基础
- Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
- Redis使用引用计数实现内存回收
- Redis 有多个数据库,默认使用数据库0
- Redis使用epoll实现io复用,并且单线程,除了一些备份数据的操作fork多进程,其他均是单线程
内部结构
SDS
struct sdshdr {
// 记录 buf 数组中已使用字节的数量
// 等于 SDS 所保存字符串的长度
int len;
// 记录 buf 数组中未使用字节的数量
int free;
// 字节数组,用于保存字符串
char buf[];
};
- 一个可以存储二进制的字符串结构而已,类似string
- 二进制安全
使用场景
- 所有的key,以及string的Val类型,以及其他类型的字符串存储
链表
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;
} listNode;
- 朴实无华的双向链表
使用场景
- list数据结构
字典
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
typedef struct dictEntry {
void *key;// 键
union {
void *val;// 值
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
- unordered_map,哈希表
- 使用拉链法解决hash冲突

信息
- ht[1]只用于rehash(hash扩容)使用
- size为2的倍数,方便按照倍数扩容
- hash算法使用MurmurHash3
- 计算过程为先算出hash,然后和size &运算(保证不会超出范围),冲突时插入时候优先插入链表头部
rehash
服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于
1; 服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于5
- 渐近式,不会出现突发性能问题(还是用空间换时间)
- 按照倍数扩大
过程
- 为
ht[1]分配空间, 让字典同时持有ht[0]和ht[1]两个哈希表。- 在字典中维持一个索引计数器变量
rehashidx, 并将它的值设置为0, 表示 rehash 工作正式开始。- 在 rehash 进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将
ht[0]哈希表在rehashidx索引上的所有键值对 rehash 到ht[1], 当 rehash 工作完成之后, 程序将rehashidx属性的值增一。- 随着字典操作的不断执行, 最终在某个时间点上,
ht[0]的所有键值对都会被 rehash 至ht[1], 这时程序将rehashidx属性的值设为-1, 表示 rehash 操作已完成。
- 标识开始hash,在每次操作时候进行,按照顺序
- 均为单线程操作
操作
- 查找先在原来的查,找不到再查新的,删除,改变归同时操作两个
- 增加只在新的增加
使用场景
- 键值对的map映射
跳表
跳表
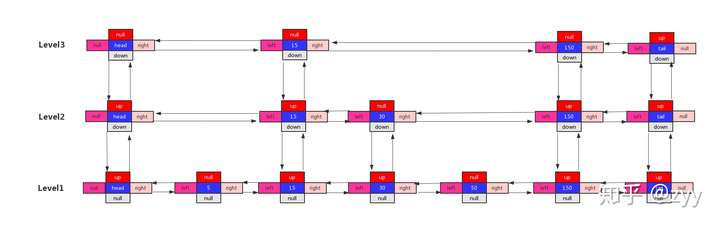
- 就是一个二维链表,从有序链表构建
- 最上层开始查,下一个比他小就向右,否则向下
- 插入数据后random,50%的概率向上插入,递归向上遍历

优缺点
- 实现简单,比平衡树简单多了
- 比B树占用内存更少
- 缓存局部性
确定层数
- level=log2(n) - 1,每一层是下一层的一半
typedef struct zskiplistNode {
// 后退指针
struct zskiplistNode *backward;
// 分值
double score;
// 成员对象
robj *obj;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
}
使用场景
- 需要排序的zset
为什么不用B+树
- 实现简单:跳表相对于B+树来说,实现起来更为简单,代码量也更少。这使得跳表更容易维护和优化。
- 更适合内存访问模式:Redis通常将数据存储在内存中,而跳表更适合于随机访问模式,能够充分利用CPU高速缓存,提高查询效率。
- 查询性能表现优秀:跳表的查找、插入、删除等操作都可以在O(log n)的时间复杂度内完成
- 范围查询不常用
整型数组
- 小型整数list用于节省内存的做法,底层就是数组,略
压缩列表
- listpack,小型只包含整数以及短串的list,节省内存做法.底层就是紧密排列的char数组.略
总结
- string 使用SDS实现
- list 压缩列表(小型)或者链表实现
- hash 使用压缩列表(小型,直接追加在尾部,查找直接遍历),或者字典实现
- set 整型数组或者字典
- zset 压缩列表(直接按照score排序)或者跳表(实际上又用字典再次保存了元素的val->score)实现
单机数据库
过期设置

- 使用另外一个dict储存按键的过期时间,添加过期时间时候插入链表
- 拿出时候和目前的time比较
常见删除策略
- 惰性删除(找key时候看一下,过期返回nil并且删除),对内存不友好
- 定时删除(定时遍历key查),对CPU不友好
redis策略
- 惰性删除和定期删除的结合
- 每个key都执行惰性删除
- 服务器周期性执行删除(每次有最大时间限制,随机抽取)
回收策略
- 当redis内存占用太多了,超过限制了就会触发回收
策略
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(默认),不会准确的删除所有键中最近最少使用的键,而是随机抽取3个键,删除这三个键中最近最少使用的键,抽取值可以设置,使用LFU策略
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
备份
- 实际上redis的备份应该是RDB备份,备份期间产生的请求直接使用AOF追加在文件结尾
RDB备份
- 一种压缩的二进制文件,储存当前redis所有key和val等信息,实现细节较为复杂,略
- 可以使用同步或者异步备份,默认不开启
- SAVE同步执行,BESAVE异步fork执行,因为是fork,读享写复,redis在此期间操作不影响RDB文件
- 优点: 体积小,效率高 缺点:key写入后如果改变无法写入(除非重写)
- 缺点: 最后一次备份可能数据丢失,在两次备份间隔中如果出现宕机,那么中间的数据就会丢失(核心问题是RDB写了之后不能修改导致写的时候发生的请求仅仅用RDB无法记录)
AOF备份
- 一种保存压缩命令的文件,类似状态机,通过重写复原数据库状态
- 默认开始,可以通过重写减少体积
- 优点: 可以实时更新 缺点:文件体积太大
命令编码
- SET key value
*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$5\r\nvalue\r\n,SDS串
命令请求过程
- 客户端编码命令并发送
- 服务端解析命令
- 预备操作(大部分是一些检查)
- 调用命令所在的函数指针(调用处理函数)
- 执行后续操作并发送结果
多机数据库实现
一致性hash算法(一致性哈希)
- 一致性hash都不是缓存机器自身的功能,而是集群前置的代理或客户端实现的。而redis官方的集群是集群本身通过slots实现了数据分片。
实现原理
请求
- 先对机器进行hash后对2^ 32-1取模(这个hash函数可以选择其他的),放到圆环上面
- 数据请求打入时候,顺时针找到下一个node的位置
- 如果出现数据倾斜的时候可以使用虚拟节点
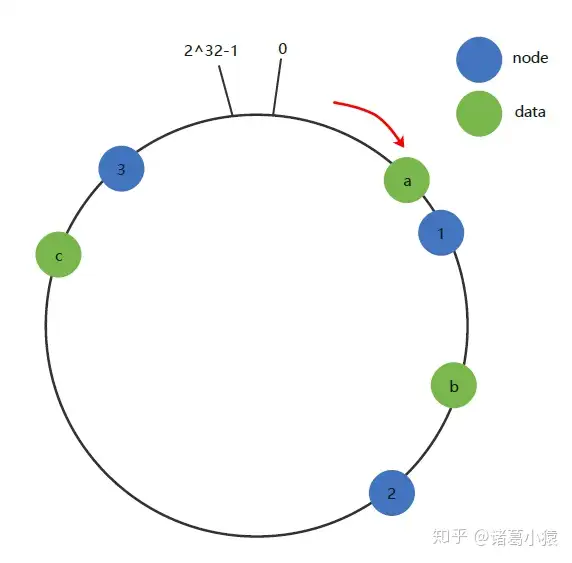
虚拟节点
- 为了使得机器分布均匀使得负载均衡,添加些虚拟节点,节点的ip指向已经存在的机器而非新机器
优点
- 扩容和宕机处理方便,只需要改变一小部分,扩展性强
缺点
- 一致性哈希的某个节点宕机或者掉线后,当该机器上原本缓存的数据被请求时,会从数据源重新获取数据,并将数据添加到失效机器后面的机器,这个过程被称为 "缓存抖动" ,而使用哈希槽的节点宕机,会导致一定范围内的槽不可用,只能通过主从复制加哨兵模式保证高可用。
- 当某台机器宕机时,极易引起雪崩,如上述介绍中删除节点。
- 删除节点就会把当前节点所有数据加到它的下一个节点上。这样会导致下一个节点使用率暴增,可能会导致挂掉,如果下一个节点挂掉,下下个节点将会承受更大的压力,最终导致集群雪崩。
- 哈希槽,一致性哈希算法更复杂
redis运行模式
单机模式
→ 上文
- 优点:简单 缺点:有性能瓶颈
主从复制
- 将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点。
- 读取可以从slave读,但是写入转发到master写
- 优点: 读压力分担给从服务器 缺点:写瓶颈和储存瓶颈都在master服务器上面,宕机之后需要人工干预
哨兵模式
- 哨兵是一种特殊的redis服务器,也有自己的master,通过raft算法选举
- 负责副redis服务器监控,类似心跳包,检查master存活状态,
- 发现master宕机之后马上选举新的master,并且通知slave,实现自动故障恢复
- 优点:宕机自动恢复可靠性高 缺点:在线扩容复杂,还是有主从的缺点
集群模式
- 把key经过hash之后放到16384个slots(一个二进制数组char bits[2048],2048*8=16384)
- 把slots指派给不同的redis master处理,当key到来时候,先计算hash,在发送MOVE重定向到正确的服务器(类似于负载均衡)
- 通过发送自己的二进制bits,告诉别人自己负责的部分
- 优点:动态扩容简单,重新分片即可

MOVE和ASK
- MOVE是槽的时候机器计算key不止自己负责的,就会永久重定向到负责的机器
- ASK则是,临时重定向,代表临时错误,一半不做处理(比如整个集群正在迁移)
崩溃恢复
总结
- 目前通常使用集群模式管理key,然后每个分片通常配置主从模式和哨兵模式,保证高可用性和可靠性
- 首先使用slot的机制(这个也可以换成一致性hash)分配到某些集群,每个集群中使用主从机制工作,同时配备哨兵模式容灾
同步
旧版
- 缺点:断线重链复制东西太多了
新版
- 使用psync命令开始
- 给oper标号,master和slave分别保存目前oper标号
- master保存一段操作的oper到内存(大约1M内存)
- 断线之后slave发送自己目前的oper标号
- master对比,如果内存还保存有,就直接发送内存里对应的内容,否则和旧版一样全发送

独立功能
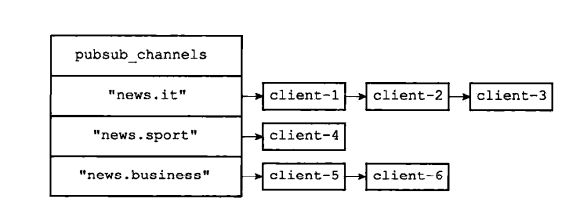
订阅频道
- 订阅使用字典存储key,val使用链表结构,订阅者会插入链表头
- key更改会先去找有没有订阅者
事务
- watch监控变量是否改变,multi开始事务,exec开始执行事务
- 执行前检查watch变量是否改变,改变则不执行事务,执行中途失败不会回滚

- 使用 set 等操作修改key 时候会遍历这个key 对应的watch, 将对应的 REDIS_DIRTY_CAS 打开, 此时提交事务检查这个标识就会发现从而触发

others
慢日志查询
- 记录查询事件超过某个特定事件的操作
监控器
- 客户端可以变为监视器,开始监视服务端的所有操作
参考
- redis设计与实现,https://1e-gallery.redisbook.com/
- https://www.cnblogs.com/zhonglongbo/p/13128955.html
- https://zhuanlan.zhihu.com/p/179266232 推荐书籍
- redis设计与实现