[!important] 这部分都是看一些系统设计的书籍总结出来的,觉得有点意思的地方,没有自己真正写过,仅供参考
短链系统
- 相当于给定一个长链转化成为短链,用于在推特这种限定字数的帖子的场所放链接
重点
- 如何保证6个字符组成的短域名的唯一性和安全性,避免重复和让别人分析逐个爬取
- 如何选取合适的数据库和存储结构
- 如何实现过期后失效
思路
- 域名的生成几种办法
- hash,太长了大于6个字符,如果截断会有冲突风险
- 自增id,可以使用数据库自增key,大小也满足,唯一性也满足,但是不满足安全性,很容易猜出数据
- 域名最终方法:
- 字符选取{0-9,a-z,A-Z}62个字符(url大小写不敏感,但是服务器处理敏感),组合6个字符有起来有568亿种组合,完全满足要求,考虑到安全性,使用五位数,最后那一位作为校验位(自定义域名直接使用5位)
- 使用自增id,但是生成的id和某个magic num相异或(相当于简单加密),最后转换为62进制
- 生成的数字hash加密(hash中再加上一个magic num),加密最后一位mod62作为最后一个数字
- 数据库选择:
- 因为关系型非常弱对事务没啥要求,没必要选mysql这种,写流量也不小直接上leveldb,再配上短链作为private key和index
- 读流量非常大,一定上redis进行缓存,可以根据域名hash的结果进行一致性hash的负载均衡redis实现 > 一致性hash算法(一致性哈希)
- 过期删除设计:
- 选择记录过期时间,从leveldb读的时候查一下是否过期,过期就返回无效
- 存到redis的时候注意一下使用
min(过期时间-现在,统一缓存时间)作为过期时间
流程
- "写"的时候
- 如果是自定义域名尝试插入康康是否有唯一键冲突,这里不能先查后加,因为出现原子性问题
- 如果是默认直接插入记录获取id,计算之后将结果写入并返回
- "读"的时候
- 根据前5位校验最后一位的正确性,相当于本体的布隆过滤器,不符合直接pass(这样可以尽量避免缓存穿透)
- 从redis中查找是否存在数据,如果不存在就从leveldb拿出来并且缓存到redis(这部分可以设置缓存时间然后每次访问刷新,也可以直接使用LRU或者LFU),将访问记录和信息异步扔到消息队列里面后直接返回
- 后台分析的进程负责消费和分析
细节优化
- 业务上可以提前拿一批号(提前插入空白+status),然后记录先扔道消息队列+redis缓存后直接返回,异步写数据库,避免数据库承受不住压力
- 可以业务层上一个LRU本地缓存,避免redis,这种就是多级缓存的思想了操作系统 > All problems in computer science can be solved by another level of indirection
附近系统
- 地球为界,搜索(以及增加删除等)给定半径范围内附近的地点,然后附加一些打分之类的功能,类似滴滴的功能也可以用这个办法类似
- 数据量大,因为按照地球划分
- 高搜索,低更改
- 第一眼看上去有点像树和堆 > kdtree,但是直接使用kdtree会有直接的问题半径不好处理,kdtree可以找到最近的k个点,但是一旦出现范围查询就不太方便,每个都必须判断是否在范围内,而且很容易出现极度不平衡的问题,参考kdtree的缺点,以及每个地点都是一个节点,浪费空间
思路
- 因为地图是二维的并且不会有变化,因此可以通过网络划分的形式组织起各个地区,其中使用四叉树组织格子
- 每个格子中设置最大地区数量,如果超过了就继续划分格子,实现动态格子划分,刚开始整体地图就一个格子,后面随着地点增多逐渐划分
- 搜索的时候从最顶格的区域进行搜索,首先划定半径的区域,这个区域使用四点定位法,然后找到最小能完全包裹这个区域的node,然后将这个node的数据全部拿出来一个一个算+排序(排序可以根据评分和距离综合排序)


存储
- 地图的存储 准错左上角的点的经纬度,然后宽和高,目前点的id列表直接用指针,因为没什么需要顺序的地方,但是可能经常要改
typedef long long ID
struct Area{
ID area_id;
double longitude // 经度
double latitude // 纬度
// ... 一些乱七八糟的属性省略
}
struct Node{
ID node_id;// 这个id便于后续根据hash进行负载均衡到不同服务器
double longitude // 经度
double latitude // 纬度
double width // 区域宽度
double height // 区域高度
bool isDivided // 是否被划分
Node* children[4] // 继续的小区域
List<ID> area_list; // 存错区域内的建筑id(不使用指针是为了方便分别存储,避免集中化),如果isDivided=false才会存在
};
Geohash
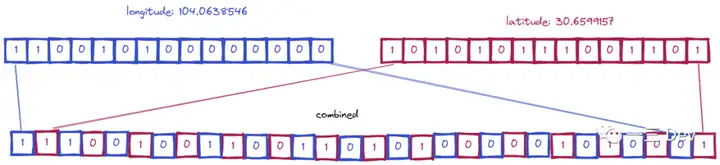
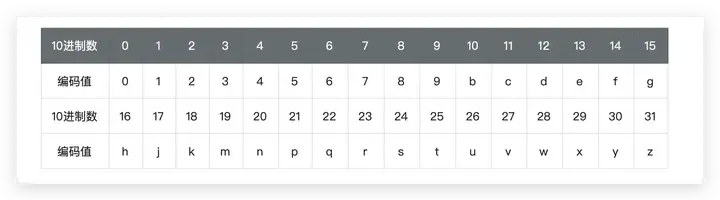
- 从第 0 位开始,偶数位放经度,奇数位放纬度,得到完整的二进制编码:将二进制编码分组(5个一组)并计算出对应的 Base32 编码
- 将二维坐标转换为字符串(Base32编码字符串)的形式,同一个区域方块内的坐标计算结果是相同的
- 长度越长,方格越小.一个GeoHash长度为1的格子包含32个GeoHash长度为2的格子
- 可以这个部分代替上面的经度和纬度的二维保存方法,四叉树直接放这个字符串,然后变成类似==前缀树==的方式存储位置,查询的时候直接比较字符串即可,或者存在数据库中使用like+%的方式查附近的人 树和堆 > trie tree(前缀树)
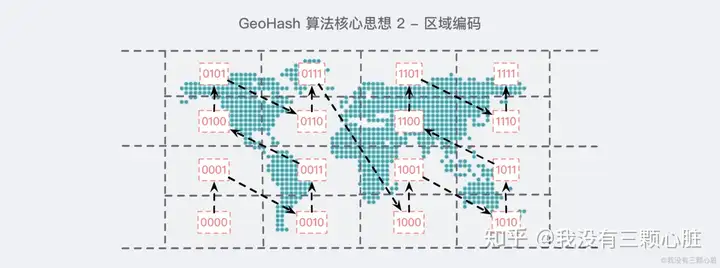
- 可以通过改变二进制串最后的几个01快速扩区附近的8个格子的hash,意味着可以在O1而不是Ologn的时间获取到附近的区域
文档系统
- 实现类似在线文档的功能,支持写作在线编辑
重点
- 如何实现协作而不冲突
- 如何实现底层的文件系统
思路
- 操作转换:每个提交带上版本号和操作的内容,然后服务器根据更改的版本以及当前的版本变化进行转换(通过类似git diff进行对比),顺序处理请求 #TODO 这里还可以深入探究一下
[!example] 当 A 通过在开头添加 x 来编辑文档时,这个改变将与 A 所看到的最后修订一起发送到服务器。假设此时 B 删除最后一个字符 c ,并且这个改变也是这样发送到服务器。 由于服务器知道修改在哪个版本上进行,因此会相应地调整更改。更具体地说,B 的变化是删除第三个 字符 c ,它将被转换为删除第四个字符,因为 A 在开头添加了 x 。
缓存系统
LRU
![[单调栈和链表双指针#146. LRU 缓存]|LRU]]
LFU
460. LFU 缓存
请你为 [最不经常使用(LFU)](https://baike.baidu.com/item/%E7%BC%93%E5%AD%98%E7%AE%97%E6%B3%95)缓存算法设计并实现数据结构。
实现 `LFUCache` 类:
- `LFUCache(int capacity)` - 用数据结构的容量 `capacity` 初始化对象
- `int get(int key)` - 如果键 `key` 存在于缓存中,则获取键的值,否则返回 `-1` 。
- `void put(int key, int value)` - 如果键 `key` 已存在,则变更其值;如果键不存在,请插入键值对。当缓存达到其容量 `capacity` 时,则应该在插入新项之前,移除最不经常使用的项。在此问题中,当存在平局(即两个或更多个键具有相同使用频率)时,应该去除 **最近最久未使用** 的键。
为了确定最不常使用的键,可以为缓存中的每个键维护一个 **使用计数器** 。使用计数最小的键是最久未使用的键。
当一个键首次插入到缓存中时,它的使用计数器被设置为 `1` (由于 put 操作)。对缓存中的键执行 `get` 或 `put` 操作,使用计数器的值将会递增。
函数 `get` 和 `put` 必须以 `O(1)` 的平均时间复杂度运行。
- 通过有序map记录每一条key的使用频率,自动排序,用hash记录key和val关系,时间复杂度log(n)
- 通过双hash机制,一个hash记录使用频率和一个链表,一个hash记录key和node*,当查询时候,增加使用频率,从hash中的链表拿出,换到下一个使用频率hash的链表,时间复杂度为O(1),重要
- 需要维护一个minFreq的变量,用来记录LFU缓存中频率最小的元素,在缓存满的时候,可以快速定位到最小频繁的链表,以达到 O(1) 时间复杂度删除一个元素。 具体做法是:
- 更新/查找的时候,将元素频率+1,之后如果minFreq不在频率哈希表中了,说明频率哈希表中已经没有元素了,那么minFreq需要+1,否则minFreq不变。
- 插入的时候将minFreq改为1即可。
[!question] 缺点 一个数字一旦积累了次数就很难被替换下来,但是很多时候有的数据遇有时效性 而且消耗大量空间,因为所有出现过的key都要记录频率
[!quote] 场景 如果数据有明显的热点,即某些数据被频繁访问,而其他数据则很少被访问,那么 LFU 算法比较适合。例如,一个视频网站的首页,某些热门视频会被很多用户频繁地访问,而其他视频则很少被访问,这时 LFU 算法就能够更好地满足需求。
SLRU
- 图中的右边部分,两个LRU组成,访问两次放入保护段,只能淘汰淘汰段的部分,保护段超过了旧放回去
- 代码参考gommon/cache/slru/slru.go at main · jiaxwu/gommon · GitHub
- 插入时候查询是否已经在淘汰段,如果在放入保护段,如果已经在保护段更新即可
- 如果不存在且未满(这个满是两个LRU之和和设置的大小),继续放入淘汰段
- 如果已经满,淘汰端最后一个淘汰
- 查询的时候类似,如果访问两次放入保护段
- 保护段长度如果超过选择最后一个放入淘汰段
[!question] 优缺点 一定程度上解决了纯LRU的额外难题,但是还是可能遇到突发流量占领的问题
W-TinyLFU
- 底层用到了 LRU,SLRU,以及布隆过滤器,CountMinSketch
- 所有的元素都需要进行CountMinSketch的次数统计,图中的pk指的是比较访问频率,中间相当于一个tidy的LUF
布隆过滤器
- 相当于bitmap,hash之后结果or后置1,如果得到的结果为0一定存在,但是为1 不一定存在
CountMinSketch
- CountMinSketch计数器的数据结构是一个二维数组,每一个元素都是一个计数器,计数器可以使用一个数值类型进行表示,比如无符号int,4位 最大值是15
- 使用多个hash减低污染,对于增加计数操作,每个元素会通过不同的哈希函数映射到每一行的某个位置,并增加对应位置上的计数
- 读取的时候读多个取最小的数字
频率统计
- 使用 布隆过滤器 作为计数器为1 的计数 使用CountMinSketch 作为计数器为16的计数,先过布隆,减少对本体16计数器的影响
保鲜机制
- 操作过一段时间会进行计数器的减少,减低临时流量的污染行为
- 布隆过滤器清空,计数器减半
[!tip] 参考 W-TinyLFU缓存淘汰策略 - 掘金
输入提示系统

- 底层还是trie
- 用于类似输入提示系统的时候可以和hashmap联合使用,记录trie 的node上对应最高的k个匹配结果
- 然后每周更新排名以达到提高速度的办法,因为对实时性要求没这么高