所有方案
UUID
通常不用来作为分布式id,更多作为临时幂等串
- UUID的生成算法基于时间戳、节点ID和随机数等多个因素,能够在分布式系统中保证消息id的唯一性,是一个字符串
优点
- 唯一性比较好,生成无需联网,本地就可以生成,全球唯一(绝大概率)
缺点
- 是一个字符串而不是int导致查询索引都非常慢
- 不能保证递增性,没什么业务相关含义
Snowflake
通常用于只需要保证唯一性不需要绝对递增性的场景(如订单id)
- 大名鼎鼎的facebook雪花id生成算法,生成方法如下
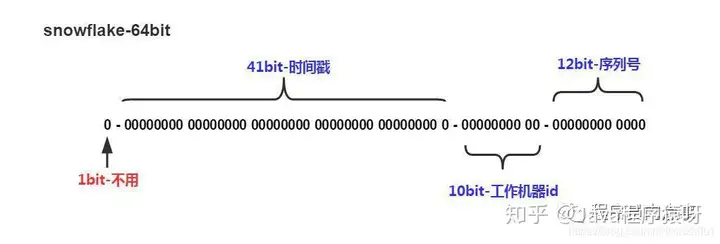
优点
- int64类型,检索更加快速
- 生成快,通过拼接生成
- 蕴含这时间戳和机器id,通过这个快速定位机器和时间
缺点
- 无法保证绝对的递增性(趋势递增还是有的,因为时间戳)和连续性
- 时钟回拨可能导致出现重复id的问题
- 解决时钟回拨的问题可以参考,实际上还是通过定时上报时间(比如3s),本地关闭NTP时间同步,然后新上线检查自己的时间和之前上报的时间差距

- 解决时钟回拨的问题可以参考,实际上还是通过定时上报时间(比如3s),本地关闭NTP时间同步,然后新上线检查自己的时间和之前上报的时间差距
这里的时钟回拨是因为本地的时间可能出现漂移但是机器上的时间校准协议自动校准导致出现时间回拨
百度UidGenerator

- delta seconds (28 bits) 这个值是指当前时间与epoch时间的时间差,且单位为秒
- worker id (22 bits) 生成worker id,需要创建一张表,机器启动之后先数据库中的表插入一条数据,获得一个自增id . 所有实例重启次数是不允许超过4194303次(即2^22-1),否则会抛出异常
- sequence (13 bits) 每秒下的并发序列,13 bits可支持每秒8192个并发
DefaultUidGenerator
流程
- 如果时间有任何的回拨,那么直接抛出异常;
- 如果当前时间和上一次是同一秒时间,那么sequence自增。如果同一秒内自增值超过2^13-1,那么就会自旋等待下一秒 (其实这个部分普通的雪花算法也可以用,但是普通雪花用这个也解决不了快速重启重复id的问题)
- 如果是新的一秒,那么sequence重新从0开始;
- 简单粗暴直接通过获取当前时间比较避免始终回拨
[!question] 缺点 性能不够好,拒绝采样次数可能很多
CachedUidGenerator
这个和上面是两种generator
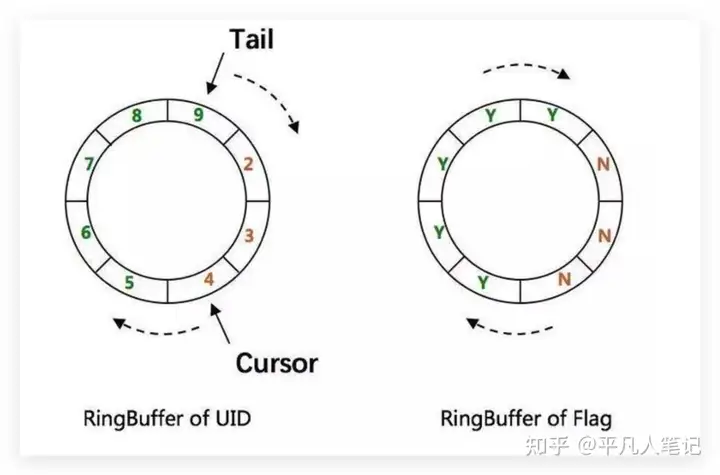
- RingBuffer Of Flag 标识位,表示目前UID数组的状态
- 其中,保存flag这个RingBuffer的每个slot的值都是0或者1,0是CANPUTFLAG的标志位,1是CANTAKEFLAG的标识位。每个slot的状态要么是CANPUT,要么是CANTAKE。以某个slot的值为例,初始值为0,即CANPUT。接下来会初始化填满这个RingBuffer,这时候这个slot的值就是1,即CANTAKE。等获取分布式ID时取到这个slot的值后,这个slot的值又变为0,以此类推。
- 保存唯一ID的RingBuffer有两个指针,Tail指针和Cursor指针。
- Tail指针表示最后一个生成的唯一ID。如果这个指针追上了Cursor指针,意味着RingBuffer已经满了。这时候,不允许再继续生成ID了。
- Cursor指针表示最后一个已经给消费的唯一ID。如果Cursor指针追上了Tail指针,意味着RingBuffer已经空了。这时候,不允许再继续获取ID了。
- RingBuffer Of UID 保存生成的id
流程
- 根据每秒的大小生成两个buffer
- 构造RingBuffer,默认paddingFactor为50。这个值的意思是当RingBuffer中剩余可用ID数量少于50%的时候,就会触发一个异步线程往RingBuffer中填充新的唯一ID,这个线程中会有一个标志位running控制并发问题),直到填满为止
- 初始化填满RingBuffer中所有slot
- 开启buffer补丁线程,每次触发填充的时候都自动添加1s然后生成一堆id慢慢填进去,填满为止
// fill the rest slots until to catch the cursor
boolean isFullRingBuffer = false;
while (!isFullRingBuffer) {
//获取生成的id,放到RingBuffer中。
List<Long> uidList = uidProvider.provide(lastSecond.incrementAndGet());
for (Long uid : uidList) {
isFullRingBuffer = !ringBuffer.put(uid);
if (isFullRingBuffer) {
break;
}
}
}
关键点
- 解决时钟回拨的关键: 在满足填充新的唯一ID条件时,通过时间值递增得到新的时间值(lastSecond.incrementAndGet()),而不是System.currentTimeMillis()这种方式,而lastSecond是AtomicLong类型,所以能保证线程安全问题。在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制; 采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费,最终单机QPS可达600万。
- 自增列:UidGenerator的workerId在实例每次重启时初始化,且就是数据库的自增ID,从而完美的实现每个实例获取到的workerId不会有任何冲突。
- RingBuffer:UidGenerator不再在每次取ID时都实时计算分布式ID,而是利用RingBuffer数据结构预先生成若干个分布式ID并保存。
- 时间递增:传统的雪花算法实现都是通过System.currentTimeMillis()来获取时间并与上一次时间进行比较,这样的实现严重依赖服务器的时间。而UidGenerator的时间类型是AtomicLong,且通过incrementAndGet()方法获取下一次的时间,从而脱离了对服务器时间的依赖,也就不会有时钟回拨的问题
[!question] 缺点 因为是使用自己的时间因此很可能导致其中的时间含义并不准确(不是系统时间),但是这部分可以使用隔一段时间进行系统时间校验解决,中期也不会重复id,因为work id不同
MongoDB
- objectId的前4个字节时间戳,记录了文档创建的时间;接下来3个字节代表了所在主机的唯一标识符,确定了不同主机间产生不同的objectId;后2个字节的进程id,决定了在同一台机器下,不同mongodb进程产生不同的objectId;最后通过3个字节的自增计数器,确保同一秒内产生objectId的唯一性

优点
- 唯一性比较好,生成无需联网,本地就可以生成,全球唯一(绝大概率)
缺点
- 是一个字符串而不是int导致查询索引都非常慢
- 不能保证递增性,没什么业务相关含义
Mysql
- 直接用插入的id作为只增id
优点
- 简单,保证递增性,唯一性,连续性
缺点
- 数据库压力大,如果不需要存储的数据浪费存储空间
- 插入数据库还是很慢的过程
Redis
- 通过一个key的incr加lua生成id
优点
- 快,无需数据库io操作,递增性,连续性
缺点
- 当redis宕机,无论是RDB还是AOF都会出现不是最新的id,导致无法判断最新的id发到什么地方了,无法保证绝对唯一性
- 一致AOF插入incr,redis回复时间过长
Leaf
-
通过提前拿号段的形式,就算宕机只会导致不连续,而不会重复
gennerator
- 分布式ID生成器

- 通过提前拿号和异步检查分配的办法(每次分配之后查一下是否已经分配超过60%,如果超过了,异步开协程那下一个号段)解决mysql速度不够快的问题
- 号码一定递增,但是不一定连续(因为如果宕机,下次回复只能拿到下一个号段,无法确定上一个号段是否发完了)
- 通过负载均衡,使得同一个号码的拿取服务全都打到同一台机器上,避免了出现因为多个号段同时发号导致号码不递增的问题
- 通过一致性hash实现自动容灾和恢复,类似[[redis实现#一致性hash算法(一致性哈希)]]
- 构建主机数组,使用二分搜索搜索key对应处理的主机端口ip
- 当处理的机器更改时候(添加或者删除),向旧的机器发送删除内存对应号段的通知(这里需要确保加入的都是新启动的,内存没有号段的,这个特性依赖微服务框架的隔离机制),这里的删除不是新的机器删除,而是框架中自带的client调用端发rpc请求删除
- rpc请求拿到所有的发号机器的ip和port,一致性hash算出自己访问哪一台机器
- 检查是否和上一次请求的机器相同,如果不相同,向上一台机器发送删除的通知,如果因为下线,连接失败没关系,如果在线,会删除缓存中的号段
- 向请求的机器发送rpc请求申请发号
- hash环的计算全部都在client中,和服务端无关
- 使用的是类似锁的机制(实际上使用的是sync.map)
//从本地缓冲池获取已经设置的Segment Getter,并且调用获取设置的segment执行 //检查是否能够生产ids, 无法生成则回源获取segment if cachedSegmentFn, ok := pool.segments.Load(key); ok { segment := (cachedSegmentFn.(SegmentIDCacheGetter))() if segment == nil { logger.Errorf("Generator segment not found:%s[3]", key) return nil } var isAccord bool nextIDs, isAccord = nextIDFn(segment, 0) //满足条件1 if isAccord { return nextIDs } applyed = int64(len(nextIDs)) //重置key对应的segment fn, 否则sync.Map的LoadOrStore无法正确执行 pool.segments.Delete(key) } //multi-goroutine情况下并发获取的都是waitGetter,仅当唯一获取了segmentFn的Goroutine完成初始化后返回 var startTime = time.Now() var initSegment *entity.NamespaceSegment var wg sync.WaitGroup wg.Add(1) waitGetter := func() *entity.NamespaceSegment { wg.Wait() return initSegment } //only one goroutine to call fn() //大量协程尝试写入这个sync.map segmentGetter, loaded := pool.segments.LoadOrStore(key, SegmentIDCacheGetter(waitGetter)) if loaded { //因为多个协程竞争导致,大部分协程到这个地方,然后进行等待,**注意,这里等待的并不是自己的wg,因为自己的wg压根没有成功存进去,等待的是成功存进去的wg,即拿到执行权限的wg** //block here wait first getter done segment := (segmentGetter.(SegmentIDCacheGetter))() if segment == nil { return nil } nNextIDs, isAccord := nextIDFn(segment, applyed) if !isAccord { return nil } return append(nextIDs, nNextIDs...) } //成功写入的协程到这部分 //Store成功,初始化Request initSegment = segmentFn() wrapGetter := func() *entity.NamespaceSegment { return initSegment } pool.segments.Store(key, SegmentIDCacheGetter(wrapGetter)) //完成wg,通知其他协程起来 wg.Done() //////////////////////////////////////////////// // 这部分是nextIDFn的内容,底层还是使用atomic实现的 func(segment *entity.NamespaceSegment, applyedN int64) ([]int64, bool) { var apply = n - applyedN //有效的ID列表, 超出保留的ID列表 var validIDs []int64 var counter *int64 if iCounter, ok := globalCounter.Load(key); !ok { return nil, false } else { counter = iCounter.(*int64) } // 注意这里是先进行原子递增,在进行拿出号码,这样可以实现多个协程一起拿的操作 nextID := atomic.AddInt64(counter, apply) if nextID <= segment.MaxID { for s := nextID - apply + 1; s <= nextID; s++ { validIDs = append(validIDs, s) } return validIDs, true } else { for s := nextID - apply + 1; s <= segment.MaxID; s++ { validIDs = append(validIDs, s) } return validIDs, false } - 分布式ID生成器
优点
- 快速,提前在内存中直接发
- 绝对递增性和保证唯一性
- 可以通过hash环进行容灾
缺点
- 宕机会出现不连续的情况
- mysql拿的一下出现抖动以及缓慢(可以通过提前拿号缓解)
微信方案
实现
- 底层也是基于mysql号段模式,不够提前拿号
- 模型还是存在一个问题:重启时要读取大量的max_seq数据加载到内存中。为了解决这个问题,微信使用的方式是相邻uin的用户一起使用同一个发号器

容灾
微信
- 使用主从容灾的办法,出现问题及时切换
- 因为svrkit的路由机制,因此最多试错一次就可以拿到正确的信息(不过这样利用率低)
企业微信
- 使用一致性hash,类似tira-others > gennerator,但是容灾的方式更加的简单
- 请求到服务器,服务器首先查看自己缓存中是否存在这个号的号段,每次读取都必须需要访问数据库一次(这里理论上性能很差,但是实际上用的是分布式kv,开销不是很大)
- 如果不存在,给数据库的max_id向前移动一步,如果存在但是和数据库版本不一样也会移动

参考
- https://www.infoq.cn/article/wechat-serial-number-generator-architecture
- https://tech.meituan.com/2017/04/21/mt-leaf.html
- https://zhuanlan.zhihu.com/p/152179727