用户提供的价值而不是过程的细节,也不是数据库的增删改查==,例如应该是'开发票'而不是'添加发票','作废发票'而不是'删除发票'
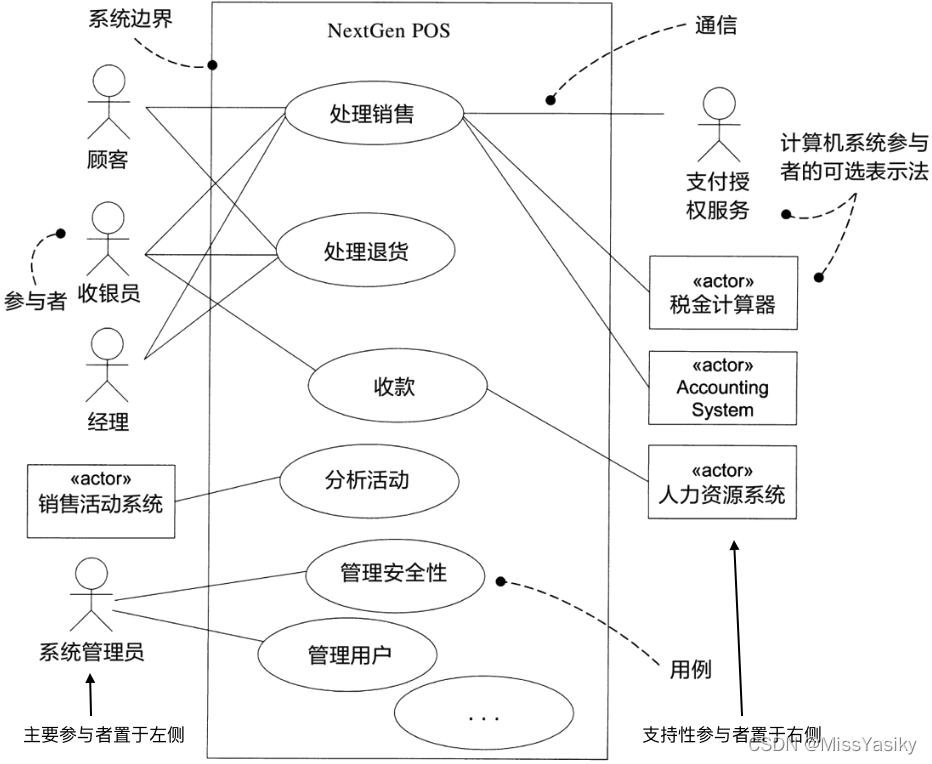
分析
分析一般画得是类图
分析类图
- 具体例子可以参考 设计模式
- 分析类的种类
- 边界类:输入、输出,及简单的过滤
- 控制类:控制用例流,为实体分配责任
- 实体类:系统的核心,封装领域逻辑和数据。
- 执行者先把消息发给边界类对象,边界类对象能(类比于数据库的表)
- 泛化:类似==面向对象中的继承==,子类通过继承超类而拥有超类的特征,是一种集合关系,如人与男人、女人。识别泛化关系的方法有:
- 对类与类之间,思考A是否是B的一种,而B是否是A的一种
- 对多个已有的类,抽象出公共部分,形成超类
- 从一般的类,细化出特殊的子类
- 尽量不要跨领域形成泛化关系
- 关联:对象通过组装其他对象而拥有其他对象的特征,是个体类间的关系,如人与手、脚。只有系统负责维护的关系,才构成关联。泛化和关联,可以视分析场景进行转变,可用于简化模型。关联的形式有:
- 普通关联(一根直线)
- 聚合(直线一端是空心菱形):多个对象和某个对象的关联紧密,视为受其影响的分区(如公司与各个部门)
- 组合(直线一端是实心菱形):比聚合更严格,“部分”对象跟随“整体”对象销毁而销毁;“部分”对象只属于一个“整体”对象;“整体”对象负责“部分对象的创建与销毁。
- 自反关联,即关联发生在同一个类上
- 依赖:其他不能视为泛化或关联的类间关系
- 类的可见性
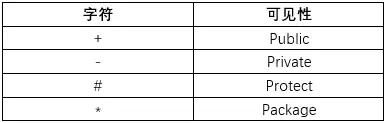
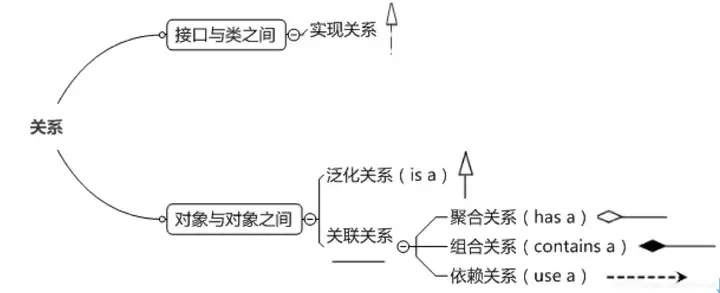
[!tip] 参考 https://zhuanlan.zhihu.com/p/109655171 https://zhuanlan.zhihu.com/p/149035395
UML关系图
demo
- 箭头上的数字代表 1 个学生可以不参加课程,也可以无限制参加各种课程
- 1 代表一个,0..* 代表 0 个到无限个
[!important] 多重性 多重性应用于关联的目标端,说明源类的每个实例与目标类实例的连接个数。 0..*:0个或多个 3..7:指定范围(3~7个,包含3和7)
依赖
- 对于两个相对独立的对象,当一个对象负责构造另一个对象的实例,或者依赖另一个对象的服务时,这两个对象之间主要体现为依赖关系。
- 类 A 使用到了类 B,而这种使用关系具有偶然性,临时性,非常弱的,但是 B 类中的变化会影响到类 A
[!example] 你是一名出租车司机,每天开着公司给你分配的车去载客,而每天出租车可能不同,我只是个司机,公司给我什么车我就开什么车,我使用这个车。
关联
- 对于两个相对独立的对象,当一个对象的实例与另一个对象的一些特定实例存在固定的对应关系时,这两个对象之间为关联关系。双向关联的话箭头可以省略。
- 两个类中一种强依赖关系,比如我和我的朋友,这种关系比依赖更强,不存在依赖关系中的偶然性,关系也不是临时的,一般是长期性的。
[!example] 我是一名老司机,车是我自己的,我拥有这辆车,平时也会用着辆车去载客人。
聚合
- 聚合关系是关联关系的一种,耦合度强于关联,他们的代码表现是相同的,仅仅是在语义上有所区别:关联关系的对象间是相互独立的,而聚合关系的对象之间存在着包容关系,他们之间是“整体-个体”的相互关系。
- 聚合关系中作为成员变量的类一般使用 set 方法赋值
[!quote] 依赖:用完就扔。
关联,聚合:不属于我,但是用完先放着。
组合:是我的一部分,用完保存好。
组合
- 相比于聚合,组合是一种耦合度更强的关联关系。存在组合关系的类表示“整体-部分”的关联关系,“整体”负责“部分”的生命周期,他们之间是共生共死的;并且“部分”单独存在时没有任何意义。
[!example] 人和灵魂,身体之间是组合关系,当人的生命周期开始时,必须同时拥有灵魂和肉体,当人的生命周期结束时,灵魂肉体随之消亡;无论是灵魂还是肉体,都不能单独存在,他们必须作为人的组成部分存在。
继承
实现
[!tip] 参考 https://zhuanlan.zhihu.com/p/24576502
彩色建模
- #TODO 这里可以参考一下彩色建模
设计
DDD领域驱动模型是在这里起作用的
设计序列图
- 设计序列图描绘的是系统的具体逻辑,是和代码最接近的地方
状态机图
- 按照下图规范
[!tip] 参考 UML之状态机图 - gd_沐辰 - 博客园
DDD领域驱动
QA
如何确定使用什么图
- 如果侧重点是一个请求的完整生命流程, 侧重于一个请求的整体链路和大致步骤, 使用时序图, 因为时序图可以看到这个调用方和整个调用流程
- 如果侧重于某个点的详细复杂逻辑(比如很多判断异步循环)类似 微服务框架,或者某个服务某个接口的详细流程,使用流程图(适合在接口逻辑设计时候使用)
- 如果是整体架构的层面的设计,观察有多少个模块以及这些模块的层次和联系,使用架构图, 类似tira-im的第一幅图
- 总结:
- 首先架构图(实际上也是一个流程图)确定服务的架构
- 然后时序图设计请求的大致流程和涉及服务
- 最后流程图设计接口的实现具体逻辑