项目架构
泳道
[!question] 出现背景
- 关于一个服务上的多个需求的同时测试,存在服务抢占分支测试的问题;
- 不同的业务组在测试时依赖的第三方服务有改动或正在进行新需求测试影响本业务测试。
- 对服务链按需求进行分组复制,并实现逻辑、物理的隔离,使得不同需求的服务链运行在相隔的环境上,逻辑上如同游泳场中的泳道。

实际上就是解决多个微服务多个版本同时进行测试时候环境隔离的问题,服务注册发现只能发生在同一条泳道上
特性
- 泳道相当于提供了多条“请求的跑道”,理解泳道主要在于理解“流量跑到哪去了”:
- 泳道内如果没有部署被调用服务,流量会fallback到骨干 – 比如上图[泳道-2]中的B服务节点 调用了[骨干链路]中的C服务节点
- 泳道内若存在被调用节点,那么流量是一定不会fallback的 (包括不可用的和禁用的) – 比如上图[泳道-2]中的A服务节点 只会调用 [泳道-2]中的B服务节点,即使[泳道-2]中的B不可用,也是不会fallback的
- 骨干环境是一定不会调用到泳道内的 – 比如上图中绝逼不会有 从[骨干链路]到[泳道-2]的调用
- 泳道之间是一定不会互相调用的 – 比如上图中绝逼不会有 [泳道-1]与[泳道-2]之间的调用
MCV架构
model
- 数据库连接层,有关数据库的操作都在这一层
- 这一层出现错误不打日志,向上层传递到control层
control
- 核心逻辑层,实现核心且复杂的逻辑(传统的CURD业务一般这一层很少),需要调用的部分直接调用model层的内容
- 这一层出现的错误需要打日志记录并向上传递到view层
view
- 路由层,直接对接前端的数据,对数据进行基本的合法性校验,转换为内部格式后传递给control层
- 这一层出现错误不打日志,直接将错误返回给客户端
DDD架构
领域驱动模型

interface层
- 接入层和mcv中的view层类似,提供对外的接口
application层
也称为biz层
- 应用层,流程编排服务,不承担业务逻辑,只负责调用和组装application
domain层
- 核心逻辑层面,称为实体,直接操作数据库,以及实体的所有操作,但是不能调用和依赖其他任何的其他domain,降低耦合度,是实现的核心逻辑的地方
- domian之间禁止直接相互调用,必须相互隔离
DAO/Infeastructure层
- 任何数据源,包括数据库或者其他的系统
防腐层

- 核心就是通过独立一个层次为了防止第三方接口污染我们的领域服务,类似设计模式中的适配器模式,完成参数的映射
- 这样可以只更改防腐层的内容,不会影响领域内的内容,其实就是多加了一个中间层
MCV和DDD区别
- mcv被称为失血模型,因为实体的具体逻辑是在service层,如果操作复杂,很容易导致service膨胀,有点面向过程的味道,实体是在model,但是逻辑在service层
- DDD完全是面向对象式,充血模型,充血地方在于domain既是实体也承担了该实体的所有操作,可以想象成为一个类application只用于编排和组合
- DDD更加适合大型系统的开发,MCV更加合适用于小型的系统,DDD实在太复杂了,还引入了类似防腐层的概念
项目指标
服务降级
- 系统有限的资源的合理协调
- 概念:服务降级一般是指在服务器压力剧增的时候,根据实际业务使用情况以及流量,对一些服务和页面有策略的不处理或者用一种简单的方式进行处理,从而释放服务器资源的资源以保证核心业务的正常高效运行。
- 原因: 服务器的资源是有限的,而请求是无限的。在用户使用即并发高峰期,会影响整体服务的性能,严重的话会导致宕机,以至于某些重要服务不可用。故高峰期为了保证核心功能服务的可用性,就需要对某些服务降级处理。可以理解为舍小保大
- 应用场景: 多用于微服务架构中,一般当整个微服务架构整体的负载超出了预设的上限阈值(和服务器的配置性能有关系),或者即将到来的流量预计会超过预设的阈值时(比如双11、6.18等活动或者秒杀活动)
- 服务降级是从整个系统的负荷情况出发和考虑的,对某些负荷会比较高的情况,为了预防某些功能(业务场景)出现负荷过载或者响应慢的情况,在其内部暂时舍弃对一些非核心的接口和数据的请求,而直接返回一个提前准备好的fallback(退路)错误处理信息。这样,虽然提供的是一个有损的服务,但却保证了整个系统的稳定性和可用性。
比如遇到过年抢红包的时候朋友圈的延迟是可以接受的,直接返回没有新的朋友圈,把宝贵的资源用在重要的地方
- 降级分成3种
- 功能降级预案, 对下游某些依赖的功能的降级, 当然这块有时候和熔断一起用, 通常是某个功能模块走兜底或者暂时不可用
- 压力降级预案, 用于应对正常节假日等流量激增, 损耗一定的功能保证服务可用性正常
- 极端降级预案, 最坏的准备, 默认假设是所有下游全部崩溃, 所有的依赖全部完蛋, 只有自己能用的情况下如何给用户返回一些兜底的信息而非直接报错
服务熔断
- 应对雪崩效应的链路自我保护机制。可看作降级的特殊情况
- 概念:应对微服务雪崩效应的一种链路保护机制,类似股市、保险丝
- 原因: 微服务之间的数据交互是通过远程调用来完成的。服务A调用服务,服务B调用服务c,某一时间链路上对服务C的调用响应时间过长或者服务C不可用,随着时间的增长,对服务C的调用也越来越多,然后服务C崩溃了,但是链路调用还在,对服务B的调用也在持续增多,然后服务B崩溃,随之A也崩溃,导致雪崩效应
- 服务熔断是应对雪崩效应的一种微服务链路保护机制。例如在高压电路中,如果某个地方的电压过高,熔断器就会熔断,对电路进行保护。同样,在微服务架构中,熔断机制也是起着类似的作用。当调用链路的某个微服务不可用或者响应时间太长时,会进行服务熔断,不再有该节点微服务的调用,快速返回错误的响应信息。当检测到该节点微服务调用响应正常后,恢复调用链路。
- 服务熔断的作用类似于我们家用的保险丝,当某服务出现不可用或响应超时的情况时,为了防止整个系统出现雪崩,暂时停止对该服务的调用。
比如遇到A依赖B,但是B崩溃了,导致B请求很慢,导致A服务大延迟使用,整条链路上服务都会出问题,为了避免这个情况使用熔断,B模块的请求直接返回失败
吞吐量指标
- 通过响应时间Response Time(如P99,P95),最大每秒请求数(QPS),Concurrency并发数来衡量
QPS
- 每秒响应的请求数,通常用于衡量系统的处理能力。mysql的qps大概在几千到几万左右,redis在十万到百万级
RT
- 按照响应时间从小到大排序, 99%的接口响应时间即为 P99 的时间,通常来说,随着QPS和Con的上升,RT也会上升
Concurrency
- 指系统同时能处理的请求数量,这个也反应了系统的负载能力
测量方法
- 使用性能测试工具对系统进行压力测试,模拟多个客户端同时向服务器发送请求,以获得最高的QPS和网络并发数。在测试过程中,可以逐步增加请求的并发数,直到系统达到极限,即无法再处理更多的请求为止。这时,所得到的QPS和网络并发数即为系统的最高值。
- 在测试中同时监测系统的响应时间,以获得R99值。要获得R99值,可以先计算出所有请求的响应时间,然后按照从小到大的顺序排序,最后取出排在99%位置上的响应时间,即为R99值。
部署方式
Serverless
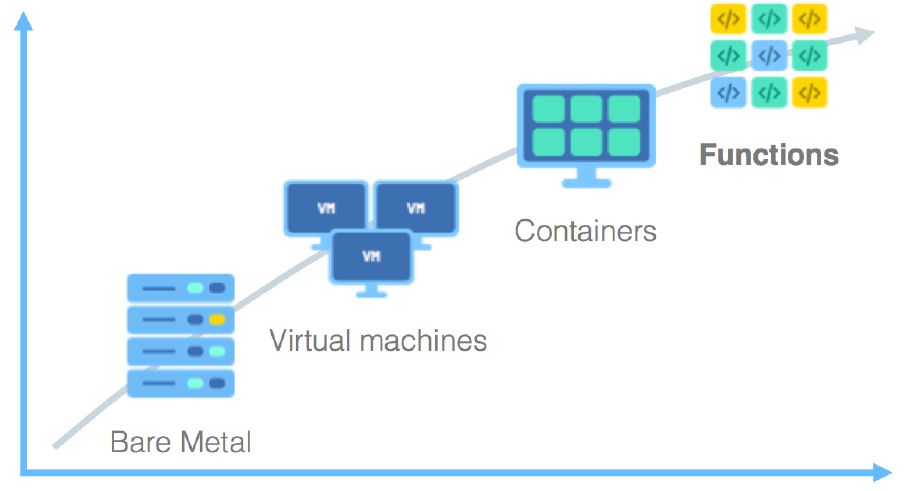
- 实际上是一个转变:实体机器->虚拟机(云服务器)->容器(docker)->云函数(serverless)
- 只需要关注核心逻辑的功能,不需要考虑资源和并发容灾的问题
优缺点
- 更加关注逻辑,将运维的工作完全替代,将扩容等操作交给云服务器厂商
- 不会有资源的浪费,按使用量付费
- 和框架强依赖,一旦换一家云服务器厂商,代码移植麻烦,自己存在的前提是云服务厂商存在
- 大部分是小厂在用
相关工具
工程Git使用
How to create an issue
- https://zhuanlan.zhihu.com/p/75691927
How to create an pr github
代码
兼容性
- 所有的程序和代码必须向下兼容,除非整体所有代码重构,所有对外的接口无论什么情况下都需要向下兼容
- 所有的字段绝对不能删除和更改!,所有的更新不能损坏已有的功能,需要做到绝对的向下兼容
整洁
- 圈复杂度尽量在10以内,保证长久的重构性
- 尽量避免代码重复,抽象成为公共的函数或者部分
个人感想
- 项目只有自己经历过自己去做过,才知道里面的易错点在哪里
- 项目只有上线过,有用户使用,才知道系统的瓶颈在哪里和如何改进
- 自己看懂的项目只知道原理,但是并不知道项目的核心要点目标是什么,核心难点是什么,这样的项目拿出去讲只会露馅,只有自己做过的项目,实际上上线了的项目才能作为核心拿出来讲
系统设计要点
系统设计四步法
- 了解问题并确定设计范围:确认一下这个设计题目的设计重点在什么地方,大概需要承受多大的流量和DAU
- 提出高层次的设计:整体上的架构设计,比如设计用到什么组件,这些组件分别在哪个地方,也可以画个草图
- 设计重点实现的部分:有些部分是这个系统设计的重点,比如短链系统的url hash计算生成,im系统的推拉模型
- 讨论后续问题:比如哪个地方可以优化,性能瓶颈在怎么地方,如何进行水平扩展
三大要点
- 结构性: 怎么划分结构层次, 最重要的性质, 直接决定了整个系统的可维护性以及优雅性, 是系统设计最底层的部分
- 扩展性: 但这个系统承担更多的业务需求, 出现更多的业务场景时候如何应付复杂度的提升, 这个时候时候是否会会损坏系统的结构性和优雅性
- 容灾性: 但出现不可预期的风险时候如何作兜底容灾而不是系统直接 down 掉, 如何减少下游依赖并且默认下游不可用性
- 前面一点是传统的系统设计的基础,也是之前一直学得, 后面两点才是工作之后才发现一样重要的, 特别是当你处理的是高度复杂的业务系统和不停迭代的用户需求以及高可用性的保障时
代码仓库管理方式
- monorepo 和 multirepo
monorepo
- 相当于大型的仓库, 整个项目相关的所有代码都放到一个 git 仓库统一管理, 类似google 就是采用 monorepo
- monorepo可以避免下面 multirepo 出现安全性的问题, 因为 lib 和 src 作为一起的 review 可以轻易发现错误的代码
multirepo
- 目前绝大多数公司采用的方式, 按照 功能/mcv/ddd 来进行划分, 每个git仓库就是一个微服务或者共享的 lib库
- 这种对于 go 来说有个致命的缺点, 不安全性
- go 可以直接通过 go get 将包直接引入, 这种情况下即使是分支也可以直接引入, 但是如果恶意代码放在某个 lib 的 banch 上(这是非常简单的, 创建分支的权限 rd 都有的), 然后通过 go get 引入, 这种情况下 go.mod 只会记录hash 值, 甚至不会计算时间, 这就导致 codereview 所有的 go.mod 的依赖基本是不可能的 , 最后就是可以轻松实现注入恶意代码
参考
- https://zhuanlan.zhihu.com/p/337708438