微信的tablekv底层就是一个leveldb
应用场景
- 读少写多的情况
- 日志系统
- 消息队列
- 分布式储存
- 缓存
特点
- 底层使用LSM技术构建储存
- 利用了磁盘的顺序写必随机写快的多的特点
- 只提供Get,Put,Delete接口
优点
- 强大的写性能
- 强大的可靠性
缺点
- 牺牲了sql的结构化,完全退化为KV
- 牺牲一定的读性能
- 不支持多线程写入
- 生成很多文件,管理麻烦
WAL
- Write Ahead Log,写入前先写日志,至于日志的刷盘时机可以通过
- 每次写入都做一次
sync,可靠性最高,不会丢数据,但是性能最低; - 每次写入,但是不
sync,数据库崩溃不会丢数据,但是机器崩溃会丢数据,性能高,底层实现是共享内存,即使数据库崩了,内存也不会马上被回收; - 每次写入,不
sync,但是每1s做一次sync,数据库崩溃不会丢数据,但是机器崩溃丢最多1s的数据,性能较高。
- 每次写入都做一次
LSM
- Log-Structured-Merge-Tree
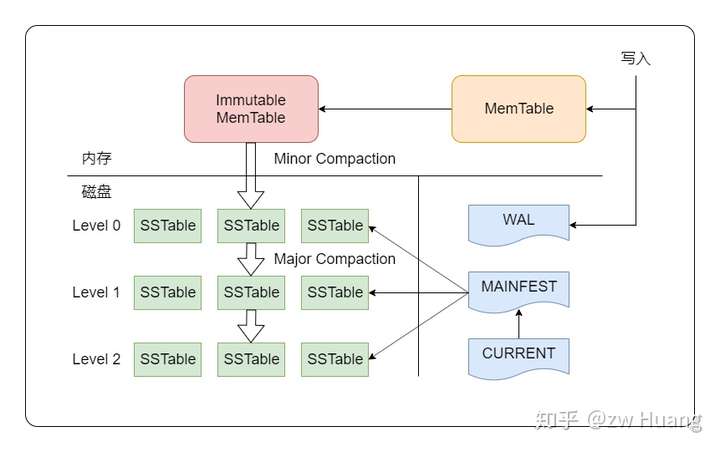
- 分级储存,分为在内存中的MemTable,在磁盘中的SSTable
- 有一个lru缓存用于缓存sstable的热点数据,避免多次io读取,而且是以Data Block为最小单位进行缓存
PUT流程
- 先写日志(顺序写)
- 按照key的字典序排序key,维护一个有序的map,leveldb使用跳表实现,将这个key,val插入跳表(如果已经存在直接更新)
- 判断跳表的容量是否太大,太大将memtable刷成sstable0,新建新的sstable0
- 如果sstable0的数量太多(大概十倍),会将所有的sstable归并合并成一个大的sstable1,相同的key会直接合并(取最新的),sstable1也类似
DELETE流程
- 和PUT的流程类似,只是key的状态打上delete的状态
GET流程
- 计算key的int值,在memtable中查询这个key是否存在,如果存在直接返回,
- 如果不存在,在sstable0层寻找,找不到去sstable1找,找到之后将数据加入LRU缓存,为了避免尽量避免找太多次,每个table都维护布隆过滤器,先经过布隆过滤器,再进行二分查找
索引实现
- 感觉上和B+索引的思想类似,计算索引字段对应的key值,然后构建跳表,key为计算值,val为原来的主键key,查找到主键key之后进行回表查询真实的数据
QA
为什么索引使用有序二分而不是哈希
- 存储的方面,hash磁盘的落地很麻烦,更何况还要用过链表存储解决hash冲突
- 这样设计使得范围查询和排序成为可能,hash无法范围查询
- 因为redis是内存数据库,快是主要的需求,因此用字典,和leveldb有差别
tablekv(Quorum_KV)
- 底层是leveldb,但是套了一层paxos分布式协议,保证高可用性,但是通过LSM树的形式使得具有很快的写入速度,是一个非常厉害的平衡了可用性和速度的数据库(通常这两者是冲突的),但是读的速度比较慢,但是因为微信读写比例接近1:1,因此影响不大
总结
- 很多公司最终都转型到这个数据库上面,大部分数据存储其实使用kv类型就足够了,对ACID业务型需求不是刚需
- mysql这种写入速度完全不满足需求
- redis这种满足需求了但是不可避免存在极端情况下数据丢失,因此不可能作为磁盘的持久化存储方案
- 两者一起使用时之前的解决方案,但是缺点是一致性本质上是CAP的无解问题,解决一致性麻烦太大,如果对强一致性没有太大需求,用这个也可以,但是代码负责心和出错率会增加
- leveldb属于均衡选手,牺牲本来就很快的读性能为写性能让路(在磁盘上),本身携带了缓存的系统,使得相当于将缓存和数据进行了结合,,具有极强的写性能和较强的读性能,因此很多公司最后的数据库选型都是这种
组件对比
| 公司 | 字节 | 腾讯 |
|---|---|---|
| 组件 | abase | tablekv |
| 底层 | RocketDB(底层也是LevelDB改编而来) | LevelDB |
| 上层组件 | 上层通过类似 slots 分配的形式, 每个负责处理的集群再通过主从复制的方式实现一致性的, 只能保证最终一致性, 本质上和 redis的多集群方式类似 redis实现 | 套了一层 paxos 协议, 能够保证强一致性 |
参考
- https://juejin.cn/post/7123922716419178526
- https://zhuanlan.zhihu.com/p/206608102
- https://zhuanlan.zhihu.com/p/361699941