redis和mysql数据一致性问题
- 无法保证强一致性,只能保证最终一致性
- 根本原因是因为,redis和mysql操作不是原子操作(因为跨系统)
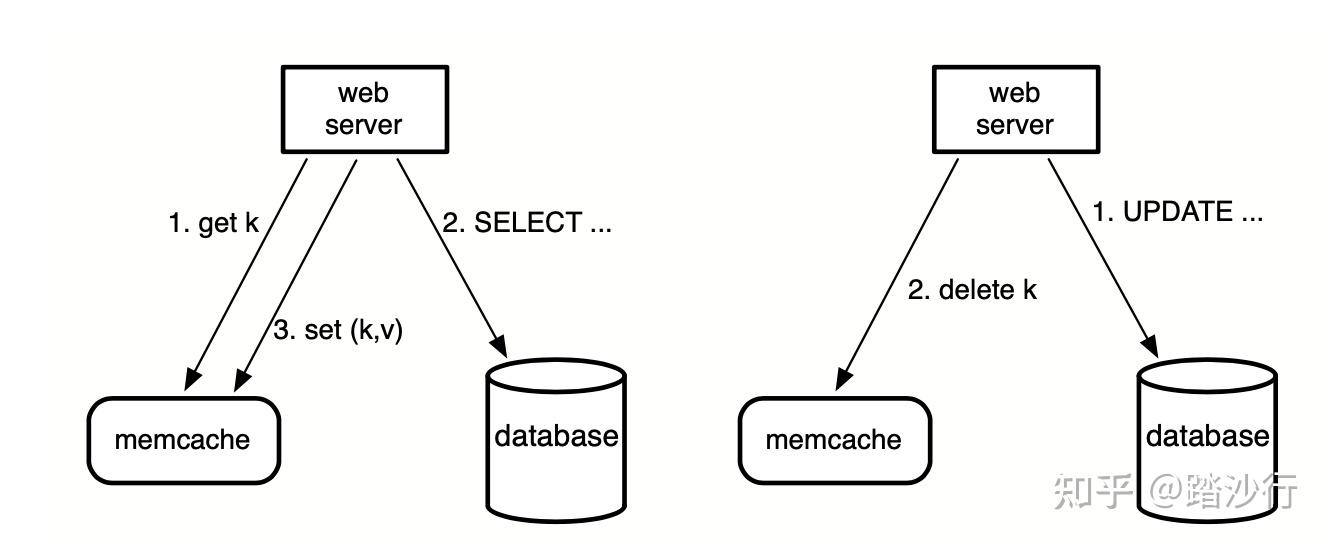
先操作缓存
- 删除redis缓存
- 更新mysql数据库
缺点
- 更新mysql时候其他线程读取mysql,导致旧值存在于缓存中,因为这种可能发生可能性大,因此用的少
先操作数据库Cache Aside Pattern(旁路缓存模式)
- 更新mysql
- 删除redis缓存
优点
- 就算有旧值后面也会被删除
缺点
- 更新mysql时候其他线程读到旧值,但是因为网络波动,在删除缓存后写入旧值,导致旧值存在缓存中(发生概率还是比较小的,用的比较多)
延时双删
- 删除缓存(避免读到旧值,但是通常可省略)
- 更新数据库
- 睡觉一会(几十ms左右)
- 删除缓存(删除可能其他线程写的脏缓存)
优点
- 更大可能性不会出现第二种的问题
缺点
- 时间难以把控
- 性能减低(睡觉的原因)
其他
MQ
- 通过MQ把DB和redis解耦,把删除任务扔到MQ中,通过MQ保证执行的顺序和串行化
为什么不是update而是delete
实际上字节用的就是这种
- 避免A先改,B后改,但是因为网络问题,B先更新缓存,A把旧缓存更新的问题(这个感觉发生可能性比较小)
- 如果写的比较多,那么频繁更新缓存影响性能
解决缓存命中率低
- 如果要求强一致性,那么可以通过分布式锁避免其他线程操作
- 最终一致性,可以DB更新后,更新一个生存时间非常短的缓存,减低影响
总结
- 只能用于一致性要求不这么高,但是更新频繁,读取频繁的情况,比如好友数量,消息热度这种
- 真正账户余额这种还是要么不用redis,直接mysql读(数据小),要么上etcd这种强一致性的数据库
数据一致性的其他解决方案
binlog 删除
- 订阅mysql binlog, 如果出现update 情况就删除 redis 中的数据
- 读时候miss就顺便缓存
优点
- 写操作和 redis接耦
- 删除缓存极端 case 得到缓解
缺点
- 多出一个组件, 复杂性增加
- 更新之前的缓存是脏的, 短时间的错误数据
binlog 更新
- 优点和缺点类似
- 这个将删除改为更新, 但是有个问题时这个依赖 mq 的顺序消费的特性, 都者数据会是错误的
- 这个也会出现一段时间缓存是错误的
read-Through和write-Back
- 相当于外部封装了一层sdk, 所有的操作直接写入缓存之后马上返回, 返回之后缓存再写入 db中, 读的时候也是读缓存, 读取不到 sdk自行处理(感觉相当于封装了一个存储)

facebook 一致性方案
- get 使用 udp 进行连接数据传输, set/delete 使用tcp进行数据传输, udp失败的情况直接当做 cache miss处理
- 使用 lease 机制保证按顺序写入缓存, 针对一个特定的Key,当第一次查询出现Cache Miss的时候,会为它产生一个Lease返回给Client,Client在查询到真正的值之后Set Memcache的时候必须带上这个Lease,这样才能通过合法性检查。多个并发 get 的情况下只有一个能拿到 lease 写入 cache 其他需要等待 cache写入后读取
- 这里可能出现问题时拿到 lease 及进程意外退出, 导致 lease 无法写入, 这里可以通过设置 lease 有效期进行缓解(但是在有效期期间这个 key还是处于失败的状态)
缓存雪崩
- 缓存大规模失效,导致请求大规模打到mysql情况
- 此时mysql宕机,马上重启也会有大量数据导致宕机
产生原因
- redis崩了
- key失效时间设置得都差不多
解决办法
- 失效时间设置好一点(比如加上随机数)
- 熔断保护机制.当流量到达一定的阈值时,就直接返回“系统拥挤”之类的提示,防止过多的请求打在数据库上。至少能保证一部分用户是可以正常使用,其他用户多刷新几次也能得到结果.
缓存击穿
- 某个热点key没了,导致大量请求打到mysql上(mysql存在,redis不存在)
解决办法
- 设置热点key永不过期
缓存穿透
- 大量恶意的不存在的数据请求,导致大量请求持续打到mysql上(mysql不存在,redis不存在)
解决办法
- 其他系统 > 布隆过滤器,一种bitmap,将存在的key或得到结果,如果查询的key和其或结果和原来不一样,说明key不存在
缓存预热
- 在刚启动的缓存系统中,如果缓存中没有任何数据,如果依靠用户请求的方式 重建缓存数据,那么对数据库的压力非常大,而且系统的性能开销也是巨大 的。
mysql索引失效
- 对索引使用左或者左右模糊匹配
- 使用左或者左右模糊匹配的时候,也就是
like %xx或者like %xx%这两种方式都会造成索引失效。因为索引相当于前缀匹配 - 使用左模糊匹配(like "%xx")并不一定会走全表扫描,关键还是看数据表中的字段。如果数据库表中的字段只有主键+二级索引,那么即使使用了左模糊匹配,也不会走全表扫描(type=all),而是走全扫描二级索引树(type=index)
- 对索引使用函数或者进行表达式计算
- 如
select * from t_user where id + 1 = 10;
- 对索引隐式类型转换
- 联合索引非最左匹配
- WHERE 子句中的 OR
redis为什么这么快
- Redis 的大部分操作都在内存中完成,并且采用了高效的数据结构,因此 Redis 瓶颈可能是机器的内存或者网络带宽,而并非 CPU,既然 CPU 不是瓶颈,那么自然就采用单线程的解决方案了;
- Redis 采用单线程模型可以避免了多线程之间的竞争,省去了多线程切换带来的时间和性能上的开销,而且也不会导致死锁问题。
- Redis 采用了 I/O 多路复用机制处理大量的客户端 Socket 请求,IO 多路复用机制是指一个线程处理多个 IO 流,就是我们经常听到的 select/epoll 机制。简单来说,在 Redis 只运行单线程的情况下,该机制允许内核中,同时存在多个监听 Socket 和已连接 Socket。内核会一直监听这些 Socket 上的连接请求或数据请求。一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。
redis做消息队列的几种方式以及缺点
1. LIST+BRPOP
优点
- 消息下发延迟小
- 消息积压下表现好
- 多个程序BRPOP此时有数据只会通知一个程序
缺点
- 消息ack麻烦,无法确定是否成功处理,无法真正保证必达性
- 不能做广播模式
- 不支持重复消费以及分组消费
2. 发布订阅模型
优点
- 多信道订阅,消费者可以同时订阅多个信道,从而接收多类消息,典型的广播模式,一个消息可以发布到多个消费者
- 消息即时发送,消息不用等待消费者读取,消费者会自动接收到信道发布的消息
缺点
- 消息一旦发布,不能接收。换句话就是发布时若客户端不在线,则消息丢失,不能寻回
- 不能保证每个消费者接收的时间是一致的
- 若消费者客户端出现消息积压,到一定程度,会被强制断开,导致消息意外丢失。通常发生在消息的生产远大于消费速度时 可见,Pub/Sub 模式不适合做消息存储,消息积压类的业务,而是擅长处理广播,即时通讯,即时反馈的业务/
3. Stream流模型
[!tip] 参考 https://www.jianshu.com/p/d32b16f12f09 https://zhuanlan.zhihu.com/p/496944314 https://cloud.tencent.com/developer/article/2331486 https://juejin.cn/post/7094646063784525832 https://www.cnblogs.com/coloz/p/13812840.html

使用命令
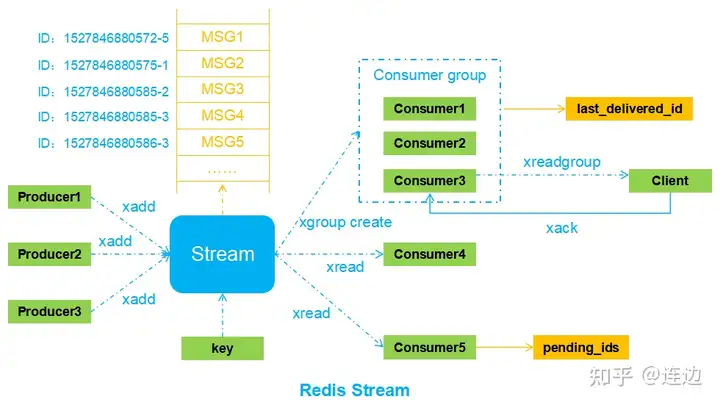
结构体
stream
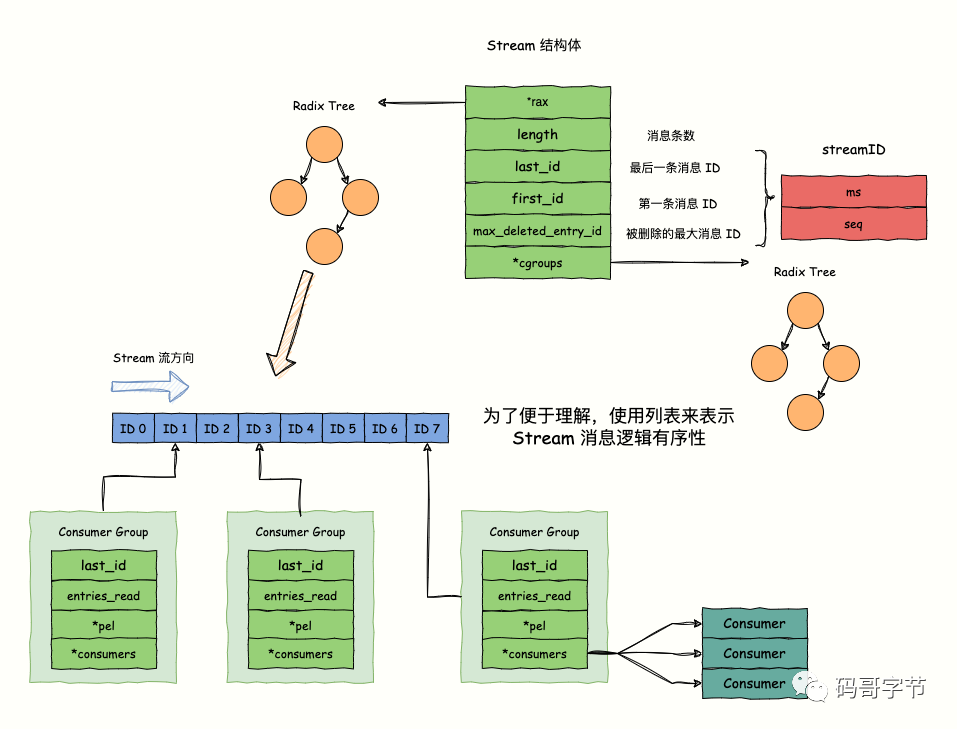
typedef struct stream {
rax *rax; // 是一个 `rax` 的指针,指向一个 Radix Tree,key 存储消息 ID,value 实际上指向一个 listpack 数据结构,存储了多条消息,每条消息的 ID 都大于等于 这个 key 的消息 ID
uint64_t length; // 该 Stream 的消息条数
streamID last_id; // 当前 Stream 最后一条消息的 ID。
streamID first_id; // 当前 Stream 第一条消息的 ID。
streamID max_deleted_entry_id; // 当前 Stream 被删除的最大的消息 ID。
uint64_t entries_added;// 总共有多少条消息添加到 Stream 中,`entries_added = 已删除消息条数 + 未删除消息条数`
rax *cgroups;// rax 指针,也指向一个 Radix Tree ,**记录当前 Stream 的所有 Consume Group**,每个 Consume Group 的名称都是唯一标识,作为 Radix Tree 的 key,Consumer Group 实例作为 value
} stream;
// 结构体,消息 ID 抽象,一共占 128 位,内部维护了毫秒时间戳(字段 ms);一个毫秒内的自增序号(字段 seq),**用于区分同一毫秒内插入多条消息**。
typedef struct streamID {
uint64_t ms;
uint64_t seq;
} streamID;
- stream中使用树和堆 > radix tree实现消息列表而不是list
[!info] 原因
- redis的消息支持根据id删除,因此需要有索引的出现,因此不能单纯用list
- redis的消息支持顺序消费,而且key大量重复,因此不能直接用hash
- 节省空间,而且因为redis默认使用时间戳+顺序编号作为id,公共前缀比较长,可以节省空间
- value的类型是redis实现 > 压缩列表,直接存储的就是消息的id和内容
- listpack的所有key都是增加的,比叶子节点的node大
- 消息的id是(毫秒时间戳-序号)
consumer group
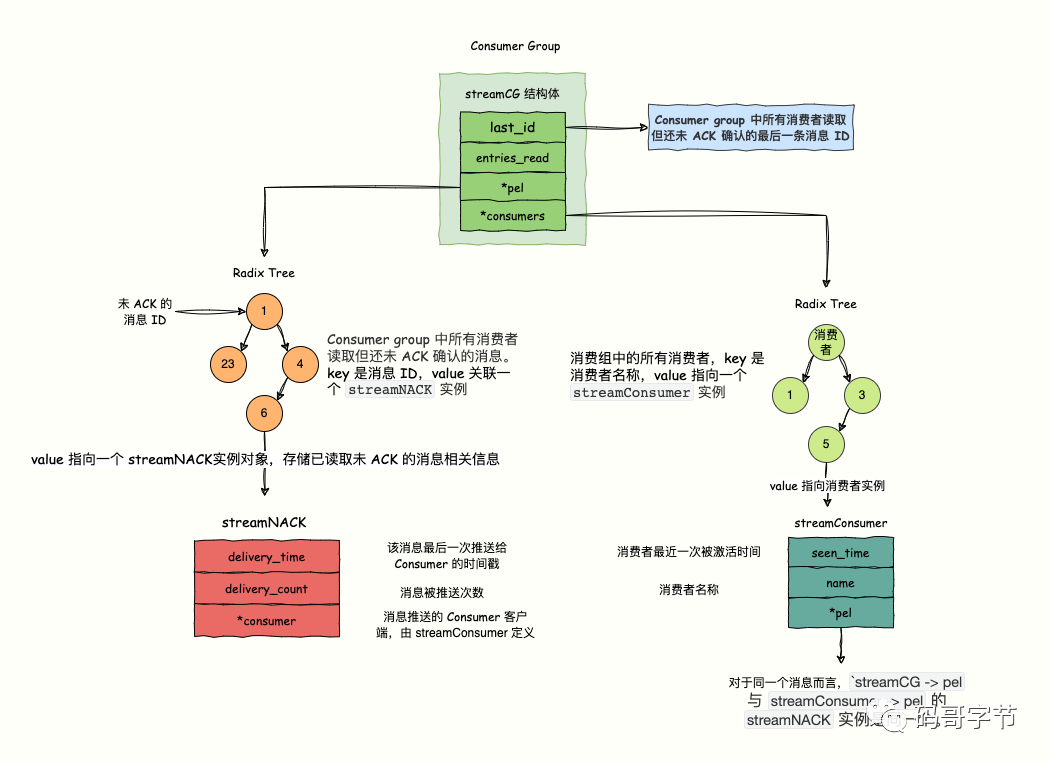
/* Consumer group. */
typedef struct streamCG {
streamID last_id;// **已经获取了,无论是否ack的id**
long long entries_read;
rax *pel;
rax *consumers;// key是消费者name,val是消费者实体
} streamCG;
/* Pending (yet not acknowledged) message in a consumer group. */
typedef struct streamNACK {
mstime_t delivery_time;
uint64_t delivery_count;
streamConsumer *consumer;
} streamNACK;
typedef struct streamConsumer {
mstime_t seen_time;
sds name;
rax *pel;
} streamConsumer;
- 没有ack的消息可能在consumer中的pel和group的pel都记录一次,但是这两个指向的都是同一个streamNACK结构体,因此是共享的
- pel是整个维护必达性的核心结构体,所有没有被ack的数据都会放到这里,保证至少被消费一次
- 消费者和消费者组参考消息队列
Iterator
typedef struct raxStack {读取之后无论是否ack,last_id都会更新
void **stack; /*用于记录路径,该指针可能指向static_items(路径较短时)或者堆空间内存; */
size_t items, maxitems; /* 代表stack指向的空间的已用空间以及最大空间 */
void *static_items[RAX_STACK_STATIC_ITEMS];
int oom; /* 代表当前栈是否出现过内存溢出. */
} raxStack;
typedef struct raxIterator {
int flags; //当前迭代器标志位,目前有3种,RAX_ITER_JUST_SEEKED代表当前迭代器指向的元素是刚刚搜索过的,当需要从迭代器中获取元素时,直接返回当前元素并清空该标志位即可;RAX_ITER_EOF代表当前迭代器已经遍历到rax树的最后一个节点;AX_ITER_SAFE代表当前迭代器为安全迭代器,可以进行写操作。
rax *rt; /* 当前迭代器对应的rax */
unsigned char *key; /*存储了当前迭代器遍历到的key,该指针指向
key_static_string或者从堆中申请的内存。*/
void *data; /* 当前key关联的value值 */
size_t key_len; /* key指向的空间的已用空间 */
size_t key_max; /*key最大空间 */
unsigned char key_static_string[RAX_ITER_STATIC_LEN]; //默认存储空间,当key比较大时,会使用堆空间内存。
raxNode *node; /* 当前key所在的raxNode */
raxStack stack; /* 记录了从根节点到当前节点的路径,用于raxNode的向上遍历。*/
raxNodeCallback node_cb; /* 为节点的回调函数,通常为空*/
} raxIterator;
- 使用还是通过栈+中序遍历节点的方式寻找下一个
整体流程
写入
- 先创建一个stream,创建raxio tree
- 根据last_id,生成要插入的新的ID,找到最大的tree的节点(最右边的节点)
- 判断listpack是否还能插入,能插入能插入
- 不能就根据key创建一个新的listpack
读取
- 所有的读取行为以group的last_id进行读取
- 读取之后无论是否ack,last_id都会更新
- 没有ack的消息都会被扔到pel中和消费者的pel中,被分配给消费者的消息不会再给其他消费者,也只能特定的消费者来ack
[!info] 重发时机
- 检测到消费者有断线的情况
- 消息过期,这部分xadd指定时间
redis如何实现延迟队列
- 使用 zset这个命令,用设置好的时间戳作为score进行排序,使用
zadd score1 value1 ....命令就可以一直往内存中生产消息。再利用 zrangebysocre 查询符合条件的所有待处理的任务,通过循环执行队列任务即可。也可以通过zrangebyscore key min max withscores limit 0 1查询最早的一条任务,来进行消费
如何避免SQL注入进攻
- 预处理:采用预编译语句集
redis和memcached优劣势
- redis支持的数据结构比memcached更加丰富,mem只支持字符串和数字类型
- mem不支持持久化存储,redis支持持久化存储
- mem占用的内存小,redis更多,mem不支持主从复制,mem使用更加简单
微信拿到红包分配
分配算法
- 随机,额度在0.01和剩余平均值*2之间.例如:发100块钱,总共10个红包,那么平均值是10块钱一个,那么发出来的红包的额度在0.01元~20元之间波动。
- 领取红包后继续使用同样的方法计算
幂等性处理
mysql的private key
- 让业务方生成唯一ID,这个ID作为mysql唯一约束,如果插入失败则说明已经处理
mysql乐观锁version
- 先将唯一id插入,下一个请求来的时候查询是否已经插入,如果发现已经插入这说明已经处理(这个不需要使用锁,但是需要在业务层对version进行判断),tira-pay使用的方式就是这个
Redis的setNX
- 将ID拼接一些信息插入redis中,设置3分钟缓存,无法插入则说明已经处理(tira-im使用的方法)
列数据库
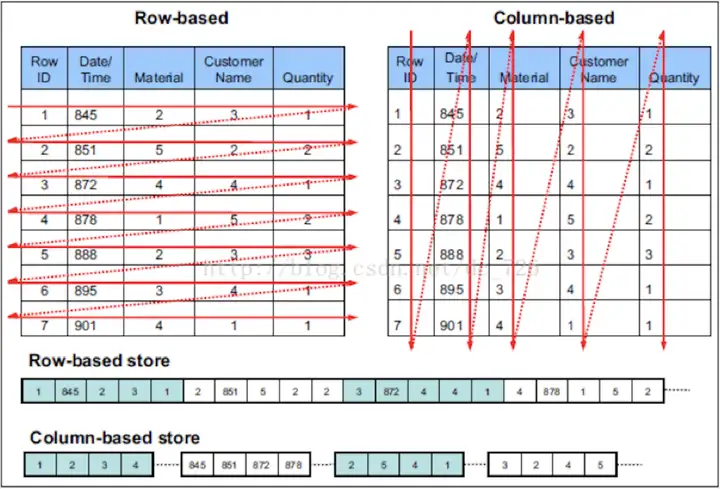
特点
- 读多于写
- 大宽表,读大量行但是少量列,结果集较小
- 数据批量写入,且数据不更新或少更新
- 无需事务,数据一致性要求低
- 灵活多变,不适合预先建模
优点
- 同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
- 更高的压缩比意味着更小的data size,从磁盘中读取相应数据耗时更短
- 更加适合于大量数据的读取分析
缺点
- 一行的全量查询慢(例如查需一个人的所有信息)
- 基本不支持ACID事务
应用场景
hbase 就是列数据库
- 类似数据分析(批量分析某个值的特征),大规模日志存储,大规模打点监控(压缩特性,并且可以接受秒级延迟)用的比较多
- 基本上是数仓和日志在用,通常是 hbase 配合 hadoop(基于mapreduce 的分布式系统基础架构,也是数仓的主要构成)
innodb和myisam的区别
- InnoDB支持事务,MyISAM不支持
- InnoDB支持表、行(默认)级锁,而MyISAM支持表级锁
- MyISAM 中 B+ 树的数据结构存储的内容是实际数据的地址值,它的索引和实际数据是分开的,只不过使用索引指向了实际数据。这种索引的模式被称为非聚集索引。InnoDB 中 B+ 树的数据结构中存储的都是实际的数据,这种索引有被称为聚集索引。
- myisam比较快,但是功能比较少
redis缓存的缺点(微信支付不用)
- 数据的一致性的问题,本质类似CAP,只能保证最终一致性,或者放弃可用性,
- 会有一种错误的安全感,高并发下会出现缓存失效的情况
使用缓存时容易有一种「虚假」的安全感,因为缓存的存在,会认为服务端性能能抗住热点时的请求,所以当缓存失败,峰值又上来之后,很快就把服务打挂了。因此,微信支付内部在做性能测试时,都需要先把缓存关掉。 即使是使用缓存,也只会使用单机的缓存,如同机部署的memcached,因为使用分布式的缓存,有多个写入来源的话,一旦缓存被写坏,排查起来会非常麻烦,因为根本不知道是在哪里被写坏的。
- 掉电丢失记录,可能出现数据的丢失
慢sql
特征
- 数据库CPU负载高。一般是查询语句中有很多计算逻辑,导致数据库cpu负载。
- IO负载高导致服务器卡住。这个一般和全表查询没索引有关系。
- 查询语句正常,索引正常但是还是慢。如果表面上索引正常,但是查询慢,需要看看是否索引没有生效。
查看
- 使用explain可以查看一个语句是否使用了索引
- 打开慢日志查询(会记录每一条执行时间长的sql),一般是由于没有索引,或者索引失效,或者数据量太大造成的
关系型和非关系型数据库区别
- 关系模型可以简单理解为二维表格模型,而一个关系型数据库就是由二维表及其之间的关系组成的一个数据组织。
- 非关系型数据库又被称为 NoSQL(Not Only SQL ),意为不仅仅是 SQL。通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定,常用于存储非结构化的数据。
- 参考
拉取数据时候根据时间戳而不是id
- 现在基本上的拉取方式是 offset+limit,实际上mysql会将所有的数据拉取出来,然后排序好在偏移到offset拿出limit,因此数据量会非常大
- 但是如果是通过时间戳拉取的话,只会根据时间戳的范围进行拉取而不会全量拉取.因此业界通常的做法是通过 begin_time, end_time 拉取,而不是用limit
关系型数据库优缺点
- 采用二维表结构非常贴近正常开发逻辑(关系型数据模型相对层次型数据模型和网状型数据模型等其他模型来说更容易理解);
- 支持通用的SQL(结构化查询语言)语句;
- 丰富的完整性大大减少了数据冗余和数据不一致的问题。并且全部由表结构组成,文件格式一致;
- 可以用SQL句子多个表之间做非常繁杂的查询;
- 关系型数据库提供对事务的支持,能保证系统中事务的正确执行,同时提供事务的恢复、回滚、并发控制和死锁问题的解决。
- 海量数据情况下读写效率低:对大数据量的表进行读写操作时,需要等待较长的时间等待响应。
- 可扩展性不足:不像web server和app server那样简单的添加硬件和服务节点来拓展性能和负荷工作能力。
- 数据模型灵活度低:关系型数据库的数据模型定义严格,无法快速容纳新的数据类型(需要提前知道需要存储什么样类型的数据)。(比如巨大的表格增加字段)
非关系型数据库的优缺点
- 非关系型数据库存储数据的格式可以是 key-value 形式、文档形式、图片形式等。使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。
- 速度快,效率高。 NoSQL 可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘。
- 非关系型数据库具有扩展简单、高并发、高稳定性、成本低廉的优势。
- 可以实现数据的分布式处理。
- 非关系型数据库暂时不提供 SQL 支持,学习和使用成本较高。
- 非关系数据库没有事务处理,无法保证数据的完整性和安全性。适合处理海量数据,但是不一定安全。
- 功能没有关系型数据库完善。
- 复杂表关联查询不容易实现。
为什么mysql2000万行数据之后性能急剧下降
- mysql中索引B+树的高度大约是3,在2000w行数据内,并且页的大小是和磁盘的格子大小相关的
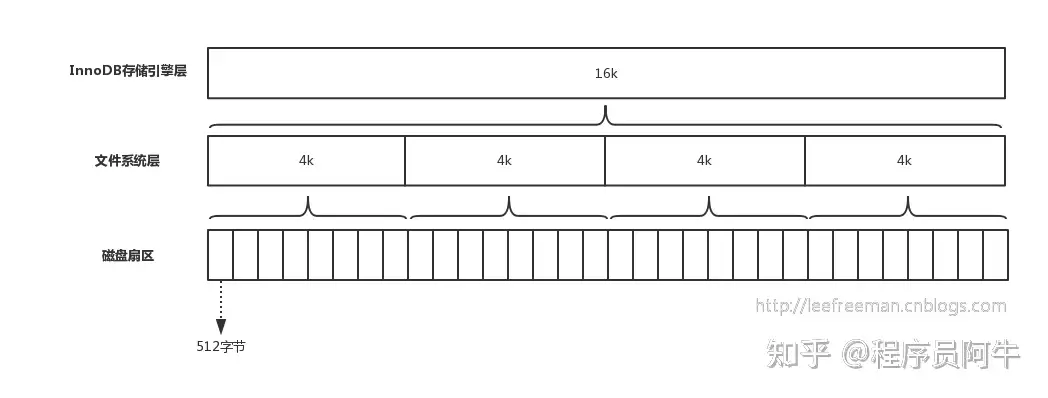
- 2000万行一下时候,基本上都是3层索引(大概是3层索引时候底层数据的极限容纳值),使得查找的效率相差不大
- 超过2000w行之后,B+需要变高,变高导致最底层的8页变成16页,多出16个页面,页面直接从磁盘中读取,导致io次数变多,性能变差,参考
查询的时候limit和offset有什么缺陷
- 数据库实际上是查找了offset+limit条,然后返回最后的limit条,当出现offset非常大的时候(特别是下滑刷新的时候),导致没吃查询的速度变得很慢
- 因此toC的一般使用时间戳的方式select,类似序号的形式,只是序号使用时间戳
mysql 在数据量非常大情况下如何统计行数
- 使用
select table_name,table_rows from information_schema.tables where TABLE_SCHEMA='effect_user_busi' and table_name='user_favorite' LIMIT 1;可以查到大概的数量级(有少量误差)
如何提高秒杀中数据库瓶颈
- 热点行事务想收集多行,然后只需要加锁一次一次性运行多个事务语句直接处理
- 参考 什么是热点行性能优化_云原生数据库 PolarDB(PolarDB)-阿里云帮助中心
如何选择数据库
- 如果出现ACID的需求支持事务性,类似支付这种业务,只能选择mysql,如果流量大或者分布式就用消息队列 和分布式事务,具体参考 支付系统
- 如果出现强一致性和分布式强需求,但是对事物性要求不高,类似 服务注册发现中心,就用etcd,参考 微服务框架 > coa
- 如果需要数据高速读写,但是不需要持久化存储(比如一些临时的排行榜),直接上redis redis实现
- 如果需要数据高速读写,需要持久化存储,但是对数据的一致性要求没这么高的,用redis+mysql 具体参考 数据库总结 > redis和mysql数据一致性问题
- 这样的缺点就是 需要解决一致性问题,以及还有穿透雪崩风险,错误概率大,成本高
- 而且redis一旦出问题挂了,mysql也会马上因为流量太大挂掉
- 如果需要数据较高速读写,需要持久化存储,对数据的一致性要求高的,用leveldb,参考LevelDB底层
- 如果需要灵活的数据结构和更舒适的开发体验,对事务没有强需求,小型项目,数据频繁变化,存储维度多样(有子结构和数组这种),类似文档型数据,用mongodb Mongodb基础
- 如果需要数据高速读写,需要强持久化存储(数据完全不丢失),对数据的一致性要求高的. 那基本是不可能的
- 高速读写意味着只能站在缓存进行,持久化只能在存储进行,一致性高只能在同一个系统进行(不同进程会出现cap问题),导致这三者必须牺牲掉一个或者减少一个去平衡其他两个,leveldb就是其中佼佼者
- 如果数据量非常大,重复率高,需要进行大量存储和离线数据分析(类似用户数据大表的备份,程序日志搜索等),对实时性要求不高(能接受秒级延迟),用列数据库 数据库总结 > 列数据库
- 出现用户大量的关系需要存储,类似关注,特别是共同关注这种需求,业务查询的时候通常以用户维度查询而不会用范围查询(数据分析的需求通常倒入列数据库离线分析),要求高性能查询扩展关系查询,通常用图数据库 Neo4j底层原理
- 如果是关键词搜索,通常使用ES这种倒排索引的数据库 zincsearch底层实现

Mysql Redis DRC 同步
- DRC (Data Replicate Center) 用于数据库的同步数据
- 使用类似从库复制的手法解决 , 同机房有 sync-out 模拟从库消费主库的 binlog , 发送到对机房的 sync-in (当然中间会放 mq) , sync-in 同步binlog到当地的机房
- 如果出现冲突遵循最后更新原则(即按照时间判断这个更新是否生效), 但是核心还是需要避免冲突, 根据用户 did划分机房(不用uid 是处理没有登陆的情况下)
缓存如何优化
- 3级缓存的机制缺点是, 如果遇到热点数据经常需要读取的,就会出现有时候因为没有命中缓存导致缓存穿透的问题
- 实际上这部分如果是少量的热点key可以通过全量缓存到内存中, 然后定时从数据库刷新的办法实现, 这样热点数据缓存命中率是100%
- 至于怎么从3层缓存到这种全量缓存的一种办法是通过检测 QPS, 如果QPS 过高就自动转化为这种形式
- https://juejin.cn/post/6964531365643550751
- https://mp.weixin.qq.com/s/bWofuM5eS2Q8ylF-4AD0kA
- https://zhuanlan.zhihu.com/p/346651831
- https://xiaolincoding.com/mysql/index/index_interview.html#%E4%BB%80%E4%B9%88%E6%98%AF%E7%B4%A2%E5%BC%95
- https://mp.weixin.qq.com/s?__biz=MzUxODAzNDg4NQ==&mid=2247503394&idx=1&sn=6e5b7b2c9bd9002a4b2dfa69273069b3&chksm=f98d8a88cefa039e726f1196ba14210ddbe49b5fcbb6da620778a7497fa25404433ef0b76268&scene=21#wechat_redirect
- https://mp.weixin.qq.com/s?__biz=MzU3ODA4NTc2Ng==&mid=2247484078&idx=1&sn=87a62dbe2d4ca7e56f2e0319465147a3&chksm=fd7bf447ca0c7d51dbbce887ce37ea7088d508b8766e09892706225a49fad06ad3716d48e0e0&token=2107017276&lang=zh_CN#rd