nsq

[!tip] 参考 https://zhuanlan.zhihu.com/p/115368450 https://nsq.io/components/utilities.html#nsq_to_file
特点
- 使用push的方式推送消息
- 支持集群部署
- topic->channel->protocol(连接),消息层层传递,各个层次通过chan for-select模型连接
和kafka对比
[!tip] 参考 https://zhuanlan.zhihu.com/p/46421050
kafka架构
- 参考组成
注册发现
- kafka使用zookeeper,一种类似raft的强一致性算法保证
- nsq使用nsqlookup,只提供简单注册发现服务(类似http转发的功能,不参与消息传输)
推送
- kafka pull,消费者拉取,阻塞式pull
- 优点:流控简单,消费者要多少拿多少
- 缺点:pull频率把控重要(太慢丢失实时性,太快浪费资源)
- nsq push,有msg马上主动下发
- 优点:及时性很好
- 缺点:流控麻烦,需要额外配置(告知可以处理多少)
存储
- kafka 直接扔到硬盘里,不过因为是循序写,非常快,而且还有操作系统 > 零拷贝文件传输的机制使得更加快
- nsq 除非超过
--mem-queue-size,否则都扔在内存,因此当消息在被写入磁盘之前,NSQ宕机或关闭了进程,会出现丟数据的情况
保证
- Kafka,支持最多一次(At most once)、至少一次(At lease once)、准确一次(Excatly once)三种策略
- nsq,则只支持最常见的一种,也就是至少一次。
备份
- Kafka则通过partition的机制,对消息做了备份,增强了消息的安全性。
- Nsq只把消息存储到一台机器中,不做任何备份,一旦机器奔溃,磁盘损坏,消息就永久丢失了。
顺序
- kafka支持消息顺序消费(消费完A再消费B)
- kafka支持顺序消费的原因是可以指定放入的part,二每个part是一个队列消费的顺序是一定的,可以保证顺序消费
- 返回成功是在写入磁盘中后,因此可以保证顺序消费
- part必须上一条成功之后才会发下一条
- kafka中push时候可以指定key,key相同的会被分配到同一个part,使得同一个key的消息可以按顺序消费,同一个part是有序的
- nsq不支持
- 因为nsq设计的和kafka不一样,nsq每个topic只有一个chan,因此压根没有支持上一条不接受下一条不发的机制(这样会严重影响消息发送的效率)
- 而且nsq中大量使用协程,消息之间的处理也不能完全保证顺序
事务
- kafka支持事务,可以原子性写入多个topic
- nsq不支持
延时器
- nsq使用纯粹的时间堆实现
- kafka主要是时间堆,但是细节上用时间轮来优化
总结
- nsq和专业的消息队列还是有差别的,但是小规模可以用,毕竟轻的多
消息队列作用
- 降低耦合度,通过两个不同模块处理
- 请求之间的缓冲削峰,避免突发流量
- 处理异步化,提高响应速度和体验
消息队列名词
消费者
- 消息消费的一个实例
消费者组
- 每个消费组有一个或者多个消费者
- 每个消费组拥有一个唯一性的标识id
- 消费组在消费topic的时候,topic的每个partition只能分配给一个消费者
nsq的channel类似消费组,protocol类似消费者
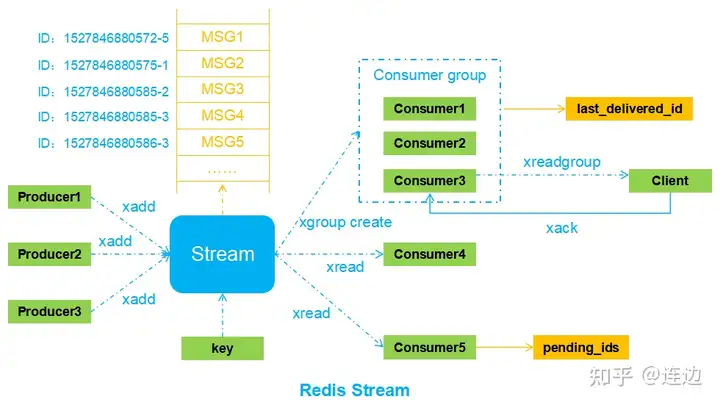
redis stream
3. Stream流模型
[!tip] 参考 https://www.jianshu.com/p/d32b16f12f09 https://zhuanlan.zhihu.com/p/496944314 https://cloud.tencent.com/developer/article/2331486 https://juejin.cn/post/7094646063784525832 https://www.cnblogs.com/coloz/p/13812840.html

使用命令
结构体
stream
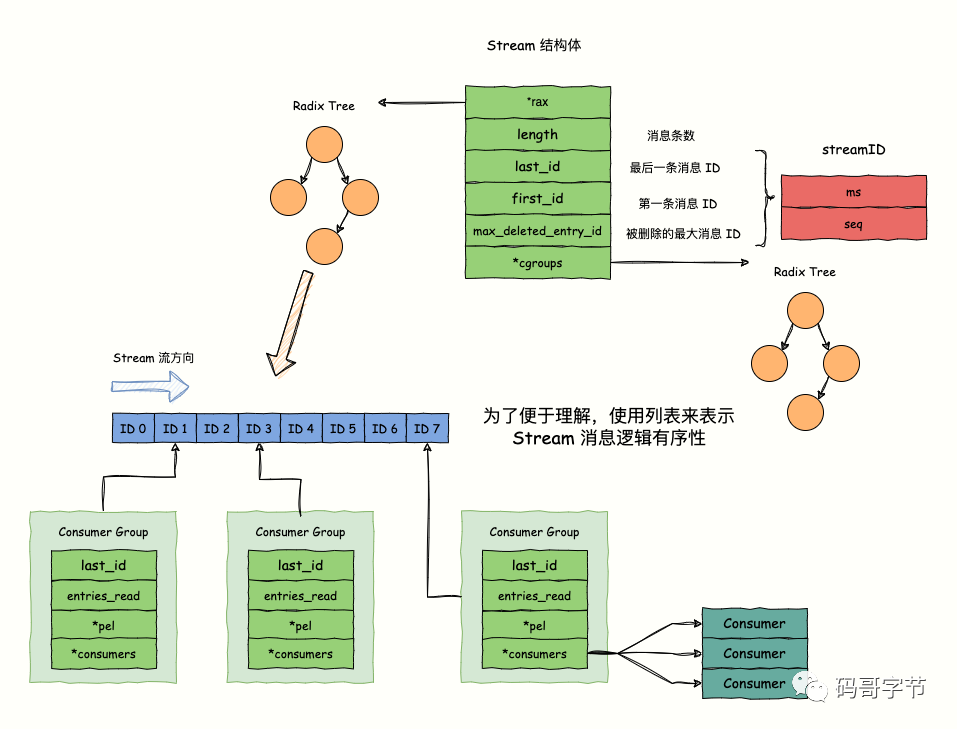
typedef struct stream {
rax *rax; // 是一个 `rax` 的指针,指向一个 Radix Tree,key 存储消息 ID,value 实际上指向一个 listpack 数据结构,存储了多条消息,每条消息的 ID 都大于等于 这个 key 的消息 ID
uint64_t length; // 该 Stream 的消息条数
streamID last_id; // 当前 Stream 最后一条消息的 ID。
streamID first_id; // 当前 Stream 第一条消息的 ID。
streamID max_deleted_entry_id; // 当前 Stream 被删除的最大的消息 ID。
uint64_t entries_added;// 总共有多少条消息添加到 Stream 中,`entries_added = 已删除消息条数 + 未删除消息条数`
rax *cgroups;// rax 指针,也指向一个 Radix Tree ,**记录当前 Stream 的所有 Consume Group**,每个 Consume Group 的名称都是唯一标识,作为 Radix Tree 的 key,Consumer Group 实例作为 value
} stream;
// 结构体,消息 ID 抽象,一共占 128 位,内部维护了毫秒时间戳(字段 ms);一个毫秒内的自增序号(字段 seq),**用于区分同一毫秒内插入多条消息**。
typedef struct streamID {
uint64_t ms;
uint64_t seq;
} streamID;
- stream中使用树和堆 > radix tree实现消息列表而不是list
[!info] 原因
- redis的消息支持根据id删除,因此需要有索引的出现,因此不能单纯用list
- redis的消息支持顺序消费,而且key大量重复,因此不能直接用hash
- 节省空间,而且因为redis默认使用时间戳+顺序编号作为id,公共前缀比较长,可以节省空间
- value的类型是redis实现 > 压缩列表,直接存储的就是消息的id和内容
- listpack的所有key都是增加的,比叶子节点的node大
- 消息的id是(毫秒时间戳-序号)
consumer group
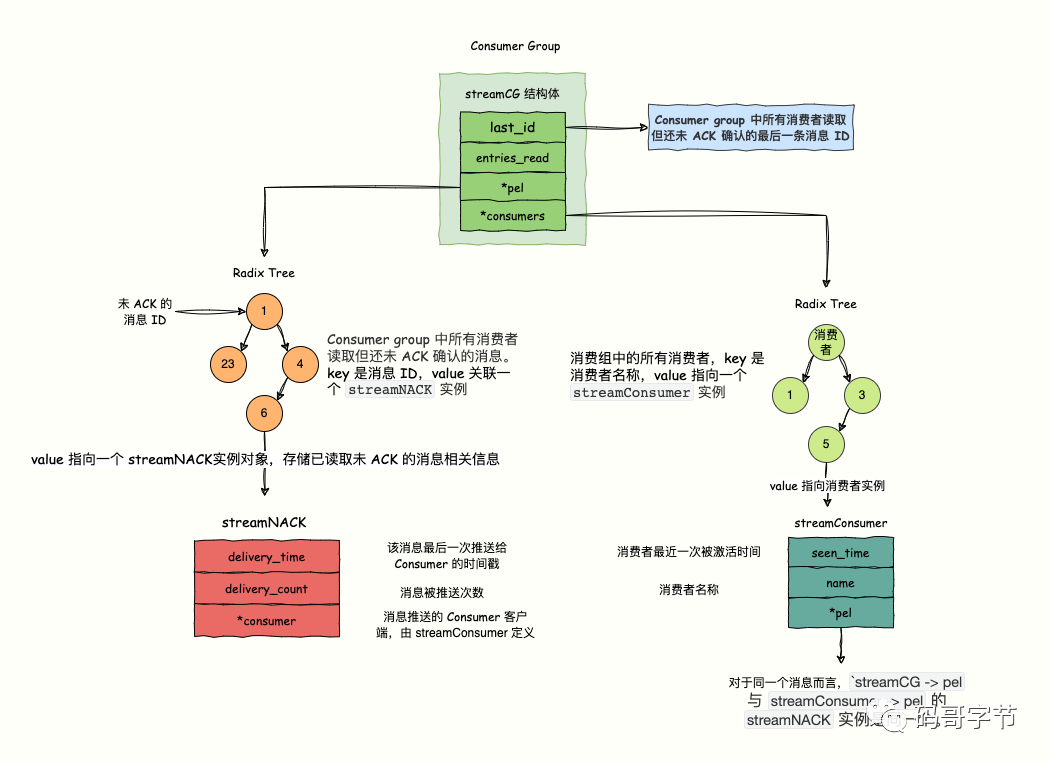
/* Consumer group. */
typedef struct streamCG {
streamID last_id;// **已经获取了,无论是否ack的id**
long long entries_read;
rax *pel;
rax *consumers;// key是消费者name,val是消费者实体
} streamCG;
/* Pending (yet not acknowledged) message in a consumer group. */
typedef struct streamNACK {
mstime_t delivery_time;
uint64_t delivery_count;
streamConsumer *consumer;
} streamNACK;
typedef struct streamConsumer {
mstime_t seen_time;
sds name;
rax *pel;
} streamConsumer;
- 没有ack的消息可能在consumer中的pel和group的pel都记录一次,但是这两个指向的都是同一个streamNACK结构体,因此是共享的
- pel是整个维护必达性的核心结构体,所有没有被ack的数据都会放到这里,保证至少被消费一次
- 消费者和消费者组参考消息队列
Iterator
typedef struct raxStack {读取之后无论是否ack,last_id都会更新
void **stack; /*用于记录路径,该指针可能指向static_items(路径较短时)或者堆空间内存; */
size_t items, maxitems; /* 代表stack指向的空间的已用空间以及最大空间 */
void *static_items[RAX_STACK_STATIC_ITEMS];
int oom; /* 代表当前栈是否出现过内存溢出. */
} raxStack;
typedef struct raxIterator {
int flags; //当前迭代器标志位,目前有3种,RAX_ITER_JUST_SEEKED代表当前迭代器指向的元素是刚刚搜索过的,当需要从迭代器中获取元素时,直接返回当前元素并清空该标志位即可;RAX_ITER_EOF代表当前迭代器已经遍历到rax树的最后一个节点;AX_ITER_SAFE代表当前迭代器为安全迭代器,可以进行写操作。
rax *rt; /* 当前迭代器对应的rax */
unsigned char *key; /*存储了当前迭代器遍历到的key,该指针指向
key_static_string或者从堆中申请的内存。*/
void *data; /* 当前key关联的value值 */
size_t key_len; /* key指向的空间的已用空间 */
size_t key_max; /*key最大空间 */
unsigned char key_static_string[RAX_ITER_STATIC_LEN]; //默认存储空间,当key比较大时,会使用堆空间内存。
raxNode *node; /* 当前key所在的raxNode */
raxStack stack; /* 记录了从根节点到当前节点的路径,用于raxNode的向上遍历。*/
raxNodeCallback node_cb; /* 为节点的回调函数,通常为空*/
} raxIterator;
- 使用还是通过栈+中序遍历节点的方式寻找下一个
整体流程
写入
- 先创建一个stream,创建raxio tree
- 根据last_id,生成要插入的新的ID,找到最大的tree的节点(最右边的节点)
- 判断listpack是否还能插入,能插入能插入
- 不能就根据key创建一个新的listpack
读取
- 所有的读取行为以group的last_id进行读取
- 读取之后无论是否ack,last_id都会更新
- 没有ack的消息都会被扔到pel中和消费者的pel中,被分配给消费者的消息不会再给其他消费者,也只能特定的消费者来ack
[!info] 重发时机
- 检测到消费者有断线的情况
- 消息过期,这部分xadd指定时间
kafka
组成
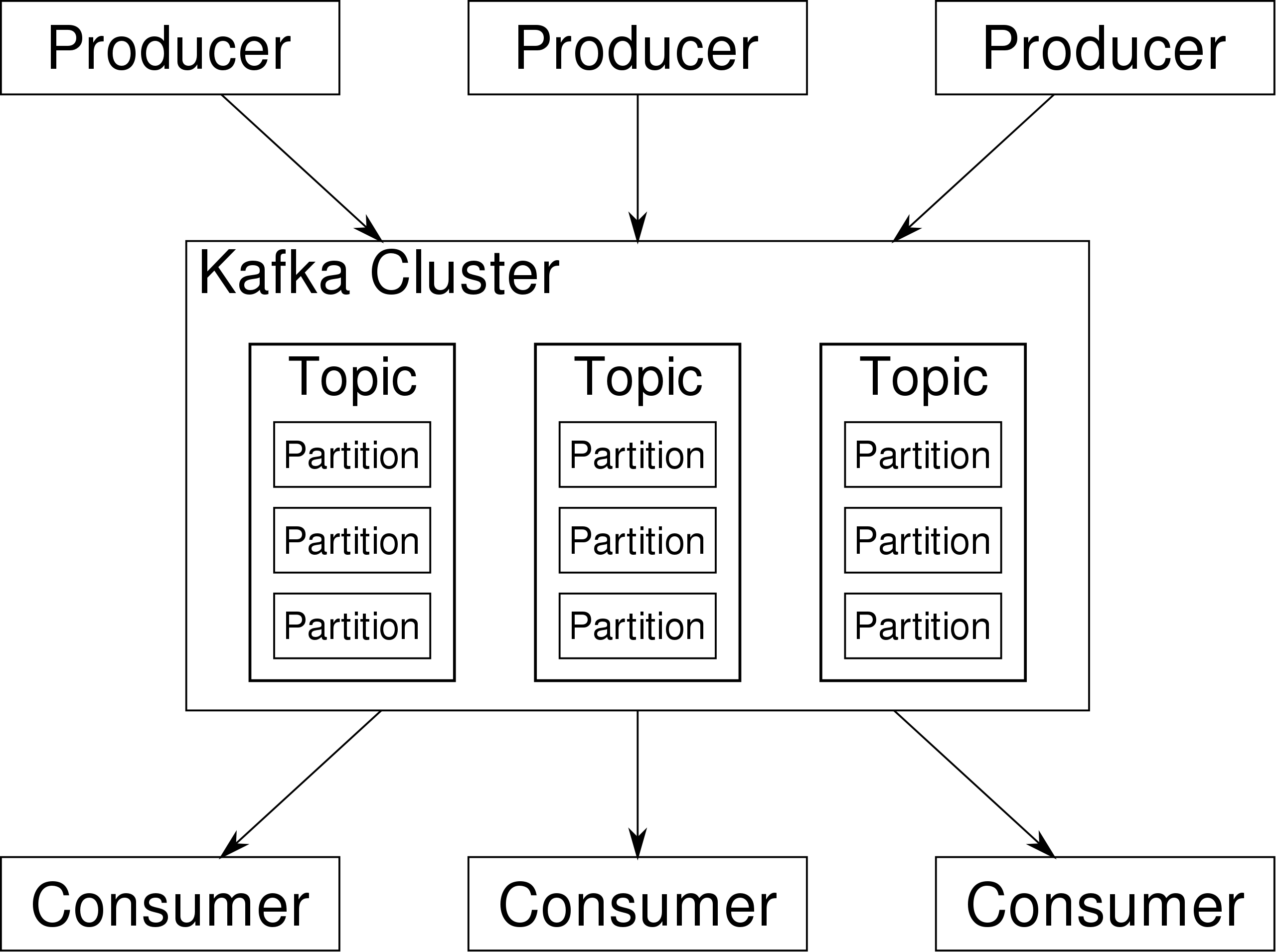
- Broker:一台kafka服务器就是一个broker。一个cluster由多个broker组成。
- 每个topic有多个part,每个part都是一个队列,这个队列的实现是通过文件的写入和偏移量完成的
- 如果消息没有指定part,那么将会负载均衡消息到part
- 储存的结构都是在磁盘中而不是在内存中
- Consumer作为一个消费者组,每个消息只会被一个消费者组消费一次
- Kafka 不会向 Consumer 推送消息。Consumer 必须自己从 Topic 的 Partition 拉取消息。
- 为保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个分区都有若干个副本,一个leader和若干个follower.读写都是向leader中,follower只是作为一个容灾备份,而且==是以partition为单位创建副本,而不是broker==
broker
- 在 Kafka 集群中会有一个或多个 broker,其中有一个 broker 会被选举为控制器(Kafka Controller),它负责管理整个集群中所 有分区和副本的状态。当某个分区的leader副本出现故障时,由控制 器负责为该分区选举新的leader副本。当检测到某个分区的ISR集合发 生变化时,由控制器负责通知所有broker更新其元数据信息。当使用 kafka-topics.sh脚本为某个topic增加分区数量时,同样还是由控制 器负责分区的重新分配(相当于broker中的leader)
分区
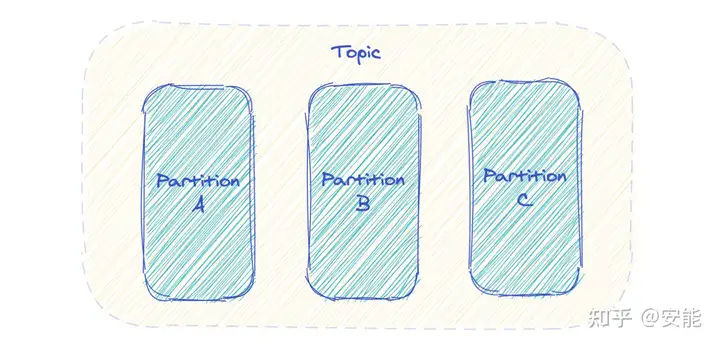
- Kafka 中 Topic 被分成多个 Partition 分区。
- Topic 是一个逻辑概念,Partition 是最小的存储单元,掌握着一个 Topic 的部分数据。topic列表存储在zookeeper中,数据存储在kafka中
- 每个 Partition 都是一个单独的 log 文件,每条记录都以追加的形式写入。
- 默认情况下,每个topic默认一个partition
- 对于一个topic以及订阅他的一个消费组
- 如果partition大于等于消费者数量:每个消费者处理>=1个partition
- 如果partition小于消费者数量:==每个消费者处理1个partition,剩下的消费者闲置,不会出现同一个消费组多个消费者同时处理一个partition==,这样可以保证同一个partition的消息的顺序消费
- kafka尽量保证分区符副本分布的均衡性,即平均每个partition在每个broker上都有一个副本(当然这一堆副本中有一个leader)
分配
这部分是分区到消费者的分配策略
- 参考分配策略
[!tip] 参考 微信公众平台
优势
- 如果把 Topic 的所有 Partition 都放在一个 Broker 上,那么这个 Topic 的可扩展性就大大降低了,会受限于这个 Broker 的 IO 能力。把 Partition 分散开之后,Topic 就可以水平扩展 。
- 一个 Topic 可以被多个 Consumer 并行消费。如果 Topic 的所有 Partition 都在一个 Broker,那么支持的 Consumer 数量就有限,而分散之后,可以支持更多的 Consumer。
- 一个 Consumer 可以有多个实例,Partition 分布在多个 Broker 的话,Consumer 的多个实例就可以连接不同的 Broker,大大提升了消息处理能力。可以让一个 Consumer 实例负责一个 Partition,这样消息处理既清晰又高效。
offset
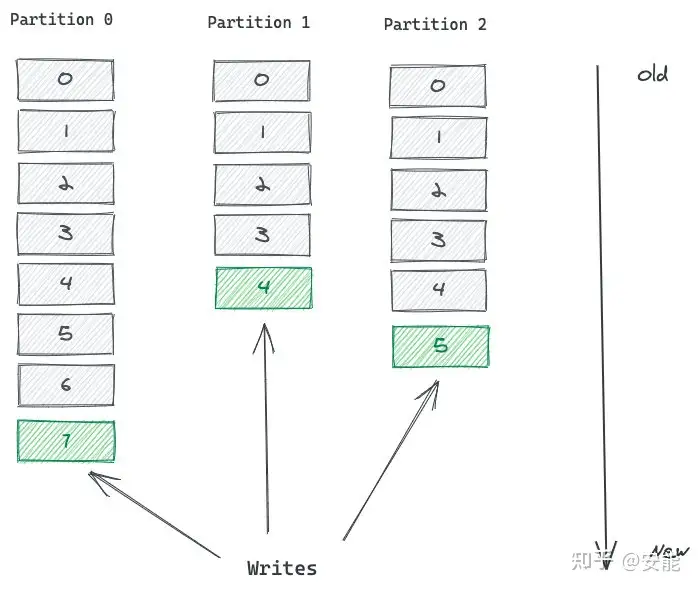
- Partition 中的每条记录都会被分配一个唯一的序号,称为 Offset(偏移量)。
- Offset 是一个递增的、不可变的数字,由 Kafka 自动维护。
- 当一条记录写入 Partition 的时候,它就被追加到 log 文件的末尾,并被分配一个序号,作为 Offset。
- 这个 Topic 有 3 个 Partition 分区,向 Topic 发送消息的时候,实际上是被写入某一个 Partition,并赋予 Offset。
- 消息的顺序性需要注意,一个 Topic 如果有多个 Partition 的话,那么从 Topic 这个层面来看,消息是无序的。
- offset是最后一条已读的消息位置,而不是最前一条未读的消息位置
- 但单独看 Partition 的话,Partition 内部消息是有序的。所以,一个 Partition 内部消息有序,一个 Topic 跨 Partition 是无序的。如果强制要求 Topic 整体有序,就只能让 Topic 只有一个 Partition
- ==每个<partition,group,topic> 这个三元组唯一确定了一个offset,任何一个部分不一样offset都不同==
[!tip] 参考 细说 Kafka Partition 分区 - 知乎 (zhihu.com)
消息
构成


- 时间增量是相对于消息批次的其实时间戳的
- 属性是一些位表示消息的属性(如时间戳的类型,是否压缩等)
- 上面的key是发送者设置的,没有则无
- Kafka 可变长度的具体做法借鉴了 Google ProtoBuffer 中的 Zig-zag 编码方式 #TODO 可以看一下
消息批次

- 这个是位于批量消息最前面的,最后的消息就是多条消息,用于批量发消息节省空间提高空间使用率
- CRC:对于批次内的数据计算校验值
- 增加了 PID、producer epoch、序列号等信息主要是为了支持幂等性以及事物引入的
- 这里的属性占用了两个字节。低3位表 示压缩格式,可以参考v0和v1;第4位表示时间戳类型;第5位表示此 RecordBatch是否处于事务中,0表示非事务,1表示事务。第6位表示 是否是控制消息(ControlBatch),0表示非控制消息,而1表示是控 制消息,控制消息用来支持事务功能
controller
- 每个Broker都会在Controller Path (/controller)上注册一个Watch。 当前Controller失败时,对应的Controller Path会自动消失(因为它是ephemeralNode),此时该Watch被fire,所有“活” 着的Broker都会去竞选成为新的Controller (创建新的Controller Path),但是只会有一个竞选成功(这点由Zookeeper保证)。竞选成功者即为新的Leader,竞选失败者则重新在新的Controller Path上注册Watch。因为Zookeeper的Watch是一次性的, 被fire一次之后即失效,所以需要重新注册.
- 这里因为broker的数量不会多到太离谱,羊群效应的影响没这么大
安装
# 如果版本3.x更改端口 务必再config/server.properties中添加,否则不成功
listeners=PLAINTEXT://127.0.0.1:9092
存储
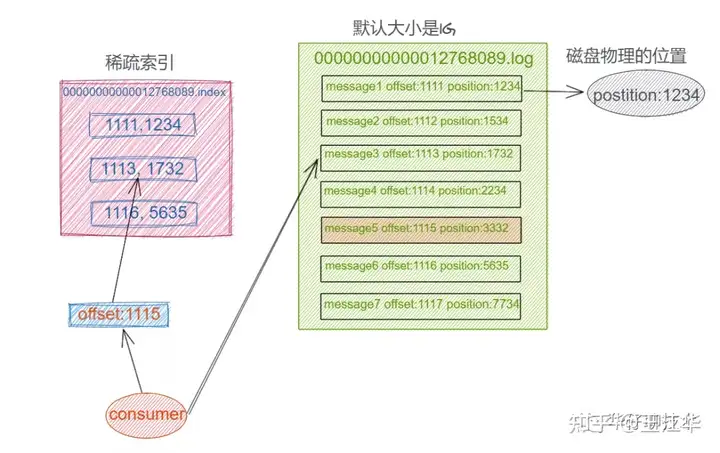
- index文件是稀疏索引,而且文件名是
- Log 日志在物理上只是以文件夹的形式存储,而每个 LogSegement 对应磁盘上的一个日志文件和两个索引文件,以及可能的其他文件
- 每个 Segment 对应4个文件:“.index” 索引文件, “.log” 数据文件, “.snapshot” 快照文件, “.timeindex” 时间索引文件。这些文件都位于同一文件夹下面,该文件夹的命名规则为:topic 名称-分区号.index, log, snapshot, timeindex 文件以当前 Segment 的第一条消息的 Offset 命名。其中 “.index” 文件存储大量的索引信息,“.log” 文件存储大量的数据,索引文件中的元数据指向对应数据文件中 Message 的物理偏移量。
- Kafka 是基于「主题 + 分区 + 副本 + 分段 + 索引」的结构
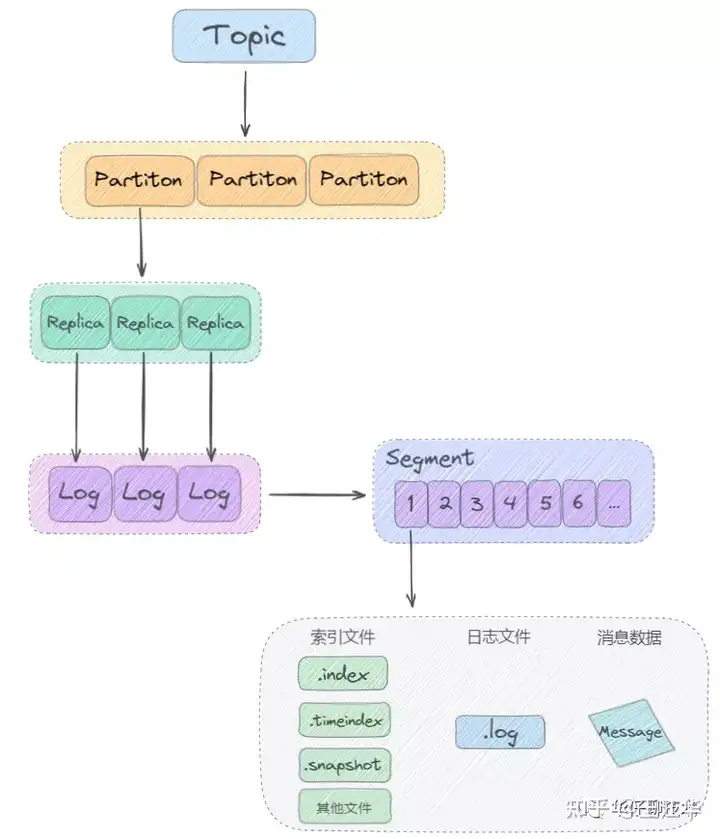
日志写入
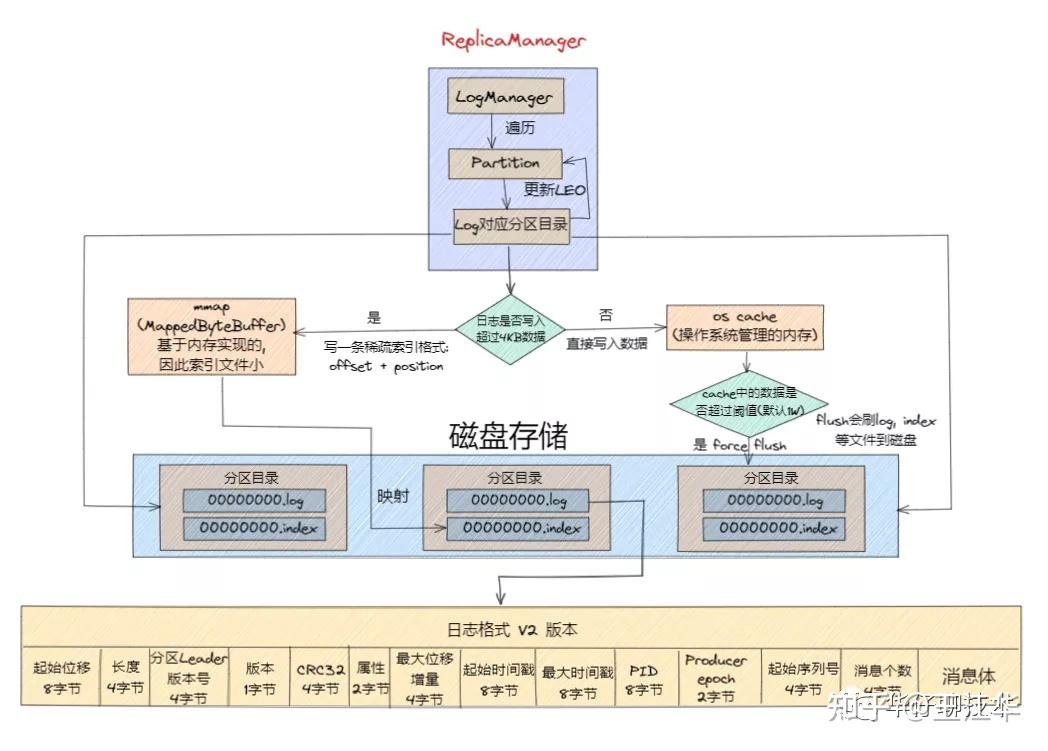
[!tip] 参考 搞透Kafka的存储架构,看这篇就够了 - 知乎
日志清理
- 共有3种策略删除,将日志分段文件添加上“.deleted”的后缀(也包括日志分段对应的索引文件)
- Kafka的后台定时任务会定期删除这些“.deleted”为后缀的文件,这个任务的延迟执行时间可以通过file.delete.delay.ms参数来设置,默认值为60000,即1分钟。
- 基于时间的保留策略
- 基于日志大小的保留策略
- 基于日志起始偏移量的保留策略
- 每个segment日志都有它的起始偏移量,如果起始偏移量小于 logStartOffset,那么这些日志文件将会标记为删除。
日志压缩
- #TODO 这里确定一下如何实现日志压缩的
LSR机制
- LEO( Log End Offset):指的是每个副本最大的offset;
- HW(High Watermark):字面意思高水位,指的是消费者能见到的最大的offset,ISR队列中最小的LEO。
- ISR (In-Sync Replica): 所有与Leader副本保持一定程度同步的副本(包括Leader副本在内)组成ISR,ISR中的副本是可靠的,它们跟随Leader副本的进度。
- OSR (Out-of-Sync Replica): 与Leader副本同步滞后过多的副本组成了OSR,这些副本可能由于网络故障或其他原因而无法与Leader保持同步。
- AR (Assigned Replica): 分区中的所有副本统称为AR,AR=ISR+OSR。
- 消息可以被消费是在HW的位置,而不是ack的位置,有的LSR太久跟不上会被踢到OSR,HW的位置是LSR集合决定的,知道副本追上了才能被加到LSR中
LSR选举
ISR 的全称叫做:In-Sync Replicas (同步副本集), 我们可以理解为和 leader 保持同步的所有副本的集合。所有Partition的Leader选举都由controller决定。
- 只有LSR有资格参加选举,OSR没有(这部分可以配置)
- 一旦leader宕机,会通过controller从Zookeeper中读取当前分区的所有ISR(in-sync replicas)集合,选择PreferredReplica作为当前Partition的leader(就是按照序号选)
[!tip] 为什么不使用类似分布式raft选举或者zookeeper raft适用于保证极高的一致性的前提下选举,可能出现耗时较高的情况,而且因为分为了ISR和OSR两个部分,副本的同步问题得到了解决(相当于LSR任何一个都可以),因此可以直接指定.而且更加简单,raft过于复杂 zookeeper的watch机制可能出现羊群效应(每个副本都在watch和抢夺的情况下,如果宕机的那个Broker上的Partition比较多, 会造成多个Watch被触发,造成集群内大量的调整,导致大量网络阻塞。),以及导致zookeeper负载过重(要维护大量副本的watch)
生产者
- send会放入发送生产者缓冲区(这部分非kafka服务器)中,但是不一定发送,如果不flush,按照一定周期也会发,flush是立刻清空缓冲区马上发送,flush函数会等待ack到达或者超时,如果超时抛出异常,但是不会进行重试,重试需要业务端自己执行
- #TODO 参考"深入探索kafka"书补充完
ACK
- 1(默认):leader收到数据就成功,可能丢数据,但可能重复数据
- 0:无需等待来自broker的确认而继续发送下一批消息。这种情况下数据传输效率最高,但是数据可靠性最低
- -1或all:producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高
定时/延时消息
原理
-
参考# Kafka中的方法
- 两者结合使用.Kafka 中的时间轮(TimingWheel)是一个存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表(TimerTaskList)。TimerTaskList是一个环形的双向链表,链表中的每一项表示的都是定时任务项(TimerTaskEntry),其中封装了真正的定时任务(TimerTask)。

- DelayQueue 中保存着所有的 ==TimerTaskList== (注意这里并不保存task只是相当于把那个时间点有task的信息时间点记录下,这样减少了堆元素的数量)对象,根据时间来排序,这样延时越小的任务排在越前面。
- 外部通过一个线程(叫做ExpiredOperationReaper)从 DelayQueue 中获取超时的任务列表 TimerTaskList,然后根据 TimerTaskList 的 过期时间来精确推进时间轮的时间,这样就不会存在空推进的问题啦。
- DelayQueue 只存放了 TimerTaskList,并不是所有的 TimerTask,数量并不多,相比空推进带来的影响是利大于弊的,DelayQueue才是真正对任务进行延时排序的地方,时间轮的用途是分级聚合任务,减少DelayQueue中的对象数。
- 两者结合使用.Kafka 中的时间轮(TimingWheel)是一个存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表(TimerTaskList)。TimerTaskList是一个环形的双向链表,链表中的每一项表示的都是定时任务项(TimerTaskEntry),其中封装了真正的定时任务(TimerTask)。
场景
- 事务场景下,为了保证可读性的控制,使用延迟发送的方式
消费者
AutoCommit
- true表示消费者只要接收到这个消息自动提交偏移
- false表示消费者需要手动提交偏移
__consumer_offsets
- 存储offset的特殊topic,key是上文的三元组<Group ID,主题名,分区号 >**,val是offset
- kafka会定时清理过期的信息
- kafka 默认为该 topic 创建了50个分区,并且对每个 group.id 做哈希求模运算,从而将负载分散到不同的 __consumer_offsets 分区上
[!tip] 为什么不存储在zookeeper或者hash hash不适合落盘保存,这个操作是写远远大于读的操作,因此写性能必须非常好,读时候找到最新的提交,然后后期进行日志压缩(相同key保存最新)
Rebalance机制
正常情况下,kafka会为每个topic分配几个partition,然后每个消费者组的成员负责不同的partition的消费,但是出现某些情况会导致重新分配.==在这里可能出现消息的重复问题==
触发时机
- 组成员发生变更,比如新consumer加入组,或已有consumer主动离开组,再或是已有consumer崩溃时则触发rebalance(==这里处理超时也会被认为是崩溃==)。
- 组订阅topic数发生变更,比如使用基于正则表达式的订阅,当匹配正则表达式的新topic被创建时则会触发rebalance。
- 组订阅topic的分区数发生变更,比如使用命令脚本增加了订阅topic的分区数。
分配策略
- range策略主要是基于范围的思想:它将单个topic的所有分区按照顺序排列,然后把这些分区划分成固定大小的分区段并依次分配给每个consumer
- round-robin策略则会把所有topic的所有分区顺序摆开,然后轮询式地分配给各个consumer
- sticky策略有效地避免了上述两种策略完全无视历史分配方案的缺陷,采用了“有黏性”的策略对所有consumer实例进行分配,可以规避极端情况下的数据倾斜并且在两次rebalance间最大限度地维持了之前的分配方案
拉取消息
- 通过主动pull而不是push机制拉取数据
- Push 模式最大缺点就是 Broker 不清楚 Consumer 的消费速度,且推送速率是 Broker 进行控制的, 这样很容易造成消息堆积,如果 Consumer 中执行的任务操作是比较耗时的,那么 Consumer 就会处理的很慢, 严重情况可能会导致系统 Crash。
- 如果 Kafka Broker 没有消息,这时每次 Consumer 拉取的都是空数据, 可能会一直循环返回空数据。 针对这个问题,Consumer 在每次调用 Poll() 消费数据的时候,顺带一个 timeout 参数,当返回空数据的时候,会在 Long Polling 中进行阻塞,等待 timeout 再去消费,直到数据到达。
状态机
消费控制

下文的commit是提交偏移(也就是消费者确认ack),消费是具体拿到消息的处理 Broker:一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个 topic。
at most once模式
- 基本思想是保证每一条消息commit成功之后,再进行消费处理;
- 设置自动提交为false,接收到消息之后,首先commit,然后再进行消费
- 特点:不会重复发送,可能消息丢失 ,acks = 0 可以实现。acks=0 保证producer往leader只发送一次,不管是否发送成功,因此可能丢数据,但不会重复发送
at least once模式
- 基本思想是保证每一条消息处理成功之后,再进行commit;
- 设置自动提交为false;消息处理成功之后,手动进行commit;
- 特点:会重复发送,消息不会丢失,ack = all 或-1可以实现。
exactly once模式
实际上并没有办法实现完全的exactly once,核心难点在于消费者端回commit和消费message,这两个不是原子操作,下面方法是保证生产者端不会重复发送
生产者幂等性
对于单个分区,幂等生产者不会因为生产者或 broker 故障而产生多条重复消息。
- 核心思想是发送端数据发送成功,并且成功的消息只发送一次(重复的数据被服务器拒绝掉);消费端再进行at most once模式消费。
- 特点:不会重复发送,消息不会丢失,at least once 加上消费者幂等性可以实现,还可以用kafka生产者的幂等性来实现
- 生产者端开启这个模式后会给每个消息编号,同一条消息发送两次不会二次写入。kafka每次发送消息会生成PID和Sequence Number,并将这两个属性一起发送给broker,broker会将PID和Sequence Number跟消息绑定一起存起来,下次如果生产者重发相同消息,broker会检查PID和Sequence Number,如果相同不会再接收
过程
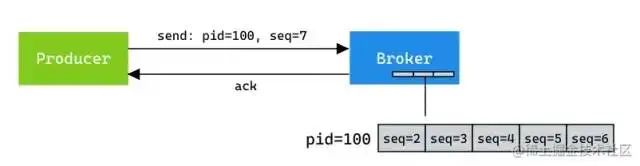
Producer每次启动后,会向Broker申请一个全局唯一的pid。- 重启后pid会变化,此时 <pid, seq num>中的pid不相同,因此kafka会认为是新的消费者,seq从0开始
- Broker端也会为每个
<PID, Topic, Partition>维护一个序号
Sequence Number:针对每个<Topic, Partition>都对应一个从0开始单调递增的Sequence(这意味着pid,partition,sequence三个部分可以唯一确定一条消息),同时Broker端会缓存这个seq num(==这里并不意味着所有的消息都需要放在同一个partition中 ==)- 判断是否重复: 拿 <pid, seq num> 去 Broker 里对应的队列 ProducerStateEntry.Queue(默认队列长度为 5)查询是否存在
- 如果 nextSeq == lastSeq + 1,即 服务端seq + 1 == 生产传入seq,则接收。
- 如果 nextSeq == 0 && lastSeq == Int.MaxValue,即刚初始化,也接收。
- 反之,要么重复,要么丢消息,均拒绝。
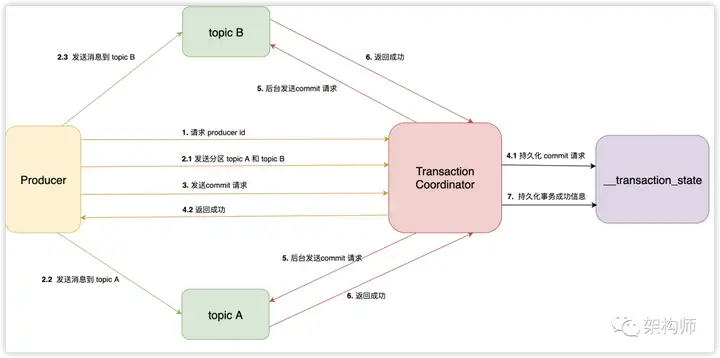
事务:跨分区原子写入
- 保证的是多个写操作的原子性,要么一起成功,要么一起不成功,通常用于写多个分区的消息时候(比如: 写下单topic-> 处理支付业务-> 写支付topic)或者需要 写 和commit相结合(保证写和commit原子性)
过程
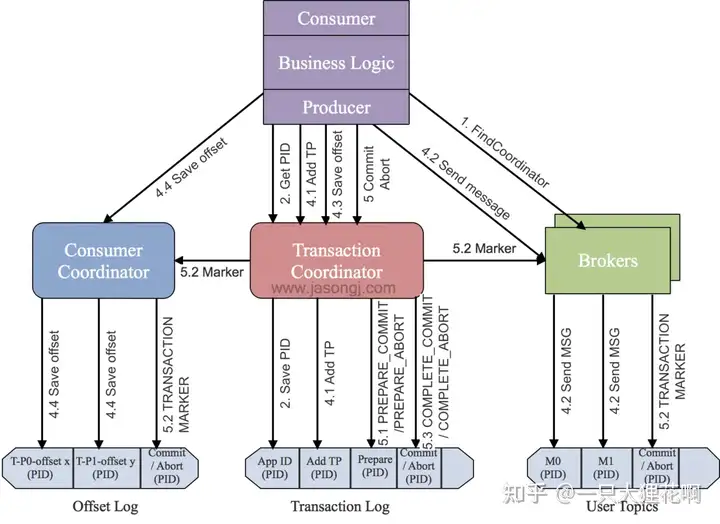
- 查找 Transaction Coordinator:
Producer 通过向任意一个 Broker 发送 FindCoordinatorRequest 请求,获取 Transaction Coordinator 的地址,Transaction Coordinator 负责协调和管理事务的生命周期 - 初始化事务(initTransaction):
Producer 发送 InitPidRequest 给 Transaction Coordinator,获取 PID(Producer ID)。 Transaction Coordinator 记录 PID 和 Transaction ID 的映射关系,并执行一些额外的初始化工作,包括恢复之前未完成的事务和递增 PID 对应的 epoch.==(Transaction ID唯一确定机器,因为pid可能改变,但是Transaction ID是设置的不会变)== - 开始事务(beginTransaction):
Producer 执行 beginTransaction() 操作,本地记录该事务的状态为开始。此时,Transaction Coordinator 尚未被通知,只有在 Producer 发送第一条消息后,Transaction Coordinator 才认为事务已经开启 - Read-Process-Write 流程:
当Producer 开始发送消息,Transaction Coordinator 将消息存储于 Transaction Log 中,并将其状态标记为 BEGIN。如果该事务是第一个消息,Transaction Coordinator 还会启动事务的计时器(每个事务都有自己的超时时间)。注册到 Transaction Log 后,Producer 继续发送消息,即使事务未提交,消息已经保存在 Broker 上。即使后续执行了事务回滚,消息也不会删除,只是状态字段标记为 abort.这个时候的消息存在broker中但是不可见(RC情况下),==这里事务消息是存储在broker,不会直接发给消费者,而且不会乱序消费下一条消息,即使导致后面的消息阻塞== - 事务提交或终结(commitTransaction/abortTransaction):
在 Producer 执行 commitTransaction 或 abortTransaction 时,Transaction Coordinator 执行两阶段提交:- 第一阶段,将 Transaction Log 中该事务的状态设置为 PREPARE_COMMIT 或 PREPARE_ABORT。
- 第二阶段,将 Transaction Marker 写入事务涉及到的所有消息,即将消息标记为 committed 或 aborted。这一步 Transaction Coordinator 会发送给每个事务涉及到的 Leader(标记完消息后就可见了)。Broker 收到请求后,将对应的 Transaction Marker 控制信息写入日志。
- 一旦 Transaction Marker 写入完成,Transaction Coordinator 将最终的 COMPLETE_COMMIT 或 COMPLETE_ABORT 状态写入 Transaction Log,标明该事务结束。
- Consumer 在 read_committed 模式下只需做一些消息的过滤,即过滤掉回滚了的事务和处于 open 状态的事务的消息。过滤这些消息时,Consumer 利用消息中的元数据信息,不需要与 Transactional Coordinator 进行 RPC 交互。
[!tip] 参考 【Kafka】kafka消费者的三种模式(最多/最少/恰好消费一次)&生产者幂等性_kafka at least once 【Kafka】Kafka 实现 Exactly-once - 简书 (jianshu.com) 【Kafka系列】Kafka事务机制