类型说明
index
- 类似mysql的数据库(不是索引)
filed
- 类似表中的字段
document
- 类似数据行,基本数据单元
type
- 类似数据表
原理介绍
倒排索引
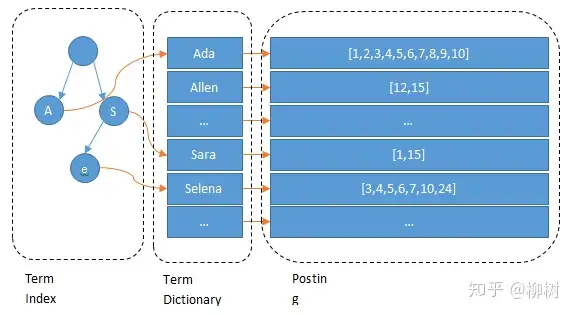
- 一般的数据库是通过文章->获取单词(正向索引),这个是通过单词->获取文章列表
- 首先通过单词建立字典树,val为链表或者bitmap
- 查询时候拿出所有词的list或者bitmap,取交集
bitmap和list的优缺点
- bitmap每个key需要维护一个和文章总数大小相同的bit数组,当文章非常多的时候内存不足,但是bitmap与运算非常快,相对于list包含一个文章的代价也比较小(只需要一个bit),适合用于文章总数不是很多,但是文章比较相似(包含的关键字非常多,每个关键词被很多文章包含)
- list每个词出现的文章成一个list,这个list太长时候浪费内存,list做与运算比较慢,需要先排序(当然插入时候就排序也可以)然后两两合并,适合用于文章短,但是很多,内容不一样,每个关键词包含的文章较少,合并通过归并的思想,1和2合并,得到的结果再和3合并
- 因此采用的方案可以是使用List,然后两两合并的时候将list转bitmap,然后通过bitmap的与操作(这样不用排序)
wukong源代码阅读
- 实话实说,没看到什么东西很特别,绝大多数都是上面的东西
- 悟空使用的还是基于list的合并方式
创建索引
{
"name": "message",
"storage_type": "disk",
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "standard"
}
}
}
},
"mappings": {
"properties": {
"content": {
"type": "text" // 定义需要索引的数据名字和类型
}
}
}
}
- curl 创建索index
curl -u admin:cndsjc -X POST -H "Content-Type: application/json" -d '{
"name": "message",
"storage_type": "disk",
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "standard"
}
}
}
},
"mappings": {
"properties": {
"content": {
"type": "text"
}
}
}
}' http://127.0.0.1:10004/api/index
参考
- https://zhuanlan.zhihu.com/p/33671444
- https://geekdaxue.co/read/ZincSearch-doc/search-type 中文文档地址