前提
- 至少一半的机器运行正常
- 广播时间需要<<选举超时时间<<平均故障时间
- 非拜占庭情况下
状态机复制
- 底层是状态机的复制,同一个系统,相同的输入之后得到的状态是相同的
状态转换
- 所有的机器只会是leader(领导者),candidate(候选人),follower(跟随者)
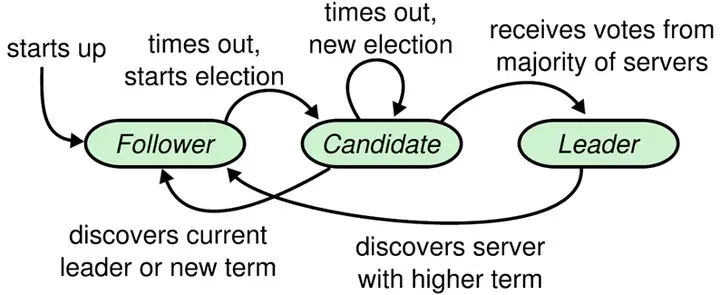
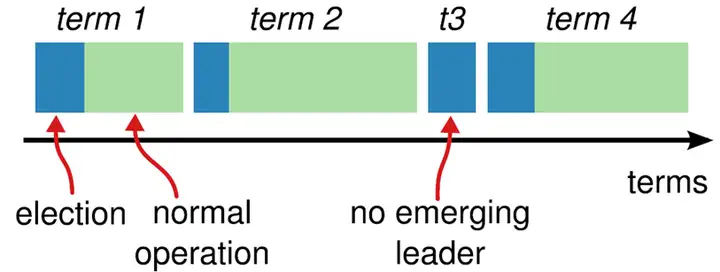
- Raft算法将时间分为一个个的任期(term),每一个term的开始都是Leader选举。在成功选举Leader之后,Leader会在整个term内管理整个集群。如果Leader选举失败,该term就会因为没有Leader而结束。
- 只存在两种RPC
- RequestVote RPC : candidate发起,请求投票
- AppendEntries RPC : leader复制日志和心跳保活
- 通讯会交换任期号,如果是follwer发现自己的任期比较小,那么会切换到大的任期号,如果是其他两种发现,会切换为follower
- 节点忽略过期任期号的请求(比如刚复活的进行选举,会选举失败)
领导者选举
- 心跳机制,leader向follower发送心跳包(携带任期号),超过最大时间follower发现没收到心跳之后
- 增大自己的任期号
- 切换为candidate状态,投票给自己,发送RequestVote给其他机器
- 结果三种可能
- 超过半数选票成为leader
- 其他赢了,标志为收到其他leader的心跳包,新leader任期不小于自己的任期号
- 没人获胜,重新选举
- 为了公平和防止进入死循环,选举超时时间会进行随机化(从发现leader没发心跳包,到成为candidate发送rpc的时间随机化)
RequestVote RPC内容
被候选者用来收集选票:
Arguments:
term 候选者的任期
candidateId 候选者编号
lastLogIndex 候选者最后一条日志记录的索引
lastLogItem 候选者最后一条日志记录的索引的任期
Results:
term 当前任期,候选者用来更新自己
voteGranted 如果自己将票投给候选人则为 true。
接受者的实现:
1. 如果 leader 的任期小于自己的任期返回 false。(5.1)
2. 如果本地 voteFor 为空,候选者
日志复制
- 只有leader具有写的权限(即向日志中附加条目),follower的写请求都会重定向到leader
AppendEntries RPC 内容
被 leader 用来复制日志,同时也被用作心跳
Arguments:
term leader 任期
leaderId 用来 follower 重定向到 leader
prevLogIndex 前继日志记录的索引
prevLogItem 前继日志的任期
entries[] 存储日志记录
leaderCommit leader 的 commitIndex
Results:
term 当前任期,leader 用来更新自己
success 如果 follower 包含索引为 prevLogIndex 和任期为
prevLogItem 的日志
接受者的实现:
1. 如果 leader 的任期小于自己的任期返回 false。(5.1)
2. 如果自己不存在索引、任期和 prevLogIndex、prevLogItem
匹配的日志返回 false。(5.3)
3. 如果存在一条日志索引和 prevLogIndex 相等,
但是任期和 prevLogItem 不相同的日志,
需要删除这条日志及所有后继日志。(5.3)
4. 如果 leader 复制的日志本地没有,则直接追加存储。
5. 如果 leaderCommit>commitIndex,
设置本地 commitIndex 为 leaderCommit 和最新日志索引中
较小的一个。
- 只有日志号和任期号才能唯一确定一个日志
日志有两种状态,生成和提交,提交之后不可撤回,只有半数以上节点ack,日志才会变为提交,只有leader同意,follower才能提交,没有生成的日志有可能被替代
- 具体流程
- leader接受到写请求,将日志通过rpc复制到所有的follower中
- 等待超过半数的follower复制成功并且返回ack(就是下一个心跳包)之后,leader会提交日志到版本库,并且返回应用层成功的消息
- leader告诉所有的follower让他们提交
- follower提交
follower宕机
- 如果follower没有响应,leader会不断进行重发到该follower尝试
- follower回复之后会进行一致性检查恢复缺失的日志
当发送一个 AppendEntries RPC 时,Leader会把新日志条目紧接着之前的条目的log index和term都包含在里面。如果Follower没有在它的日志中找到log index和term都相同的日志,它就会拒绝新的日志条目。
leader宕机
- 如果宕机的leader还有日志未提交,那么可能出现其他leader强制性覆盖旧leader未提交的数据
安全性
投票
- 如果投票者手上的日志信息比candidate还新,就会拒绝该请求
相同任期比日志号,不同任期比任期号,日志号不是提交了的日志号,而是存在的日志号码(没有提交的也算)
日志
- leader只会对自己的任期内的日志计算副本数目的提交,上一个任期内的日志不会被马上提交,只有自己产生了新日志才会进行统一提交
成员变更
联合一致
- 采用两阶段的方法避免脑裂问题
- leader发起rpc请求,使整个集群进入联合一致的状态,此时rpc在新旧两个配置都要达到大多数才算成功
- leader发起rpc,整个集群进入新配置状态,能达到大多数就算成功,在新增节点时,需要等待新增的节点完成日志同步才开始成员变更
- 复杂,使用较少
单节点变更
- 完成增加节点的日志同步
- leader发送rpc请求,等待大多数之后就可以提交标识成功
数据读写
- 写请求统一发送到leader
- 读请求到了 follower 后,follower会去向 leader 请求 readindex(也就是当时 leader 的 commitindex), leader 在确认自己还是 leader 之后,就会吧 readindex 发给 follower,follower 会对比自己的 commitindex 和 readindex,只有commitindex 大于等于 readindex 之后,才能读取数据返回.
ETCD
- etcd 就是底层使用raft实现的一个kv类型的数据库,可以保证强一致性,属于CP类型的数据库
参考
- https://raft.github.io/
- https://zhuanlan.zhihu.com/p/32052223